









收藏和点赞,您的关注是我创作的动力
概要
本文设计了一个动物智能识别系统,采用YOLOv4和Mobilenetv2-YOLOv4算法对上传的图片、视频以及摄像头录入的画面进行特定动物种类的目标检测。在图像识别模块中,本文采用了YOLOv4算法对动物图像进行识别。在视频识别模块和摄像头识别模块中,为了进一步提高算法的识别速度,使用轻量级神经网络Mobilenetv2作为YOLOv4的新主干网络,并改进了模型中的部分标准卷积,显著地提升了模型的运算速率。本文通过Pytorch框架搭建了YOLOv4和Mobilenetv2-YOLOv4模型,并分别使用COCO动物数据集和VOC动物数据集对两个模型进行训练。在本文测试环境下,YOLOv4和Mobilenetv2-YOLOv4在各自测试集上的mAP分别可以达到88.73%和78.33%。而在检测速度对比上,YOLOv4和·原文对照报告· ·研究生版·Mobilenetv2-YOLOv4的平均检测速度分别可以达到1.26张/秒和5.37张/秒。
最后本文通过Flask框架搭建了本地网站,部署了两种目标检测模型。实现了对用户上传的图像、视频以及摄像头录入的画面进行动物目标识别的功能,并可以在前端页面展示最后的检测结果。
关键词:动物识别;目标检测;YOLOv4;Mobilenetv2
一、基于YOLOv4的动物图像检测
3.1 YOLOv4网络结构
YOLOv4 对YOLOv3做出了进一步的改进。YOLOv4网络结构可以分为输入层、主干特征提取网络、Neck层和预测层。整体网络结构可以用下图3.1描述:
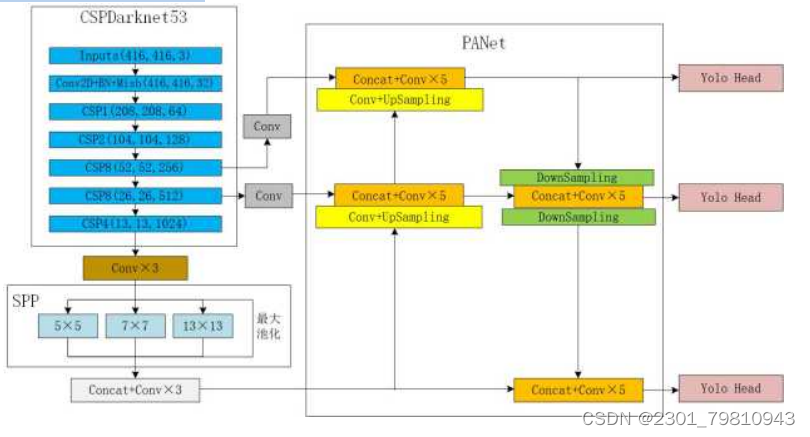
图3.1 YOLOv4网络结构
3.1.1 输入层
YOLOv4在输入层使用了Mosaic数据增强的方法。其原理是对每次输入的四张图片进行随机的旋转、放缩、裁剪等,并且按照四个方向排布,实现图片和边框的重新整合。这样做的好处是扩大了数据集,并且能使网络一次性计算多张图片的参数,减少了GPU的消耗。
3.1.2 主干特征提取网络CSPDarknet53
YOLOv4的主干网络CSPDarknet53包含了Darknet53和CSPNet结构。CSP结构主要将输入分为两个部分分别进行处理。一部分经过原有的主干结构进行计算,即原本的残差卷积块的堆积结构。另一部分则输入到残差边结构,只经过少量的计算就和输出相连。CSP中的残差边结构可以最大化梯度组合的差异,增强网络的学习能力,在保证准确率的同时降低计算的内存流量。
