







第十四讲:字符函数和字符串函数
总结:
这一讲讲的全部是关于字符和字符串的一系列函数
1.字符分类函数
1.1函数简介
字符分类函数是一系列函数,他们是c语言中专门做字符分类的,他们都被包含在一个头文件<ctype.c>中,以下是这些字符分类函数:

1.2函数讲解
这些函数的使用十分相似,所以我们只单独对一个函数进行详细讲解,抽取的这个函数为:islower
- 函数原型:

- 函数参数和返回值:
函数参数:这个函数的参数为int类型的参数,所以我们可以将字符\字符的ASCII码值传入
函数返回值:函数返回值为int类型,如果参数是小写字符的话就返回非0值,如果为小写字符的话就返回0
1.3函数使用
下面我们来看这个函数是如何使用的:
//1.3函数使用
#include <ctype.h>
int main()
{
int ret1 = islower('a'); //传入字符
printf("%d\n", ret1);
int ret2 = islower(97); //传入ASCII码值
printf("%d\n", ret1);
//上面的ret1和ret2的结果是相同的,都是非0值
int ret3 = islower('A');
printf("%d\n", ret3);
//这时传入的是一个大写字符,所以ret3的结果为0
return 0;
}
1.4练习
写⼀个代码,将字符串中的⼩写字⺟转⼤写,其他字符不变:
//写⼀个代码,将字符串中的⼩写字⺟转⼤写,其他字符不变。
//解析:
//1.要判断是否为小写字符
//2.在是小写字符的情况下,将小写字符转换成大写字符
//3.转换条件:小写字符的ASCII码值-32就是大小字符的ASCII码值
int main()
{
char arr[] = "Hello World";
for (int i = 0; i < strlen(arr); i++)
{
if (islower(*(arr + i)))
*(arr + i) -= 32;
}
printf("%s\n", arr);
return 0;
}
2.字符转换函数
在上一个练习中,为了实现字符大小写转换,使用了ASCII码值-32的方法,而在c语言中,提供了两个字符转换函数它们被包含在头文件<ctype.h>中:
int tolower ( int c ); //将参数传进去的⼤写字⺟转⼩写
int toupper ( int c ); //将参数传进去的⼩写字⺟转⼤写
所以要再进行大小写转换时,就可以这样写:
//字符转换函数实现小写转大写
int main()
{
char arr[] = "Hello World";
for (int i = 0; i < strlen(arr); i++)
*(arr+i) = toupper(*(arr + i));
printf("%s\n", arr);
return 0;
}
由于在之前已经讨论过以下多数函数的使用,所以在这里只进行总结和函数实现的详解
3.strlen函数的使用和模拟实现
3.1函数原型:
size_t strlen ( const char * str );
3.2使用注意点:
- 字符串以 ‘\0’ 作为结束标志,strlen函数返回的是在字符串中 ‘\0’ 前⾯出现的字符个数(不包含 ‘\0’ )
- 参数指向的字符串必须要以 ‘\0’ 结束
- 注意函数的返回值为 size_t,是⽆符号的( 易错 ),在这里进行易错点讲解:
//3.strlen函数的使用易错点
int main()
{
char arr1[] = "abc";
char arr2[] = "abcd";
if (strlen(arr1) - strlen(arr2) > 0)
printf(" >0 \n"); //√
else
printf(" <=0 \n"); //×
return 0;
}
//错误讲解:
//strlen的返回值为size_t类型,是一种无符号整形,strlen(arr1) - strlen(arr2)的结果为无符号整形的-1,对于-1:
//原码:10000000000000000000000000000001
//反码:11111111111111111111111111111110
//补码:11111111111111111111111111111111
//在进行比较时,会将-1的补码值和0进行比较,显然,-1的补码的值非常大!
