






总概
排序算法是计算机科学中常见的一类算法,它们可以将一组数据按照某个规则进行排列。
排序算法可以分为内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。
以下是排序算法的图总结:
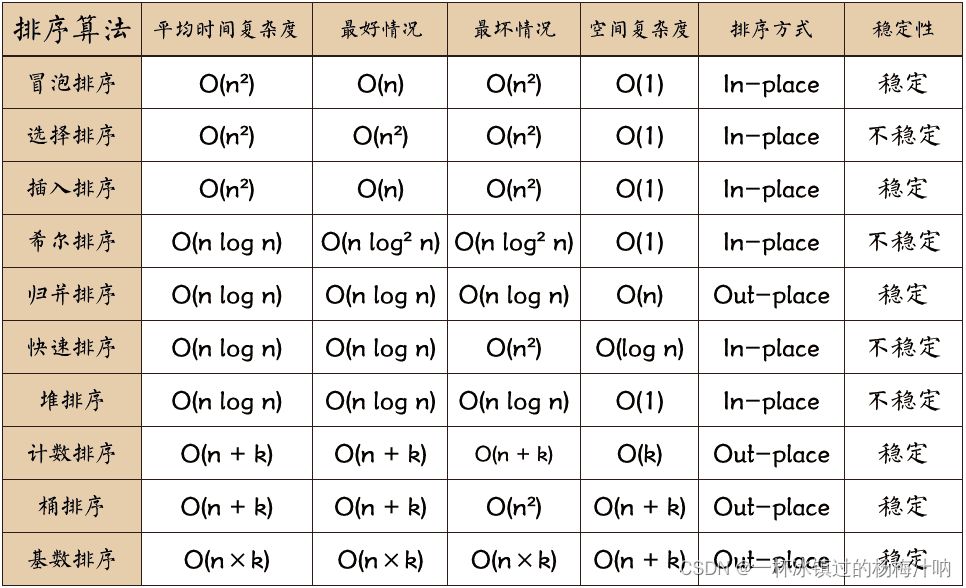
| 名词 | 解释 |
|---|---|
| n | 数据规模 |
| k | "桶"的个数 |
| In-place | 占用常数内存,不占用额外内存 |
| Out-place | 占用额外内存 |
| 稳定性 | 排序后 2 个相等键值的顺序和排序之前它们的顺序相同 |
冒泡排序
步骤:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
#include <iostream>
using namespace std;
template<typename T> //整数或浮点数皆可使用,若要使用类(class)或结构体(struct)时必须重载大于(>)运算符
void bubble_sort(T arr[], int len) {
int i, j;
for (i = 0; i < len - 1; i++)
for (j = 0; j < len - 1 - i; j++)
if (arr[j] > arr[j + 1])
swap(arr[j], arr[j + 1]);
}
int main() {
int arr[] = { 61, 17, 29, 22, 34, 60, 72, 21, 50, 1, 62 };
int len = (int) sizeof(arr) / sizeof(*arr);
bubble_sort(arr, len);
for (int i = 0; i < len; i++)
cout << arr[i] << ' ';
cout << endl;
float arrf[] = { 17.5, 19.1, 0.6, 1.9, 10.5, 12.4, 3.8, 19.7, 1.5, 25.4, 28.6, 4.4, 23.8, 5.4 };
len = (float) sizeof(arrf) / sizeof(*arrf);
bubble_sort(arrf, len);
for (int i = 0; i < len; i++)
cout << arrf[i] << ' '<<endl;
return 0;
}选择排序
步骤:
- 在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。
- 再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
- 重复第二步,直到所有元素均排序完毕。
template<typename T> //整數或浮點數皆可使用,若要使用物件(class)時必須設定大於(>)的運算子功能
void selection_sort(std::vector<T>& arr) {
for (int i = 0; i < arr.size() - 1; i++) {
int min = i;
for (int j = i + 1; j < arr.size(); j++)
if (arr[j] < arr[min])
min = j;
std::swap(arr[i], arr[min]);
}
}插入排序
步骤:
- 将第一待排序序列第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。
- 从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。)
void insertion_sort(int arr[],int len){
for(int i=1;i<len;i++){
int key=arr[i];
int j=i-1;
while((j>=0) && (key<arr[j])){
arr[j+1]=arr[j];
j--;
}
arr[j+1]=key;
}
}希尔排序
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。但希尔排序是非稳定排序算法。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率;
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位;
希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录"基本有序"时,再对全体记录进行依次直接插入排序。
步骤:
- 选择一个增量序列 t1,t2,……,tk,其中 ti > tj, tk = 1;
- 按增量序列个数 k,对序列进行 k 趟排序;
- 每趟排序,根据对应的增量 ti,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
template<typename T>
void shell_sort(T array[], int length) {
int h = 1;
while (h < length / 3) {
h = 3 * h + 1;
}
while (h >= 1) {
for (int i = h; i < length; i++) {
for (int j = i; j >= h && array[j] < array[j - h]; j -= h) {
std::swap(array[j], array[j - h]);
