






目录
List:有序可重复字符串集合,支持两端插入/删除,可实现队列、栈、消息队列等,底层是双向链表或压缩链表
Sorted Set(有序集合):带分数的有序集合,按分数排序
Redis(Remote Dictionary Server)是一个开源的、基于内存的数据存储系统,通常被用作数据库、缓存和消息中间件。
Redis的下载与安装
Redis的下载
Linux 版 (适用于企业级开发)
- Redis 高级开始使用
- 以4.0 版本作为主版本
Windows 版本 (适合零基础学习)
- Redis 入门使用
- 以 3.2 版本作为主版本
- 下载地址:https://github.com/MSOpenTech/redis/tags
Redis核心文件
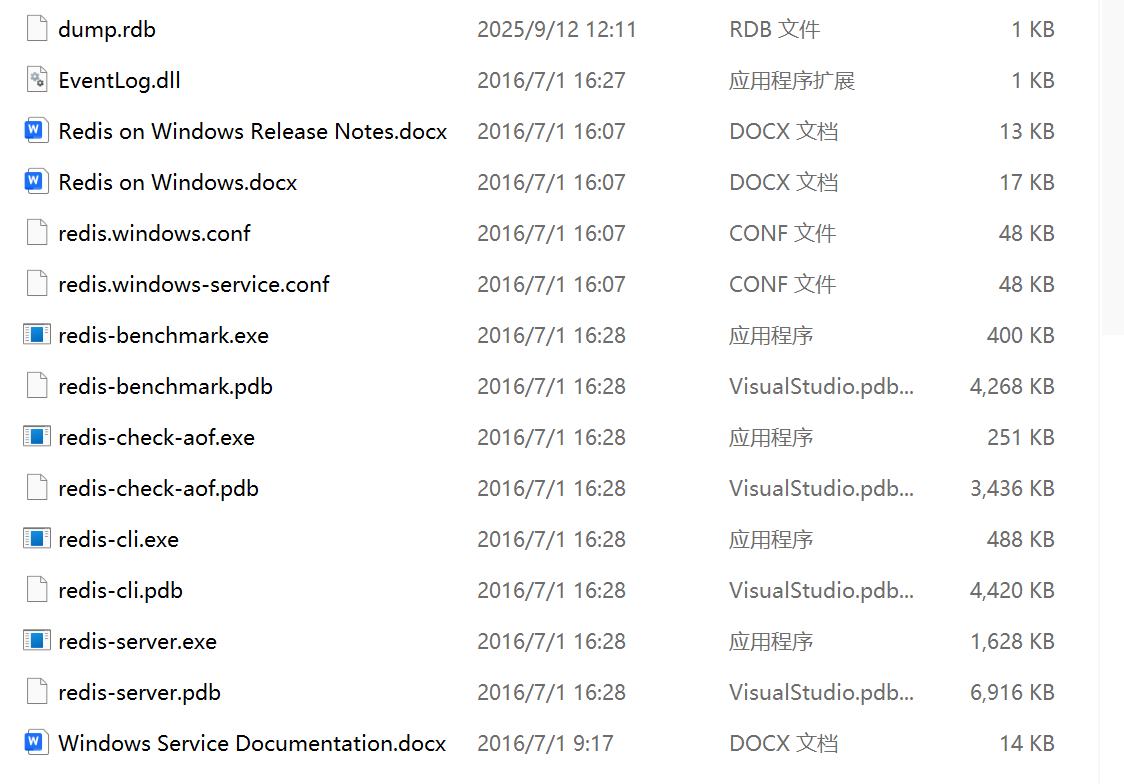
核心文件:
- redis-server.exe 服务器启动命令
- redis-cli.exe 命令行客户端
- redis.windows.conf redis核心配置文件
- redis-benchmark.exe 性能测试工具
- redis-check-aof.exe AOF文件修复工具
- redis-check-dump.exe RDB文件检查工具(快照持久化文件)
启动Redis
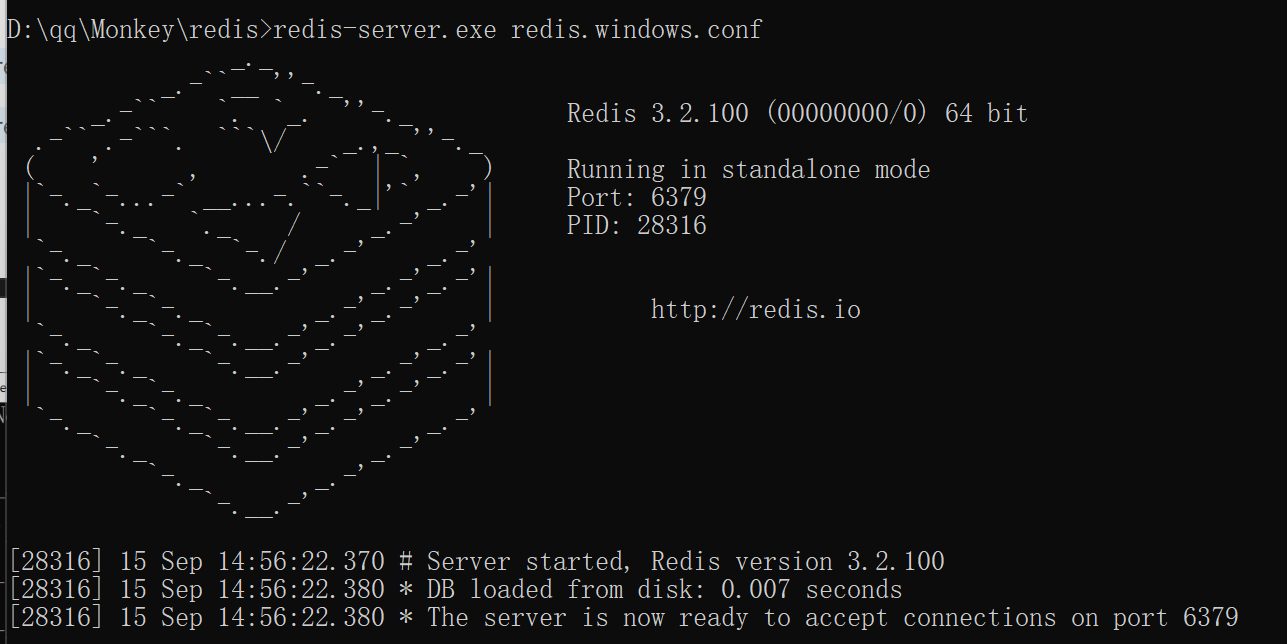
服务器启动
方式1:双击redis-server.exe
方式2:指令redis-server.exe redis.windows.conf
客户端连接
双击redis-cli.exe
Redis基本操作