CSPDarknet53中有5个CSP模块。输入图像在进入每个CSP模块前都会先通过一个3×3的卷积核进行下采样。在每个CSP模块中,会先使用一个1×1的卷积核将输入特征图分为两个部分,并使每部分的通道数都会减半。因此,对于输入到主干部分的特征图,需要再使用一次1×1的卷积改变通道数。其输出经过多个残差卷积块后再通过一个1×1的卷积与残差边的输出相连,并使用一个1×1的卷积整合输出特征图信息。由于在每个CSP模块前都使用了降采样结构,因此网络的参数量大大减少。并且因为CSP模块的引入,使得网络抑制了梯度消失的现象,在降低计算量的同时增强了其学习能力。CSPDarknet53还引用了新的Mish激活函数。其公式如下式3.1所示:
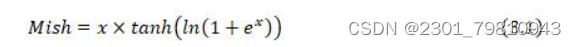
该激活函数由于在正数部分没有最大值边界,克服了过饱和问题。同时相比于ReLU,Mish可以得到绝对值较小的负值从而获得更优的梯度。Mish的函数曲线对比ReLU也更加平滑,从而可以使网络达到更好的精度与鲁棒性。
3.1.3 Neck层
在进行目标检测任务时,一般会在网络的骨干网络和输出层之间加入Neck层来更好地挖掘整合特征。YOLOv4中·的Neck层主要由SPPNet和PANet结构组成。
(1)空间金字塔池化结构SPPNet
YOLOv4在主干网络之后加入了SPPNet结构进行池化。该结构会对主干网络的输出特征图先进行三次卷积,然后利用1×1、5×5、9×9、13×13的池化核进行最大值池化,将结果整合后再进行三次卷积。对于任意的输入尺寸,SPPNet都能够产生固定的输出大小,可以适用于多尺度训练。
SPPNet的多核池化结构相比于使用单一尺寸的池化核,显著地提升了主干网络对特征的学习能力。同时它将特征图都归一化到单一尺寸,使得网络更加容易收敛。
(2)路径聚合网络PANet
YOLOv4使用了PANet结构来完成融合特征。PANet主要可以分为特征金字塔、自底向上路径增强、自适应特征特征和全连接聚变四个模块。相比于YOLOv3中FPN结构使用自顶向下的路径来获取特征,PANet使用了另一条自底向上的连接,该结构大约只有十层,极大的缩短了高低层特征融合的距离,丰富了每层的特征。同时,与YOLOv4中FPN只对高层特征进行池化,PANet中的自适应特征池化可以对各个层级不同尺度的特征层进行操作,使得网络能够更好地聚合不同层之间的特征,保证特征信息的完整性。
3.1.4 预测层
YOLOv4的预测层主要包括YOLO Head结构。YOLO Head的主要作用是利用PANet整合的特征进行预测。YOLO Head由3×3和1×1的卷积核组成。对于输入的特征图,Head部分会先使用3×3的卷积整合前面的特征,再使用1×1的卷积将特征转换为YOLOv4的结果。最后对生成的预测框通过阈值进行判断,并使用CIOU回归损失函数加上DIOU非极大值抑制的方法调整筛选预测框的位置,得到最后的输出结果,
3.2 YOLOv4图像检测
YOLOv4的动物图像检测流程如图3.2所示:
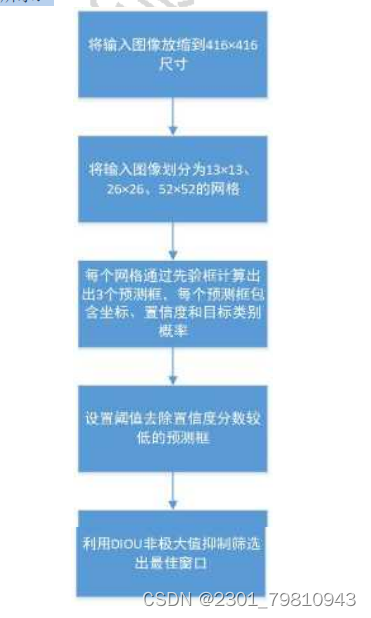
图3.2 YOLOv4检测流程
二、智能动物识别系统设计
5.1 需求分析
传统的动物识别系统需要依靠人工比对图片去识别并框定动物的位置,整个过程不仅效率低、速度慢,且需要耗费大量的人力,无法大量部署在实际环境中对动物进行实时检测。因而需要设计一个可以自动对图像或视频进行实时动物检测的系统。
本文所设计的智能动物识别系统的核心是可以通过动物检测算法来识别出图像以及视频中的动物种类,并框定出不同动物的位置。本系统搭建了一个用于动物识别的网站,网站后端部分采用Flask框架搭建,前端部分采用HTML、CSS、JavaScript、Bootstrap来设计网页界面,程序开发环境为PyCharm。该网站的主要功能需求有如下几点:
(1)图像识别功能:用户可以向网站上传图像文件,网站调用本文所设计的YOLOv4动物目标检测模型对上传的图像进行动物识别及检测,并将检测结果直观的展示在网页界面上。检测结果中需要将识别的动物种类及动物所在的位置框定出来,并展示出动物识别种类的置信度。
(2)视频识别功能:用户可以向网站上传视频文件,网站调用本文所设计的Mobilenetv2-YOLOv4或YOLOv4动物检测模型对上传的视频进行动物识别及检测。视频检测处理时需要实时展示处理后的视频,并在视频中将识别的动物种类及动物所在的位置框定出来。整个视频处理过程需要尽量实时高效。
(3)摄像头识别功能:网站可以开启摄像头,然后调用算法对摄像头画面内的动物目标进行识别。
(4)结果展示功能:网站可以提供动物检测处理框定后的图像及视频文件的下载,并在网页上以表格形式展示图像中框定的动物种类、置信度、动物的位置坐标等信息,使使用者可以查看并使用检测的结果。
整个系统在处理图像和视频时需要具有较快的检测速度和较高的准确率,特别是在检测视频时需要保持尽量高的帧率,贴合实际环境下的野生动物检测场景。
5.2 系统设计
本系统对前两章提到的图像和视频识别算法进行了程序设计,并将算法模型部署在了本地网站上。用户通过本地网站上传图像或视频,然后调用相应的模型接口对文件进行处理,最后在前端网页进行结果展示。
网站的后端部分采用Flask框架搭建,前端部分采用HTML、CSS、JavaScript、Bootstrap来设计网页界面,功能上主要分为图像识别模块、视频识别模块和摄像头识别模块三个部分,其中视频识别模块又包含YOLOv4和Mobilenetv2-YOLOv4两种算法,其功能示意图如图5.1所示
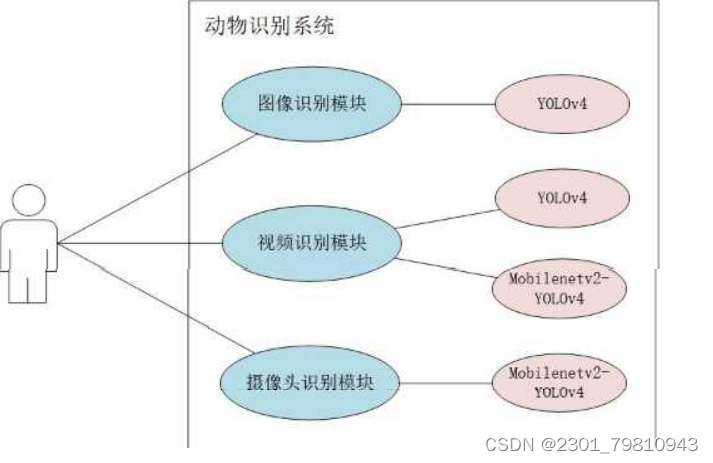
图5.1 动物识别系统功能示意图
5.3 系统展示
启动服务端程序后,首先访问系统主页http://127.0.0.1:5000,动物检测系统主页如图5.5所示:
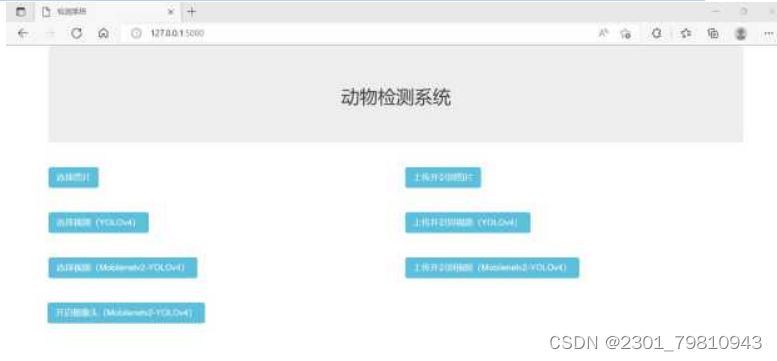
图5.5 动物识别系统首页
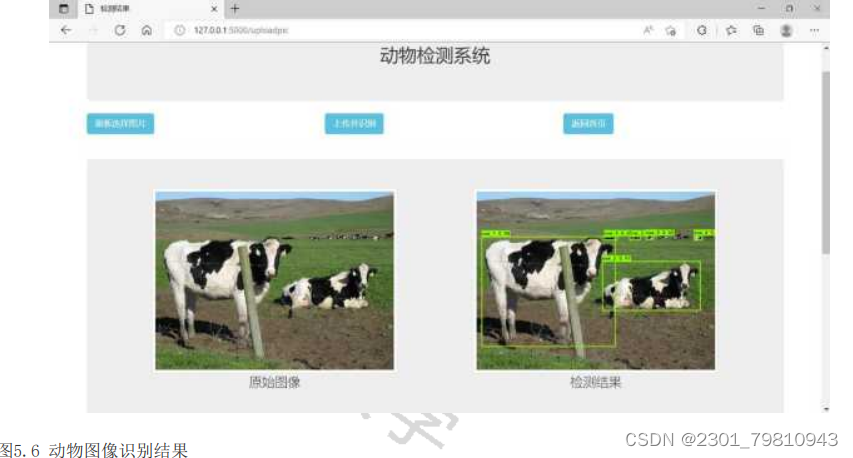
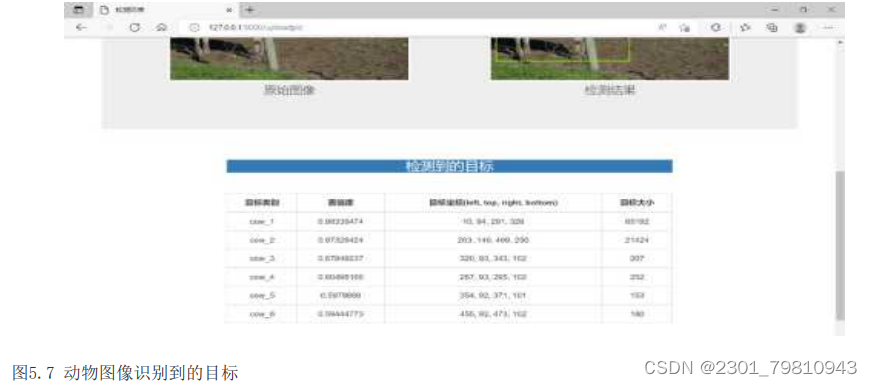
开始测试系统图像识别模块。依次点击“选择图片”、“上传并识别图片”按钮,上传图片后,系统自动跳转到http://127.0.0.1:5000/uploadpic。测试结果如图5.6、5.7所示。系统成功框定出了图像中的目标动物,并将目标动物的检测信息以表格形式展现了出来。
5.3.2 视频识别模块测试
然后测试系统视频识别模块,先测试使用YOLOv4模型进行视频识别。依次点击“选择视频(YOLOv4)”、“上传并识别视频(YOLOv4)”按钮,上传视频后,系统自动跳转到http://127.0.0.1:5000/uploadvideo。测试结果如图5.8所示,系统基本正确框定出了视频中的目标动物,此时处理视频的FPS为1.15。

图5.8 YOLOv4动物视频识别结果
再测试使用Mobilenetv2-YOLOv4模型进行视频识别。依次点击“选择视频(Mobilenetv2-YOLOv4)”、“上传并识别视频(Mobilenetv2-YOLOv4)”按钮,上传视频后,系统自动跳转到http://127.0.0.1:5000/uploadvideo2。测试结果如图5.9所示,系统也基本正确框定出了视频中的目标动物,此时处理视频的FPS为8.35,明显大于YOLOv4处理视频时的1.15。
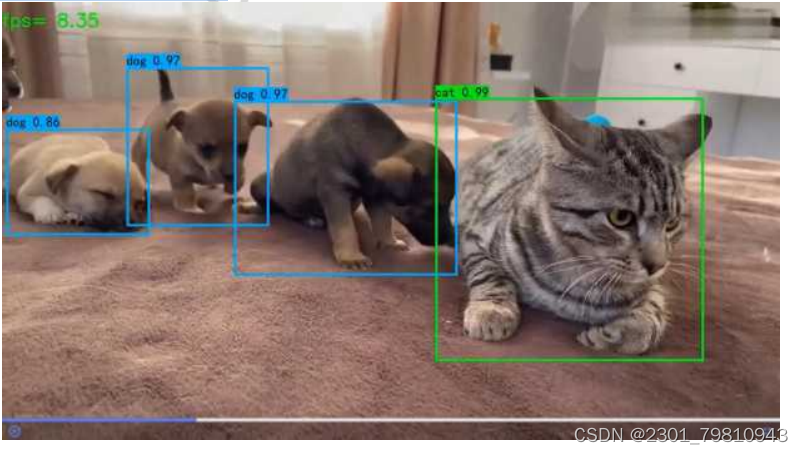
图5.9 Mobilenet-YOLOv4动物视频识别结果
比较两次视频识别测试结果,可以看出,在使用Mobilenetv2-YOLOv4模型时,系统的处理速度要明显快与YOLOv4模型,而识别的准确率与YOLOv4模型差别不大,这与本文的设计预期相符。
三、总结
动物目标检测是目标检测领域中重要的应用场景之一。本文从检测速度和准确性考虑,使用了单阶段目标检测算法YOLOv4。YOLOv4模型主要包括输入层、主干网络、Neck层和输出层。对于输入的图像,主干网络CSPDarknet53会先挖掘出初步的有效特征图,并将特征图输入到Neck层中进行处理,得到更好的特征图,最后经由输出层得到预测结果。对于视频识别,系统会将视频逐帧转换成图片后输入到模型中完成检测。如果直接使用YOLOv4模型进行检测,则会因为模型较大而导致检测速率过慢,难以应用到实时场景中。针对该问题,本文设计了参数更少,运算速度更快的改进模型Mobilenetv2-YOLOv4。该模型将YOLOv4的主干网络CSPDarknet53替换为了参数更少的Mobilenetv2,并将网络中3×3的卷积核替换为了在Mobilenetv1中广泛使用的深度可分离卷积核,大大降低了YOLOv4的网络参数数量,显著提高了模型在视频检测和摄像头检测时的检测速度。
