






爬虫解析
解析
xpath
xpath使用:
注意:提前安装xpath插件
(1)打开chrome浏览器
(2)点击右上角小圆点
(3)更多工具
(4)扩展程序
(5)拖拽xpath插件到扩展程序中
(6)如果crx文件失效,需要将后缀修改zip
(7)再次拖拽
(8)关闭浏览器重新打开
(9)ctrl + shift + x
(10)出现小黑框
1.安装lxml库
pip install lxml ‐i https://pypi.douban.com/simple
2.导入lxml.etree
from lxml import etree
3.etree.parse() 解析本地文件
html_tree = etree.parse('XX.html')
4.etree.HTML() 服务器响应文件
html_tree = etree.HTML(response.read().decode('utf‐8')
4.html_tree.xpath(xpath路径)
xpath解析本地文件
我们创建一个html文件
from lxml import etree
# xpath解析
# (1)本地文件 etree.parse
# (2)服务器响应的数据 response.read().decode('utf-8') ***** etree.HTML()
# xpath解析本地文件
tree = etree.parse('070_尚硅谷_爬虫_解析_xpath的基本使用.html')
print(tree)
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8"/> <!-- 结束标签加一个/ -->
<title>Title</title>
</head>
<body>
<ul>
<li id="l1" class="c1">北京</li>
<li id="l2">上海</li>
<li id="c3">深圳</li>
<li id="c4">武汉</li>
</ul>
<!-- <ul>-->
<!-- <li>大连</li>-->
<!-- <li>锦州</li>-->
<!-- <li>沈阳</li>-->
<!-- </ul>-->
</body>
</html>
如果<meta charset="UTF-8">后面没有加/,我们运行代码时编译器就会报错,开始和结束标签不匹配

xpath解析服务器响应数据
xpath基本语法:
1.路径查询
//:查找所有子孙节点,不考虑层级关系
/ :找直接子节点
2.谓词查询
//div[@id]
//div[@id="maincontent"]
3.属性查询
//@class
4.模糊查询
//div[contains(@id, "he")]
//div[starts‐with(@id, "he")]
5.内容查询
//div/h1/text()
6.逻辑运算
//div[@id="head" and @class="s_down"]
//title | //price
li_list=tree.xpath('//body/li')#li不是body的子节点,找不到任何数据
#严格的层级关系
li_list=tree.xpath('//body//li')
li_list=tree.xpath('//body/ul/li')
from lxml import etree
# xpath解析
# (1)本地文件 etree.parse
# (2)服务器响应的数据 response.read().decode('utf-8') ***** etree.HTML()
# xpath解析本地文件
tree = etree.parse('070_尚硅谷_爬虫_解析_xpath的基本使用.html')
#tree.xpath('xpath路径')
