







 文章讨论了色情内容识别如何通过机器学习模型结合MD5识别进行有效管理,提及了使用大量训练数据和人工审核的过程。同时,还提到了Java开发者的学习资源,如《Java核心架构进阶知识点》的重要性。
文章讨论了色情内容识别如何通过机器学习模型结合MD5识别进行有效管理,提及了使用大量训练数据和人工审核的过程。同时,还提到了Java开发者的学习资源,如《Java核心架构进阶知识点》的重要性。
误杀一般都是加菲猫之类的…毕竟全身都是黄的。
具体百度网盘是怎么做的,我猜是机器学习+MD5识别。如果我来干这个的话,先按照经典的方法做一个模型出来,特征就是视频图像识别的特征+文件名文本特征+文件格式,大小等特征。模型拿个常见分类器就行了。
估计音频特征也可以,porn的音频特点也很明确(日语 or 英语那些词太明显了),一抓一个准。
继续丧心病狂的话就加视频特征。连续多帧里面人数量的变化啦(人数量相对固定,大都是一到两个,三四个也有,再多就不是那么常见了);人物移动的pattern啦(很少大范围的移动,而更多是小范围的往复运动);发生的场景啦(大都是室内小空间,并连续很多分钟都是一个场景啦,偶尔有一些外景)。
不过我觉得完全不需要这么复杂就可以做到很高的准确率了…
有模型之后,每隔一天或者几天,具体根据模型效率和机器的负载来决定,在网盘的图片和视频数据上跑一遍,把不该有的东西干掉,然后记录下MD5码。
这些MD5码就是黑名单了,往后每次用户新上传的时候就用这个MD5码做一次判断,不该有的就不让你传了。就是一次哈希查找,效率很快,根据百度网盘本身极速上传功能推断,百度已经有了很成熟的MD5操作的模块了。
这两个加起来就既满足了效果(靠机器学习模型每隔一段时间的精确判断),也满足了效率(MD5实时校验)。
所以呢,你们不要以为改了MD5码就可以逃得过去了,过一段时间人家重跑自动识别算法时还是会被干掉的…这种内容我党管的那么严,搞不好部门领导就要被喊去喝茶的,不可能不好好做的…
---------------------------------------闲扯的分割线--------------------------------
色情内容识别是一个很认真的研究领域好咩。不过…
干这个确实需要大量的训练数据。当年中科院计算所有一个组在做这方面的国家项目,黄色+反动内容识别。人家都是带着条子和公款去国外采购影片和轮子的东东回来做训练数据的…
我不懂事的时候有个女朋友花钱太厉害,逼的没办法去一家前著名论坛网站打零工做过类似项目,不过是自动识别黄色/反动的文本…
他们有积累了很久的人工识别的数据。招了不少人做类似鉴黄师的工作,三班倒每班连干八小时,拿一个简单的搜索引擎对用户发布的内容不停地用各种关键词搜,看到不该看的就删帖+搜集起来。然后这些人工识别的数据拿来给我们训练自动识别模型。
当时为了提高识别效果我被迫看了好多训练数据。。。。。。
我只能说…太刺激了…太暴力了…太有想象力了…
我原先只知道有黄色的,有反动的,没想到还有黄色+反动的…
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
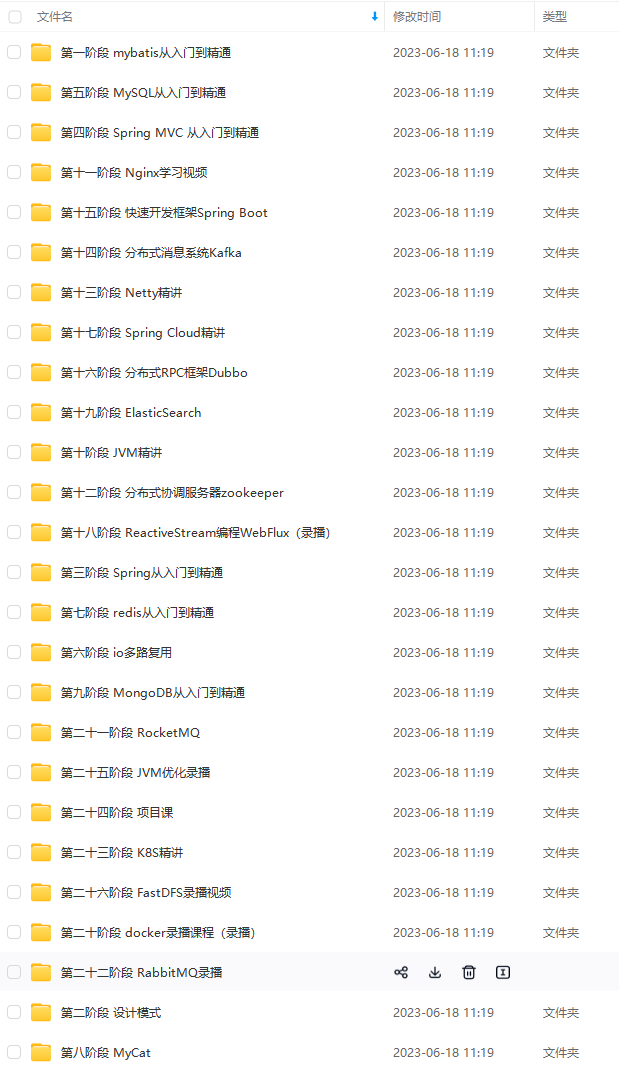
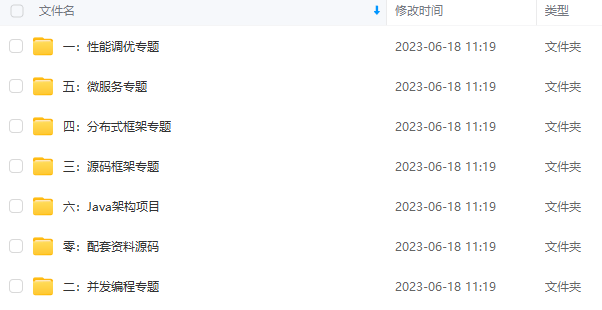
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

Java核心架构进阶知识点
面试成功其实都是必然发生的事情,因为在此之前我做足了充分的准备工作,不单单是纯粹的刷题,更多的还会去刷一些Java核心架构进阶知识点,比如:JVM、高并发、多线程、缓存、Spring相关、分布式、微服务、RPC、网络、设计模式、MQ、Redis、MySQL、设计模式、负载均衡、算法、数据结构、kafka、ZK、集群等。而这些也全被整理浓缩到了一份pdf——《Java核心架构进阶知识点整理》,全部都是精华中的精华,本着共赢的心态,好东西自然也是要分享的



内容颇多,篇幅却有限,这就不在过多的介绍了,大家可根据以上截图自行脑补
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
码讲义》点击传送门即可获取!**


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









