







🌸个人主页:https://blog.csdn.net/2301_80050796?spm=1000.2115.3001.5343
🏵️热门专栏:🍕 Collection与数据结构 (91平均质量分)https://blog.csdn.net/2301_80050796/category_12621348.html?spm=1001.2014.3001.5482
🧀Java EE(94平均质量分) https://blog.csdn.net/2301_80050796/category_12643370.html?spm=1001.2014.3001.5482
🍭MySql数据库(93平均质量分)https://blog.csdn.net/2301_80050796/category_12629890.html?spm=1001.2014.3001.5482
🍬算法(97平均质量分)https://blog.csdn.net/2301_80050796/category_12676091.html?spm=1001.2014.3001.5482
感谢点赞与关注~~~

1. 只出现一次的数字(难度:🟢1度)
- 题目描述
给你一个 非空 整数数组 nums ,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
你必须设计并实现线性时间复杂度的算法来解决此问题,且该算法只使用常量额外空间。
示例 1 :
输入:nums = [2,2,1]
输出:1
示例 2 :
输入:nums = [4,1,2,1,2]
输出:4
示例 3 :
输入:nums = [1]
输出:1
-
题目解析
- 这里我们使用Set这样的容器来解决这样的问题
- 要是这个数字在Set中存在,就删除元素,要是不存在,就添加元素.
- 最后使用迭代器遍历Set,并返回最终只出现了一次的数字.
-
代码编写
class Solution {
public int singleNumber(int[] nums) {
Set<Integer> set = new HashSet<>();
for (int i = 0;i < nums.length;i++){
if (!set.contains(nums[i])){
set.add(nums[i]);
}else{
set.remove(nums[i]);
}
}
for (int x:set){//使用迭代器获取到Set中的元素
return x;
}
return -1;
}
}
2. 复制带随机指针的链表(难度:🟡3度)
- 题目描述
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示 Node.val 的整数。
random_index:随机指针指向的节点索引(范围从 0 到 n-1);如果不指向任何节点,则为 null 。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例 1:
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例 2:
输入:head = [[1,1],[2,1]]
输出:[[1,1],[2,1]]
示例 3:
输入:head = [[3,null],[3,0],[3,null]]
输出:[[3,null],[3,0],[3,null]]