}
}
h = h / 3;
}
}归并排序
归并排序(Merge sort)是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。
作为一种典型的分而治之思想的算法应用,归并排序的实现由两种方法:
- 自上而下的递归(所有递归的方法都可以用迭代重写,所以就有了第 2 种方法);
- 自下而上的迭代;
步骤:
-
申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列;
-
设定两个指针,最初位置分别为两个已经排序序列的起始位置;
-
比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置;
-
重复步骤 3 直到某一指针达到序列尾;
-
将另一序列剩下的所有元素直接复制到合并序列尾。
//迭代:
template<typename T> // 整數或浮點數皆可使用,若要使用物件(class)時必須設定"小於"(<)的運算子功能
void merge_sort(T arr[], int len) {
T *a = arr;
T *b = new T[len];
for (int seg = 1; seg < len; seg += seg) {
for (int start = 0; start < len; start += seg + seg) {
int low = start, mid = min(start + seg, len), high = min(start + seg + seg, len);
int k = low;
int start1 = low, end1 = mid;
int start2 = mid, end2 = high;
while (start1 < end1 && start2 < end2)
b[k++] = a[start1] < a[start2] ? a[start1++] : a[start2++];
while (start1 < end1)
b[k++] = a[start1++];
while (start2 < end2)
b[k++] = a[start2++];
}
T *temp = a;
a = b;
b = temp;
}
if (a != arr) {
for (int i = 0; i < len; i++)
b[i] = a[i];
b = a;
}
delete[] b;
}
//递归:
void Merge(vector<int> &Array, int front, int mid, int end) {
// preconditions:
// Array[front...mid] is sorted
// Array[mid+1 ... end] is sorted
// Copy Array[front ... mid] to LeftSubArray
// Copy Array[mid+1 ... end] to RightSubArray
vector<int> LeftSubArray(Array.begin() + front, Array.begin() + mid + 1);
vector<int> RightSubArray(Array.begin() + mid + 1, Array.begin() + end + 1);
int idxLeft = 0, idxRight = 0;
LeftSubArray.insert(LeftSubArray.end(), numeric_limits<int>::max());
RightSubArray.insert(RightSubArray.end(), numeric_limits<int>::max());
// Pick min of LeftSubArray[idxLeft] and RightSubArray[idxRight], and put into Array[i]
for (int i = front; i <= end; i++) {
if (LeftSubArray[idxLeft] < RightSubArray[idxRight]) {
Array[i] = LeftSubArray[idxLeft];
idxLeft++;
} else {
Array[i] = RightSubArray[idxRight];
idxRight++;
}
}
}
void MergeSort(vector<int> &Array, int front, int end) {
if (front >= end)
return;
int mid = (front + end) / 2;
MergeSort(Array, front, mid);
MergeSort(Array, mid + 1, end);
Merge(Array, front, mid, end);
}快速排序
快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。
快速排序又是一种分而治之思想在排序算法上的典型应用。本质上来看,快速排序应该算是在冒泡排序基础上的递归分治法。
步骤:
-
从数列中挑出一个元素,称为 "基准"(pivot);
-
重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
-
递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
//函数法
sort(a,a + n);// 排序a[0]-a[n-1]的所有数.
