






简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。
HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和Map Reduce。HDFS为海量的数据提供了存储,而Map Reduce则为海量的数据提供了计算。

Hadoop主要优势
1.高可靠性:Hadoop按位存储和处理数据的能力值得人们信赖。
2.高扩展性:Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
3.高效性:Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
4.高容错性:Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
5.低成本:与一体机、商用数据仓以及QlikView、Yonghong Z-Suite等数据集市相比,Hadoop是开源的,项目的软件成本因此会大大降低。
Hadoop组成
Hadoop由许多元素构成
其最底部是Hadoop Distributed File System(HDFS),它存储Hadoop集群中所有存储节点上的文件。
HDFS的上一层是Map Reduce引擎,该引擎由Job Trackers和Task Trackers组成。
通过对Hadoop分布式计算平台最核心的分布式文件系统HDFS、Map Reduce处理过程,以及数据仓库工具Hive和分布式数据库Hbase的介绍,基本涵盖了Hadoop分布式平台的所有技术核心。
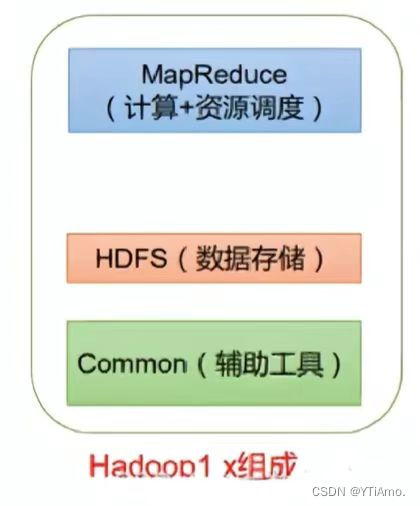
Hadoop1.x时代,Hadoop中的Map Reduce同时处理业务逻辑运算和资源的调度,耦合性较大。
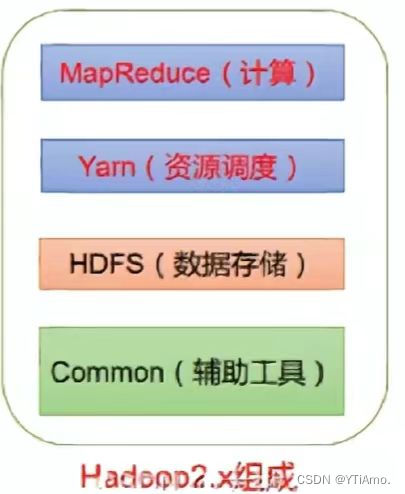
在Hadoop2.x时代,增加了Yarn。Yarn只负责资源的调度,Mapreduce只负责运算。
Hadoop3.x在组成上没有变化
Hadoop核心架构
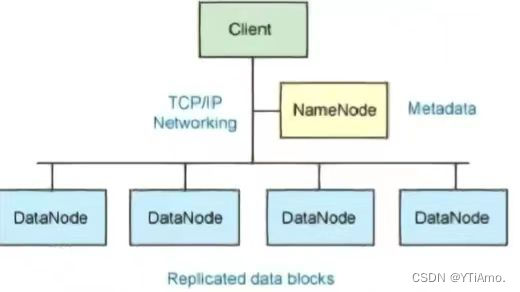
Hadoop文件系统使用分布式文件系统设计开发。它是运行在普通硬件。不像其他的分布式系统,HDFS是高度容错以及使用低成本的硬件设计。
HDFS的架构是基于一组特定的节点构建的,这是由它自身的特点决定的。
