







汉字点阵原理
点阵的介绍
点阵是一种将图像或字符分解为由点组成的矩阵的显示方式。每个点被视为一个像素,可以通过控制每个像素的状态(亮或暗)来显示出图像或字符。
在点阵显示中,通常使用一个二维矩阵来表示图像或字符,每个元素代表一个像素。矩阵的行和列分别对应于显示屏的行和列。通过设置每个像素的状态,可以在显示屏上呈现出各种图像和字符。
例如,一个8x8的点阵矩阵可以表示一个由64个像素组成的图像或字符。图像或字符的每个像素通过设置为亮(通常用1表示)或暗(通常用0表示)来决定其显示状态。按照特定的排列方式,将每个像素的状态传输到显示屏上,就可以呈现出对应的图像或字符。
点阵显示广泛应用于各种设备和场景,如LED显示屏、LCD显示屏、OLED显示屏等。它们被用于显示文本、图标、图像等内容。通过控制每个像素的状态,点阵显示可以实现丰富的图形和字符显示效果。
在嵌入式系统中,点阵显示经常用于显示汉字、图标、进度条等信息,以及提供用户界面的交互元素。通过使用适当的字模数据和控制算法,可以实现高质量、高效率的点阵显示效果,为用户提供更好的视觉体验。
我们也可以利用取模软件,将我们需要的文字,以点阵的方式呈现出来: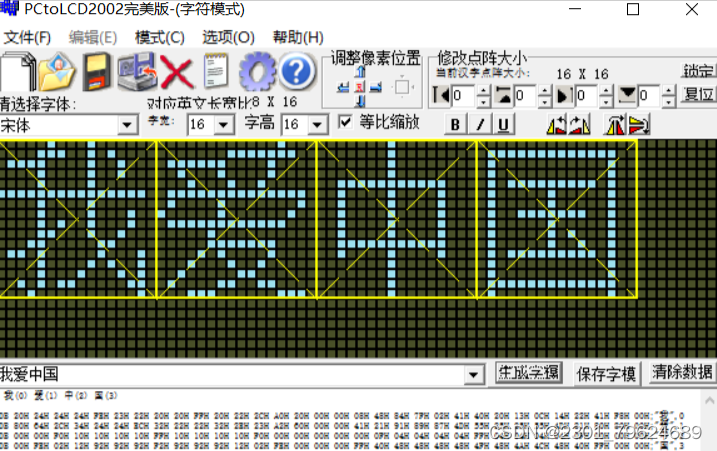 ASCII编码
ASCII编码
ASCII(American Standard Code for Information Interchange)是一种最常用的字符编码标准,用于将字符映射为数字,在计算机中表示和存储文本信息。ASCII编码使用一个字节(8个比特)来表示一个字符,最初是为了表示英文字符而设计。
以下是ASCII编码的表格示例:
| 十进制 | 字符 | 描述 |
| 65 | A | 大写字母A |
| 97 | a | 小写字母a |
| 48 | 0 | 数字0 |
| 32 | 空格 | |
| 33 | ! | 感叹号 |
| 126 | ~ | 波浪号 |
ASCII编码共定义了128个字符,包括大写字母、小写字母、数字、标点符号和控制字符等。其中,前32个字符(0-31)是控制字符,用于控制打印机和通信设备的行为。后面的95个字符(32-126)是可显示字符,用于显示文本内容。
ASCII编码只能表示有限的字符范围,无法表示其他语言的字符。随着计算机的发展和国际化的需求,后来出现了更加完善的字符编码方式,如Unicode和UTF-8,可以表示几乎所有的字符。
需要注意的是,ASCII编码只使用了一个字节来表示一个字符,因此它只能表示256个不同的字符。在使用ASCII编码的环境中,如果遇到非ASCII字符,可能会出现乱码或无法识别的情况。
ASCII编码在计算机系统中广泛使用,尤其在早期的系统和英文环境中。虽然现代计算机系统更多地使用Unicode和UTF-8等编码方式,但ASCII编码仍然具有重要的历史和概念意义。
汉字编码
汉字是中文的基本文字单位,而计算机是一种以数字为基础的设备,因此需要将汉字转换为计算机能够理解和处理的数字编码。计算机汉字编码的发展背景是为了在计算机系统中能够准确地表示和处理汉字,实现中文信息的输入、存储和显示。
在计算机汉字编码的发展过程中,出现了多种编码方式。以下是一些常见的计算机汉字编码方式及其特点的表格:
| 编码方式 | 特点 |
| GB2312 | 由中国国家标准委员会于1980年制定,包含了6763个常用汉字和682个非汉字字符,是最早的汉字编码标准。 |
| GBK | 在GB2312的基础上扩展,包含了21003个汉字和图形字符,支持繁体字和少数民族文字。 |
| GB18030 | 在GBK的基础上扩展,包含了27533个汉字和图形字符,支持Unicode字符集,是目前最完备的中文字符集编码。 |
| Unicode | 包含了世界上几乎所有的字符,每个字符都有唯一的编码,可以表示多种语言文字,包括汉字。常用的汉字编码方式是UTF-8和UTF-16。 |
| Big5 | 主要用于繁体中文的编码,是台湾地区最常用的汉字编码方式。 |
| HZGB2312 | 用于在ASCII字符集中表示汉字,是一种特殊的汉字编码方式。 |
这些编码方式都有各自的特点和适用范
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1560
1560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









