







前言
在数据库系统中,多个事务的并发执行是不可避免的。然而,并发执行可能导致数据不一致的情况。为了解决这个问题,数据库管理系统(DBMS)使用调度策略来控制事务的执行顺序。本文将简洁地介绍可串行化调度这一概念,帮助你理解如何确保多个事务的并发执行不会导致数据错误。
什么是可串行化调度?
可串行化调度 是指多个事务并发执行的结果,必须与某种顺序下串行执行这些事务的结果相同。换句话说,即使事务是交叉执行的,只要结果和按某个顺序串行执行时的结果一致,我们就可以认为这个调度是正确的。
为什么可串行化调度重要?
在一个理想的数据库环境中,所有事务都应该串行执行,这样可以确保数据的一致性。然而,现实中事务往往是并发执行的。如果不加控制,可能会导致数据不一致。因此,确保并发调度的结果与串行执行的结果相同,是保证数据正确性的关键。
可串行化调度的例子
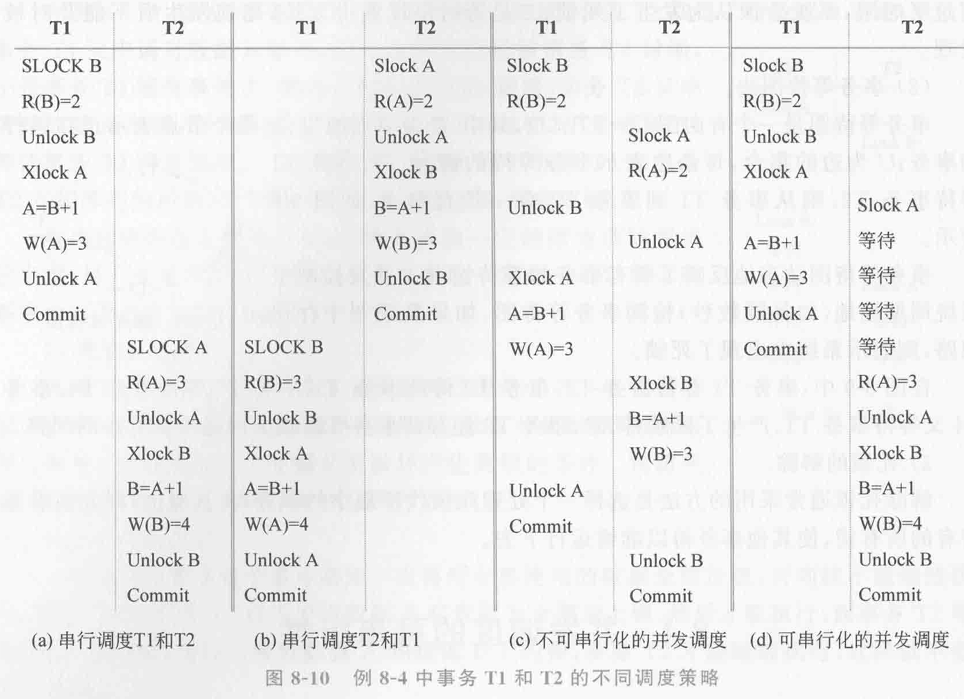
让我们来看一个简单的例子,以便更好地理解可串行化调度。
事务T1:
- 读取数据B
- A = B + 1
- 写回A
事务T2:
- 读取数据A
- B = A + 1
- 写回B
假设数据A和B的初值都是2。根据不同的调度策略,结果可能会有所不同:
-
串行调度1(T1先执行,T2后执行) :
- T1执行后,A = 3,B = 2。
- T2接着执行,B = A + 1 = 3。
最终结果:A = 3,B = 3。
-
串行调度2(T2先执行,T1后执行) :
- T2执行后,B = 3,A = 2。
- T1接着执行,A = B + 1 = 4。
最终结果:A = 4,B = 3。
并发调度:
如果事务T1和T2同时执行,但没有进行正确的调度控制,可能会发生不可预料的结果。例如,如果T1读取了B的旧值2,T2读取了A的旧值2,那么最后可能会得到A = 3,B = 3,这与任何一种串行调度的结果都不相同。因此,这样的调度是不可串行化的。
冲突可串行化调度
在并发事务中,如果不同事务对同一数据的操作涉及到至少一个写操作,就会产生冲突。冲突的操作是不能交换执行的,它们必须保持一定的执行顺序。我们称这样的调度为冲突可串行化。
冲突的类型:

- 读-读冲突:两个事务读取同一个数据(不冲突)。
- 写-读冲突:一个事务写数据,另一个事务读同一数据(冲突)。
- 读-写冲突:一个事务读数据,另一个事务写同一数据(冲突)。
- 写-写冲突:两个事务都写同一个数据(冲突)。
举例:
 假设有两个事务T1和T2,T1读写数据A,T2读写数据B,且它们的操作顺序如下:
假设有两个事务T1和T2,T1读写数据A,T2读写数据B,且它们的操作顺序如下:
- T1:读A -> 写A -> 读B -> 写B
- T2:读A -> 写A -> 读B -> 写B
在这种情况下,T1和T2的操作顺序发生了一些交错,如果通过交换不冲突的操作,能够将它们的操作顺序调整为某种串行顺序,那么这个调度就称为冲突可串行化。
如何判断调度是否是冲突可串行化的?
判断一个调度是否是冲突可串行化的,可以通过交换不冲突的操作来实现。如果在保证冲突操作顺序不变的前提下,能够通过交换不冲突的操作将调度转换为串行调度,那么该调度就是冲突可串行化的。
例子:

假设有一个调度SC=R1(A) W1(A) R2(A) W2(A) R1(B) W1(B) R2(B) W2(B),我们可以通过交换不冲突的操作来判断它是否为冲突可串行化的调度。
- R1(B) 和 W2(A) 是不同事务对不同数据的操作,不冲突,可以交换。
- 继续交换其他不冲突的操作,直到形成一个串行调度。
最终我们得到的调度与串行调度一致,因此这个调度是冲突可串行化的。
总结:可串行化调度的实际应用
在实际的数据库系统中,可串行化调度 是并发控制的核心原则之一。它确保了多个事务并发执行时,不会引发数据的不一致性问题。通过使用冲突可串行化的判断标准,数据库系统可以在保证正确性的前提下,提高并发执行的效率。
















 1789
1789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











