






目录
1' 使用Pandas读取两个表格数据,并将其根据姓名进行合并
一、前期准备
检测电脑中是否含有 numpy 和 pandas 这两个第三方库:
命令行:pip show numpy
以及 pip show pandas
若含有,出现下图画面:

若不含有:
具体安装方法如下:
命令行安装:pip install numpy
或者 pip install pandas
想要更具体的了解可看 Excel_wordcloud操作(词云库)这篇博客
注意:Anaconda与IDLE是两个通道
当jupyter notebook下载了NumPy这个第三方库,IDLE中可能仍需要下载:
具体哪种情况下还需要下载:可见上一篇博客
下图为正在下载时的图片,可供参考:
二、Pandas数据分析
pandas 是一种基于 NumPy 的开源数据分析工具包,提供了高性能、简单易用的数据结构和数据分析函数。
1.Series对象
(1)定义和创建
Series对象是一种带有标签数据的一维数组,标签在Pandas中有对应的数据类型 Index ,Series类似于一维数组与字典的结合。
1' 创建Series对象
首先,导入第三方库:
import pandas as pd 导入数据分析第三方库pandas 别名为pd
import numpy as np 导入科学计算第三方库numpy 别名为np
然后,创建Series对象
1)
默认标签index为0,1,2,...,也可以自己定义

索引大小必须和列表大小一致
效果为:

2)
将字符串转换成列表
index = list( ' abcde ' )
效果为:

3)
用字典创建Series对象
默认索引为字典的键,指定索引时,会以索引为键获取值,没有值时,默认为 NaN;通过标量创
建 Series,会重复填充标量到每个索引上。

效果为:

Series 有两个关键的属性,分别是 values 和 index
values 属性获取具体值,类型为一维 ndarray
index 属性获取相应素引,类型为 Index

效果为:


效果为:

2' Index对象的常见操作
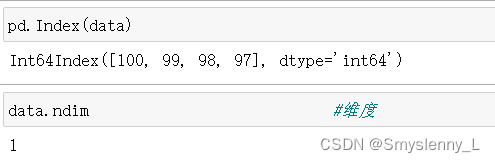
ndim:
ndarray 对象的维度
shape:
代表数组形状,返回一个元组,表示数组各个维度的长度,元组的长度为数组的维
度(与ndim相同),元组的每个元素的值代表了数组每个维度的长度

该数组的形状为1行4列
' , ' :表明返回的是元组 ,数组的形状为一维 ,该维度的长度为4
size:
ndarray 中元素的个数,相当于各个维度长度的乘积

2. 数据访问
宇典中的键不允许重复,但 Series 的索引允许有重复值。以索引为键,可访问对应的
值,如果值有多个,则结果为 Series 类型。
调用字典的一些常见方法,如keys()、items()等
(1) keys()

用字典的形式keys()方法访问对象
效果为:

(2) items()

用键值对 items()方法访问对象
效果为:

(3)用位置索引访问数据

3.常用方法

(1)Series对象的排序方法
1' sort_index():
对Series 按照索引排序,生成一个新的 Series 对象 ( 对对象标签排序 )

效果为:

2' sort_ values():
对 Series 按照值排序,生成一个新的 Series 对象
对对象值排序,但不改变原对象的顺序

效果为:

3' rank():
对值进行排名,从1开始,对于相同的值默认采用原地排序(对对象值排名)

效果为:

3.DataFrame对象
DataFrame可以看作是一种既有行索引,又有列索引的二维数组,类似于Excel表或关系型数据库中的二维表,是Pandas中最常用的基本结构。
(1)定义和创建
DataFrame 可通过一维ndarray、list、dict、Series的字典或列表、二维ndarray、单个Series、一维数组及其他的 DataFrame 等创建。

效果为:
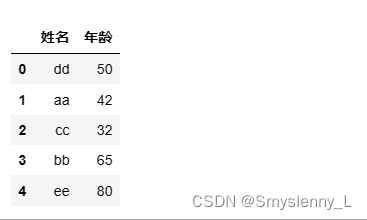
创建 DataFrame 时,可通过 index 和 columns 参数指定行索引和列索引,若没有指定索引,则默认索引为从 0开始的连续数字
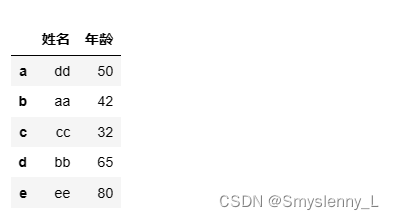
为 DataFrame 对象指定索引

效果为:
注:

消掉固有格式
效果为:
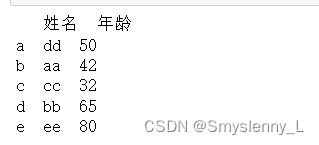
扩展:

(2)数据访问
1'
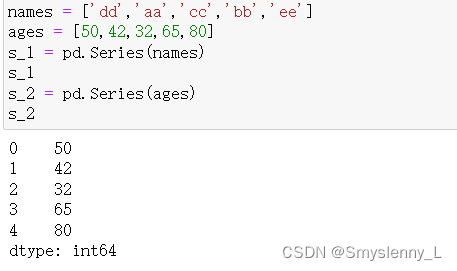
输出的内容会进行覆盖
2'

效果为:

(1)以列索引为关键字,获取某一列数据。例如d_1[列索引],结果为 Series对象。

效果为:

(2)还可进一步获取某个数据,例如 d_1[列索引][行索引],这里需要使用两个中括号,不能合并。

效果为:

(3)访问多列

效果为:

(4) 根据属性索引(属性后面没有括号)
如果列索引为字符申,则可以列名为属性名,获取某一列数据。

效果为:

(5)DataFrame 也存在隐式索引和显式索引
显式索引主要是根据对应的标签访问数据,而隐式索引主要是根据位置序号访问数据。
DataFrame 也支持索引器访问数据,其中1oc[行索引,列索引]通过显式索引访问数据,iloc[行索
引,列索引]通过隐式索引访问数据。

输出内容会进行覆盖!!!!!!!
最终效果为:

(3)常见操作
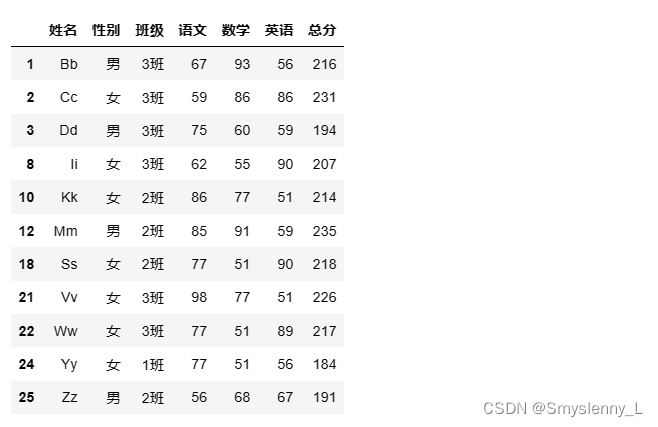
1' 使用Pandas读取两个表格数据,并将其根据姓名进行合并

skiprows:跳过多少行
合并:
方法一:merge()方法
根据相同的列表合并数据
效果为:

方法二:用join()方法合并

set_index() :设置索引列,可以用一个已有列名作为索引,返回新的对象
效果为:
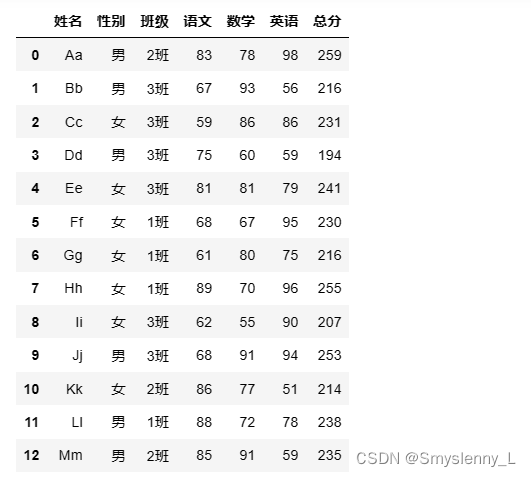
2' 实现按总分 或 语文、数学、英语单科从高到低排序功能

sort_values(by):根据值进行排序,可以指定一列或多列,返回新的对象,默认由低到高。
由高到低:ascending = False
效果为:

3' 打印所有存在不及格科目(单科<60分)的学生记录
1)对列表索引

效果为:
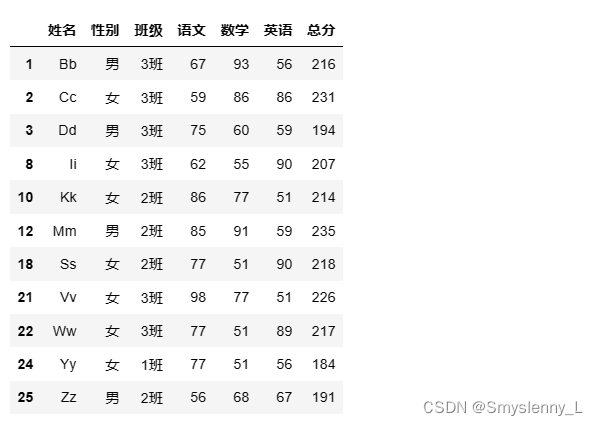
2)对属性索引

效果为:















 1814
1814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









