







1、需要导入的包:如果没有可以pip install ***
import requests
import re
import csv2、需要注意的点:
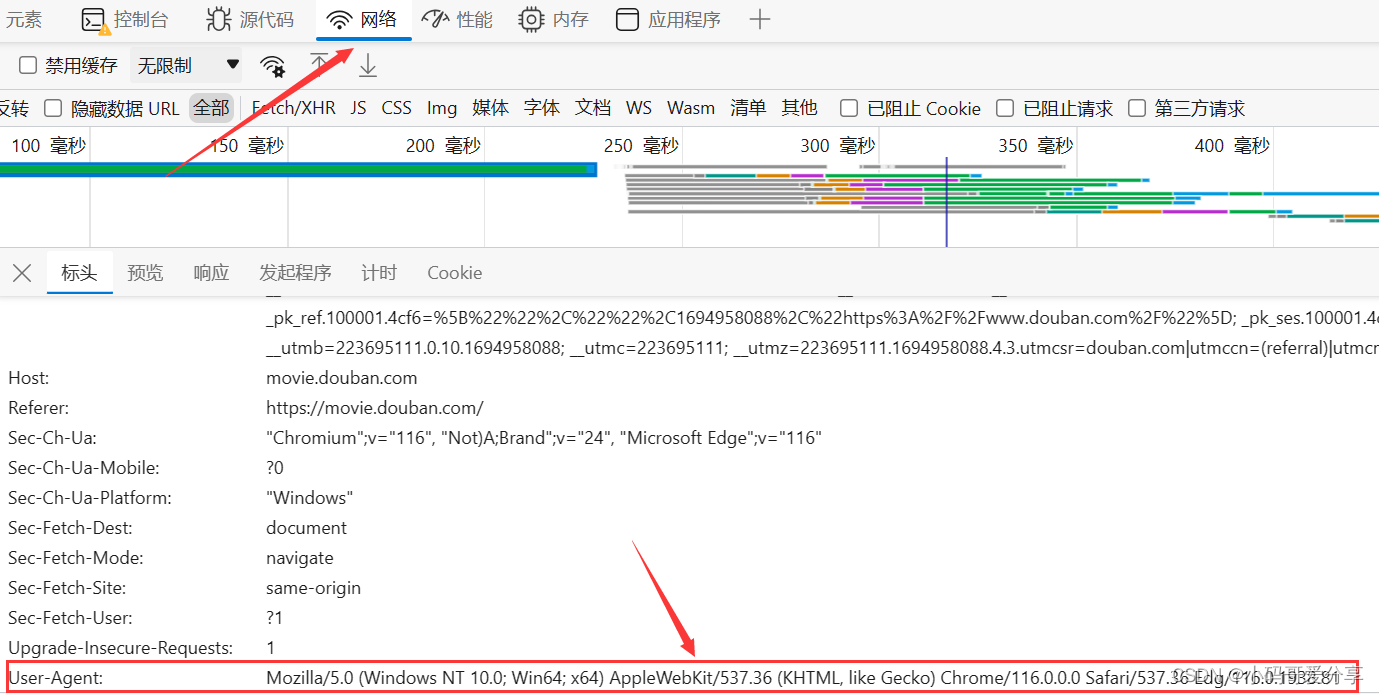
①:一般情况下务必加入header
②:re正则匹配部分的字符串,它是拿着这个匹配规则去一个一个对应文中内容,所以定义的这个匹配规则一定要对你想提取的内容具有普适性,也就是要符合提取内容的一般形式规则。
③:在用csv写入文件的时候,注意要设置newline="",不然写入后没两条之间会有空行,mode='a'保证连续写入内容,mode='w'在下次写入时会自动清空之前的内容。
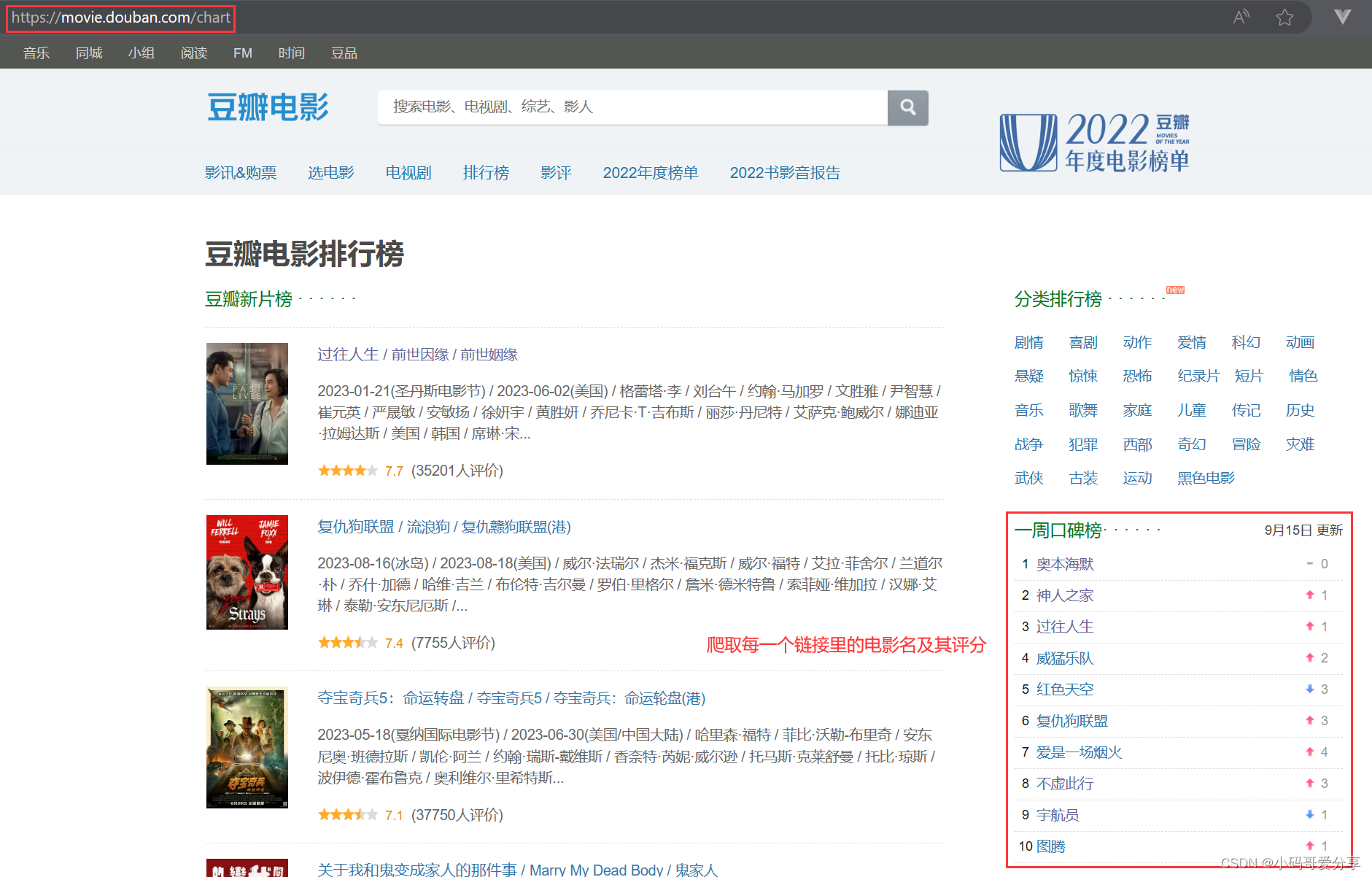
④:finditer()与search()的区别:一篇内容中需要多次匹配时用finditer(),只需要提取一处时用search(),比如整个页面中我只需要提取电影名及其评分时用search()。
# 主地址
domain = "https://movie.douban.com/chart/"
# 用户代理(防反爬)
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 "
"Safari/537.36 Edg/116.0.1938.81"
}
# 请求页面
resp = requests.get(domain, headers=header)
# 解析内容(定位到一周口碑的地方)
obj1 = re.compile(r'<div class="name">.*?href="(?P<url>.*?)"', re.S)
# 解析内容(定位到电影名<这里只提取第一首选名>和评分)
obj2 = re.compile(r'<script type="application.*?"name": "(?P<name>.*?) .*?'
r'"ratingValue": "(?P<rate>.*?)"', re.S)
"""
执行解析得到每一部电影主页面的地址:(示例)
https://movie.douban.com/subject/35593344/
"""
result1 = obj1.finditer(resp.text)
# 写入的文件(mode = 'a' 可以连续写入)
file = open('data(一周口碑榜)', encoding='utf-8', mode='a', newline="")
csvWriter = csv.writer(file)
# 访问每一个地址,找到获取其电影名和评分
for it in result1:
# 加strip()把最后一个'/'去掉
# https://movie.douban.com/subject/35593344
child_resp = requests.get(it.group('url').strip('/'), headers=header)
result2 = obj2.search(child_resp.text)
dic = result2.groupdict()
dic['name'] = dic['name'].strip(',\n"')
print(dic)
# 逐行写入
csvWriter.writerow(dic.values())如有不明白的地方可以发在评论区!















 563
563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