# 查找ul下面的li
# li_list = tree.xpath('//body/ul/li')
# 查找所有有id的属性的li标签
# text()获取标签中的内容
# li_list = tree.xpath('//ul/li[@id]/text()')
# 找到id为l1的li标签 注意内容需要引号的问题
# li_list = tree.xpath('//ul/li[@id="l1"]/text()')
# 查找到id为l1的li标签的class的属性值
# li = tree.xpath('//ul/li[@id="l1"]/@class')
# 查询id中包含l的li标签
# li_list = tree.xpath('//ul/li[contains(@id,"l")]/text()')
# 查询id的值以l开头的li标签
# li_list = tree.xpath('//ul/li[starts-with(@id,"c")]/text()')
#查询id为l1和class为c1的
# li_list = tree.xpath('//ul/li[@id="l1" and @class="c1"]/text()')
li_list = tree.xpath('//ul/li[@id="l1"]/text() | //ul/li[@id="l2"]/text()')
# 判断列表的长度来判断数据个数
print(li_list)
print(len(li_list))
获取百度一下
# (1) 获取网页的源码
# (2) 解析 解析的服务器响应的文件 etree.HTML
# (3) 打印
import urllib.request
url = 'https://www.baidu.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
# 请求对象的定制
request = urllib.request.Request(url = url,headers = headers)
# 模拟浏览器访问服务器
response = urllib.request.urlopen(request)
# 获取网页源码
content = response.read().decode('utf-8')
# 解析网页源码 来获取我们想要的数据
from lxml import etree
# 解析服务器响应的文件
tree = etree.HTML(content)
# 获取想要的数据 xpath的返回值是一个列表类型的数据,我们加[]获取值
result = tree.xpath('//input[@id="su"]/@value')[0]
print(result)
站长素材
1.站长素材图片抓取并且下载
点我进入站长素材网–》懒加载
我们需要获取站长素材网站的前十页的图片
我们查看network,我们发现在第一页
url=https://sc.chinaz.com/tupian/qinglvtupian.html
在第n页
https://sc.chinaz.com/tupian/qinglvtupian_page
其中page=n
所以,我们可以添加一个条件控制语句
if(page == 1):
url = 'https://sc.chinaz.com/tupian/qinglvtupian.html'
else:
url = 'https://sc.chinaz.com/tupian/qinglvtupian_' + str(page) + '.html'
一般的设计图片网站会进行懒加载,我们对需要对懒加载的图片标签进行xpath解析,而不是对已经加载的图片标签进行xpath解析

# (1) 请求对象的定制
# (2)获取网页的源码
# (3)下载
# 需求 下载的前十页的图片
# https://sc.chinaz.com/tupian/qinglvtupian.html 1
# https://sc.chinaz.com/tupian/qinglvtupian_page.html
import urllib.request