所以我们在使用过程中可以进行转换:
//转化:
int main()
{
char arr1[] = "abc";
char arr2[] = "abcd";
if (strlen(arr1) > strlen(arr2))
printf(" >0 \n");
else
printf(" <=0 \n");
return 0;
}
- strlen的使⽤需要包含头⽂件<string.h>
3.3strlen函数的模拟实现
strlen函数的模拟实现方法不一,下面仅仅展示三种实现方法:
//3.3.1方法1(计数器的方法)
int MyStrlen1(const char *pa)
{
//先防止空指针的出现
assert(pa != NULL);
int count = 0; //进行计数
while (*pa++)
count++;
return count;
}
//3.3.1方法2(指针-指针的方法)
int MyStrlen2(char* pa)
{
//先防止空指针的出现
assert(pa != NULL);
char* start = pa;
while (*pa)
pa++;
return pa - start;
}
//3.3.3方法3(递归的方法)(如果要求不能创建临时变量求出字符串长度可以使用)
int MyStrlen3(char* pa)
{
//先防止空指针的出现
assert(pa != NULL);
if (*pa)
return 1 + MyStrlen3(pa + 1);
else
return 0;
}
int main()
{
char arr[] = "abcde";
int ret1 = MyStrlen1(arr);
printf("ret1 = %d\n", ret1);
int ret2 = MyStrlen2(arr);
printf("ret1 = %d\n", ret2);
int ret3 = MyStrlen3(arr);
printf("ret3 = %d\n", ret3);
return 0;
}
4.strcpy函数的使用和模拟实现
4.1函数原型
char* strcpy(char * destination, const char * source );
4.2使用注意点
- 将源字符串拷贝到目标空间上,包括\0,这里的\0是停止拷贝的条件
- 源字符串必须以\0结尾
- 目标空间必须足够大, 确保能够放下源字符串
- 目标空间必须可修改
4.3strcpy函数的模拟实现
//4.3strcpy函数的模拟实现
char *MyStrcpy(char* pa, const char* pb)
{
char* start = pa;
//防止pa和pb为空指针
assert(pa && pb);
while (*pb)
{
*pa = *pb;
pa++;
pb++;
}
*pa = '\0';
return start;
}
int main()
{
char arr1[20] = "xxxxxxxxx";
char arr2[] = "abcde";
char *a = MyStrcpy(arr1, arr2);
printf("%s\n", a);
return 0;
}
但是这一串代码可以优化:
//4.3strcpy函数的模拟实现(优化版)
char* MyStrcpy(char* pa, const char* pb)
{
char* start = pa;
//防止pa和pb为空指针
assert(pa && pb);
//while (*pb)
//{
// *pa = *pb;
// pa++;
// pb++;
//}
while (*pa++ = *pb++)
;
*pa = '\0';
return start;
}
int main()
{
char arr1[20] = "xxxxxxxxx";
char arr2[] = "abcdedfs";
char* a = MyStrcpy(arr1, arr2);
printf("%s\n", a);
return 0;
}
5.strcat函数的使用和模拟实现
5.1函数原型

5.2使用注意事项
- 该函数是将源字符串追加到目标字符串的末尾的函数,并且会将源字符串中的\0也进行追加,追加规则是将源字符串的初始字符覆盖到目标字符串的终止字符,即\0
- 源字符串必须以\0终止
- 目标字符串中也必须要有\0,否则不知道要在哪进行追加
- ⽬标空间必须有⾜够的⼤,能容纳下源字符串的内容
- ⽬标空间必须可修改
- 字符串⾃⼰给⾃⼰追加,会造成内存溢出的问题,因为自己给自己追加的话会覆盖字符串末尾的\0,再在末尾加上一个\0,这样就会导致目标字符串的长度不断增加,最终超出其分配的空间,导致内存溢出
