






 本文介绍了如何使用Selenium在B/S模式下爬取MOOC课程评论,包括工作流程、任务分解、自动化打开浏览器、评论抓取、驱动更新等内容,并展示了如何自动获取和更新Edge浏览器驱动。
本文介绍了如何使用Selenium在B/S模式下爬取MOOC课程评论,包括工作流程、任务分解、自动化打开浏览器、评论抓取、驱动更新等内容,并展示了如何自动获取和更新Edge浏览器驱动。
文章目录
前言
善始者繁多,克终者盖寡。
前些时候了解到“情感分析”这个研究研究方向,对其颇感兴趣,但是做情感分析需要大量的文本,课程评论、商品评论都是很不错的素材。可是,人工去收集这些评论信息实在是太麻烦了,如果一门在线课程有1w条评论,这不得把键盘的按爆,所以呢希望寻求一种自动化的方法,让我们的程序替代我们去获取这些评论信息,也就是咱们常说的爬虫了。
一、什么是爬虫
国人将“Spider”译为“爬虫”,可以形象的理解像蜘蛛一样在网络上爬行,找到自己想要的东西。简而言之就是让程序模仿咱们浏览网页的这个过程,咱们重点关注在实际工作中程序时如何执行的。
二、 Selenium—一款强大的自动化工具
说到Selenium不得不先提一下现在主流的三种工作模式:C/S、B/S、P2P。
①C/S,Client Server的缩写,表示客户端/服务端的模式,典型代表就是咱们的手机版QQ,咱们如果要使用QQ的服务,就必须得安装QQ这个软件,再由腾讯中心给我们提供服务;
②B/S,Broswer Server的缩写,表示浏览器/服务端的模式,曾经手机这样移动设备还未普及时候非常火爆的一种方法,就是通过浏览器和远程服务器交流,可以把网页版淘宝理解为这种方式,咱们提高的Selenium就是工作在这种模式下的;
③P2P,Point to Point的缩写,表示点对点服务的模式,我们使用的QQ、微信就是这样的,我们既可以向别人发送信息,也可以接收别人的信息,换句话说我们既充当了客户端又充当了服务端。
Selenium是一种B/S模式下工作的工具,通过它我们可以实现按钮点击、输入文字各种各样的操作,像刷客、刷票这样的功能都可以实现。
三、B/S模式工作流程
我们在浏览器中输入某个网址或者某个查询关键字,然后点击回车,浏览器会给我们返回一些页面,这一系列的操作大致可以分为三个过程:
①在浏览器输入关键字或网址,向服务器发送请求;
②服务器接收到我们发送的请求,开始处理这些请求;
③服务器将请求结果返回给浏览器,如果一切正常就能够在浏览器显示一些页面,不然也会返回比如“404 not found”、“505”等信息。

四、使用Selenium爬取MOOC课程评论
4.1 任务分解
以获取MOOC课程评论的过程为例,我们可以将此行为划分为6个步骤,并通过Selenium来实现。
①在浏览器中输入MOOC网页链接;
②浏览器会返回给我们一些页面,页面里包含了很多的文字、图像、视频等;
③我们根据自己的需求在页面里找到这些评论并将其保存下来;
④继续保存下一条评论;
⑤当前页面的评论爬取完毕之后点击“下一页”;
⑥当最后一个页面的最后一条评论也保存之后,关闭浏览器。
4.2 打开浏览器并向服务器发送请求
常用的浏览器有火狐、谷歌、Edge等,我们使用Selenium是需要加载对应浏览器的驱动。将对应浏览器驱动下载后放在程序同一级目录下,并且驱动的命名也有要求。
使用这种方法虽然可行,但是浏览器的更新速度实在太快了,没更新一次浏览器我们就得重新下载对应浏览器的驱动,真的是麻烦至极!!!
