







Foundation Models for Recommender Systems: A Survey and New Perspectives
推荐系统的基础模型:综述与新视角
日期:2024年2月
网址:https://arxiv.org/pdf/2402.11143
论文综述系统性地探讨了基础模型(FMs)在推荐系统(RecSys)中的应用现状、分类框架、挑战与未来方向。
论文重点和创新点
论文重点
-
系统性综述FM4RecSys:
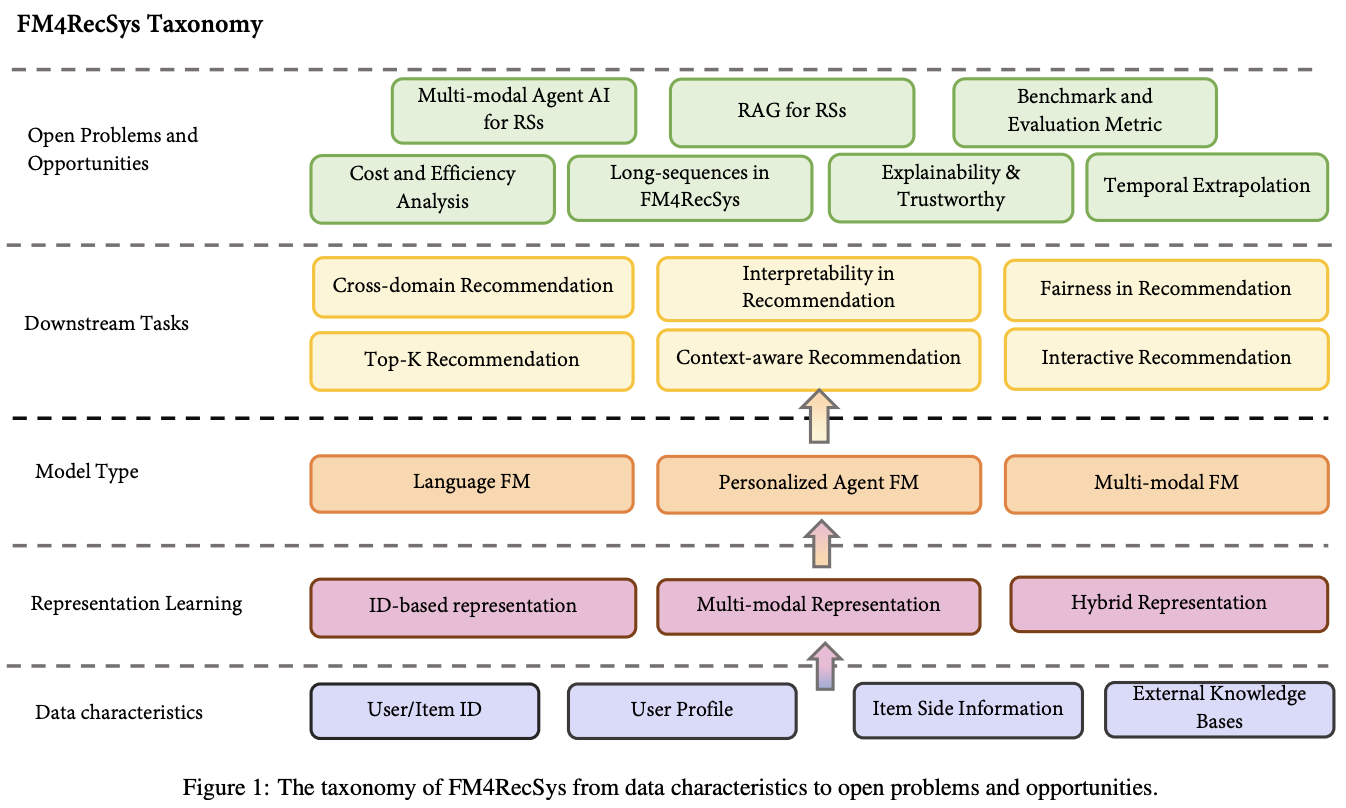
• 首次全面梳理基础模型(FMs)在推荐系统中的应用,涵盖数据表征、模型类型、下游任务等维度,提出统一的分类框架(图2)。
• 超越以往仅关注大语言模型(LLMs)的综述,扩展至多模态基础模型(如CLIP、ViT)和个性化代理(Agent AI)。 -
四大核心分类:
• 数据表征:对比ID-based(如TransRec)、多模态(如VIP5)和混合表征(如CLLM4Rec)的优劣,强调语义与协同信号的平衡。
• 模型类型:
◦ 语言基础模型:分预训练(如M6-Rec)、微调(如InstructRec)、提示工程(如ChatGPT零样本推荐)。
◦ 多模态模型:如KP4SR利用知识图谱提示解决语义鸿沟。
◦ 个性化代理:模拟用户行为(如RecAgent)或作为推荐系统(如Self-Inspiring算法)。
• 下游任务:覆盖Top-K推荐、上下文感知推荐(如DRDT)、交互式推荐(如对话式CRS)、跨域推荐(如HAMUR)、可解释性与公平性(如UP5)。 -
关键挑战与解决方案:
• 长序列处理:RoPE技术扩展上下文窗口,适配用户行为序列建模。
• 可解释性:结合知识图谱(如Logic-Scaffolding)和Chain-of-Thought技术生成逻辑化解释。
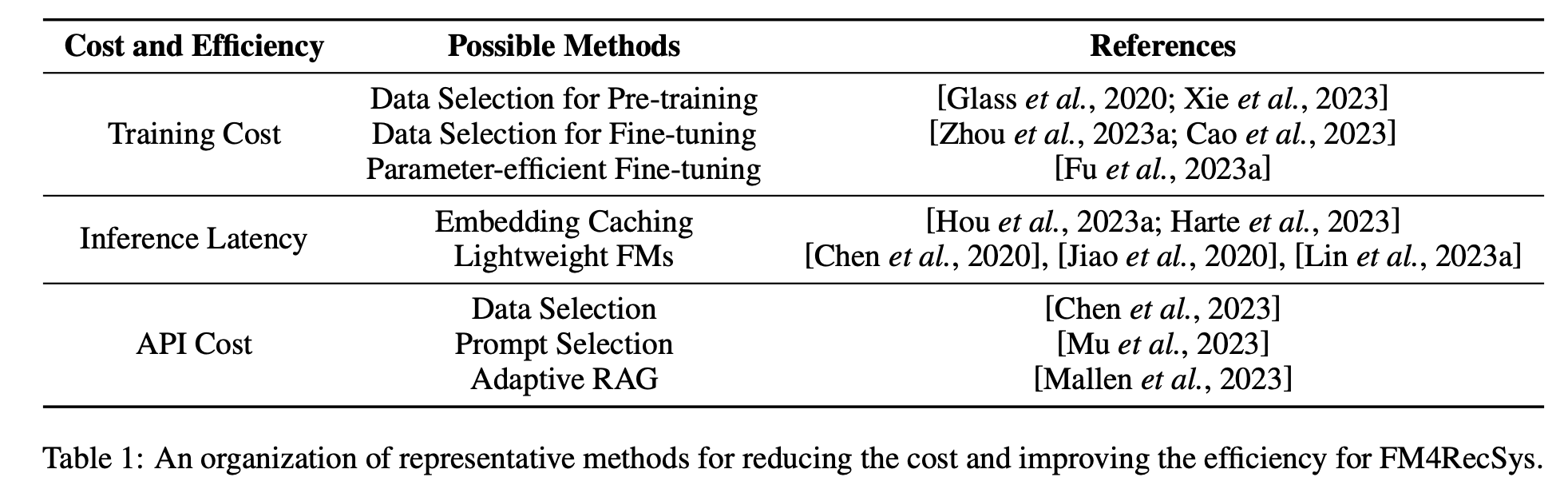
• 效率问题:参数高效微调(LoRA)、嵌入缓存、模型压缩(AWQ量化)降低计算成本。
创新点
-
统一框架与新型分类法:
• 提出“数据-模型-任务”三维分类体系,首次将Agent AI和多模态FM纳入推荐系统研究范畴。 -
前沿问题深度剖析:
• RAG与推荐结合:探讨检索增强生成技术如何缓解FM的幻觉问题,动态更新用户偏好(如RELLA)。
• 时序外推:提出将用户偏好视为时间序列,利用LLMTIME2实现零样本偏好预测。
• 多模态Agent AI:构想代理通过感知环境(如医疗场景)生成实时推荐,推动仿真与A/B测试革新。 -
