







平方误差函数是怎么来的?
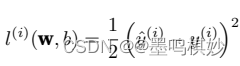
我们知道在线性回归(Linear Regeration)中,我们想找到的就只有两个量:
1.权重向量(W)
2.偏置项(b)
然后知噪声=真实值-预测值:
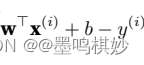
这个得到的噪声,有两种理解,
1.由于它是噪声,那么它越小越好,这样预测结果更偏向真实值,而且由于偏差有正有负,所以又有两种方法,一是取绝对值,二是取平方,那么这个偏差越小,这个预测就越精确;
2.由于数据很多,所以存在噪声是必然的,因为没有一条直线可以完全经过所有的点,误差的纯在必然,但是对于大量数据,理论上说它符合高斯正态分布:
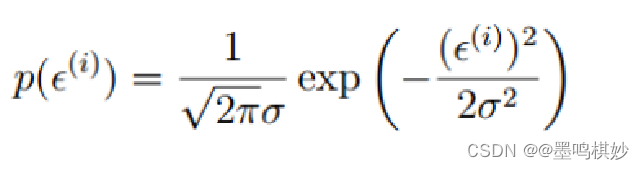
将残差带入高斯正态分布函数里,可以得到:
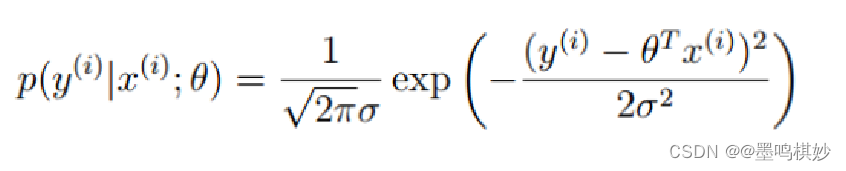 此处没有带b这个偏置项
此处没有带b这个偏置项
![]()
得到关于残差的似然函数,为了简化运算,对似然取对数,得: 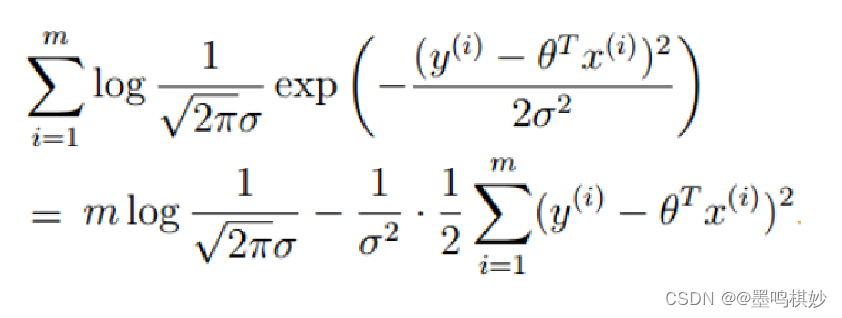
这个就是似然函数的公式,似然越大,则说明条件取得越优秀。
所以让![]() 越小,似然越大。
越小,似然越大。
自用,笔记。















 9247
9247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