def open_broswer(broswerType):
#加载浏览器驱动
firefor_driver = "geckodriver.exe"
chrome_driver = "chromedriver.exe"
edge_driver = "MicrosoftWebDriver.exe"
if broswerType=="Firefox" or broswerType=="FireFox" or broswerType=="firefox" or broswerType=="huohu" or broswerType=="火狐":
path = os.getcwd() + "\\" + firefor_driver
elif broswerType=="Chrome" or broswerType=="chrome" or broswerType=="guge" or broswerType=="谷歌":
path = os.getcwd() + "\\" + chrome_driver
else:
#默认打开edge浏览器
path = os.getcwd() + "\\" + edge_driver
return path
加载对应驱动后就可以调用get方法向服务器发送请求了,此时如果程序能够正常运行,默认会打开Edge浏览器并进入对应课程链接。
#加载自动化测试驱动,让浏览器自动执行某些操作
path = open_broswer(broswer)
if path.endswith("geckodriver.exe"):
driver = webdriver.Firefox(executable_path=path)
elif path.endswith("chromedriver.exe"):
driver = webdriver.Chrome(executable_path=path)
else:
driver = webdriver.Edge(executable_path=path)
# header = r"{User-Agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:106.0) Gecko/20100101 Firefox/106.0}"
driver.get(url)
4.3 在页面中找到评论并保存
向服务器发送请求后,服务器会返回一个html页面,此时我们需要使用我们需要对其进行解析(参看web的DOM),找到对应标签后使用PQuery(类似于JavaScript中的JQuery)找到所有的评论并保存到本地。
此处对应任务分解中的②③④步骤。
#模仿点击查看课程评价的行为
element = driver.find_element(By.ID,"review-tag-button")
element.click()
next_element = driver.find_element(By.CLASS_NAME, value="ux-pager_btn__next")
time_flag = str(time.strftime("%Y_%m_%d_%H_%M_%S",time.localtime()))
filename = "result\\comment" + time_flag + ".txt"
del_and_create_dir(filename)
next_source = driver.page_source
next_query = PyQuery(next_source)
content = next_query(".ux-mooc-comment-course-comment_comment-list_item_body_content")
with open(filename, "a", encoding="utf-8") as f:
for item in content.items():
item_text = item.children().text()
# print(item_text)
f.write(item_text)
f.write("\n")
4.4 爬取下一页评论并保存
此操作是在4.3基础上的改进,4.3只是爬取一个页面的评论,通过设置循环告诉程序要爬取的页面数,让程序将设定范围内的所有评论全都存下来。
element = driver.find_element(By.ID,"review-tag-button")
element.click()
# print("********************************************************")
'''
模仿点击下一页功能,类名是ux-pager_btn ux-pager_btn__next,
类名中的空格表示该元素属于多个类别,任意取其中一个就行,但是要保证其唯一性
'''
next_element = driver.find_element(By.CLASS_NAME, value="ux-pager_btn__next")
time_flag = str(time.strftime("%Y_%m_%d_%H_%M_%S",time.localtime()))
filename = "result\\comment" + time_flag + ".txt"
del_and_create_dir(filename)
for index in range(sum_page):
next_source = driver.page_source
next_query = PyQuery(next_source)
content = next_query(".ux-mooc-comment-course-comment_comment-list_item_body_content")
with open(filename, "a", encoding="utf-8") as f:
for item in content.items():
item_text = item.children().text()
# print(item_text)
f.write(item_text)
f.write("\n")
time.sleep(1)
next_element.click()
4.5 其他方法
每次开始爬取任务时应当判断是目标目录下是否有重名文件,如果有重名文件则应当将其删除,以免造成不必要的影响。但是在4.3和4.4中已经引入了时间戳的文件命名方法,理论上说应当不会出现同名文件。
def del_and_create_dir(filename):
#判断文件是否存在,如果存在则删除文件
filepath = os.getcwd() + "\\" + filename
print(os.getcwd())
if os.path.exists(filepath):
os.remove(filepath)
五、改进程序—自动更新驱动
使用上述方法爬取MOOC课程评论是,所有浏览器驱动都是手动下载并且手动放置的,浏览器更新一次我们就得重新下载一次驱动,这个过程太过繁琐,有没有一种自动更新驱动的方法呢?
答案是有的,microsoft已经贴心的为我们准备了浏览器驱动自动更新的方法!!!