最后,本文将这两种检测算法部署在了本地网站上。用户可以通过本地网站上传图片或视频文件直接进行检测处理,得到检测结果并以可视化的界面展现出来,也可以直接打开设备摄像头进行检测。
四、目 录
目录
摘 要 3
第1章 绪论 7
1.1 研究背景及意义 7
1.2 国内外研究现状 7
1.3 本文工作及结构 8
第2章 相关背景知识 10
2.1 卷积神经网络 10
2.1.1 卷积层 10
2.1.2 池化层 11
2.1.3 全连接层 12
2.2 基于深度学习的目标检测算法 12
2.2.1 两阶段目标检测算法 12
2.2.2 单阶段目标检测算法 13
2.3 本章小结 14
第3章 基于YOLOv4的动物图像检测 15
3.1 YOLOv4网络结构 15
3.1.1 输入层 15
3.1.2 主干特征提取网络CSPDarknet53 15
3.1.3 Neck层 16
3.1.4 预测层 16
3.2 YOLOv4图像检测 17
3.3 实验结果及分析 18
3.3.1 YOLOv4模型训练配置 18
3.3.2 YOLOv4模型Loss和精度 18
3.4 本章小结 20
第4章 基于Mobilenetv2-YOLOv4的动物视频检测 21
4.1 Mobilenetv2网络 21
4.2 Mobilenetv2-YOLOv4网络的实现 22
4.2.1 主干网络替换 22
4.2.2 卷积核替换 23
4.3 实验结果及分析 23
4.3.1 Mobilenetv2-YOLOv4模型训练配置 23
4.3.2 Mobilenetv2-YOLOv4模型Loss和精度 24
4.3.3 YOLOv4和Mobilenetv2-YOLOv4模型对比 25
4.3 本章小结 26
第5章 智能动物识别系统设计 27
5.1 需求分析 27
5.2 系统设计 27
5.2.1 动物检测系统网站相关技术 28
5.2.2 图像识别模块 29
5.2.3 视频识别模块 30
5.2.4 摄像头识别模块 31
5.3 系统测试 32
5.3.1 图像识别模块测试 32
5.3.2 视频识别模块测试 33
5.3.3 摄像头识别模块测试 35
5.4 本章小结 35
第6章 总结与展望 36
6.1 总结 36
6.2 展望 36
参考文献 37
致谢 39

















 1204
1204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