这些节点包括Name Node(仅一个),它在HDFS内部提供元数据服务;DataNode,它为HDFS提供存储块。
NameNode
1.NameNode是一个通常在HDFS实例中的单独机器上运行的软件。它负责管理文件系统名称空间和控制外部客户机的访问。
2.DataNode和块的文件映射的元数据经过NameNode
3.NameNode决定是否将文件映射到DataNode上的复制块上
4.NameNode在一个称为Fslmage的文件中存储所有关于文件系统名称空间的信息
5.NameNode本身不可避免的具有SPDF(Single Point Of Failure)单点失效的风险,主备模式并不能解决这个问题,通过Hadoop Non-stop namenode才能实现100%uptime可用时间
NameNode
DataNode也是一个通常在HDFS实例中的单独机器上运行的软件。Hadoop集群包含一个NameNode和大量DataNode。DataNode通常以机架的形式组织,机架通过一个交换机将所有系统连接起来。Hadoop的一个假设是:机架内部节点之间的传输速度快于机架节点的传输速度DataNode响应来自HDFS客户机的读写请求。它们还响应来自NameNode的创建,删除和复制块的命令。
文件操作
HDFS并不是一个万能的文件系统。它的主要目的是支持以流的形式访问写入的大型文件
首先需要将该文件缓存到本地的临时存储。如果缓存的数据大于所需的HDFS块大小,创建文件的请求将发送给NameNode。NameNode将以DataNode标识和目标块响应客户机
同时也通知将要保存文件块到副本的DataNode。当客户机开始将临时文件发送给第一个DataNode时,将立即通过管道方式将块内容转发给副本DataNode。客户机也负责创建保存在相同HDFS名称空间中的校验和(checksum)文件
在最后的文件块发送之后,NameNode将文件创建提交到它的持久化元数据存储(在Edit log和Fsimage文件)
HDFS流程
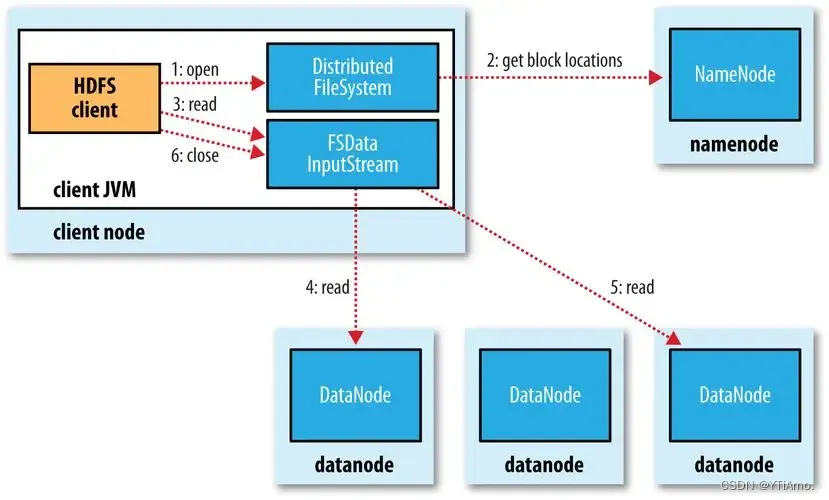
HDFS写入流程
client发起文件上传请求,通过RPC与NameNode建立通讯,NameNode检查目标文件是否已存在,父目录是否存在,返回是否可以上传;
client请求第一个block该传输到那些DataNode服务器上;
NameNode根据配置文件中指定的备份数量及副本放置策略进行文件分配,返回可用的DataNode的地址;
