






微服务
一:MP补充:
1.1.注解:

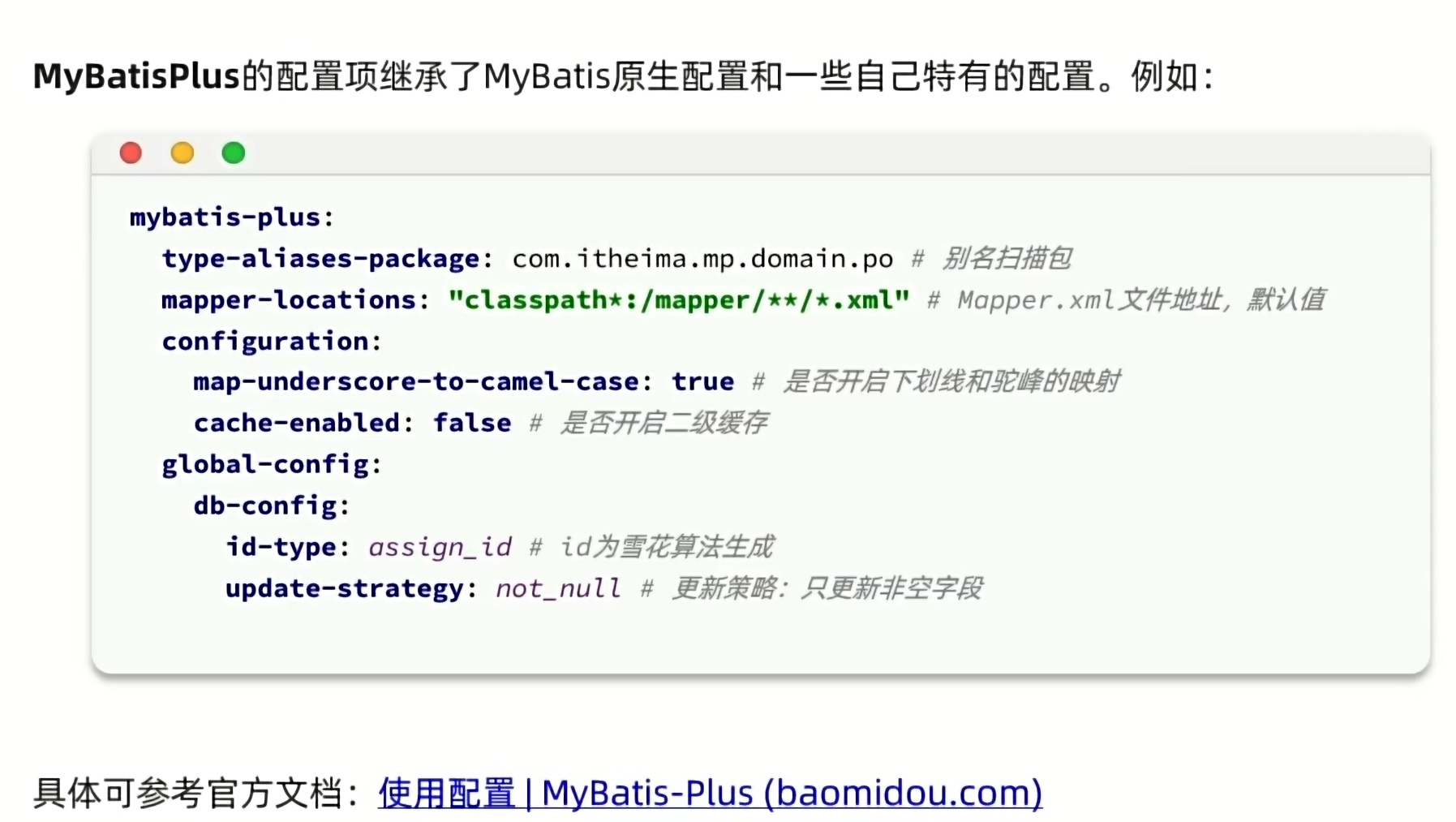
1.2.配置:
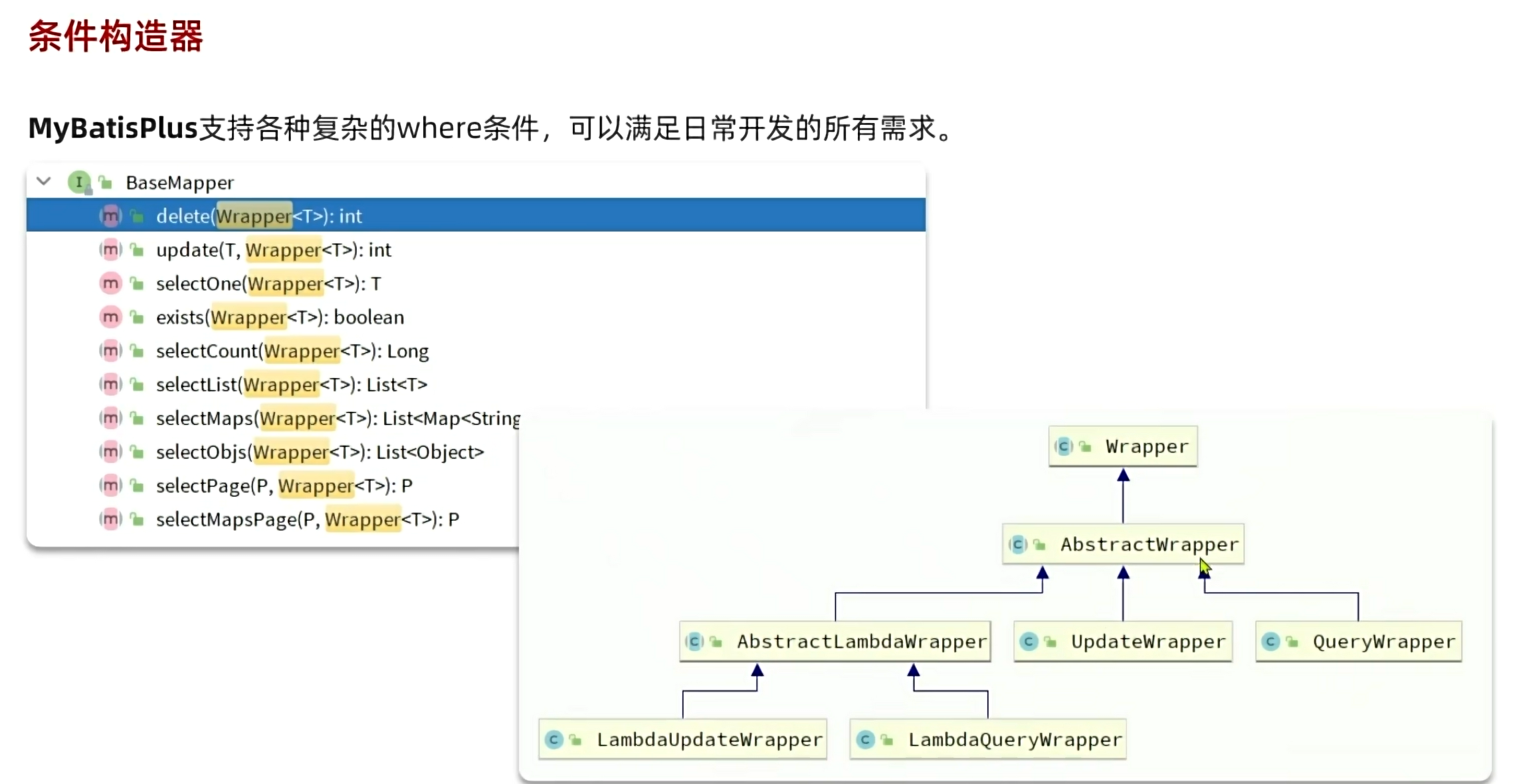