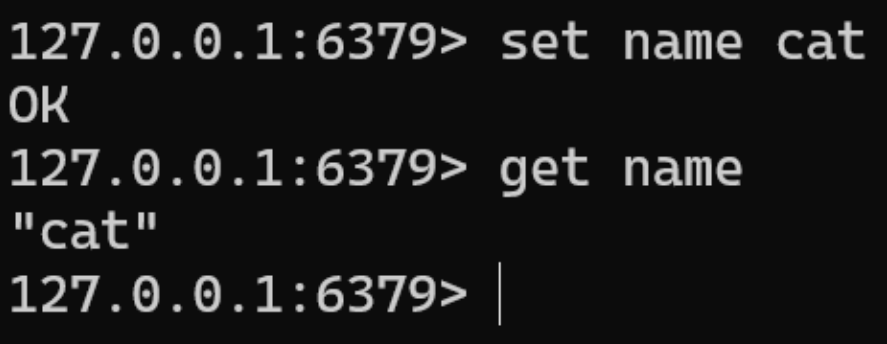
信息添加
- 功能:设置 key,value 数据
- 命令: set key value
信息查询
- 功能:根据 key 查询对应的 value,如果不存在,返回空(nil)
- 命令: get key
清除屏幕信息
- 功能:清除屏幕中的信息
- 命令:clear
退出客户端命令行模式
- 功能:退出客户端
- 命令:quit exit 按钮
帮助
- 功能:获取命令帮助文档,获取组中所有命令信息名称
- 命令: help 命令名称 或者 help @组名
Redis数据类型(5种常用)
- redis 数据存储格式 redis 自身是一个 Map,其中所有的数据都是采用 key : value 的形式存储
- 数据类型指的是存储的数据的类型,也就是 value 部分的类型,key 部分永远都是字符串
key的语法:
- 在一个项目中,key最好使用统一的命名模式
- key区分大小写
- key不要太长,尽量不要超过1024字节。不仅消耗内存,也会降低查找的效率
- key不要太短,太短可读性会降低
String:最基本类型,可存储字符串、数字或二进制数据。
- 是二进制安全的,即可以存储任何编码的字符串(如 UTF-8、二进制数据),最大长度为 512MB。 支持对字符串的部分操作(如截取子串),以及对数字的自增 / 自减(INCR/DECR)、范围增减(INCRBY/DECRBY)等
- 当字符串长度较短(<= 20 字节)且是整数时,使用 int 编码(直接存储为长整型)。 当字符串长度较长或非整数时,使用 raw 编码(简单动态字符串 SDS 结构,便于修改和避免缓冲区溢出)。