from lxml import etree
def create_request(page):
if(page == 1):
url = 'https://sc.chinaz.com/tupian/qinglvtupian.html'
else:
url = 'https://sc.chinaz.com/tupian/qinglvtupian_' + str(page) + '.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
}
request = urllib.request.Request(url = url, headers = headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(content):
# 下载图片
# urllib.request.urlretrieve('图片地址','文件的名字')
tree = etree.HTML(content)
name_list = tree.xpath('//div[@id="container"]//a/img/@alt')
# 一般设计图片的网站都会进行懒加载
src_list = tree.xpath('//div[@id="container"]//a/img/@src2')
for i in range(len(name_list)):
name = name_list[i]
src = src_list[i]
url = 'https:' + src
urllib.request.urlretrieve(url=url,filename='./loveImg/' + name + '.jpg')
if __name__ == '__main__':
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page,end_page+1):
# (1) 请求对象的定制
request = create_request(page)
# (2)获取网页的源码
content = get_content(request)
# (3)下载
down_load(content)
json
json只能解析本地的json文件
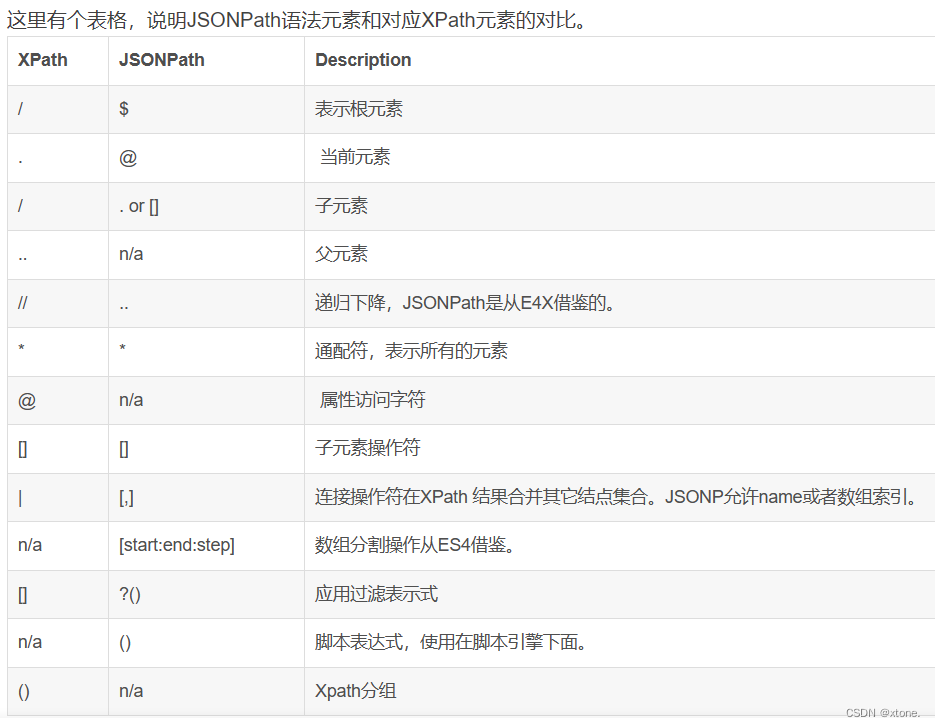
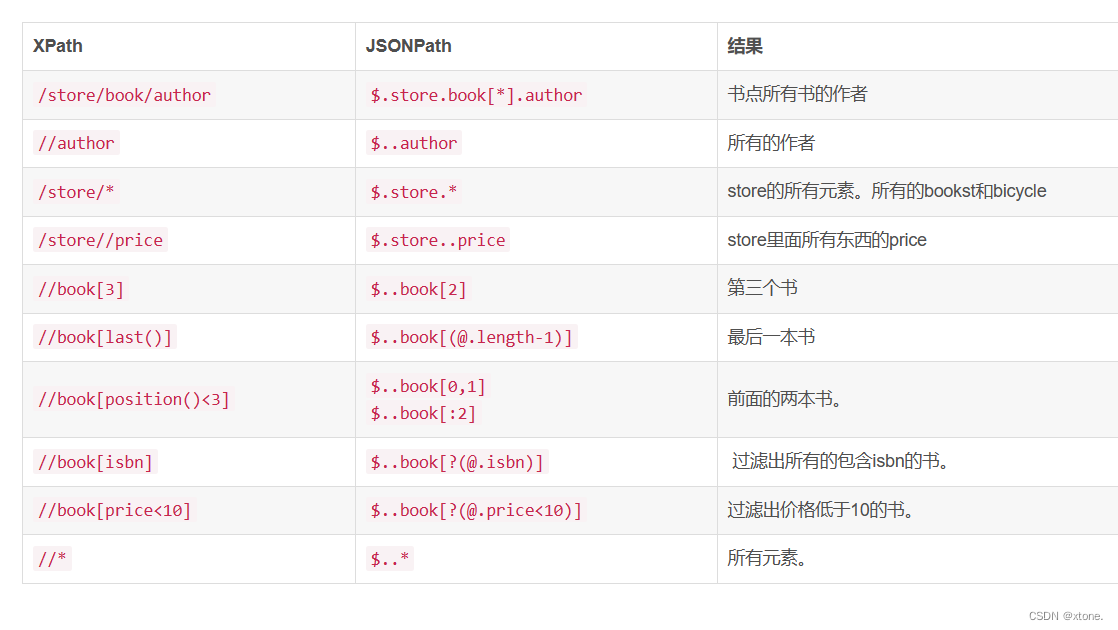
xpath和json的对应关系如下
json基本使用
我们创建一个json文件
{ "store": {
"book": [
{ "category": "修真",
"author": "六道",
"title": "坏蛋是怎样练成的",
"price": 8.95
},
{ "category": "修真",
"author": "天蚕土豆",
"title": "斗破苍穹",
"price": 12.99
},
{ "category": "修真",
"author": "唐家三少",
"title": "斗罗大陆",
"isbn": "0-553-21311-3",
"price": 8.99
},
{ "category": "修真",
"author": "南派三叔",
"title": "星辰变",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"author": "老马",
"color": "黑色",
"price": 19.95
}
}
}
import json
import jsonpath
obj = json.load(open('073_尚硅谷_爬虫_解析_jsonpath.json','r',encoding='utf-8'))