5.1 获取Edge浏览器版本信息
在Winods 10操作系统中,Edge浏览器的配置信息放置在“C:\Program Files (x86)\Microsoft\Edge\Application\msedge.VisualElementsManifest.xml”中,我们通过DOM方法读取文件内容,截取浏览器的版本号。
def get_broswer_verson():
# 读取edge文件夹下面的xml文件(包含版本信息)
dom = xml.dom.minidom.parse(r'C:\Program Files (x86)\Microsoft\Edge\Application\msedge.VisualElementsManifest.xml')
dom_ele = dom.documentElement
ve = dom_ele.getElementsByTagName('VisualElements')
# 包含版本号的字符串文本
ve_text = ve[0].toxml()
rematch = re.match(r'(.*)\"(.*)\\VisualElements\\Logo.png', ve_text)
edge_version = rematch.group(2) # 匹配得到版本号
return edge_version
5.2 自动更新Edge浏览器驱动
有些方法虽已经过时,但并不影响其正常使用。
def auto_update_driver():
driver = webdriver.Edge(EdgeChromiumDriverManager().install())
print(driver)
5.3 程序中使用的库
from pyquery import PyQuery
from selenium import webdriver
from webdriver_manager.microsoft import EdgeChromiumDriverManager
from selenium.webdriver.common.by import By
import time
import os
import xml.dom.minidom # 处理包含浏览器版本信息的xml文件
import re
六 程序测试
使用Edge浏览器自动爬取中国大学MOOC中某门课程前5页的课程评论,并最后显示当前浏览器的版本信息。
if __name__ == '__main__':
broswer = "edge"
url = "https://www.icourse163.org/course/ZJU-199001"
sum_page = 5
auto_update_driver()
get_MOOC(broswer,url,sum_page)
print(get_broswer_verson())
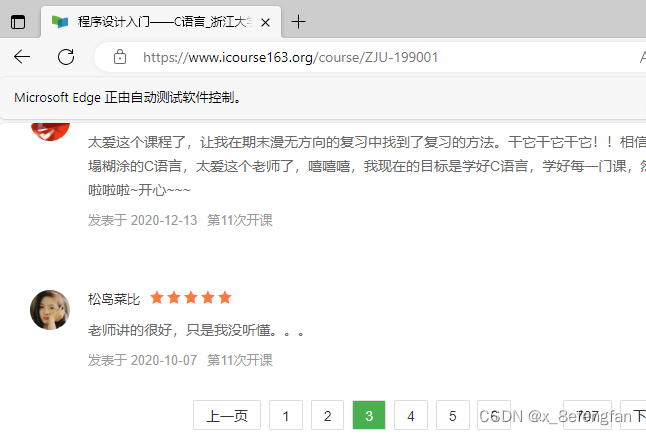
程序运行过程如图所示:

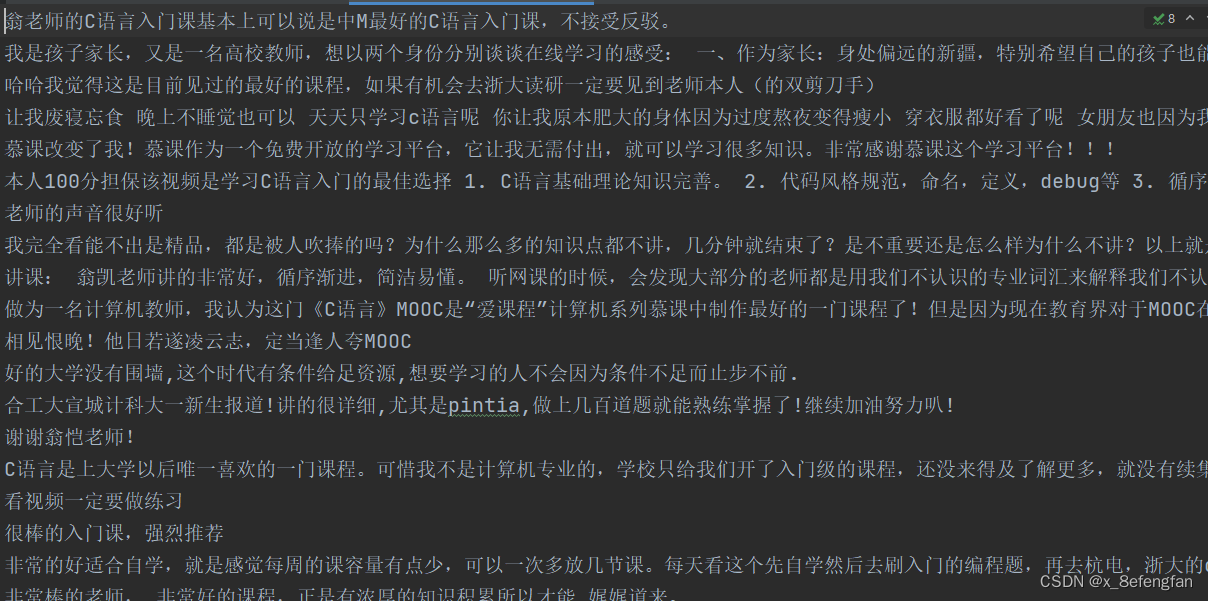
最终课程评论会保存在程序同级目录result下,文件部分内容如图所示:


















 948
948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