//迭代法
// 参考:http://www.dutor.net/index.php/2011/04/recursive-iterative-quick-sort/
struct Range {
int start, end;
Range(int s = 0, int e = 0) {
start = s, end = e;
}
};
template <typename T> // 整數或浮點數皆可使用,若要使用物件(class)時必須設定"小於"(<)、"大於"(>)、"不小於"(>=)的運算子功能
void quick_sort(T arr[], const int len) {
if (len <= 0)
return; // 避免len等於負值時宣告堆疊陣列當機
// r[]模擬堆疊,p為數量,r[p++]為push,r[--p]為pop且取得元素
Range r[len];
int p = 0;
r[p++] = Range(0, len - 1);
while (p) {
Range range = r[--p];
if (range.start >= range.end)
continue;
T mid = arr[range.end];
int left = range.start, right = range.end - 1;
while (left < right) {
while (arr[left] < mid && left < right) left++;
while (arr[right] >= mid && left < right) right--;
std::swap(arr[left], arr[right]);
}
if (arr[left] >= arr[range.end])
std::swap(arr[left], arr[range.end]);
else
left++;
r[p++] = Range(range.start, left - 1);
r[p++] = Range(left + 1, range.end);
}
}
//递归法
template <typename T>
void quick_sort_recursive(T arr[], int start, int end) {
if (start >= end)
return;
T mid = arr[end];
int left = start, right = end - 1;
while (left < right) { //在整个范围内搜寻比枢纽元值小或大的元素,然后将左侧元素与右侧元素交换
while (arr[left] < mid && left < right) //试图在左侧找到一个比枢纽元更大的元素
left++;
while (arr[right] >= mid && left < right) //试图在右侧找到一个比枢纽元更小的元素
right--;
std::swap(arr[left], arr[right]); //交换元素
}
if (arr[left] >= arr[end])
std::swap(arr[left], arr[end]);
else
left++;
quick_sort_recursive(arr, start, left - 1);
quick_sort_recursive(arr, left + 1, end);
}
template <typename T> //整數或浮點數皆可使用,若要使用物件(class)時必須設定"小於"(<)、"大於"(>)、"不小於"(>=)的運算子功能
void quick_sort(T arr[], int len) {
quick_sort_recursive(arr, 0, len - 1);
}堆排序
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。堆排序可以说是一种利用堆的概念来排序的选择排序。分为两种方法:
- 大顶堆:每个节点的值都大于或等于其子节点的值,在堆排序算法中用于升序排列;
- 小顶堆:每个节点的值都小于或等于其子节点的值,在堆排序算法中用于降序排列;
步骤:
-
创建一个堆 H[0……n-1];
-
把堆首(最大值)和堆尾互换;
-
把堆的尺寸缩小 1,并调用 shift_down(0),目的是把新的数组顶端数据调整到相应位置;
-
重复步骤 2,直到堆的尺寸为 1。
#include <iostream>
#include <algorithm>
using namespace std;
void max_heapify(int arr[], int start, int end) {
// 建立父節點指標和子節點指標
int dad = start;
int son = dad * 2 + 1;
while (son <= end) { // 若子節點指標在範圍內才做比較
if (son + 1 <= end && arr[son] < arr[son + 1]) // 先比較兩個子節點大小,選擇最大的
son++;
if (arr[dad] > arr[son]) // 如果父節點大於子節點代表調整完畢,直接跳出函數
return;
else { // 否則交換父子內容再繼續子節點和孫節點比較
swap(arr[dad], arr[son]);
dad = son;
son = dad * 2 + 1;
}
}
}
void heap_sort(int arr[], int len) {
// 初始化,i從最後一個父節點開始調整
for (int i = len / 2 - 1; i >= 0; i--)
max_heapify(arr, i, len - 1);
// 先將第一個元素和已经排好的元素前一位做交換,再從新調整(刚调整的元素之前的元素),直到排序完畢
for (int i = len - 1; i > 0; i--) {
swap(arr[0], arr[i]);
max_heapify(arr, 0, i - 1);
}
}
int main() {
int arr[] = { 3, 5, 3, 0, 8, 6, 1, 5, 8, 6, 2, 4, 9, 4, 7, 0, 1, 8, 9, 7, 3, 1, 2, 5, 9, 7, 4, 0, 2, 6 };
int len = (int) sizeof(arr) / sizeof(*arr);
heap_sort(arr, len);
for (int i = 0; i < len; i++)
cout << arr[i] << ' ';
cout << endl;
return 0;
}计数排序
计数排序的核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。
步骤:
- 找出待排序的数组中最大和最小的元素
- 统计数组中每个值为i的元素出现的次数,存入数组C的第i项
- 对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加)
- 反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1
//C版本
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
void print_arr(int *arr, int n) {
int i;
printf("%d", arr[0]);
for (i = 1; i < n; i++)
printf(" %d", arr[i]);
printf("\n");
}
void counting_sort(int *ini_arr, int *sorted_arr, int n) {
int *count_arr = (int *) malloc(sizeof(int) * 100);
int i, j, k;
for (k = 0; k < 100; k++)
count_arr[k] = 0;
for (i = 0; i < n; i++)
count_arr[ini_arr[i]]++;
for (k = 1; k < 100; k++)