# 书店所有书的作者
# author_list = jsonpath.jsonpath(obj,'$.store.book[*].author')#*代表所有的book标签下的所有author
# print(author_list)
# 所有的作者
# author_list = jsonpath.jsonpath(obj,'$..author')
# print(author_list)
# store下面的所有的元素
# tag_list = jsonpath.jsonpath(obj,'$.store.*')
# print(tag_list)
# store里面所有东西的price
# price_list = jsonpath.jsonpath(obj,'$.store..price')
# print(price_list)
# 第三个书
# book = jsonpath.jsonpath(obj,'$..book[2]')#通过下标获取第几本书
# print(book)
# 最后一本书
# book = jsonpath.jsonpath(obj,'$..book[(@.length-1)]')
# print(book)
# 前面的两本书
# book_list = jsonpath.jsonpath(obj,'$..book[0,1]')
# book_list = jsonpath.jsonpath(obj,'$..book[:2]')
# print(book_list)
# 条件过滤需要在()的前面添加一个?
# 过滤出所有的包含isbn的书。
# book_list = jsonpath.jsonpath(obj,'$..book[?(@.isbn)]')
# print(book_list)
# 哪本书超过了10块钱
book_list = jsonpath.jsonpath(obj,'$..book[?(@.price>10)]')
print(book_list)
json解析淘票票
需求:获取北京这个城市卖票的区域
我们打开网页的请求头

我们发现给出的网页并没有给出任何的数据,说明了请求头给出了一些数据的限制
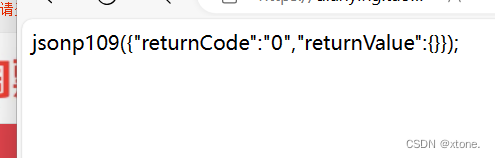
我们将其请求头全复制下来,其中需要注意的是我们需要将请求头中开头是:的请求头全注释掉,有'accept-encoding': 'gzip, deflate, br'的请求头给注释掉
import urllib.request
url = 'https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1629789477003_137&jsoncallback=jsonp138&action=cityAction&n_s=new&event_submit_doGetAllRegion=true'
headers = {
# ':authority': 'dianying.taobao.com',
# ':method': 'GET',
# ':path': '/cityAction.json?activityId&_ksTS=1629789477003_137&jsoncallback=jsonp138&action=cityAction&n_s=new&event_submit_doGetAllRegion=true',
# ':scheme': 'https',
'accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
# 'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': 'cna=UkO6F8VULRwCAXTqq7dbS5A8; miid=949542021157939863; sgcookie=E100F01JK9XMmyoZRigjfmZKExNdRHQqPf4v9NIWIC1nnpnxyNgROLshAf0gz7lGnkKvwCnu1umyfirMSAWtubqc4g%3D%3D; tracknick=action_li; _cc_=UIHiLt3xSw%3D%3D; enc=dA18hg7jG1xapfVGPHoQCAkPQ4as1%2FEUqsG4M6AcAjHFFUM54HWpBv4AAm0MbQgqO%2BiZ5qkUeLIxljrHkOW%2BtQ%3D%3D; hng=CN%7Czh-CN%7CCNY%7C156; thw=cn; _m_h5_tk=3ca69de1b9ad7dce614840fcd015dcdb_1629776735568; _m_h5_tk_enc=ab56df54999d1d2cac2f82753ae29f82; t=874e6ce33295bf6b95cfcfaff0af0db6; xlly_s=1; cookie2=13acd8f4dafac4f7bd2177d6710d60fe; v=0; _tb_token_=e65ebbe536158; tfstk=cGhRB7mNpnxkDmUx7YpDAMNM2gTGZbWLxUZN9U4ulewe025didli6j5AFPI8MEC..; l=eBrgmF1cOsMXqSxaBO5aFurza77tzIRb8sPzaNbMiInca6OdtFt_rNCK2Ns9SdtjgtfFBetPVKlOcRCEF3apbgiMW_N-1NKDSxJ6-; isg=BBoas2yXLzHdGp3pCh7XVmpja8A8S54lyLj1RySTHq14l7vRDNufNAjpZ2MLRxa9',
'referer': 'https://dianying.taobao.com/',
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