批判性洞见:
• 揭示FM的双刃剑效应:
◦ 安全性:提示注入攻击风险,需人类对齐(如CValues数据集)。
◦ 隐私:联邦学习与机器遗忘(如推荐反学习)成为未来方向。
• Benchmark缺陷:指出现有评估局限于单一数据集(如Amazon Beauty),呼吁构建多任务、多模态基准。 -
实用导向优化:
• 系统分析API成本(如GPT-4令牌开销)、训练/推理效率,给出具体方案(表1),如动态RAG减少上下文长度。
总结
该论文通过体系化的文献梳理和前瞻性思考,不仅填补了FM4RecSys领域的综述空白,更通过跨模态、Agent AI、RAG等交叉创新,为下一代推荐系统提供了理论基石与实践路径。其核心价值在于将分散的研究脉络整合为有机框架,并尖锐指出技术落地中的隐蔽挑战(如隐私、成本),推动领域从“模型性能”向“可信部署”演进。
摘要
最近,基础模型 (FM) 凭借其广泛的知识库和复杂的架构,在推荐系统 (RS) 领域提供了独特的机会。在本文中,我们试图彻底研究基于 FM 的推荐系统 (FM4RecSys)。我们首先回顾一下 FM4RecSys 的研究背景。然后,我们提供了现有 FM4RecSys 研究工作的系统分类法,可以分为四个不同的部分,包括数据特征、表示学习、模型类型和下游任务。在每个部分中,我们回顾了最近的主要研究进展,概述了代表性模型并讨论了它们的特点。此外,我们详细阐述了 FM4RecSys 的开放问题和机遇,旨在阐明该领域未来的研究方向。总之,我们回顾了我们的发现并讨论了该领域的新兴趋势。
1 引言
推荐系统(Recommender Systems, RSs)通过个性化定制内容和体验来满足用户偏好,在商业提升和决策过程中发挥着日益重要的作用[Ricci et al., 2015; Zhang et al., 2019]。与此同时,基础模型(Foundation Models, FMs)在自然语言处理、计算机视觉和多模态任务等领域取得了显著进展。近年来,FMs 正在重塑推荐系统的架构,提升其性能,并为推荐交互提供新的方式。基于基础模型的推荐系统凭借更强的泛化能力,能够更好地利用复杂的用户-物品信息,并处理更多样化的推荐任务[Geng et al., 2022]。
具体而言,基于基础模型的推荐系统(FM4RecSys) 是指利用预训练知识和推荐数据集,捕捉用户偏好、物品特征及上下文变量的丰富表示,以提高推荐任务的个性化和预测准确性。接下来,我们将探讨现有研究的动机,以深入理解 FMs 在推荐系统中的实际应用和影响。
