






pandas数据分析
1、Series对象
(1)定义和创建
(2)数据访问
(3)常用方法
(1)定义和创建
Serise对象是一种带有标签数据的一维数组,标签在pandas中有对应的数据类型“Index”,Serise类似于一维数组与字典的结合。
# 导入库
import pandas as pd #导入数据分析库pandas,别名pd
import numpy as np #导入科学计算库numpy,别名np
import matplotlib.pyplot as plt #导入数据可视化库matplotlib的模块pyplot,别名plt
data = pd.Series([6,8,3,4,32],index = ['a','b','c','d','e']) #创建对象data,默认标签序号为0,1,2...,但也可以自己定义
data
data = pd.Series([6,8,3,4,32],index = list('dfghe')) #将字符串强行转换成列表
data

data.index #访问标签,属性后面没有小括号
Index(['d', 'f', 'g', 'h', 'e'], dtype='object')
data.values #访问对象数据
array([ 6, 8, 3, 4, 32], dtype=int64)
data.ndim #维度
1
data.shape #Series对象形状,返回的是元祖
(5,)
data.size #对象的个数
5
names = ['aa','cc','dd','bb','ee']
ages = [56,45,89,32,65]
pd.Series(ages,names)
pd.Series({'aa':18,'cc':66,'bb':98,'dd':33,'ee':56}) #用字典{}“键值对”创建Serise对象
print(data) #内容输出数据,将被后面数据覆盖
print(data) #打印对象内容

data_1 = pd.Series(np.arange(10,30,5),index = list('abcd')) #用科学计算库生成数据创建Series对象
data_1

(2)数据访问
data_1.index
Index(['a', 'b', 'c', 'd'], dtype='object')
data_1.values
array([10, 15, 20, 25])
data_1.keys() #作为字典键key()方法访问
Index(['a', 'b', 'c', 'd'], dtype='object')
list(data_1.items()) #作为键值对items()方法访问
[('a', 10), ('b', 15), ('c', 20), ('d', 25)]
(3)常用方法
data.sort_values() #根据对象数据排序,不改变原有对象
data.sort_index() #根据对象标签排序,不改变原有对象
data.rank() #根据对象数据排名
data #原有对象不变
2、DataFrame对象
(1)定义和创建
(2)数据访问
(3)常用方法
(4)常见操作
(1)定义和创建
DataFrame可以看做是一种既有行索引,又有列索引的二维数组,类似于Excel表或关系型数据库中的二维表,是pandas中最常见的基本结构。
names = ['aa','dd','ee','oo','ff']
ages = [45,87,65,32,54]
nums = ['21','22','23','24','25']
classes = ['1','2','3','4','5']
data_2 = pd.DataFrame({'学号':nums,'姓名':names,'年龄':ages,'班级':classes},index =list('abcde'))
data_2
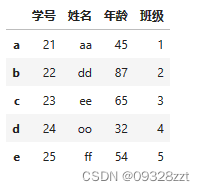
(2)数据访问
data_2[['年龄','姓名']] #根据列名访问1列或多列数据
data_2.年龄 #根据属性访问
data_2.年龄>50 #根据属性表达式判断数据返回逻辑值
data_2['年龄'][3] #根据列名和标签访问具体数据
data_2.loc['c','姓名'] #根据列名显示索引访问
data_2.iloc[0:3,1:2] #根据序号隐式索引访问
(3)常用方法
(4)常见操作
(1)Pandas中的缺失值处理
(2)Pandas中的分组操作
(3)Pandas中的数据合并操作
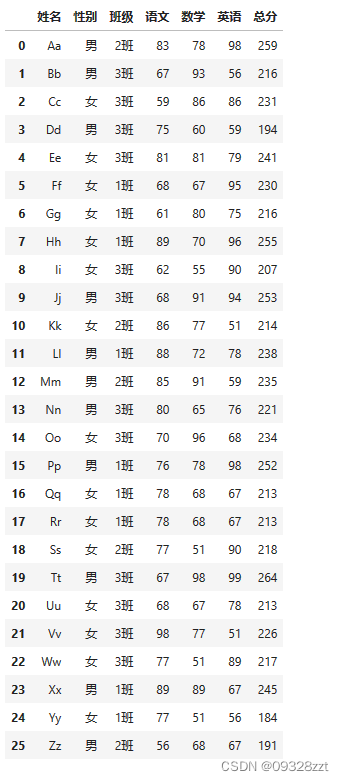
data_1 = pd.read_excel('../Stu_pack/pandas/exer_1.xlsx',skiprows = 1)
data_2 = pd.read_excel('../Stu_pack/pandas/exer_2.xlsx',skiprows = 1)
data_2
data_3 = pd.merge(data_1,data_2) #用merge()方法合并数据
data_3
data_1.join(data_2.set_index('姓名'),on = '姓名') #用join()方法合并
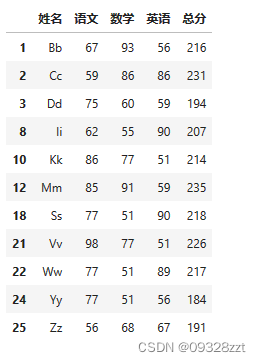
data_2[(data_2['语文']<60) | (data_2['数学']<60) | (data_2['英语']<60)] #判断某1列有不及格的数据
data_2[(data_2.语文<60) | (data_2.数学<60) | (data_2.英语<60)] #用属性索引判断















 7491
7491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