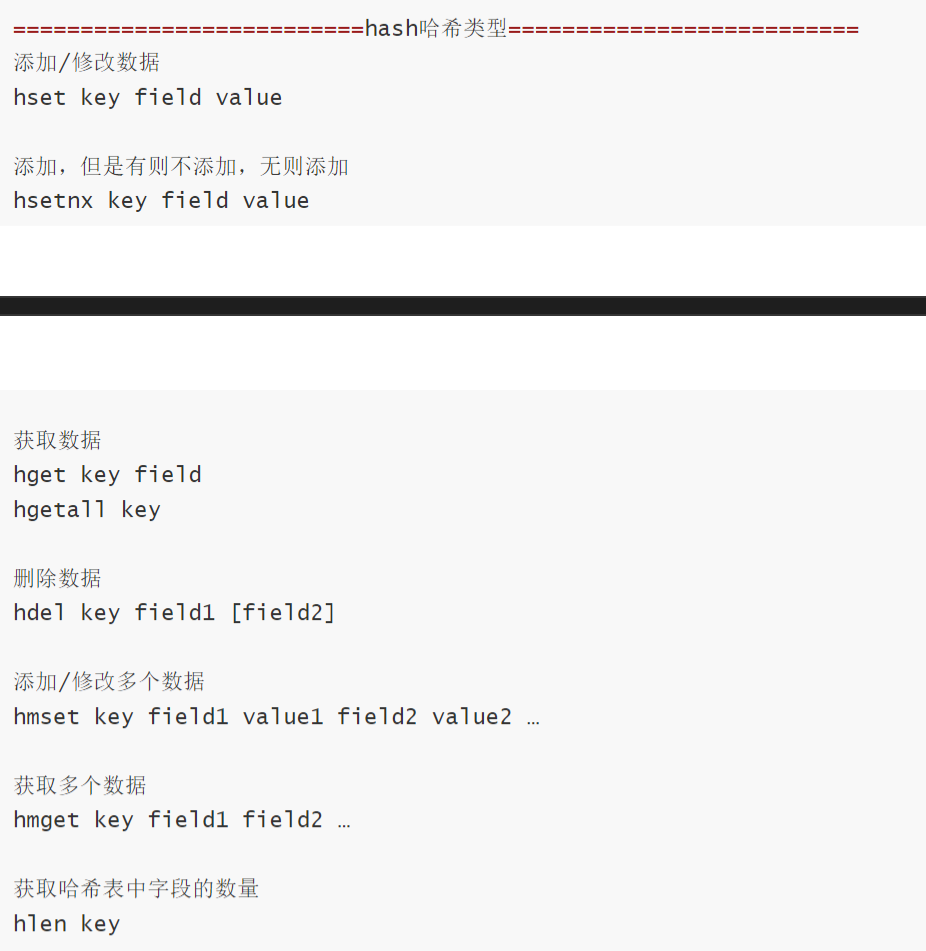
Hash:键值对集合,适合存储对象
- 适合存储结构化数据(如用户信息:id、name、age 等),可单独操作某个字段(无需修改整个对象)。 占用空间比 String 存储序列化对象更高效(减少键名冗余)
- 当 Hash 中字段数量少且字段 / 值较短时,使用 ziplist(压缩列表)编码,节省空间。 当字段数量或长度超过阈值(默认字段数 > 512 或单个字段 / 值长度 > 64 字节),转为 hashtable(哈希表)编码,提升查询效率。