1.1 研究动机
我们列举了推动 FM4RecSys 研究发展的主要动机:
1. 增强泛化能力
基础模型通过大规模数据学习复杂模式,能够更好地适应未见过的数据[Bommasani et al., 2021]。在推荐系统中,这意味着 FMs 可以更准确地预测用户偏好和行为,尤其是在数据稀疏或面对新物品(如零样本/少样本推荐场景[Gao et al., 2023a; Ding et al., 2021; Hou et al., 2023b])时,通过有限信息推断用户偏好或物品特征,从而提升冷启动推荐效果。
2. 提升交互体验
FMs 为推荐系统引入了变革性的交互范式。例如,传统对话推荐系统(CRSs)依赖预设的对话模板[Gao et al., 2021; Lei et al., 2020],限制了交互的灵活性和广度。而 FMs 支持动态、非结构化的自然语言对话,用户可以通过更直观的方式表达需求、提问或获取个性化推荐,显著提升了交互的自然性和参与感。
3. 改进解释与推理能力
传统推荐系统的解释通常基于简单数据(如用户评论或共现行为[Li et al., 2020]),缺乏深度逻辑。FMs 能够结合常识知识和用户上下文生成连贯的解释,例如通过分析用户历史行为、偏好和物品特征,提供更具说服力的推荐理由[Sun et al., 2023]。这种能力在医疗健康等关键领域尤为重要,可支持更可信的决策(如诊疗建议)[Wang et al., 2023d]。
1.2 与现有 LLM 推荐综述的差异
尽管已有研究探讨大语言模型(LLMs)与推荐系统的结合(如 Liu et al.[2023c] 分析训练策略、Wu et al.[2023] 从判别/生成视角总结 LLM4Rec),本文的独特贡献在于:
• 系统性框架:如图 1 所示,我们构建了涵盖数据特征、表示学习、模型类型和下游任务的完整分类体系。
• 更广的模型覆盖:不仅关注 LLMs,还包括多模态基础模型和个性化代理。
• 前沿问题与机遇:深入探讨未解决的挑战(如长序列处理、可解释性)和新兴方向(如多模态代理 AI、RAG 增强推荐)。
2. FM4RecSys的研究进展
2.1 数据特征与表征学习
在基础模型(FM)时代之前,推荐系统主要依赖用户和物品的独热编码(one-hot encoding)进行表示。随着FM4RecSys的出现,研究开始转向更丰富的输入形式,如用户画像、物品辅助信息(side information)以及外部知识库(如维基百科),以提升推荐性能。