






本周小组的主要任务是:对本项目做一个详细的学习规划
一、文献综述:无人机植物分类核心方法
1.1 学位论文文献:
《融合无人机 LiDAR 和高光谱特征的天然次生林树种及林分类型识别》
链接:http://dspace.nefu.edu.cn/handle/112221/23669
研究方法:聚焦无人机多源数据(高光谱 + LiDAR)的深度融合,利用 CNN 的特征学习能力提升天然次生林(复杂混交林)的分类精度。
常用模型:卷积神经网络、融合策略、随机森林(RF)、梯度提升机
1.2 外文文献:
1)《Tree Species Classification of Drone Hyperspectral and RGB Imagery with Deep Learning Convolutional Neural Networks》
链接:https://www.preprints.org/manuscript/202002.0334/v1
研究方法:提出三维卷积神经网络(3D-CNN),结合高光谱(HS)、RGB 影像和冠层高度模型(CHM)进行树种分类
模型:基于3D-CNN的多模态特征融合(深度学习)
2)《Classification of Individual Tree Species Using UAV LiDAR Based on Transformer》
链接:https://www.mdpi.com/1999-4907/14/3/484
研究方法:直接处理无人机激光雷达(LiDAR)点云数据,探索基于 Transformer 的 3D 深度学习算法在个体树种分类领域的潜力。利用东北林业大学实验林场获取的无人机 LiDAR 数据,经去噪、地面滤波等预处理后,采用改进随机游走算法进行单木分割并制作数据集。训练和测试六种不同的 3D 深度学习神经网络和随机森林算法对三种树种的点云进行分类。
模型:基于 Transformer 的 3D 深度学习算法
1.3 中文文献:
1)《基于不同机器学习算法的无人机高光谱影像树种分类研究》:
http://mp.weixin.qq.com/s?__biz=MzA4MzQ0NjUwMg==&mid=2247484689&idx=1&sn=2f1f3d4dd9e4868b70041efc4faf6c80&scene=0
研究方法:利用无人机采集黑龙江省帽儿山实验林场的高光谱数据,进行预处理后,分别用基于高斯核的支持向量机、随机森林、k - 近邻 3 种机器学习算法建立基于全波段高光谱数据的树种分类模型,又基于不同波段选择方法对全波段数据降维后构建分类模型,最后联合波段选择方法与高光谱图像纹理特征构建树种分类模型。
常用模型:支持向量机、随机森林、k - 近邻。
2)《基于机器学习算法和空间分辨率调整的无人机高光谱树种分类研究》3:
链接:https://www.opticsjournal.net/Articles/OJ73cdf44e63baffce/References
研究方法:以无人机获取的高光谱影像为数据源,运用机器学习算法,通过调整空间分辨率来提升高光谱树种分类精度。
常用模型:随机森林、支持向量机。
1.4 植物分类模型总结(根据文献):
| 模型 | 核心特征 | 优势 | 局限 |
|---|---|---|---|
| 最大似然法 | 基于概率统计,假设每个类别在特征空间服从高斯分布,通过计算像元属于各类别的概率进行分类 | 原理清晰简单,在数据符合高斯分布假设时,分类效果较好,计算速度较快,不需要大量的训练样本 | 对数据的分布有要求,当数据不满足高斯分布时,分类精度会下降;易受噪声和异常值影响 |
| 最小距离法 | 计算待分类像元与各类别均值的距离(如欧氏距离),将其归属于距离最小的类别 | 计算量小,算法简单,运算速度快,对于特征维度较低的数据处理方便 | 仅考虑了像元到类别均值的距离,没有考虑数据的分布特征,分类精度相对较低,对复杂的、类别间特征重叠较多的数据分类效果差 |
| 支持向量机 | 利用核函数将数据映射到高维特征空间,寻找最优分类超平面;对于线性不可分的数据,通过引入松弛变量和惩罚因子来处理 | 对于小样本、高维度数据表现良好,能够有效处理非线性分类问题;泛化能力强,在解决二分类问题上有突出优势 | 训练时间较长,对大规模数据集的训练效率较低;核函数的选择和参数调优比较困难,需要一定的经验和技巧;对多分类问题的处理相对复杂,通常需要通过组合多个二分类器来实现 |
| 随机森林 | 基于集成学习,由多棵决策树构成,通过对决策树的结果进行投票或平均等方式得出最终分类结果;在构建决策树时,采用随机选择特征和样本的方法 | 能处理高维度数据,不需要进行特征选择;对噪声和异常值具有较好的鲁棒性;训练速度快,泛化能力强,能够评估特征的重要性 | 模型解释性相对决策树变弱;在某些情况下,可能会出现过拟合现象,尤其是在数据量较小或树的数量过多时;计算量随着树的数量增加而增大 |
