







欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
一项目简介
一、项目背景与意义
OCR(Optical Character Recognition,光学字符识别)技术是一种将图像中的文本转换为可编辑和可搜索的文本格式的技术。这种技术在许多领域都有广泛的应用,如文档数字化、数据提取、自动化处理等。基于Python+PyQt5编写的OCR文字识别软件充分利用了这两种技术的优势,为用户提供了一个直观、易用的界面,并通过调用先进的OCR算法,实现了对图像中文本的快速、准确识别。
二、技术原理与实现
该项目主要使用Python编程语言进行开发,利用PyQt5库创建图形用户界面(GUI)。PyQt5是一个跨平台的GUI工具包,它基于Qt库并提供了一组丰富的控件和布局管理器,使得开发者能够轻松地构建出美观、易用的界面。
在OCR算法方面,该项目可以调用多种OCR引擎,如Tesseract、Google Cloud Vision、百度OCR等。这些OCR引擎都经过了大量的优化和训练,能够识别多种语言、字体和图像背景的文本。通过调用这些OCR引擎的API,该项目可以实现对图像中文本的自动检测和识别。
具体来说,该项目的实现流程如下:
用户通过图形用户界面选择待识别的图像文件。
程序调用OCR引擎的API,将图像文件传输到OCR服务器进行处理。
OCR服务器对图像进行预处理、文本检测和识别等操作,并返回识别结果。
程序将识别结果以文本形式展示给用户,并提供复制、导出等功能。
三、功能特点
基于Python+PyQt5编写的OCR文字识别软件具有以下功能特点:
跨平台性:支持Windows、Linux和Mac OS X等多种操作系统。
易用性:提供直观的图形用户界面,用户无需编写代码即可进行图像文本识别。
高效性:通过调用先进的OCR引擎API,实现对图像中文本的快速、准确识别。
灵活性:支持多种OCR引擎的选择和切换,可以根据不同需求选择最适合的OCR引擎。