具体而言,许多工作(如Bao et al., 2023c; Hua et al., 2023b)指出,构建基于FM的推荐系统的关键在于弥合FM预训练任务与推荐任务之间的差距。为此,现有研究通常将推荐数据转化为自然语言形式,以便在FM上进行微调(Zhu et al., 2023)。在这一过程中,每个用户/物品被赋予唯一的标识符(如用户画像、物品标题或数字ID),并将用户的历史交互记录转换为标识符序列。FM可以通过对这些标识符进行微调来学习其表示,从而优化推荐任务。
当前的推荐数据表示方法可分为三类:
- 基于ID的表示:在FM的背景下,近期研究(如Geng et al., 2022; Hua et al., 2023c)使用数字ID(如“user_123”或“item_57”)来表示用户和物品,以捕捉物品的唯一性。然而,数字ID缺乏语义信息,无法充分利用FM中丰富的知识。此外,FM需要足够的交互数据来微调每个ID的表示,这限制了其在大规模、冷启动和跨域推荐中的泛化能力。同时,ID索引需要更新词汇表以处理未登录词(OOV)问题,并调整FM的参数,这会带来额外的计算开销。
- 多模态表示:利用多模态辅助信息,如图像(如物品视觉信息,Sarkar et al., 2023)、文本(如物品标题、描述和评论,Li et al., 2023a; Zhang & Wang, 2023)、多模态内容(如短视频和音乐,Shen et al., 2022; Youwang et al., 2022)以及外部知识源(如维基百科中的物品关系,Zhai et al., 2023; Xi et al., 2023)。Yuan et al. (2023) 强调了基于多模态的推荐系统相较于基于ID的方法的性能优势。
- 混合表示:结合ID和多模态辅助信息,以同时实现独特性和语义丰富性。例如,TransRec(Lin et al., 2023d)使用多面标识符(ID、标题和属性)来增强物品表示的语义信息;CLLM4Rec(Zhu et al., 2023)通过硬提示和软提示将用户/物品ID与评论文本对齐,从而同时建模协同信息和内容语义。
2.2 FM4RecSys的分类框架
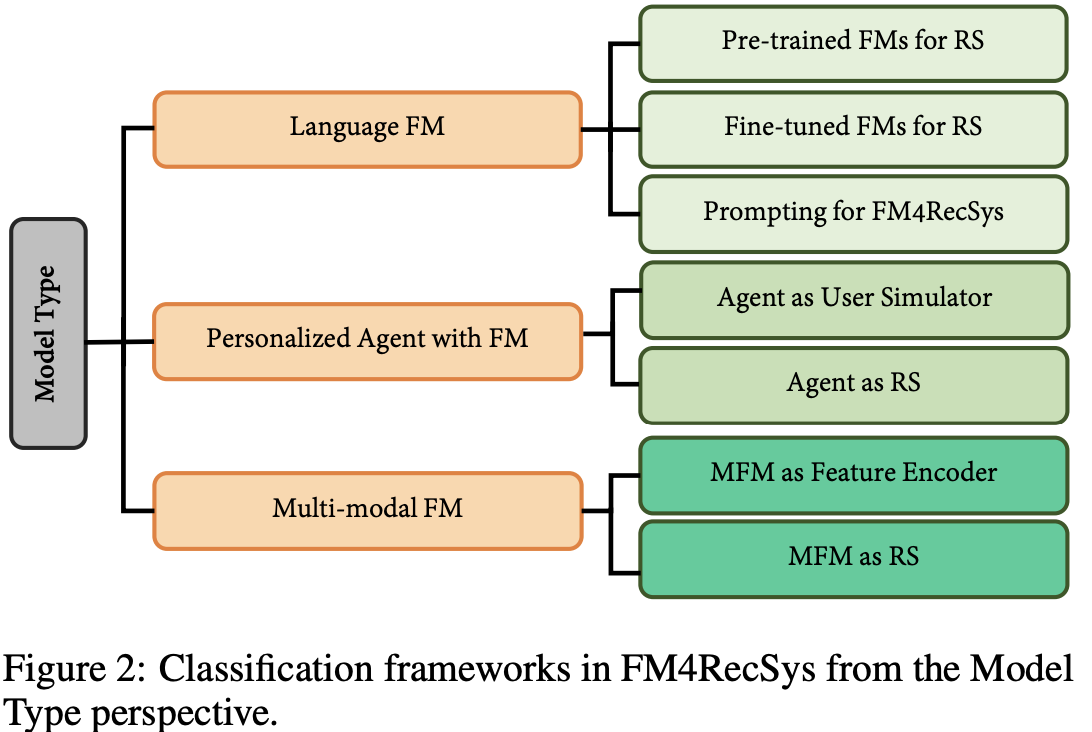
如图2所示,我们根据模型类型对FM4RecSys进行了结构化分类。与以往专注于LLM的综述不同,我们的框架不仅涵盖语言基础模型在推荐系统中的应用,还包括多模态FM和基于FM的个性化代理的研究。
语言基础模型在推荐系统中的应用
