







文章目录
一、Hadoop是什么?
1.Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
2.Hadoop主要解决两件事:海量数据的存储、海量数据的分析计算。
3.广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
二、Hadoop的版本
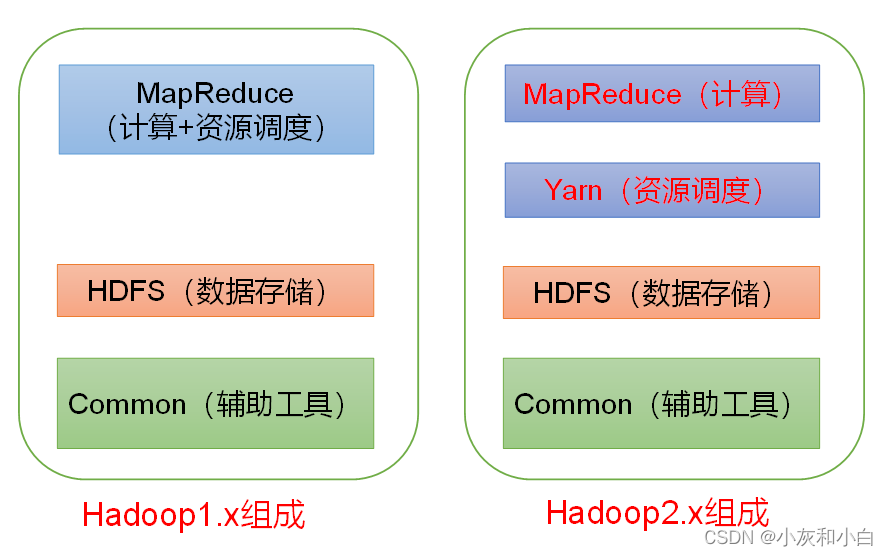
1.0版本HDFS负责海量数据存储,MapReduce负责海量数据计算和资源调度
2.0版本yarn负责资源调度,管理CPU和内存
3.0版本只是在细节上有变化
三、Hadoop的组成部分
1.HDFS
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。
(1) NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
(2)DataNode(dn):在本地文件系统存储文件数据库,以及块数据的校验和。
(3) Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。
2.YARN
Yet Another Resource Negotiator简称YARN ,另一种资源协调者,是Hadoop的资源管理器。
(1)ResourceManager(RM):整个集群资源(内存、CPU等)的管理者。
(2)NodeManager(NM):单个节点服务器的管理者。
(3)ApplicationMaster(AM):单个任务运行的管理者。
(4)Container:容器,相当于一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等。
注:客户端可以有多个。
集群上可以运行多个ApplicationMaster。
每个NodeManager上可以有多个Container.
3.MapReduce
MapReduce将计算过程分为两个阶段:Map和Reduce
(1)Map阶段并行处理输入数据
(2)Reduce阶段对Map结果进行汇总
4.HDFS、YARN、MapReduce三者的关系
MapReduce负责任务的运行,YARN负责任务调度需要的资源,HDFS负责任务输入输出的数据存储。
四、Hadoop的目录结构
1.查看Hadoop目录结构
[user@hadoop102hadoop-3.1.3]$ ll
总用量 52
drwxr-xr-x.2 user user 4096 5月 22 2017 bin
drwxr-xr-x.3 user user 4096 5月 22 2017 etc
drwxr-xr-x.2 user user 4096 5月 22 2017 include
drwxr-xr-x.3 user user 4096 5月 22 2017 lib
drwxr-xr-x.2 user user 4096 5月 22 2017 libexec
-rw-r--r--.1 user user 15429 5月 222017 LICENSE.txt
-rw-r--r--.1 user user 101 5月 22 2017 NOTICE.txt
-rw-r--r--.1 user user 1366 5月 22 2017 README.txt
drwxr-xr-x.2 user user 4096 5月 22 2017 sbin
drwxr-xr-x.4 user user 4096 5月 22 2017 share
2.重要目录
(1)bin目录:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
五、Hadoop的配置
1.配置文件
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
(1)默认配置文件:
| 要获取的默认文件 | 文件存放在Hadoop的jar包中的位置 |
|---|---|
| [core-default.xml] | hadoop-common-3.1.3.jar/core-default.xml |
| [hdfs-default.xml] | hadoop-hdfs-3.1.3.jar/hdfs-default.xml |
| [yarn-default.xml] | hadoop-yarn-common-3.1.3.jar/yarn-default.xml |
| [mapred-default.xml] | hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml |
(2)自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在$HADOOP_HOME/etc/hadoop这个路径上,用户可以根据项目需求重新进行修改配置。
2.配置集群
(1)核心配置文件
配置core-site.xml
文件内容如下:
<?xmlversion="1.0" encoding="UTF-8"?>
<?xml-stylesheettype="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为user -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>user</value>
</property>
</configuration>
(2)HDFS配置文件
配置hdfs-site.xml
<?xmlversion="1.0" encoding="UTF-8"?>
<?xml-stylesheettype="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
(3)YARN配置文件
配置yarn-site.xml
文件内容如下:
<?xml version="1.0"encoding="UTF-8"?>
<?xml-stylesheettype="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
(4)MapReduce配置文件
配置mapred-site.xml
<?xmlversion="1.0" encoding="UTF-8"?>
<?xml-stylesheettype="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(5)配置workers
也是在$HADOOP_HOME/etc/hadoop目录下,如/opt/module/hadoop-3.1.3/etc/hadoop/workers
hadoop102
hadoop103
hadoop104
添加集群服务器主机名字
注:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
3.启动集群
如果集群是第一次启动,需要在hadoop102节点格式化NameNode(注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化。)
六、Hadoop常用端口号
| 端口名称 | Hadoop2.x | Hadoop3.x |
|---|---|---|
| NameNode内部通信端口 | 8020 / 9000 | 8020 / 9000/9820 |
| NameNode HTTP UI(对用户的查询端口) | 50070 | 9870 |
| MapReduce查看执行任务端口(yarn查看服务运行的情况) | 8088 | 8088 |
| 历史服务器通信端口 | 19888 | 19888 |















 108
108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