| 卷积神经网络(CNN) | 具有卷积层、池化层和全连接层等结构,通过卷积操作自动提取数据的空间和光谱特征,利用池化操作降低数据维度,减少计算量 | 能够自动学习数据的特征,对于图像(如高光谱影像)数据的特征提取和分类效果出色;可以处理高维度的图像数据,在处理具有空间结构信息的数据时优势明显 | 训练需要大量的数据和计算资源,训练时间长;模型结构复杂,参数较多,调优困难;对数据的标注要求较高,标注成本较大 |
| 梯度提升机(GBM) | 基于集成学习,通过迭代地训练多个弱学习器(通常是决策树),每次迭代都尝试纠正上一轮的错误,逐步提升模型的性能 | 在处理回归和分类问题上都有很好的表现,能够处理非线性关系;可以自动进行特征选择和组合,对高维数据也能有效处理;泛化能力较好,预测精度较高 | 对异常值和噪声比较敏感,容易导致过拟合;训练过程相对较慢,尤其是在数据量较大时;模型的解释性相对较差,不如决策树直观 |
| k - 近邻(KNN) | 基于实例的学习方法,根据测试样本与训练集中最近的 k 个邻居的类别来进行预测。通过计算样本间的距离(如欧氏距离、曼哈顿距离)确定邻居关系 | 原理简单易懂,无需复杂的模型训练过程;对非线性数据有较好的适应性,能处理多分类问题;在数据分布比较均匀且特征空间维度较低时,效果良好 | 计算量较大,当数据集规模增大时,计算距离的开销会显著增加;对 k 值的选择非常敏感,k 值不同结果差异较大;对高维数据效果不佳,存在 “维度灾难” 问题,且受噪声影响较大 |
| Transformer | 基于自注意力机制,摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN)的序列处理或局部特征提取方式,能直接对输入序列的全局信息进行建模,捕捉不同位置元素间的依赖关系 | 能够高效地处理长序列数据,在提取长距离依赖关系上表现卓越;并行计算能力强,训练效率高;可解释性相对较好,通过注意力权重能分析模型关注的重点区域;在自然语言处理、图像等多领域表现出色 | 对于位置信息的处理需要额外的位置编码;在处理局部特征时,不如 CNN 高效;模型参数量大,对计算资源要求高,训练成本较高;在数据量较小的情况下,容易出现过拟合 |
二、本周学习规划与任务进展
2.1开发环境配置(已完成)
工具链:
IDE:PyCharm
框架:PyTorch
2.2 数据集收集
2.2.1 百种植物叶数据条目One-hundred plant species leaves data set - UCI Machine Learning Repository编辑https://archive.ics.uci.edu/dataset/241/one+hundred+plant+species+leaves+data+set![]() https://archive.ics.uci.edu/dataset/241/one+hundred+plant+species+leaves+data+set该数据集包含一百种植物叶子的分类图像,有三个特征文件,如,形状(shape),边缘(margin),纹理(texture)。
https://archive.ics.uci.edu/dataset/241/one+hundred+plant+species+leaves+data+set该数据集包含一百种植物叶子的分类图像,有三个特征文件,如,形状(shape),边缘(margin),纹理(texture)。
优点:(1)数据集包含100种不同的植物,具有种类多样性,有利于训练鲁棒的分类模型。
(2)每个类别单独一个文件夹,方便用于监督学习的图像分类任务。清晰的命名规范与文件结构便于自动处理和脚本化加载。
(3)提供多种特征提取结果,适用于机器学习方法。
(4)每张图像均为单一叶片拍摄,背景干净,适用于基于图像的深度学习分类。
(5)提供说明文档和研究论文,便于用户快速理解数据来源与应用背景。
2.2.2 植物幼苗数据集
植物幼苗数据集-生物系统中的计算机视觉 --- Plant Seedlings Dataset – Computer Vision in Biosystems编辑https://vision.eng.au.dk/plant-seedlings-dataset/![]() https://vision.eng.au.dk/plant-seedlings-dataset/该数据集被广泛用于植物识别、农业自动化和计算机视觉研究。
https://vision.eng.au.dk/plant-seedlings-dataset/该数据集被广泛用于植物识别、农业自动化和计算机视觉研究。