- 预训练模型:少数工作(如M6-Rec, Cui et al., 2022; PTUM, Wu et al., 2020)在大规模推荐数据集上对整个模型进行预训练,采用基于Transformer的架构进行下一项预测,并应用不同的语言建模任务(如掩码语言建模、排列语言建模等)。这类方法通常需要大量领域数据,训练成本较高。
- 直接微调模型:
• InstructRec(Zhang et al., 2023e)设计了丰富的指令模板(39种手动设计的模板),涵盖用户偏好、意图、任务形式和上下文。经过指令微调后,LLM能够理解并遵循不同的推荐指令。
• TallRec(Bao et al., 2023b)采用参数高效微调方法LoRA(Hu et al., 2022),分两阶段微调LLM:先在Alpaca通用数据上微调,再结合用户历史信息微调,利用物品标题作为输入,在冷启动推荐中表现优异。
• BIGRec(Bao et al., 2023a)指出LLM难以整合统计数据(如流行度和协同过滤信息),因此通过指令微调生成代表物品的标记,并将这些标记与推荐数据库中的真实物品对齐(加入流行度等统计信息)。 - 提示工程(Prompting):
• 非调优范式(不改变LLM参数),通过设计合适的提示激发LLM的推荐能力。例如,Liu et al. (2023b) 提出了一个提示构建框架,评估ChatGPT在五种常见推荐任务中的能力,并提供零样本和少样本版本。
• He et al. (2023b) 不仅评估LLM在序列推荐中的能力,还提出了基于时效性的提示和上下文学习策略,以缓解LLM的顺序感知和位置偏差问题。
• 近期研究(如Xu et al., 2024)探索了新颖的提示结构。Yao et al. (2023) 在提示中加入物品属性的自然语言描述、基于文本模板的协同过滤信息和知识图谱推理路径;Rahdari et al. (2023) 设计了分层提示结构,封装推荐物品和用户历史交互中的Top-K相似物品信息。
基于FM的个性化代理推荐系统
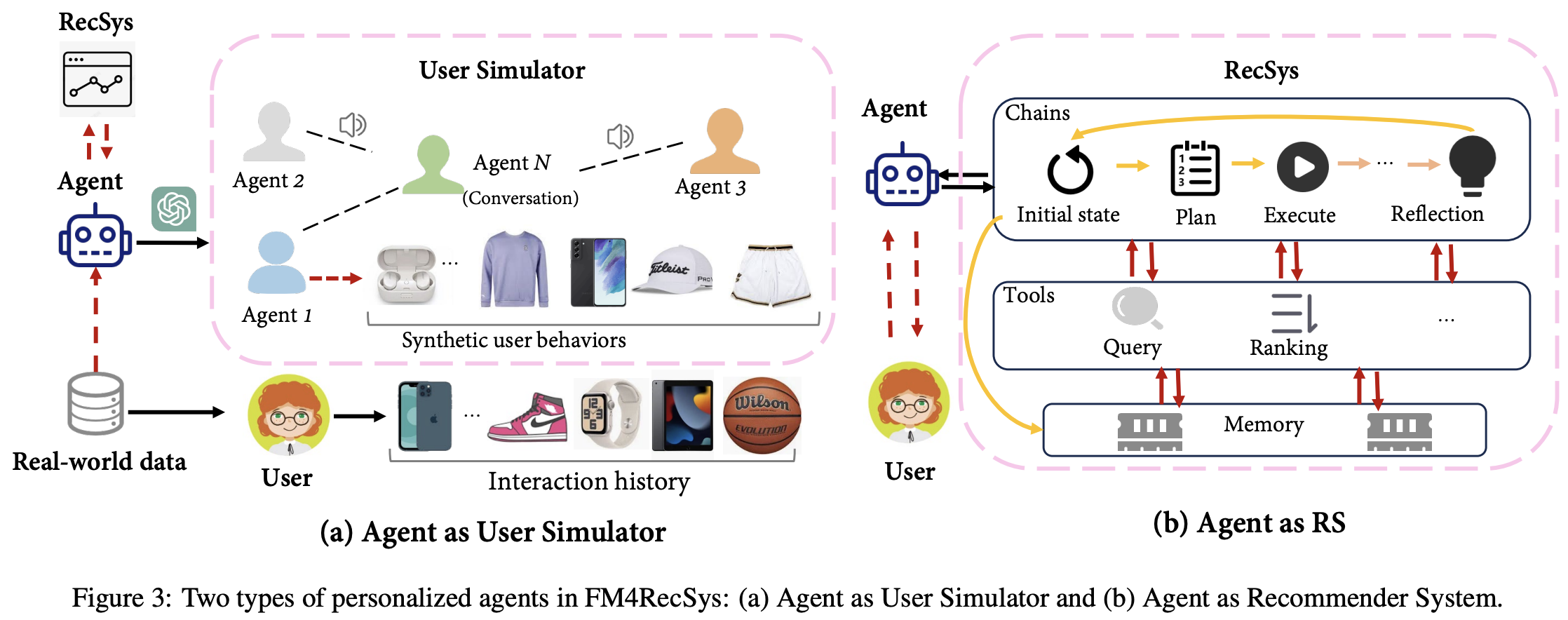
代理可以表现为用户模拟器或推荐系统本身(如图3所示)。
- 代理作为用户模拟器:
• 传统方法(如Zhu et al., 2017; Ie et al., 2019)难以模拟复杂的用户行为,而FM展现出潜力(Wang et al., 2023b)。
• Wang et al. (2023b) 提出RecAgent,将每个用户建模为FM驱动的自主代理,在虚拟模拟器中交互,考虑浏览、点击等行为以及社交因素。
