







以下是DeepSeek-R1本地部署及接入PyCharm的详细步骤指南,整合了视频内容及官方文档核心要点:
一、本地部署DeepSeek-R1模型
1. 安装Ollama框架
- 下载安装包
访问Ollama官网(https://ollama.com/download)Windows用户选择.exe文件,macOS用户选择.dmg包。
- 安装验证
双击安装包完成安装后,打开命令行工具(CMD/PowerShell)输入:
若显示版本号(如ollama -vollama version is 0.5.7),则安装成功。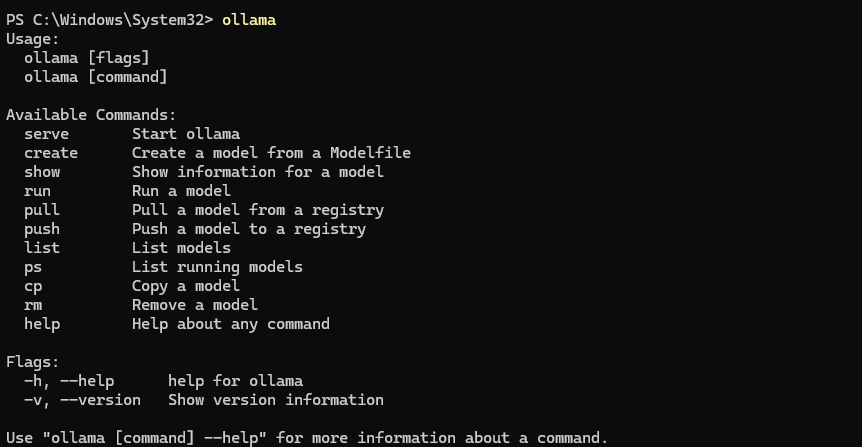
2. 下载DeepSeek-R1模型
- 选择模型版本
根据硬件配置选择合适模型 - 模型链接(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2046
2046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