'x-requested-with': 'XMLHttpRequest',
}
request = urllib.request.Request(url = url, headers = headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
我们获取的数据如下

但是这个数据并不是我们想要的,我们将改行复制下来。
我们可以使用json解析
我们打开json.cn网站
点我进入该网站
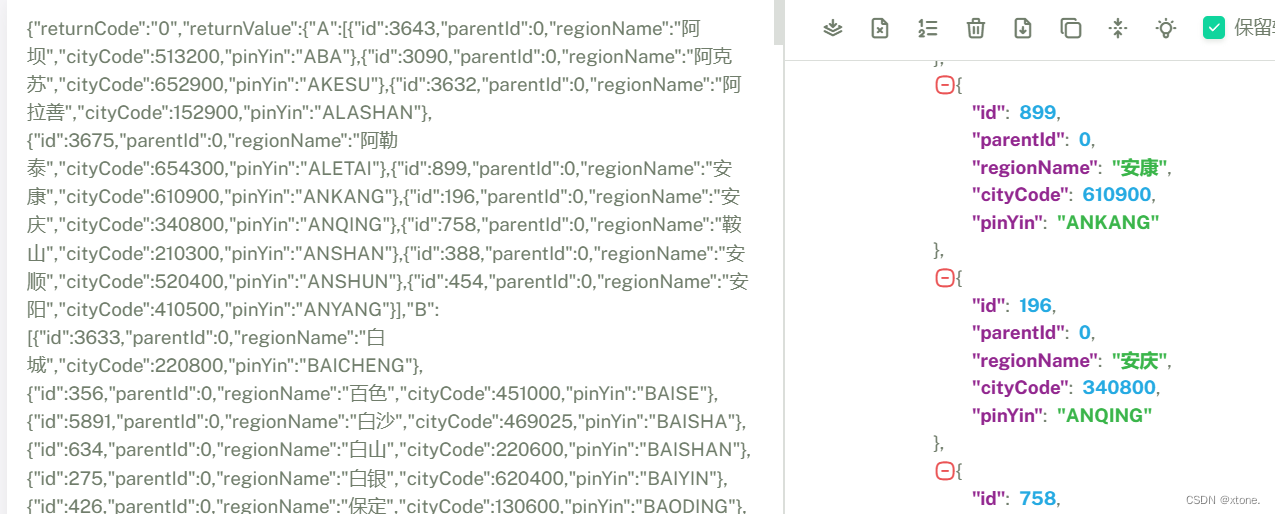
我们需要将jsonp138()删除

我们就可以获取到我们想要数据了
我们使用代码来实现该功能
我们使用split函数
split('(')[1].split(')')[0]
以(切割成两块,保留第二块
以)切割成两块,保留第一块
import urllib.request
url = 'https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1629789477003_137&jsoncallback=jsonp138&action=cityAction&n_s=new&event_submit_doGetAllRegion=true'
headers = {
# ':authority': 'dianying.taobao.com',
# ':method': 'GET',
# ':path': '/cityAction.json?activityId&_ksTS=1629789477003_137&jsoncallback=jsonp138&action=cityAction&n_s=new&event_submit_doGetAllRegion=true',
# ':scheme': 'https',
'accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
# 'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9',
'cookie': 'cna=UkO6F8VULRwCAXTqq7dbS5A8; miid=949542021157939863; sgcookie=E100F01JK9XMmyoZRigjfmZKExNdRHQqPf4v9NIWIC1nnpnxyNgROLshAf0gz7lGnkKvwCnu1umyfirMSAWtubqc4g%3D%3D; tracknick=action_li; _cc_=UIHiLt3xSw%3D%3D; enc=dA18hg7jG1xapfVGPHoQCAkPQ4as1%2FEUqsG4M6AcAjHFFUM54HWpBv4AAm0MbQgqO%2BiZ5qkUeLIxljrHkOW%2BtQ%3D%3D; hng=CN%7Czh-CN%7CCNY%7C156; thw=cn; _m_h5_tk=3ca69de1b9ad7dce614840fcd015dcdb_1629776735568; _m_h5_tk_enc=ab56df54999d1d2cac2f82753ae29f82; t=874e6ce33295bf6b95cfcfaff0af0db6; xlly_s=1; cookie2=13acd8f4dafac4f7bd2177d6710d60fe; v=0; _tb_token_=e65ebbe536158; tfstk=cGhRB7mNpnxkDmUx7YpDAMNM2gTGZbWLxUZN9U4ulewe025didli6j5AFPI8MEC..; l=eBrgmF1cOsMXqSxaBO5aFurza77tzIRb8sPzaNbMiInca6OdtFt_rNCK2Ns9SdtjgtfFBetPVKlOcRCEF3apbgiMW_N-1NKDSxJ6-; isg=BBoas2yXLzHdGp3pCh7XVmpja8A8S54lyLj1RySTHq14l7vRDNufNAjpZ2MLRxa9',
'referer': 'https://dianying.taobao.com/',
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'sec-ch-ua-mobile': '?0',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
'x-requested-with': 'XMLHttpRequest',
}
request = urllib.request.Request(url = url, headers = headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
# split 切割
content = content.split('(')[1].split(')')[0]
#默认打开的是编码格式是gbk格式,在打开时我们需要指定编码格式,utf-8
with open('074_尚硅谷_爬虫_解析_jsonpath解析淘票票.json','w',encoding='utf-8')as fp:
fp.write(content)
import json
import jsonpath
obj = json.load(open('074_尚硅谷_爬虫_解析_jsonpath解析淘票票.json','r',encoding='utf-8'))
city_list = jsonpath.jsonpath(obj,'$..regionName')
print(city_list)
BeautifulSoup
1.基本简介
1.BeautifulSoup简称:
bs4
2.什么是BeatifulSoup?
BeautifulSoup,和lxml一样,是一个html的解析器,主要功能也是解析和提取数据
3.优缺点?