• Zhang et al. (2023a) 进一步研究FM驱动的生成代理能否准确模拟真实用户行为(如电影推荐场景),设计了包含1000个LLM代理的模拟器Agent4Rec。
• Zhang et al. (2023d) 将用户和物品均视为代理,通过协作学习优化交互。 - 代理作为推荐系统:
• Wang et al. (2023e) 提出自启发规划算法,利用历史路径指导下一步决策,结合数据库、搜索引擎和摘要工具生成个性化推荐。
• Huang et al. (2023) 将FM作为“大脑”,推荐模型作为工具,解析用户意图并生成响应,核心工具包括信息查询、物品检索和排序,并通过候选记忆总线共享物品池。
多模态基础模型在推荐系统中的应用
- MFM作为特征编码器:
• 利用MFM强大的表示能力提取多模态特征(如ViT编码图像、CLIP编码图文、SentenceBERT编码文本、DeepSim编码音频、SlowFast编码视频)。
• 关键挑战是如何对齐预训练目标与下游推荐任务。 - MFM作为推荐系统:
• VIP5(Geng et al., 2023)扩展了P5框架,结合多模态个性化提示和轻量级适配器微调,提升视觉-文本推荐性能。
• KP4SR(Zhai et al., 2023)利用外部知识库和结构化知识提示,缓解序列推荐中的语义鸿沟。
• Zhou et al. (2023b) 探索GPT-4V在视觉推荐中的零样本能力,但缺乏定量评估且存在样本偏差。
2.3 FM4RecSys的应用场景
Top-K推荐任务
• 挑战:用户信息过长可能超出FM的输入长度限制。
• 解决方案:
• ID表示方法(Hua et al., 2023c)直接生成推荐(Xu et al., 2023b; Geng et al., 2022)。
• 多模态表示通过相似度计算排序(Liu et al., 2023e)。
• 借鉴NLP方法(Li et al., 2023d; Dai et al., 2023),选择K个负样本或难例与用户提示一起输入FM排序。
上下文感知推荐
• FM的世界知识和推理能力可增强推荐(Harte et al., 2023; Xi et al., 2023)。
• 例如:
• Wu et al. (2022) 基于用户画像生成个性化软提示,结合对比学习。
• Liao et al. (2023) 混合ID嵌入和文本特征,通过适配器桥接传统推荐与FM的模态差距。
• Wang et al. (2023f) 利用FM的推理能力,通过上下文示例检索抽象用户偏好。
交互式推荐
• FM提升了对话推荐系统(CRS)的交互自然性(He et al., 2023)。