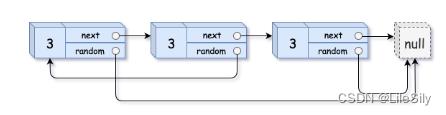
- 题目解析
- 首先,这里有的同学会以为直接把原来链表的random地址和next地址直接复制到新的链表中即可,这种做法是绝对错误的!
复制下来的next不是指向新链表的下一个结点,而是指向了原来列表的下一个结点,同理,复制下来的random不是指向新链表的任意结点,而是指向原链表的任意结点. - 为了避免上述的错误,我们必须要有一种数据结构,使得新的链表地址和旧的链表地址形成一一映射的关系,所以我们可以使用Map来实现.
- 每当new出一个新的结点,就把原来旧的结点和新的结点在Map中形成映射.
- 首先,这里有的同学会以为直接把原来链表的random地址和next地址直接复制到新的链表中即可,这种做法是绝对错误的!
- 代码编写
/*
// Definition for a Node.
class Node {
int val;
Node next;
Node random;
public Node(int val) {
this.val = val;
this.next = null;
this.random = null;
}
}
*/
class Solution {
public Node copyRandomList(Node head) {
Map<Node,Node> map = new HashMap<>();
Node cur = head;
while (cur != null){
Node node = new Node(cur.val);
map.put(cur,node);//通过map把cur和Node建立一一映射的关系
cur = cur.next;
}
Node cur1 = head;
while (cur1 != null){//把新的链表中的random和next使用Map写入
map.get(cur1).random = map.get(cur1.random);
map.get(cur1).next = map.get(cur1.next);//核心的两行代码
cur1 = cur1.next;
}
return map.get(head);
}
}
3. 宝石与石头(难度:🟢1度)
- 题目描述
给你一个字符串 jewels 代表石头中宝石的类型,另有一个字符串 stones 代表你拥有的石头。 stones 中每个字符代表了一种你拥有的石头的类型,你想知道你拥有的石头中有多少是宝石。
字母区分大小写,因此 “a” 和 “A” 是不同类型的石头。
示例 1:
输入:jewels = “aA”, stones = “aAAbbbb”
输出:3
示例 2:
输入:jewels = “z”, stones = “ZZ”
输出:0
- 题目解析
- 首先我们使用Set来解决这个问题
- 把宝石都添加进set中.
- 定义count变量来记录stone中宝石的个数.
- 遍历stone,看在set中是否存在,如果存在,就count++
- 代码编写
class Solution {
public int numJewelsInStones(String jewels, String stones) {
Set<Character> set = new HashSet<>();
int count = 0;
for (int i = 0;i < jewels.length();i++){
set.add(jewels.charAt(i));
}
for (int i = 0;i < stones.length();i++){
if(set.contains(stones.charAt(i))){
count++;
}
}
return count;
}
}
4. 字母在句子中出现的次数(难度:🟢1度)
- 题目描述
统计控制台输入的一句话中不同字⺟字符出现的次数。例如:现有字符串"Hello World!",上述字符串中各个字符的出现的次数为:
H:1
e:1
l:3
o:2
W:1
r:1
d:1
(不考虑数字、空格和特殊字符的个数,按照字符在字符串中出现的顺序显示。相同字母的大小写算两个不同字符)
- 题目解析
- 首先这道题用到了字母和数字的映射关系,我们就需要用到Map.
- 与第一题的做法类似,如果Map中没有这个key,我们就可以添加这个key,并指定值为1,之后都在1的基础上进行++.
- 这道题需要用一定的限制条件去除英文字母以外的字符:
if (line.charAt(i) > 'A' && line.charAt(i) < 'z')
- 代码编写
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
String line = scanner.nextLine();
Map<Character, Integer> map = new LinkedHashMap<Character, Integer>();
//write your code here......
for (int i = 0;i < line.length();i++){
if (line.charAt(i) > 'A' && line.charAt(i) < 'z'){
if (map.get(line.charAt(i)) == null){
map.put(line.charAt(i),1);
}else{
int val = map.get(line.charAt(i));
map.put(line.charAt(i),val+1);
}
}
}
Set<Map.Entry<Character, Integer>> entrys = map.entrySet();
for (Map.Entry<Character, Integer> entry : entrys) {
System.out.println(entry.getKey() + ":" + entry.getValue());
}
}
}
5. 前K个高频单词(难度:🟠4度)
- 题目描述
给定一个单词列表 words 和一个整数 k ,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序 排序。
示例 1:
输入: words = [“i”, “love”, “leetcode”, “i”, “love”, “coding”], k = 2
输出: [“i”, “love”]
解析: “i” 和 “love” 为出现次数最多的两个单词,均为2次。
注意,按字母顺序 “i” 在 “love” 之前。
示例 2:
输入: [“the”, “day”, “is”, “sunny”, “the”, “the”, “the”, “sunny”, “is”, “is”], k = 4
输出: [“the”, “is”, “sunny”, “day”]
解析: “the”, “is”, “sunny” 和 “day” 是出现次数最多的四个单词,
出现次数依次为 4, 3, 2 和 1 次。
- 题目解析
- 首先我们要解决的问题是TOP-K问题,我们就要使用优先级队列.
- 这里我们要统计单词的出现次数,我们就使用到了字符串和数字的映射关系,所以我们使用Map来保存这种关系
- 优先级队列中存储的是Map中的映射关系,而映射关系在优先级队列中没有比较规则,所以我们需要给优先级队列传入比较器.
- 创建小根堆来完成降序排序.
- 如果优先级队列中不满k个元素,一直添加元素,满了之后把之后遍历到的元素的value值和堆顶进行比较,如果比堆顶小,不做处理,如果比堆顶大,让堆顶出队列,把遍历到的元素添加进去.
- 最后添加进顺序表中逆序并返回.
- 需要注意的是如果这里两个单词的字典序相同的时候,需要按照大根堆的顺序排列,因为之后是字典序小的入了队,但是最后还要翻转.
- 代码实现
class Solution {
public List<String> topKFrequent(String[] words, int k) {
PriorityQueue<Map.Entry<String,Integer>> queue = new PriorityQueue<>(new Comparator<Map.Entry<String,Integer>>(){
public int compare(Map.Entry<String,Integer> o1,Map.Entry<String,Integer> o2){
if (o1.getValue().compareTo(o2.getValue()) == 0){//如果这里两个单词的字典序相同的时候,需要按照大根堆的顺序排列,因为之后是字典序小的入了队,但是最后还要翻转
return o2.getKey().compareTo(o1.getKey());
}
return o1.getValue().compareTo(o2.getValue());
}
});
Map<String,Integer> map = new HashMap<>();
for(int i = 0;i < words.length;i++){
if (map.get(words[i]) == null){
map.put(words[i],1);
}else{
int val = map.get(words[i]);
map.put(words[i],val+1);
}
}
for (Map.Entry<String,Integer> entry:map.entrySet()){
if(queue.size() < k){
queue.offer(entry);
}else{//注意引用类型比较的时候,使用compareTo方法和equals方法
if (queue.peek().getValue().compareTo(entry.getValue()) < 0){
queue.poll();
queue.offer(entry);
}else if(queue.peek().getValue().equals(entry.getValue())){
if (queue.peek().getKey().compareTo(entry.getKey()) > 0){
//字典序小的入队
queue.poll();
queue.offer(entry);
}
}
}
}
List<String> list = new ArrayList<>();
for (int i = 0;i < k;i++){
list.add(queue.poll().getKey());
}
Collections.reverse(list);//集合类的翻转
return list;
}
}















 991
991











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