client请求3台DataNode中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将整个pipeline建立完成,后逐级返回client;
当第一个block传输完成后,Client请求NameNod上传第二个block,重复3操作;
然后再pipeline反方向,逐个发送ACK(命令正确应答),最后由第一个DN发送给Client(FSDataOutputStream);
当所有block全部写完,Client调用FSDataOutputStream的close方法关闭数据流,然后调用File System。complete方法告诉NN文件写入成功。
HDFS读取数据流程
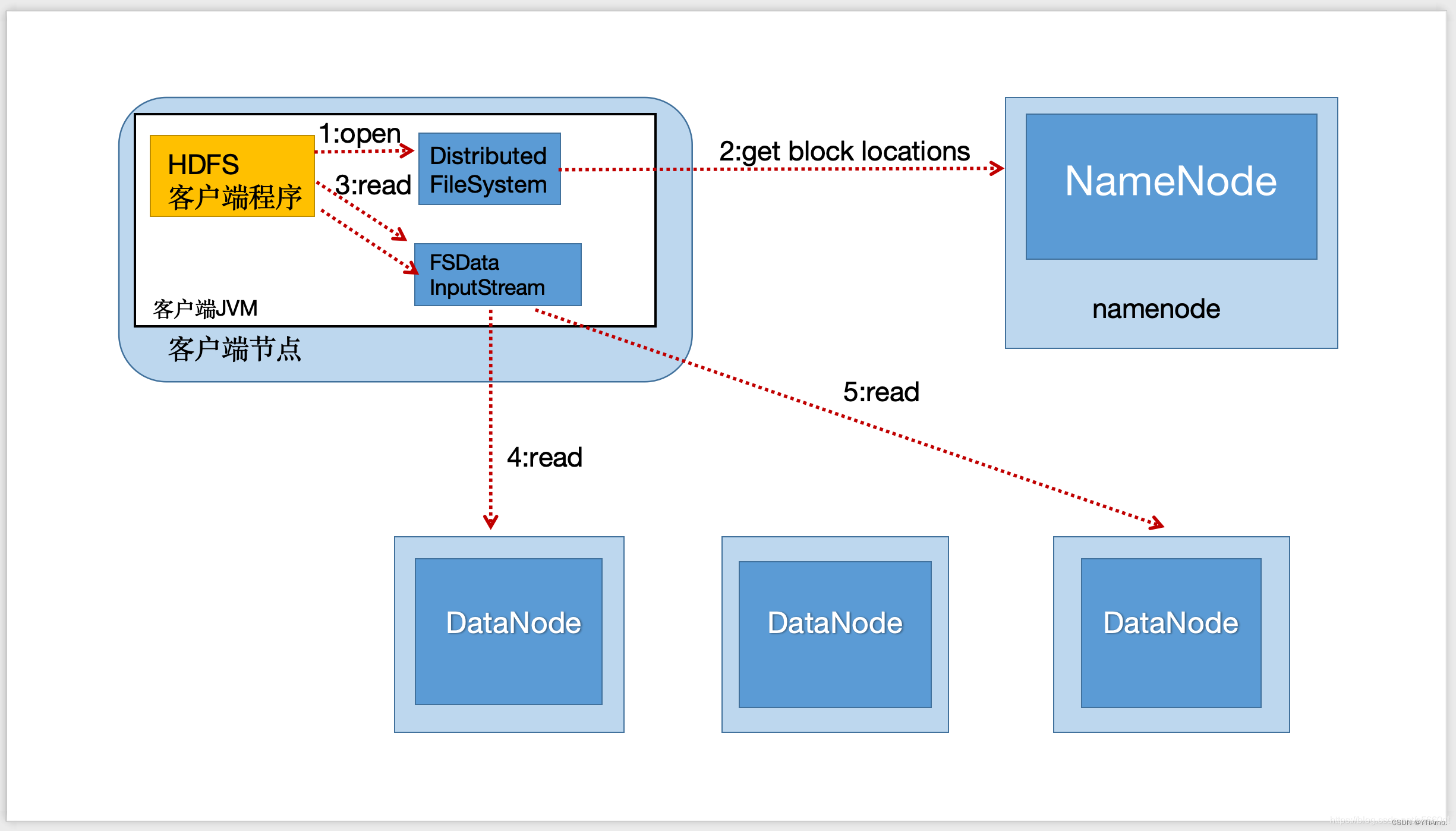
Client向NameNode发起RPC请求,来确定请求文件block所在的位置;
NameNode会视情况返回文件的部分或者全部block列表,对于每个block,NameNode都会返回含有该block副本的DataNode地址;
这些返回的DataNode地址,会按照集群拓扑结构得出DataNode与客户端的距离,然后进行排序;
Client选取排序靠前的DataNode来读取block,如果客户副本本身就是DataNode,那么将从本地直接获取数据;
当读完列表的block后,若文件读取还没有结束,客户端会继续向NameNode获取下一批的block列表;
读取完一个block都会进行checksum验证,如果苏区DataNode时出现错误,客户端会通知NameNode,然后再从下一个拥有该block副本的DataNode继续读;
Hadoop和MapReduce区别
Hadoop时一种分布式数据和计算的框架。它很擅长存储大量的半结构化的数据集。数据可以随即存放,所以一个磁盘的失败并不会带来数据丢失。Hadoop也非常擅长分布式计算——快速的跨多台机器处理大型数据集合
MapReduce时处理大量半结构化数据集合的编程模型。编程模型是一种处理并结构化特定问题的方式。例如,在一个关系数据库中,使用一种集合语言执行查询,如SQL。告诉语言想要的结果,并将他提交给系统来计算出如何产生计算。还可以 用更传统的语言(C++、Java),一步步的来解决问题。这是两种不同的编程模型,MapReduce就是另一种
MapReduce和Hadoop时相互独立的,实际上又能相互配合工作得很好。















 1974
1974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