• 近期工作(Liu et al., 2023a; Lin & Zhang, 2023)通过角色扮演提示让ChatGPT模拟用户交互,结合RAG和思维链(CoT)技术。
• 知识图谱增强方法(Wang et al., 2021; Zhang, 2023)利用FM生成对话并推荐物品。
• 局限性:流行度偏差和地域敏感性。
跨域推荐
• 基础模型的跨域类比推理能力(Hu et al., 2023)缓解数据稀疏性问题。
• 代表性方法:
• HAMUR(Li et al., 2023c)设计领域特定适配器和共享超网络。
• Tang et al. (2023) 混合多领域用户行为,用PLM建模。
• KAR(Xi et al., 2023)通过知识推理、适应和应用三阶段实现开放世界推荐。
可解释性与公平性
- 可解释性:
• 传统方法(Li et al., 2020)基于ID生成自然语言解释,但可能模糊。
• Cui et al. (2022) 在提示中加入物品特征作为提示词。
• Liu et al. (2023d)发现ChatGPT的零样本表现优于监督方法。 - 公平性:
• 用户侧:UP5(Hua et al., 2023a)基于反事实公平提示;Zhang et al. (2023c)评估ChatGPT在音乐/电影推荐中对敏感属性的公平性。
• 物品侧:Hou et al. (2023b)将推荐任务形式化为条件排序任务。
核心贡献
- 系统性分类:首次从数据表征、模型类型和任务维度全面梳理FM4RecSys。
- 跨模态与代理视角:突破LLM局限,涵盖多模态FM和代理模拟研究。
- 前沿挑战:指出长序列处理、可解释性、时间外推等未解决问题,提出RAG、多模态代理等新方向。
3. 开放性问题与未来机遇
3.1 FM4RecSys中的长序列处理
FM4RecSys面临输入序列过长的问题,受限于基础模型的固定上下文窗口长度,这在需要大量上下文的任务(如上下文感知推荐)中表现尤为明显。例如,上下文感知推荐系统需要完整的用户交互历史和长候选列表,可能超出FM的处理能力,导致推荐效果下降。目前的研究尝试借鉴NLP技术,如分段输入、摘要生成、注意力机制优化(如RoPE旋转位置编码)等,以缓解这一限制。
3.2 可解释性与可信度
在FM时代,提升推荐系统的可解释性和可信度仍具挑战性。现有方法主要分两类:
- 生成自然语言解释:通过提示工程或知识图谱对齐(如逻辑推理路径)生成推荐理由,但解释的深度和逻辑性仍有不足。