优点:(1)多样化的植物种类生长阶段:包含约960株植物,涵盖12个常见农业植物种类,如玉米、小麦、甜菜等,且涵盖多个生长阶段。有助于构建适用于不同生长周期的分类模型。
(2)高分辨率图像:所有图像均为RGB格式,物理分辨率约每毫米10个像素,可以清晰捕捉植物的细节特征,如叶形、边缘和纹理,实现精准的特征提取和分类。
(3)多种图像格式与预处理版本:提供三种图像类型,原始全景图像、未分割的单株植物图像以及自动分割的单株植物图像,实现从传统图像处理到深度学习等多种研究方法。
(4)真实的拍摄环境:图像为自然光照下拍摄,背景包含真实的农业环境元素,增强了模型在实际应用中的泛化能力。
(5)标准化的评估基准:官方建议使用F1分数作为分类性能的评估标准,为不同算法的比较提供了统一的标准。
(6)适用场景:农业自动化的杂草识别与分类、植物生长检测与病虫害检测、计算机视觉模型的训练与评估、图像分割与特征提取研究。
2.3基础代码复现
2.3.1 python+Pytorch 环境代码测试
1.测试代码:
#1.
# import torch
# import platform
#
# # 系统信息
# print(f"操作系统: {platform.system()} {platform.version()}")
# print(f"Python版本: {platform.python_version()}")
#
# # 检查PyTorch版本
# print(f"PyTorch版本: {torch.__version__}")
#
# # 确认使用CPU
# device = torch.device("cpu")
# print(f"使用设备: {device}")
#
# # CPU计算测试
# x = torch.tensor([1.0, 2.0], device=device)
# y = torch.tensor([3.0, 4.0], device=device)
# z = x + y
# print(f"计算结果: {z}")
#
#
# # 验证深度学习基本操作
# # 创建简单神经网络
# class SimpleNet(torch.nn.Module):
# def __init__(self):
# super(SimpleNet, self).__init__()
# self.fc = torch.nn.Linear(2, 1)
#
# def forward(self, x):
# return self.fc(x)
#
#
# # 初始化模型
# model = SimpleNet().to(device)
#
# # 创建测试数据
# inputs = torch.randn(10, 2, device=device)
# outputs = model(inputs)
#
# print(f"模型输出形状: {outputs.shape}")
# print("PyTorch CPU环境检查完成!")
#2.
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# 检查环境
print(f"PyTorch版本: {torch.__version__}")
device = torch.device("cpu")
print(f"使用设备: {device}")
# 生成模拟植被数据
def generate_vegetation_data(num_samples=1000, img_size=16):
"""生成四类植被的模拟数据:草地、森林、灌木、农作物"""
np.random.seed(42)
torch.manual_seed(42)
# 4类植被特征
classes = {
0: {"name": "草地", "color": [0.2, 0.8, 0.2]}, # 绿色为主
1: {"name": "森林", "color": [0.1, 0.6, 0.1]}, # 深绿色
2: {"name": "灌木", "color": [0.6, 0.8, 0.2]}, # 黄绿色
3: {"name": "农作物", "color": [0.8, 0.8, 0.2]} # 亮黄色
}
X = []
y = []
for i in range(num_samples):
# 随机选择类别
label = np.random.randint(0, 4)
y.append(label)
# 创建图像
img = np.ones((img_size, img_size, 3), dtype=np.float32)
# 根据类别设置颜色基调
base_color = classes[label]["color"]