5.3strcat函数的模拟实现
//5.3strcat函数的模拟实现
char* MyStrcat(char* pa, const char* pb)
{
char* start = pa;
assert(pa && pb);
//先找到目标字符串\0的位置
while (*pa)
pa++;
while (*pa++ = *pb++)
;
*pa = '\0';
return start;
}
int main()
{
char arr1[20] = "abc";
char arr2[] = "bcdsfd";
char *a = MyStrcat(arr1, arr2);
printf("%s\n", a);
return 0;
}
6.strcmp函数的使用和模拟实现
6.1函数原型
int strcmp( const char *string1, const char *string2 );
6.2函数使用注意事项
- 该函数是逐个字符进行比较的,直到遇到不同或者\0
- 对于函数返回值:
1.若str1 < str2,返回的是一个负值
2.若str1 > str2,返回的是一个正值
3.若str1 = str2,返回值是0 - 比较时比较的是字符的ASCII码值
6.3strcmp函数的模拟实现
//6.3strcmp函数的模拟实现(方法1)
int MyStrcmp1(const char* pa, const char* pb)
{
assert(pa && pb);
while (*pa || *pb)
{
if (*pa > *pb)
return 1;
else if (*pa < *pb)
return -1;
pa++;
pb++;
}
if (*pa == '\0' && *pb)
return -1;
else if (*pb == '\0' && *pa)
return 1;
else
return 0;
}
//6.3strcmp函数的模拟实现(优化)
int MyStrcmp2(const char* pa, const char* pb)
{
assert(pa && pb);
while (*pa == *pb)
{
if (*pa == '\0')
return 0;
pa++;
pb++;
}
return *pa - *pb;
}
int main()
{
char arr1[] = "abc";
char arr2[] = "abc";
int ret1 = strcmp(arr1, arr2);
printf("ret1 = %d\n", ret1);
int ret2 = MyStrcmp1(arr1, arr2);
printf("ret1 = %d\n", ret2);
int ret3 = MyStrcmp2(arr1, arr2);
printf("ret1 = %d\n", ret3);
return 0;
}
7.strncpy函数的使用及模拟实现
以下要讲的三个函数都是上述某个对应函数的变形,所以只将其中一个函数进行详细的解析:strncpy
7.1函数原型
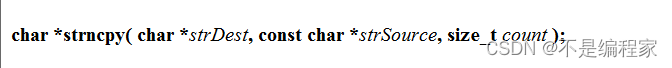
strncpy函数的功能是拷贝源字符串中的前count个字符至目标空间,包含在头文件<string.h>中,返回的是目标字符串的首地址
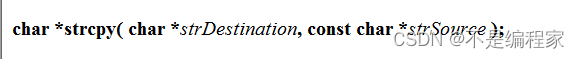
相比于strcpy函数,strncpy函数多了一个size_t类型的count参数,这个参数的作用是点名要加几个字符
7.2函数的使用
//7.2函数的使用
int main2()
{
char arr1[20] = "xxxxxxxxxxxx";
char arr2[] = "abcdef";
char* a = strncpy(arr1, arr2, 3); //abcxxxxxxxxx
//函数作用为将arr2前三个字符拷贝到arr1上
printf("%s\n", a);
return 0;
}
7.3函数使用注意事项
- 当源字符串要拷贝的长度小于目标字符串时,将源字符串前n个字符进行拷贝,但不会拷贝\0
- 当元字符的拷贝长度大于目标字符串时,会在后边添加\0,直到n个
7.4strncpy函数的模拟实现
//7.4strncpy函数的实现
char* Mystrncpy(char* pa, const char* pb, size_t len)
{
assert(pa && pb);
char* start = pa;
for (int i = 0; i < len; i++)
{
*pa = *pb;
pa++;
pb++;
}
return start;
}
int main()
{