- 模型内部机制分析:研究较少,需结合链式思考(Chain-of-Thought)等技术增强可追溯性。
3.3 时间序列外推
近期研究表明,FM能以零样本方式预测时间序列数据,性能媲美专用模型。这得益于FM对多模态分布的捕捉能力,尤其适合用户偏好这类具有周期性和趋势的数据。例如,LLMTIME2将时间序列编码为数值字符串,通过下一词预测实现连续预测,无需额外训练即可快速适应用户偏好变化。
3.4 多模态智能体AI在推荐系统中的应用
多模态智能体AI通过感知多模态环境(如视觉、上下文)生成交互式推荐,既能作为推荐系统模拟器,也能模拟用户行为,降低真实A/B测试成本。未来可扩展至医疗、路线规划等场景,但需解决实时反馈和个性化推理的挑战。
3.5 检索增强生成(RAG)与推荐系统的结合
RAG通过整合外部知识库增强FM的生成能力,尤其适合动态用户行为建模。例如:
• 解决输入长度限制:选择性检索用户历史中的关键片段。
• 减少幻觉推荐:通过实时知识更新避免生成不相关或虚构内容。
3.6 系统性能分析:API成本、训练与推理效率
成本挑战:
• 训练阶段:大规模预训练和微调开销高昂,需依赖数据选择和参数高效微调(如LoRA)。
• 推理阶段:API调用成本随提示长度增加,需优化提示压缩或自适应RAG策略。
效率优化方向:
• 训练成本:精选数据、轻量化适配器(如LoftQ)。
• 推理延迟:预计算嵌入缓存、模型蒸馏/量化。
3.7 基准测试与评估指标
现有基准(如LLM-Rec)局限于特定数据集(如Amazon Beauty)和任务,未来需构建更全面的评估框架,覆盖多模态、智能体推荐等场景,并设计领域相关的指标。
3.8 新兴趋势讨论
安全性:FM易受提示注入攻击(如生成有害内容),需通过人类偏好对齐和负样本训练提升安全性。
隐私保护:直接训练可能泄露用户交互数据,需探索联邦学习和机器遗忘技术。
关键问题总结
- 技术瓶颈:长序列处理、时间序列建模、多模态融合。
- 可信与伦理:可解释性、安全性、隐私保护。
- 落地成本:训练/推理效率、API经济性。
- 评估体系:需标准化基准和跨任务指标。
未来方向聚焦于高效适配(如轻量化微调)、动态知识整合(RAG)、多模态交互(智能体AI)及伦理对齐。
4 总结
在本文中,我们对 FM4RecSys 进行了全面回顾,提供了详细的比较并强调了未来的研究路径。我们希望这项调查能为 RecSys 研究社区提供挑战和最新进展的概述,以及基础模型中的一些开放性问题和机遇。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