缺点:效率没有lxml的效率高
优点:接口设计人性化,使用方便
2.安装以及创建
1.安装
pip install bs4
2.导入
from bs4 import BeautifulSoup
3.创建对象
服务器响应的文件生成对象
soup = BeautifulSoup(response.read().decode(), 'lxml')
本地文件生成对象
soup = BeautifulSoup(open('1.html'), 'lxml')
注意:默认打开文件的编码格式gbk所以需要指定打开编码格式
3.节点定位
1.根据标签名查找节点
soup.a 【注】只能找到第一个a
soup.a.name
soup.a.attrs
2.函数
(1).find(返回一个对象)
find('a'):只找到第一个a标签
find('a', title='名字')
find('a', class_='名字')
(2).find_all(返回一个列表)
find_all('a') 查找到所有的a
find_all(['a', 'span']) 返回所有的a和span
find_all('a', limit=2) 只找前两个a
(3).select(根据选择器得到节点对象)【推荐】
1.element
eg:p
2..class
eg:.firstname
3.#id
eg:#firstname
4.属性选择器
[attribute]
eg:li = soup.select('li[class]')
[attribute=value]
eg:li = soup.select('li[class="hengheng1"]')
5.层级选择器
element element
div p
element>element
div>p
element,element
div,p
eg:soup = soup.select('a,span')
示例:
我们先创建一个html文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div>
<ul>
<li id="l1">张三</li>
<li id="l2">李四</li>
<li>王五</li>
<a href="" id="" class="a1">尚硅谷</a>
<span>嘿嘿嘿</span>
</ul>
</div>
<a href="" title="a2">百度</a>
<div id="d1">
<span>
哈哈哈
</span>
</div>
<p id="p1" class="p1">呵呵呵</p>
</body>
</html>
基于上面的html文件我们使用bs4
from bs4 import BeautifulSoup
# 通过解析本地文件 来将bs4的基础语法进行讲解
# 默认打开的文件的编码格式是gbk 所以在打开文件的时候需要指定编码
soup = BeautifulSoup(open('075_尚硅谷_爬虫_解析_bs4的基本使用.html',encoding='utf-8'),'lxml')
# 根据标签名查找节点
# 找到的是第一个符合条件的数据
# print(soup.a)
# 获取标签的属性和属性值
# print(soup.a.attrs)
# bs4的一些函数
# (1)find
# 返回的是第一个符合条件的数据
# print(soup.find('a'))
# 根据title的值来找到对应的标签对象
# print(soup.find('a',title="a2"))
# 根据class的值来找到对应的标签对象 注意的是class需要添加下划线
# print(soup.find('a',class_="a1"))
# (2)find_all 返回的是一个列表 并且返回了所有的a标签
# print(soup.find_all('a'))
# 如果想获取的是多个标签的数据 那么需要在find_all的参数中添加的是列表的数据
# print(soup.find_all(['a','span']))
# limit的作用是查找前几个数据
# print(soup.find_all('li',limit=2))
# (3)select(推荐)
# select方法返回的是一个列表 并且会返回多个数据
# print(soup.select('a'))
# 可以通过.代表class 我们把这种操作叫做类选择器
# print(soup.select('.a1'))
# print(soup.select('#l1'))
# 属性选择器---通过属性来寻找对应的标签
# 查找到li标签中有id的标签
# print(soup.select('li[id]'))
# 查找到li标签中id为l2的标签
# print(soup.select('li[id="l2"]'))
# 层级选择器
# 后代选择器
# 找到的是div下面的li
# print(soup.select('div li'))
# 子代选择器
# 某标签的第一级子标签
# 注意:很多的计算机编程语言中 如果不加空格不会输出内容 但是在bs4中 不会报错 会显示内容
# print(soup.select('div > ul > li'))
# 找到a标签和li标签的所有的对象
# print(soup.select('a,li'))
# 节点信息
# 获取节点内容
# obj = soup.select('#d1')[0]
# 如果标签对象中 只有内容 那么string和get_text()都可以使用
# 如果标签对象中 除了内容还有标签 那么string就获取不到数据 而get_text()是可以获取数据
# 我们一般情况下 推荐使用get_text()
# print(obj.string)
# print(obj.get_text())
# 节点的属性
# obj = soup.select('#p1')[0]
# name是标签的名字
# print(obj.name)
# 将属性值左右一个字典返回
# print(obj.attrs)
# 获取节点的属性
obj = soup.select('#p1')[0]
print(obj.attrs.get('class'))
print(obj.get('class'))
print(obj['class'])














 2383
2383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