count_arr[k] += count_arr[k - 1];
for (j = n; j > 0; j--)
sorted_arr[--count_arr[ini_arr[j - 1]]] = ini_arr[j - 1];
free(count_arr);
}
int main(int argc, char **argv) {
int n = 10;
int i;
int *arr = (int *) malloc(sizeof(int) * n);
int *sorted_arr = (int *) malloc(sizeof(int) * n);
srand(time(0));
for (i = 0; i < n; i++)
arr[i] = rand() % 100;
printf("ini_array: ");
print_arr(arr, n);
counting_sort(arr, sorted_arr, n);
printf("sorted_array: ");
print_arr(sorted_arr, n);
free(arr);
free(sorted_arr);
return 0;
}桶排序
桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。为了使桶排序更加高效,我们需要做到这两点:
- 在额外空间充足的情况下,尽量增大桶的数量
- 使用的映射函数能够将输入的 N 个数据均匀的分配到 K 个桶中
同时,对于桶中元素的排序,选择何种比较排序算法对于性能的影响至关重要。
#include<iterator>
#include<iostream>
#include<vector>
using namespace std;
const int BUCKET_NUM = 10;
struct ListNode{
explicit ListNode(int i=0):mData(i),mNext(NULL){}
ListNode* mNext;
int mData;
};
ListNode* insert(ListNode* head,int val){
ListNode dummyNode;
ListNode *newNode = new ListNode(val);
ListNode *pre,*curr;
dummyNode.mNext = head;
pre = &dummyNode;
curr = head;
while(NULL!=curr && curr->mData<=val){
pre = curr;
curr = curr->mNext;
}
newNode->mNext = curr;
pre->mNext = newNode;
return dummyNode.mNext;
}
ListNode* Merge(ListNode *head1,ListNode *head2){
ListNode dummyNode;
ListNode *dummy = &dummyNode;
while(NULL!=head1 && NULL!=head2){
if(head1->mData <= head2->mData){
dummy->mNext = head1;
head1 = head1->mNext;
}else{
dummy->mNext = head2;
head2 = head2->mNext;
}
dummy = dummy->mNext;
}
if(NULL!=head1) dummy->mNext = head1;
if(NULL!=head2) dummy->mNext = head2;
return dummyNode.mNext;
}
void BucketSort(int n,int arr[]){
vector<ListNode*> buckets(BUCKET_NUM,(ListNode*)(0));
for(int i=0;i<n;++i){
int index = arr[i]/BUCKET_NUM;
ListNode *head = buckets.at(index);
buckets.at(index) = insert(head,arr[i]);
}
ListNode *head = buckets.at(0);
for(int i=1;i<BUCKET_NUM;++i){
head = Merge(head,buckets.at(i));
}
for(int i=0;i<n;++i){
arr[i] = head->mData;
head = head->mNext;
}
}基数排序
基数排序是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。
三种排序算法都利用了桶的概念,但对桶的使用方法上有明显差异:
- 基数排序:根据键值的每位数字来分配桶;
- 计数排序:每个桶只存储单一键值;
- 桶排序:每个桶存储一定范围的数值;
int maxbit(int data[], int n) //辅助函数,求数据的最大位数
{
int maxData = data[0]; ///< 最大数
/// 先求出最大数,再求其位数,这样有原先依次每个数判断其位数,稍微优化点。
for (int i = 1; i < n; ++i)
{
if (maxData < data[i])
maxData = data[i];
}
int d = 1;
int p = 10;
while (maxData >= p)
{
//p *= 10; // Maybe overflow
maxData /= 10;
++d;
}
return d;
/* int d = 1; //保存最大的位数
int p = 10;
for(int i = 0; i < n; ++i)
{
while(data[i] >= p)
{
p *= 10;
++d;
}
}
return d;*/
}
void radixsort(int data[], int n) //基数排序
{
int d = maxbit(data, n);
int *tmp = new int[n];
int *count = new int[10]; //计数器
int i, j, k;
int radix = 1;
for(i = 1; i <= d; i++) //进行d次排序
{
for(j = 0; j < 10; j++)
count[j] = 0; //每次分配前清空计数器
for(j = 0; j < n; j++)
{
k = (data[j] / radix) % 10; //统计每个桶中的记录数
count[k]++;
}
for(j = 1; j < 10; j++)
count[j] = count[j - 1] + count[j]; //将tmp中的位置依次分配给每个桶
for(j = n - 1; j >= 0; j--) //将所有桶中记录依次收集到tmp中
{
k = (data[j] / radix) % 10;
tmp[count[k] - 1] = data[j];
count[k]--;
}
for(j = 0; j < n; j++) //将临时数组的内容复制到data中
data[j] = tmp[j];
radix = radix * 10;
}
delete []tmp;
delete []count;
}自定义排序方式
struct student
{
int sum;
int num;
int chinese;
};
bool cmp(student s1,student s2)//返回值不是true的,就交换
{
if(s1.sum!=s2.sum) return s1.sum>s2.sum;
if(s1.chinese!=s2.chinese) return s1.chinese>s2.chinese;
if(s1.num!=s2.num) return s1.num<s2.num;
}
int main()
{
sort(stu,stu+n,cmp);
}















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