char arr1[20] = "xxxxxx";
char arr2[] = "abef";
char* a = strncpy(arr1, arr2, 3);
printf("%s\n", a);
char* b = Mystrncpy(arr1, arr2, 3);
printf("%s\n", b);
return 0;
}
8.strncat函数的使用
8.1函数原型
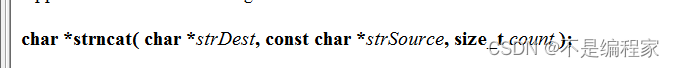
8.2函数使用注意事项
- 该函数是将源字符串的前n个字符覆(首字符同样要覆盖源字符串的\0)加到目标字符串的末尾,并且会追加一个\0
- 如果源字符串的长度小于n,只会将源字符串中到\0的内容追加到目标地址末尾
9.strncmp函数的使用
9.1函数原型
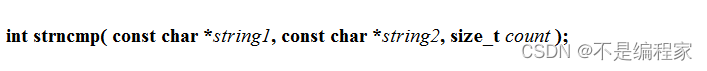
9.2函数使用注意事项
- 该函数是比较两个字符串的前n项
- 该函数的返回值和strcmp函数的返回值相同
10.strstr函数的使用和注意事项
10.1函数原型
char *strstr( const char *string, const char *strCharSet );
10.2函数使用注意事项
- 该函数的功能是查找子字符串(str2)在一个字符串(str1)中首次出现的位置,并返回该位置的指针,如果找不到,就返回null
- 字符
串的⽐较匹配不包含 \0 字符,以 \0 作为结束标志
10.3strstr函数的模拟实现
//10.3strstr函数的模拟实现
char* MyStrstr(const char* pa, const char* pb)
{
//首先先防止空指针
assert(pa && pb);
const char* moa1 = pa;
const char* moa2 = NULL;
const char* mob = NULL;
//这是一个特殊情况,当pb传入的是一个空指针时,直接返回NULL
if (*pb == '\0')
return NULL;
while (*moa1)
{
moa2 = moa1;
mob = pb;
while (*moa2 && *mob && *moa2 == *mob)
{
moa2++;
mob++;
}
if (*mob == '\0')
return moa1;
moa1++;
}
return NULL;
}
int main()
{
char arr1[] = "abcdefghi";
char arr2[] = "def";
char* a1 = strstr(arr1, arr2);
printf("a1 = %s\n", a1);
char* a2 = MyStrstr(arr1, arr2);
printf("a1 = %s\n", a2);
return 0;
}
11.strtok函数的使用
11.1函数原型
该函数的作用是查找字符串中的下一个标记,函数原型如下:
char *strtok( char *strToken, const char *strDelimit );
1.strDelimit这个参数指向的是分隔符的集合
2.strToken指向的是要查找的字符串,这个字符串中包含了一个或多个分隔符
3.strtok函数会将找到的分隔符进行标记,并将其改成\0,返回的是该字符串的首地址,如果没有找到分隔符,或者参数不合法,则返回NULL
11.2函数的使用
//11.2函数的使用
int main()
{
char arr1[] = "abc.def*g.eh"; //目标字符串
char arr2[] = ".*"; //分隔符的合集
char *a1 = strtok(arr1, arr2); //abc
//函数会找到第一个分隔符,并将分隔符替换成\0,返回这串字符的首地址(不是目标字符整个的首地址)
printf("a1 = %s\n", a1);
char* a2 = strtok(NULL, arr2); //def
printf("a2 = %s\n", a2);
char* a3 = strtok(NULL, arr2); //g
printf("a3 = %s\n", a3);
char* a4 = strtok(NULL, arr2); //eh
printf("a4 = %s\n", a4);
char* a5 = strtok(NULL, arr2); //(null)
//当找不到目标字符时,返回NULL
printf("a5 = %s\n", a5);
char* a6 = strtok(arr1, arr2); //abc
//strtok函数第一个参数不为NULL,函数会找到第一个被切割的字符串