扩展性:提供API接口和文档,方便开发者进行二次开发和定制。
二、功能
基于Python+PyQt5编写的OCR文字识别软件全套代码
三、系统
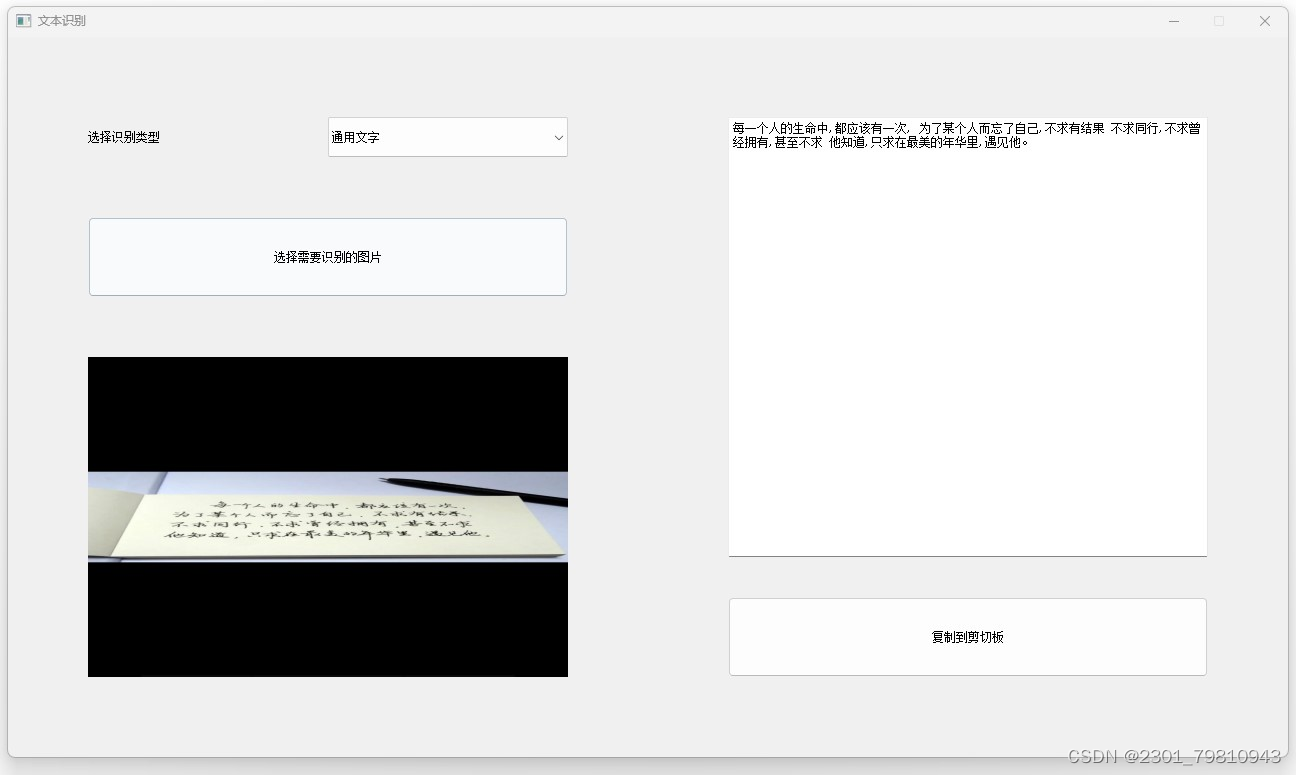
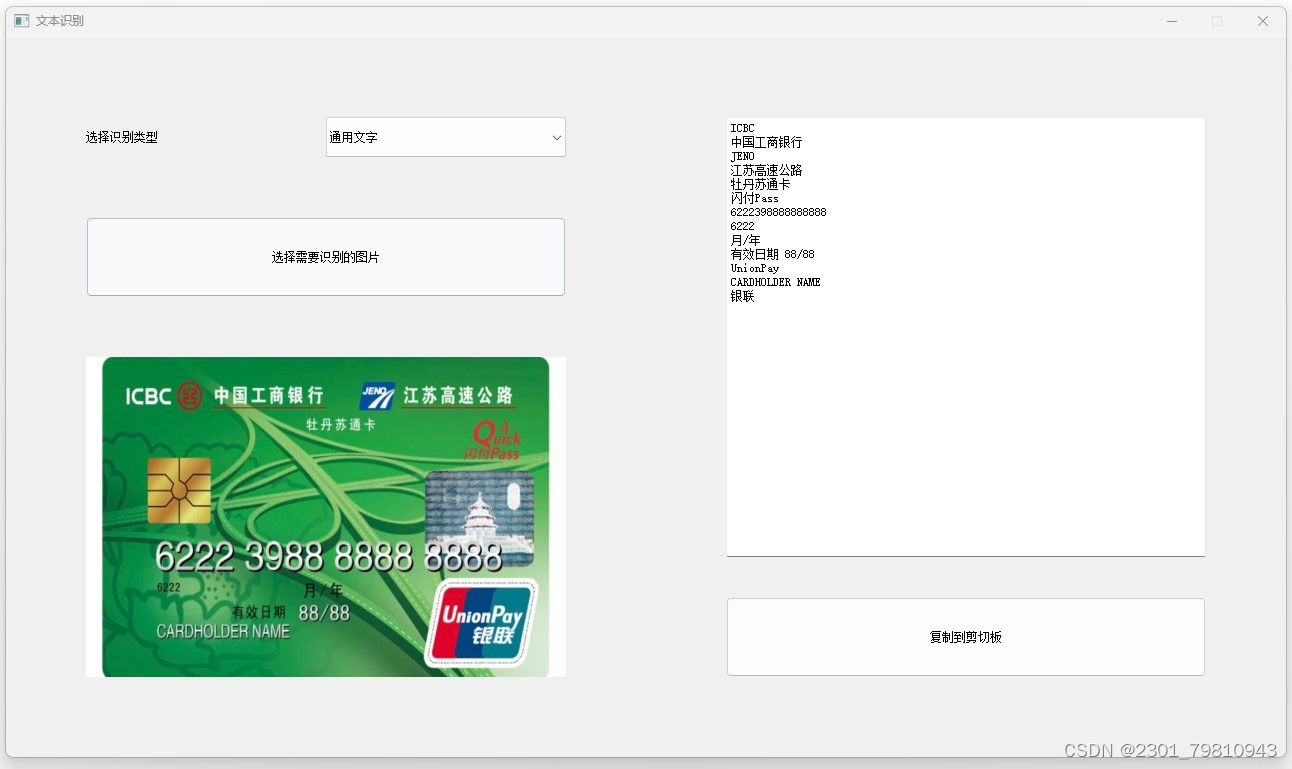
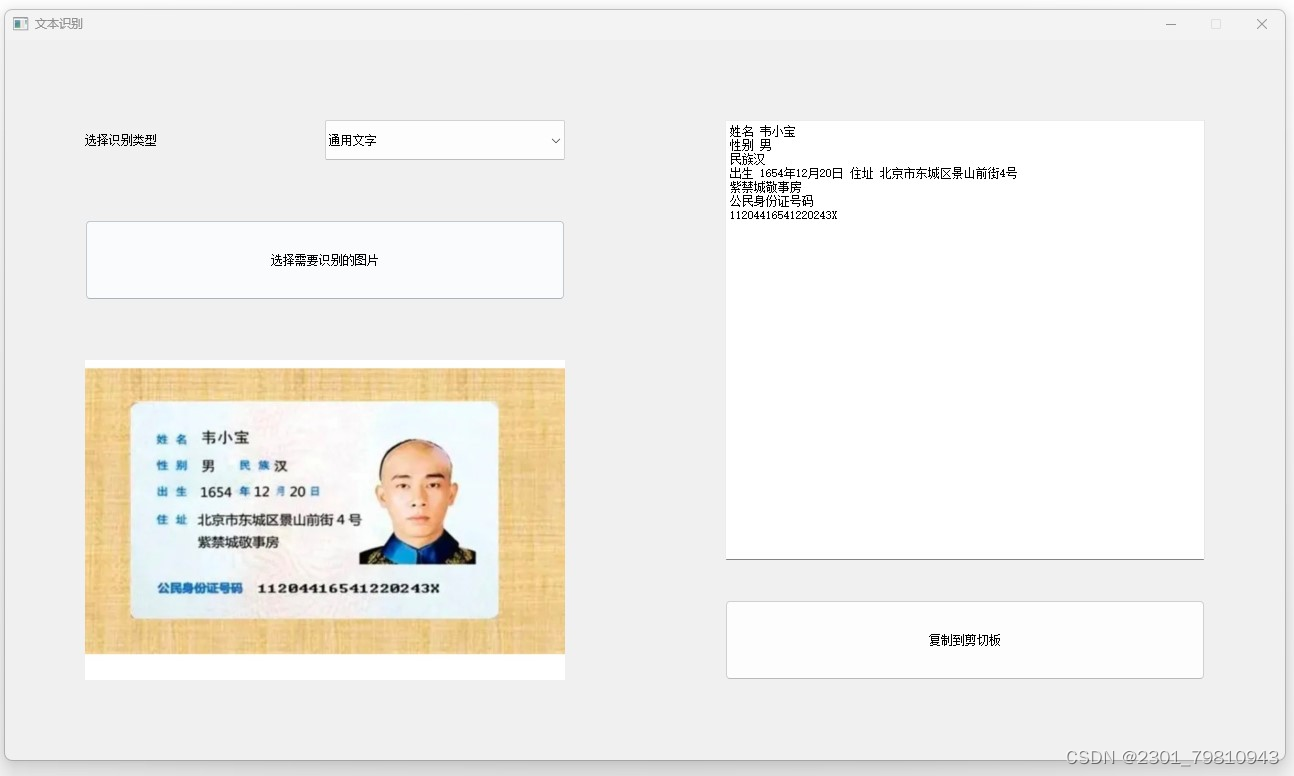
四. 总结
文档数字化:将纸质文档转换为可编辑和可搜索的电子文档。
数据提取:从图像中提取关键信息,如身份证号、银行卡号、发票信息等。
自动化处理:结合其他自动化工具,实现对图像中文本的自动处理和分析。
学术研究:用于历史文献、古籍等资料的数字化和整理。
总之,基于Python+PyQt5编写的OCR文字识别软件是一个功能强大、易于使用的工具,可以极大地提高用户从图像中提取和识别文本的效率。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