for c in range(3):
img[:, :, c] *= base_color[c]
# 添加随机噪声
noise = np.random.normal(0, 0.1, (img_size, img_size, 3)).astype(np.float32)
img = np.clip(img + noise, 0, 1)
X.append(img)
# 转换为numpy数组并调整形状
X = np.array(X).transpose(0, 3, 1, 2) # [样本数, 通道, 高, 宽]
y = np.array(y)
return X, y
# 定义简单CNN模型
class VegetationClassifier(nn.Module):
def __init__(self, num_classes=4):
super(VegetationClassifier, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(2)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(2)
self.fc1 = nn.Linear(32 * 4 * 4, 64)
self.relu3 = nn.ReLU()
self.fc2 = nn.Linear(64, num_classes)
def forward(self, x):
x = self.pool1(self.relu1(self.conv1(x)))
x = self.pool2(self.relu2(self.conv2(x)))
x = x.view(-1, 32 * 4 * 4)
x = self.relu3(self.fc1(x))
x = self.fc2(x)
return x
# 生成数据
X, y = generate_vegetation_data()
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 转换为PyTorch张量
X_train = torch.FloatTensor(X_train)
y_train = torch.LongTensor(y_train)
X_test = torch.FloatTensor(X_test)
y_test = torch.LongTensor(y_test)
# 创建数据加载器
train_dataset = TensorDataset(X_train, y_train)
test_dataset = TensorDataset(X_test, y_test)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
# 初始化模型、损失函数和优化器
model = VegetationClassifier().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练函数
def train(model, train_loader, criterion, optimizer, epochs=10):
model.train()
for epoch in range(epochs):
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch {epoch + 1}/{epochs}, Loss: {running_loss / len(train_loader):.4f}")
return model
# 评估函数
def evaluate(model, test_loader):
model.eval()
predictions = []
true_labels = []
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
predictions.extend(preds.cpu().numpy())
true_labels.extend(labels.cpu().numpy())
accuracy = accuracy_score(true_labels, predictions)
print(f"测试准确率: {accuracy * 100:.2f}%")
return accuracy
# 训练模型
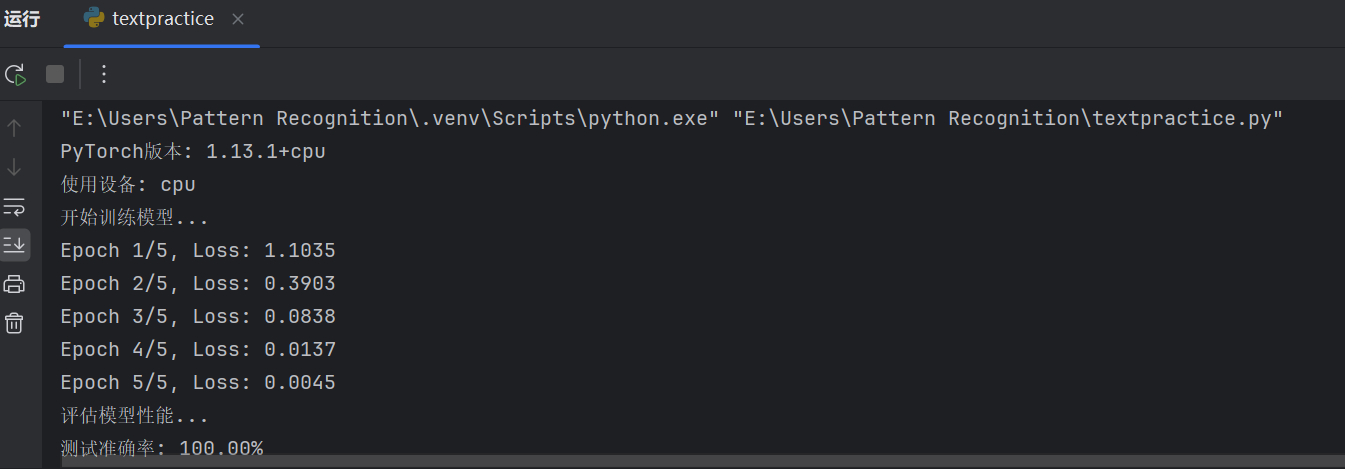
print("开始训练模型...")
model = train(model, train_loader, criterion, optimizer, epochs=5)
# 评估模型
print("评估模型性能...")
