








问题描述
有时候我们想将文章复制到博客哪里,却发现【外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传】,的错误提示,
 无奈只能一张一张图片复制,少量图片还行,要是几十张图片就有点显的麻烦了,接下来我将介绍一种将语雀当做图床来解决此问题
无奈只能一张一张图片复制,少量图片还行,要是几十张图片就有点显的麻烦了,接下来我将介绍一种将语雀当做图床来解决此问题
解决方案
这里我将以思源笔记为例子教大家如何解决此问题,其他笔记软件都一个样的
-
下载语雀登录即可
-
在要发布的文章那里选择导出预览模式
-
公众号和知乎随便选择一个,复制到语雀,并等待期完成保存
-
将文章在语雀那里复制回来思源

可以看到已经有图床标志了
-
因为思源采用的是markdown语法,而语雀采用的是富文本,复制回来多少回有点毛病,最后一步,就是替换法,将思源笔记的本地图片替换云端图片
-
首先在同一个文件夹中创建两个md文件形式[名称随意]的文件
-
一个是存储笔记软件那篇文章,另一个是存储具有图床标识的文章即可,不用分辨名称直接他会识别
-
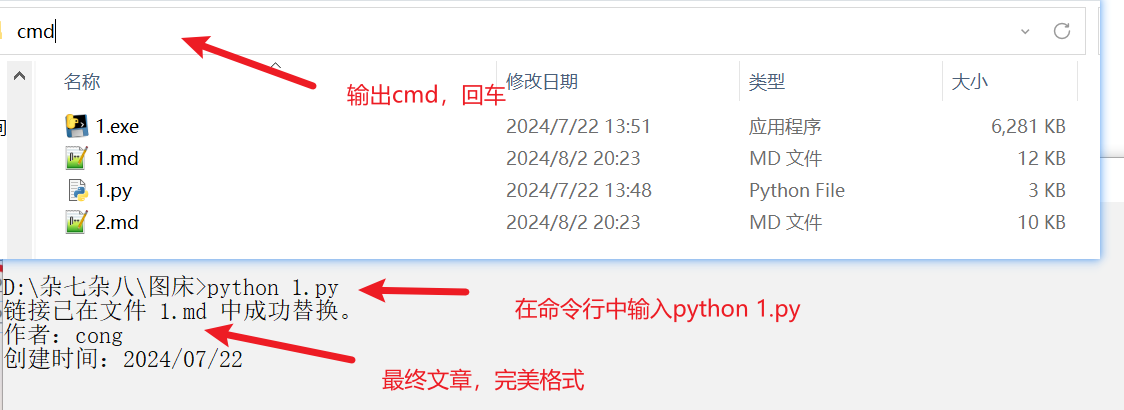
双击运行1.exe即可,你也可以在当前文件夹输入cmd,再次输入python 1.py,根据提示将对应的文件中的文章复制出来即可
-



总结
以上就是解决图床的问题的方案,最后几步用脚本时确保他的格式是markdown语法格式,如果你所在的博客平台是富文本的话,就不用写脚本了,脚本的原理就是通过将图片的本地链接转化为语雀的图片链接,其他的笔记软件可以参考此方法,照抄可能不行,虽然有点麻烦,但是可以白嫖,你们也可以使用软件的图床功能,最后附上我的脚本链接:
https://pan.baidu.com/s/1j5O9dGG5L9mQzwUwqtZTtw?pwd=cong
提取码:cong
–来自百度网盘超级会员V5的分享
脚本代码:
import re
import os
def extract_links(filename, pattern):
"""从指定文件中提取所有与正则表达式模式匹配的链接。"""
# 以读取模式打开文件,并指定UTF-8编码
with open(filename, 'r', encoding='utf-8') as file:
content = file.read() # 读取文件全部内容
# 使用正则表达式查找所有的匹配项
return re.findall(pattern, content)
def replace_links(source_content, old_links, new_links):
"""在源内容中替换旧链接为新链接。"""
# 遍历旧链接和新链接,进行替换
for old_link, new_link in zip(old_links, new_links):
# 仅替换第一次出现的匹配项
source_content = source_content.replace(old_link, new_link, 1)
return source_content # 返回替换后的内容
def find_md_files():
"""在当前目录下查找所有Markdown文件。"""
# 列出当前目录下的所有文件
files = os.listdir('.')
# 筛选出Markdown文件
return [file for file in files if file.endswith('.md')]
# 获取当前目录下的所有Markdown文件
md_files = find_md_files()
# 确定链接替换的源文件和目标文件
source_file = None
target_file = None
source_pattern = r'\!\[\]\(https://cdn\.nlark\.com/yuque/[^\)]+\)' # 源文件链接模式
target_pattern = r'\!\[.*?\]\(assets/[^\)]+\)' # 目标文件链接模式
# 遍历Markdown文件列表
for md_file in md_files:
# 从当前文件中查找源文件链接
links = extract_links(md_file, source_pattern)
if links:
source_file = md_file # 如果找到,记录源文件
else:
# 否则,从当前文件中查找目标文件链接
links = extract_links(md_file, target_pattern)
if links:
target_file = md_file # 如果找到,记录目标文件
# 如果找到了源文件和目标文件
if source_file and target_file:
# 提取源文件和目标文件中的链接
source_links = extract_links(source_file, source_pattern)
target_links = extract_links(target_file, target_pattern)
# 读取目标文件的内容
with open(target_file, 'r', encoding='utf-8') as file:
target_content = file.read()
# 替换目标文件中的链接
updated_content = replace_links(target_content, target_links, source_links)
# 将更新后的内容写回到目标文件
with open(target_file, 'w', encoding='utf-8') as file:
file.write(updated_content)
# 输出替换成功的通知
print("链接已在文件", target_file, "中成功替换。")
else:
# 如果没有找到合适的源文件或目标文件,输出错误信息
print("未能找到合适的源Markdown文件或目标Markdown文件。")
input("作者:cong\n创建时间:2024/07/22")


















 1665
1665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