List:有序可重复字符串集合,支持两端插入/删除,可实现队列、栈、消息队列等,底层是双向链表或压缩链表
- 是 “双端队列”,可在头部(left)和尾部(right)高效操作(时间复杂度 O (1))。 支持按索引访问元素,但索引越大效率越低(时间复杂度 O (n))。
- 当列表元素少且元素长度短时,使用 ziplist(压缩列表)编码。 当元素数量或长度超过阈值(默认元素数 > 512 或单个元素长度 > 64 字节),转为 linkedlist(双向链表)编码,避免压缩列表的连锁更新问题。 Redis 3.2 后引入 quicklist 编码,结合压缩列表和双向链表的优点(将链表分块,每块用压缩列表存储,平衡空间和效率)


Set:无序去重集合
- 支持高效的交集、并集、差集运算(时间复杂度与集合大小相关,通常优于客户端计算)。 查找元素是否存在的时间复杂度为 O (1)。
- 当元素全是整数且数量较少时,使用 intset(整数集合)编码,节省空间。 否则使用 hashtable(哈希表)编码,键为元素,值为 NULL(利用哈希表的去重特性)。

Sorted Set(有序集合):带分数的有序集合,按分数排序
- 兼具 Set 的去重特性和 List 的有序性,可按分数或索引范围获取元素。 查找、插入、删除的时间复杂度为 O (log n),支持按分数快速排序。
- 当元素数量少且元素长度短时,使用 ziplist(压缩列表)编码,按 “元素 + 分数” 的顺序存储,通过分数排序。 否则使用 skiplist(跳表)+ hashtable 编码:跳表按分数排序存储元素,支持范围查询;哈希表映射元素到分数,支持快速获取分数。

Jedis
如果我们要使用Java来操作Redis,就要用到Jedis(Redis官方推荐的 java连接开发工具! 使用Java 操作 Redis 中间件!)
导入依赖
<dependency>
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>4.4.3</version>
</dependency>示例代码
import redis.clients.jedis.Jedis;
public class JedisExample {
// 模拟从数据库获取用户信息的方法
public static String getFromDatabase(String userId) {
// 这里应该是真正的数据库查询逻辑,为了简单演示,直接返回模拟数据
System.out.println("从数据库中查询用户信息");
return "用户ID: " + userId + ", 姓名: 张三, 年龄: 25";
}
public static void main(String[] args) {
// 创建Jedis对象,连接到本地Redis服务器,默认端口是6379
Jedis jedis = new Jedis("localhost", 6379);
String userId = "123456";
// 尝试从Redis中获取缓存的用户信息
String cachedUserInfo = jedis.get(userId);
if (cachedUserInfo != null) {
System.out.println("从Redis缓存中获取到用户信息: " + cachedUserInfo);
} else {
// 如果Redis中没有缓存,从数据库获取
String userInfo = getFromDatabase(userId);
// 将获取到的用户信息存入Redis缓存,设置过期时间为60秒(这里的过期时间可根据业务需求调整)
jedis.setex(userId, 60, userInfo);
System.out.println("将用户信息存入Redis缓存");
System.out.println("获取到的用户信息: " + userInfo);
}
// 关闭Jedis连接
jedis.close();
}
}在初步认识了 Redis 的基础操作、数据类型以及 Jedis 客户端的使用后,我们已经能利用 Redis 实现简单的缓存等功能。但在实际生产环境中,仅掌握这些还远远不够。试想,若 Redis 服务器意外宕机,内存中的数据岂不是会全部丢失?这就涉及到 Redis 如何保证数据不丢失的持久化机制。此外,Redis 还有诸如事务、删除策略、企业级解决方案等更多强大的功能,它们能进一步拓展 Redis 的应用场景,解决更复杂的业务问题。小编将在下一篇章一一介绍,就让我们一起深入 Redis 的进阶世界,探索持久化及其他核心能力。
有问题欢迎留言!!!😗
肥嘟嘟左卫门就讲到这里啦,记得一键三连!!!😗
敬请期待下一篇章!!!🐷

















 1178
1178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