evaluate(model, test_loader)
# 可视化预测结果
def visualize_predictions(model, test_loader, num_samples=5):
model.eval()
classes = ["草地", "森林", "灌木", "农作物"]
fig, axes = plt.subplots(1, num_samples, figsize=(15, 3))
with torch.no_grad():
for i, (inputs, labels) in enumerate(test_loader):
if i >= num_samples:
break
inputs = inputs.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
# 显示图像
img = inputs[0].cpu().numpy().transpose(1, 2, 0) # 调整通道顺序
true_label = classes[labels[0].item()]
pred_label = classes[preds[0].item()]
axes[i].imshow(img)
axes[i].set_title(f"真实: {true_label}\n预测: {pred_label}")
axes[i].axis("off")
plt.tight_layout()
plt.savefig("vegetation_predictions.png")
plt.show()
print("预测结果已保存为 vegetation_predictions.png")
# 可视化预测
visualize_predictions(model, test_loader)
print("植被分类示例完成!")2.运行结果:
2.3.2 KNN分类器
1.测试代码:
# ============== 1. 导入所有依赖库并设置中文字体 ==============
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris, load_digits
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix, ConfusionMatrixDisplay
# 设置中文字体(根据操作系统选择其一)
plt.rcParams['font.sans-serif'] = ['SimHei'] # Windows系统中文支持
# plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] # macOS系统中文支持
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# ============== 2. 数据加载与探索 ==============
# 加载鸢尾花数据集
iris = load_iris()
X_iris, y_iris = iris.data, iris.target
print("[鸢尾花数据集] 维度:", X_iris.shape)
print("[鸢尾花数据集] 类别分布:", np.bincount(y_iris))
# ============== 3. 数据预处理与可视化 ==============
# 标准化鸢尾花数据
scaler = StandardScaler()
X_iris_scaled = scaler.fit_transform(X_iris)
# 可视化鸢尾花前两维特征分布(中文标签)
plt.figure(figsize=(8, 6))
plt.scatter(X_iris[:, 0], X_iris[:, 1], c=y_iris, cmap='viridis', edgecolor='k')
plt.xlabel('花萼长度 (cm)') # 中文标签
plt.ylabel('花萼宽度 (cm)')
plt.title('鸢尾花数据集分布')
plt.colorbar(label='类别')
plt.show()
# ============== 4. KNN分类器实现 ==============
# 调用Scikit-learn库
# 划分训练集与测试集(鸢尾花数据)
X_train, X_test, y_train, y_test = train_test_split(
