






目录
创建索引是一个非常危险的操作,如果数据量非常之大就触发大量的数据IO读取,可能会把机器搞的卡死,所以在最初建表的时候要合理规划好
1.索引的介绍
索引是一种特殊的文件,包含对数据表里所有记录的引用指针,可以对表里的列创建索引,并且指定索引类型,索引有自己的特殊的数据结构。
如果把表比作图书,数据就是书记的内容,索引就是书本的目录可以让我们很快速的查找到自己想要的内容。
2.索引的利弊
索引的作用是方便快速找到数据,相当于在数据库中,构建一个特殊的‘目录’(一系列特定的数据结构,硬盘)。通过这种方式,加快查询速度避免对数据一一遍历耗时耗力。
1.引入索引需要付出额外的空间代价
在当代也许会为了追求速度而舍弃空间,硬盘可以想加就加。
但是在嵌入式设备上,空间是固定大小的,硬件条件也是比较紧张的。不是说加就加的。
2.引入索引后,确实可以大大提高查找效率但是,可能会影响到增删查改的效率
当通过条件判断的方式来删除数据时,delete from 表名 where id = 5;
这样就不会影响到效率。
但是如果是插入数据,数据量发生变化,随影索引就需要调整,这样反而会使效率降低。
即便如此还是非常推荐适应索引的,因为在日常开发中大多数是查找删除数据,增加数据相对较少。
1.查看索引
show index from 表名;

PRIMARY 是给主键自动生成的索引,不需要手动创建,只要指定啦主键就会自动成对应的索引。
id 是手动生成的索引。
2.创建索引
unique ,primary key 会自动创建索引
对于非主键,非唯一约束,非外键字段,可以创建普通所引。
create index 索引名 on 表名(列名);
针对某一列创建的索引,只有在查询某列时才能生效。

创建索引是一个非常危险的操作,如果数据量非常之大就触发大量的数据IO读取,可能会把机器搞的卡死,所以在最初建表的时候要合理规划好
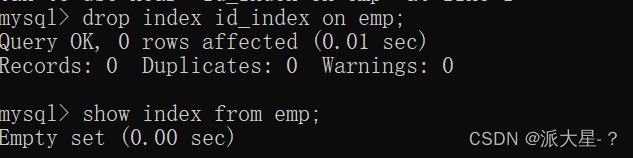
删除索引
删除索引只能删除自己创建的,不能删除自动创建出来的,删除索引也是非常危险的操作。
drop index 索引名 on 表名;
索引背后的数据结构
所谓构建索引其实就是引入一些数据结构,对数据进行储存管理,从而提高查找速度。
常见的数据结构有,顺序表,链表,栈,队列,二叉树(二叉搜索树),堆,哈希表
顺序表虽然查找速度非常之快,一旦数据量非常之大的时候,对数据增加就会非常繁琐。
链表增加数据节点会非常方便但是对于数据的查找很慢,极有可能会一一遍历。也不行
栈与队列都不占优势,他们所能提供的作用非常小,功能非常小。
二叉搜索树 如果遇到所有数据依次递增,就会以O(n)的速度遍历,效率低下
哈希表可以提高查找速率,近似O(1)完成查找。但是只能进行数据‘相等的查找’,对‘>',"<"无法进行查询。
因为哈希表通过哈希函数,把查询的key映射成数组下标,
key1>key2 不一定等于hash(key1) > hash(key2);
B-树:也就是N叉搜索树,每个节点可以有多个子树
这样就可以降低树的高度,每个节点储存多个key值。

B-树虽然高度降低啦但是每个节点比较的次数变多啦,真的比二叉树有优势吗?
虽然比较的节点变多啦,但是还是很有优势的,每个节点访问的时候只需要进行一次硬盘的读取就ok了,就可以把这个节点的数据全部读取出来,接下来的都是在内存中执行的啦。
最终的目的是减少硬盘IO的次数,不是为了减少比较次数。
可以对B-树进一步改造,B+树
B+树也是N叉搜索树。

特点:所有叶子节点,就构成啦整个数据的全集。叶子节点相互连接是相双向链表。
1.N叉搜索树,高度低,硬盘IO次数少。
2.叶子节点是全集,并且用链表结构链接,非常便于查询。
3.B+树所有查询都是落到叶子节点上完成的,
4.稳定:每次查询所经历的IO次数和比较次数是差不多的,查询的开销是稳定的。
5.B+树叶子节点是全集,非叶子节点不需要储存’‘数据行’‘,只需要储存索引列的key即可。
甚至这种结构可以将数据全部加载到内存中,这样又可以减少硬盘IO次数。















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