printf("a6 = %s\n", a6);
char* a7 = strtok(NULL, arr2); //(null)
//strtok函数的第一个参数为NULL,函数会找到记住的分隔符的位置,查找下一个分隔符
printf("a7 = %s\n", a7);
return 0;
}
11.3函数使用注意事项
- strtok函数不是线程安全的,因为它会使用一个静态变量来存储上次切割的位置,如果使用多个线程同时调用strtok函数,可能会出现错误
- strtok函数第一个参数不为NULL,函数会找到第一个被切割的字符串
- strtok函数的第一个参数为NULL,函数会找到记住的分隔符的位置,查找下一个分隔符
11.4函数的进阶使用
当我们不知道原来字符串的样子,但是还想要将其中的一些字符剔除的话,就需要加上循环来使用
//11.4函数的进阶使用
int main()
{
char arr1[] = "abc.defg.eh"; //目标字符串
char arr2[] = "."; //分隔符的合集
char *a = strtok(arr1, arr2);
while (a)
{
printf("%s ", a);
a = strtok(NULL, arr2); //abc defg eh
}
return 0;
}
这串代码可以进行优化:
int main()
{
char arr1[] = "abc.defg.eh"; //目标字符串
char arr2[] = "."; //分隔符的合集
//char* a = strtok(arr1, arr2);
//while (a)
//{
// printf("%s ", a);
// a = strtok(NULL, arr2); //abc defg eh
//}
for (char* a = strtok(arr1, arr2); a != NULL; a = strtok(NULL, arr2))
printf("%s ", a); abc defg eh
return 0;
}
12.strerror函数的使用
在不同的系统和C语言实现的标准库中都规定了一系列的错误码,一般是放在error.h这个头文件中进行说明。
每当程序启动的时候就会使用一个全局变量errno来记录当前的错误码,刚启动是errno值为0,表示没有错误,当我们在使用标准库中的函数出错了,就会将对应的错误码放在errno中,而strerror函数就会将错误码对应的错误信息进行返回,使用者可以通过打印来观察到底是哪个地方出错了
12.1函数原型
char *strerror( int errnum );
函数参数:errnum就相当于errno,也就是错误码
函数返回值:一个错误码对应一句错误信息,该函数返回的是错误码指向的错误信息的指针,指针指向的通常是一个常量字符串,所以不能够尝试修改
函数头文件,该函数包含在头文件<string.h>中,而errno包含在头文件<errno.h>中
12.2函数使用
12.2.1尝试使用
我们尝试将错误码为0-9的错误信息进行打印:
//12.2函数使用
#include <string.h>
int main()
{
for (int i = 0; i < 10; i++)
{
printf("%d : %s\n", i, strerror(i));
}
return 0;
}
程序运行结果为:
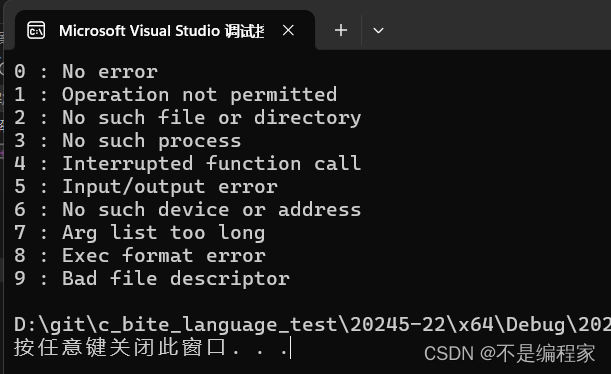
但是,错误信息所指向的错误码并不是连续的,也就是说,0-9错误码对应着有错误信息,但是10-20就不确定有没有对应的错误信息
12.2.2strerror函数基本用法
下面我们来介绍函数的简单用法:
//假设我们要打开一个并不存在的文件,并显示给出错误信息
#include <errno.h> //使用全局变量errno,要引用头文件
int main()
{
FILE* fp = fopen("test.txt", "r"); //这串代码表示打开test.txt文件
if (fp == NULL)
printf("文件打开失败,失败原因为:%s\n", strerror(errno));
else
printf("打开成功\n");
return 0;
}
这串代码的结果为:

这样我们就可以查看原因了✌
12.3对于errno
- errno是一个全局变量,包含在头文件<errno.h>中,用于存储最近一次系统调用的错误码
- 当系统调用失败时,会设置errno变量并返回一个特殊的返回值,来展示错误类型
- errno变量是一个线程本地存储的变量,不同线程之间的errno变量是独立的,再多线程的程序中,要注意errno的使用
下面是AI举例来说明errno常见的一些错误码及含义:
1. **EPERM (1)** - 操作不允许
2. **ENOENT (2)** - 没有找到文件或目录
3. **ESRCH (3)** - 没有找到进程
4. **EINTR (4)** - 系统调用被中断
5. **EIO (5)** - 输入/输出错误
6. **ENXIO (6)** - 设备不存在或无响应
7. **E2BIG (7)** - 参数列表太长
8. **ENOEXEC (8)** - 执行格式错误
9. **EBADF (9)** - 无效的文件描述符
10. **ECHILD (10)** - 没有子进程
11. **EAGAIN (11)** - 资源暂时不可用,或操作会阻塞
12. **ENOMEM (12)** - 内存不足
13. **EACCES (13)** - 权限拒绝
14. **EFAULT (14)** - 错误的地址
15. **ENOTBLK (15)** - 不是块设备
16. **EBUSY (16)** - 设备或资源忙
17. **EEXIST (17)** - 文件已存在
18. **EXDEV (18)** - 跨设备链接
19. **ENODEV (19)** - 没有设备
20. **ENOTDIR (20)** - 不是目录
21. **EISDIR (21)** - 是目录
22. **EINVAL (22)** - 无效的参数
23. **ENFILE (23)** - 文件表已满
24. **EMFILE (24)** - 进程打开文件太多
25. **ENOTTY (25)** - 不适当的寻求
26. **ETXTBSY (26)** - 文本文件忙
27. **EFBIG (27)** - 文件太大,不能打开
28. **ENOSPC (28)** - 没有空间
29. **ESPIPE (29)** - 非法的寻道
30. **EROFS (30)** - 只读文件系统
31. **EMLINK (31)** - 太多链接
32. **EPIPE (32)** - 破裂的管道
33. **EDOM (33)** - 数学函数域错误
34. **ERANGE (34)** - 数学函数结果超出范围
35. **EDEADLK (35)** - 死锁条件
36. **ENAMETOOLONG (36)** - 文件名太长
37. **ENOLCK (37)** - 没有可用的锁
38. **ENOSYS (38)** - 功能未实现
39. **ENOTEMPTY (39)** - 目录非空
40. **ELOOP (40)** - 符号链接太多
41. **EWOULDBLOCK (11)** - 与EAGAIN相同,操作会阻塞
42. **EADDRINUSE (98)** - 地址已在使用中
43. **ECONNREFUSED (107)** - 连接被拒绝
44. **EHOSTUNREACH (113)** - 主机不可达
12.4perror函数
对于strerror函数,在使用时不会自动打印出错误原因,要使用printf函数来辅助打印,所以我们可以了解可以直接打印错误信息的一个函数:perror
12.4.1函数原型
void perror( const char *string );
参数:string是一个字符串,用于在错误信息之前输出一段自定义的字符串
返回值:函数没有返回值
12.4.2函数使用方法
首先打印字符串,然后是冒号,然后是产生错误的最后一个库调用的系统错误消息,最后是换行符。如果string是空指针或指向空字符串的指针,perror只打印系统错误消息,以及一个换行符。
int main()
{
FILE* fp = fopen("test.txt", "r"); //这串代码表示打开test.txt文件
if (fp == NULL)
{
printf("文件打开失败,失败原因为:%s\n", strerror(errno));
perror("");
//string是一个指向空字符串的指针,perror只打印系统错误消息,以及一个换行符
perror("文件打开失败,失败原因为");
//首先打印字符串,然后是冒号,然后是产生错误的最后一个库调用的系统错误消息,最后是换行符
}
else
printf("打开成功\n");
return 0;
}
最后的结果为:
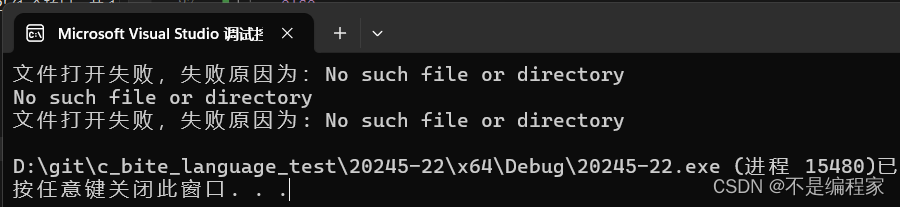
要注意的是:在使用strerror函数和perror函数时,都要尽量在库例程返回错误后立即调用,以便获得精确的错误原因,否则,后续进程可能会改变errno的值
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