X_iris_scaled, y_iris, test_size=0.3, random_state=42
)
# 训练KNN模型(K=5,欧氏距离)
knn = KNeighborsClassifier(n_neighbors=5, metric='euclidean')
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
# ============== 5. 模型评估与调参 ==============
# 计算准确率与分类报告(中文输出)
print("\n[模型评估] 准确率:", accuracy_score(y_test, y_pred))
print("[模型评估] 分类报告:\n", classification_report(y_test, y_pred))
# 分析K值对性能的影响(中文图表)
k_values = list(range(1, 15))
accuracies = []
for k in k_values:
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
accuracies.append(knn.score(X_test, y_test))
plt.figure(figsize=(8, 5))
plt.plot(k_values, accuracies, marker='o', color='#1f77b4')
plt.xlabel('K值')
plt.ylabel('测试集准确率')
plt.title('K值选择对分类性能的影响')
plt.grid(True, linestyle='--', alpha=0.7)
plt.show()
# 混淆矩阵可视化(中文标题)
ConfusionMatrixDisplay.from_estimator(knn, X_test, y_test, cmap='Blues')
plt.title('鸢尾花分类混淆矩阵(K=5)')
plt.show()
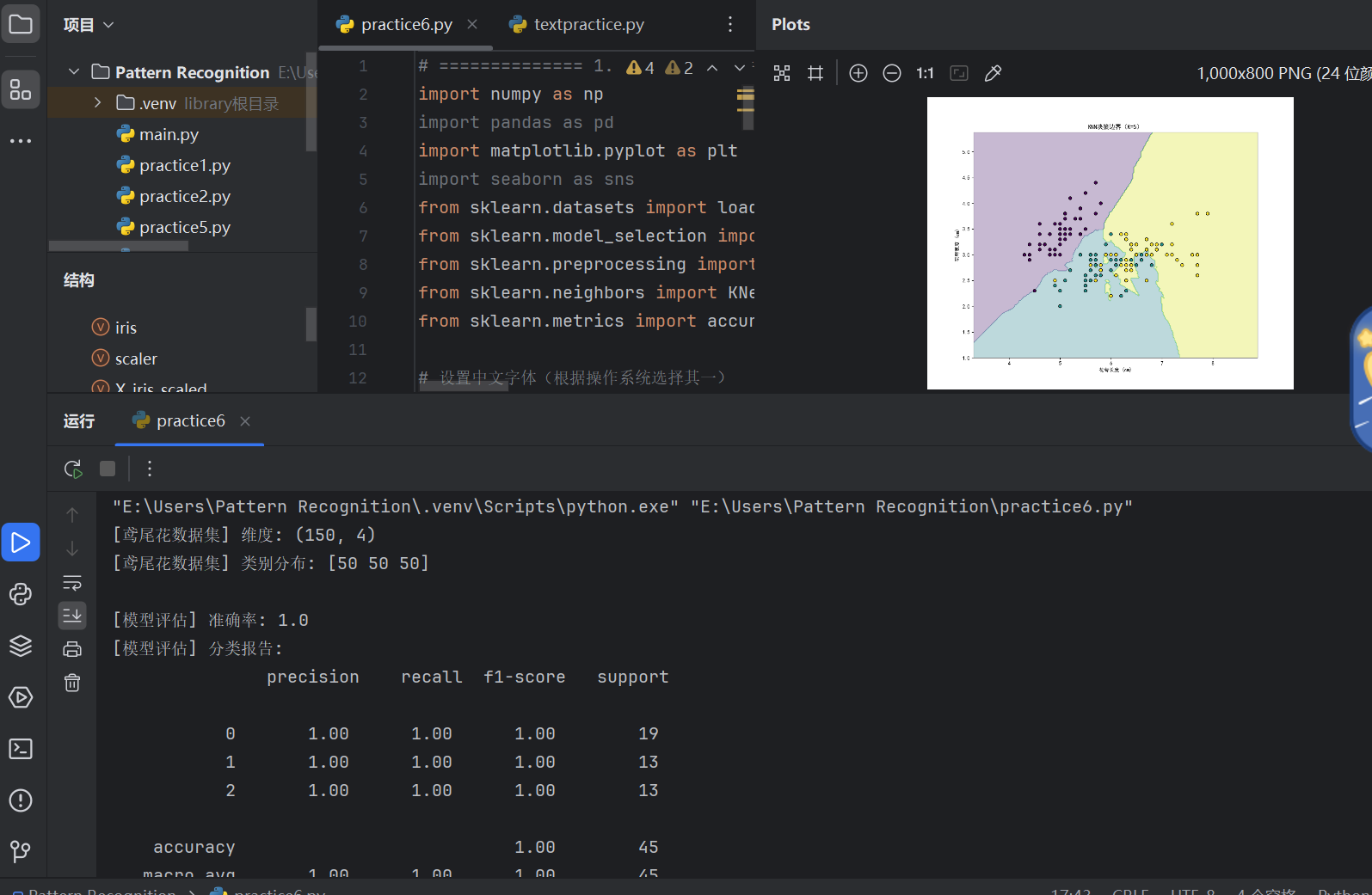
# ============== 6. 决策边界可视化(中文标签) ==============
# 仅使用前两个特征
X_2d = X_iris[:, :2]
X_train_2d, X_test_2d, y_train_2d, y_test_2d = train_test_split(
X_2d, y_iris, test_size=0.3, random_state=42
)
knn_2d = KNeighborsClassifier(n_neighbors=5)
knn_2d.fit(X_train_2d, y_train_2d)
# 生成网格点
x_min, x_max = X_2d[:, 0].min() - 1, X_2d[:, 0].max() + 1
y_min, y_max = X_2d[:, 1].min() - 1, X_2d[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
# 预测网格点类别
Z = knn_2d.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘制决策边界(中文标签)
plt.figure(figsize=(10, 8))
plt.contourf(xx, yy, Z, alpha=0.3, cmap='viridis')
plt.scatter(X_2d[:, 0], X_2d[:, 1], c=y_iris, cmap='viridis', edgecolor='k')
plt.xlabel('花萼长度 (cm)')
plt.ylabel('花萼宽度 (cm)')
plt.title('KNN决策边界(K=5)')
plt.show()2.运行结果:
2.4课程学习
1.《Pytorch日月光华课程》
2.《深度学习入门-基于Python的理论与实现》:深度学习零基础小白用一周时间去看鱼书
3.Pytorch学习:“我是土堆”
4.李沐老师的《动手学深度学习》,适用于水平较高的。或者UP主:机器学习AI算法工程师或吴恩达(双语课程)
三、下周计划
1.在对无人机数据处理的步骤充分了解的基础上,学习相关的深度学习课程进行简单的植被分类。
2.阅读大量文献,总结学习方法和研究方法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