1.3.条件构造器:

1.4.自定义sql:
在有些业务中,需要我们手动来编写部分sql语句,但是在开发业务中,sql语句是不能直接暴露在业务代码中的,但是如果我们像mybatis那样直接写xml文件,where部分又太复杂了,所以我们把where部分交给mp,其他部分自己编写:
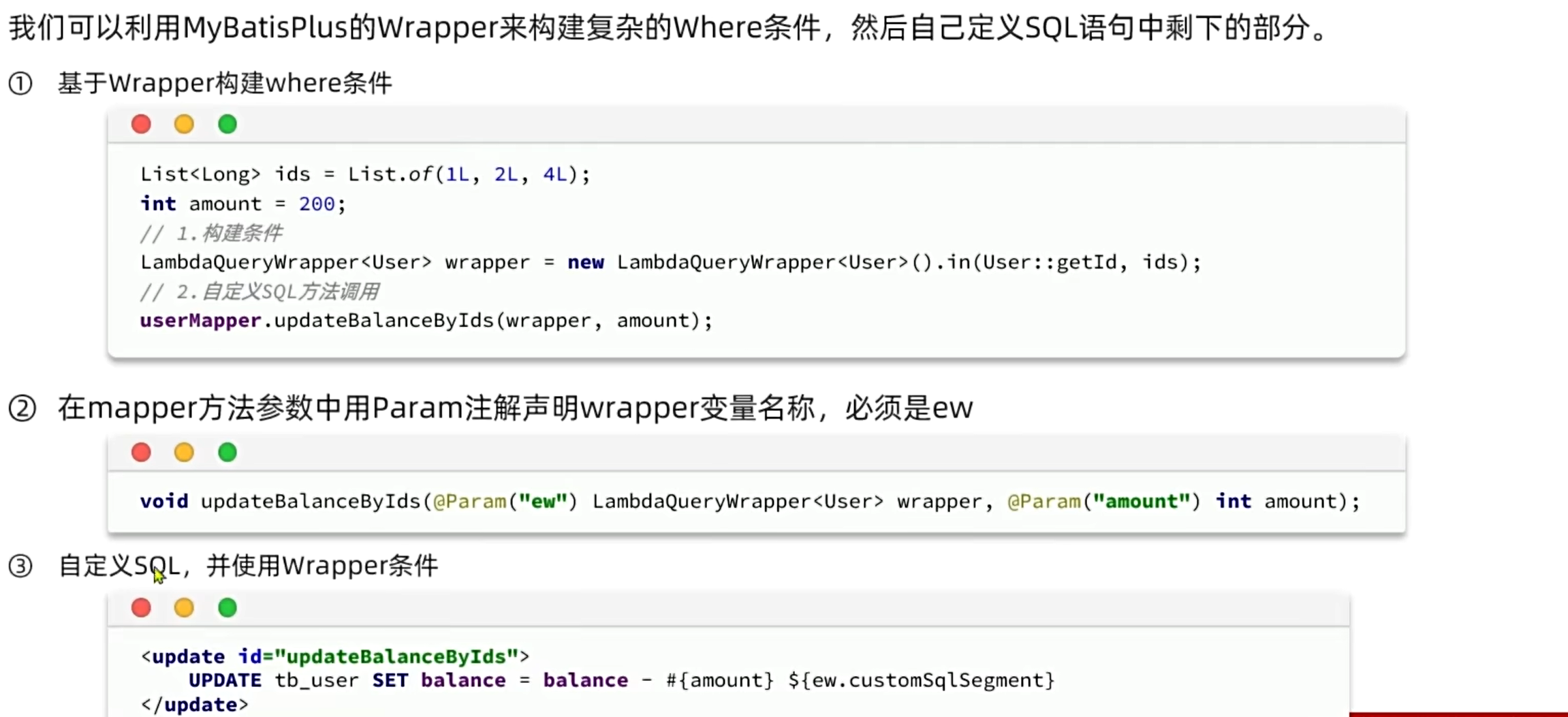
定义mapper:

编写xml文件:
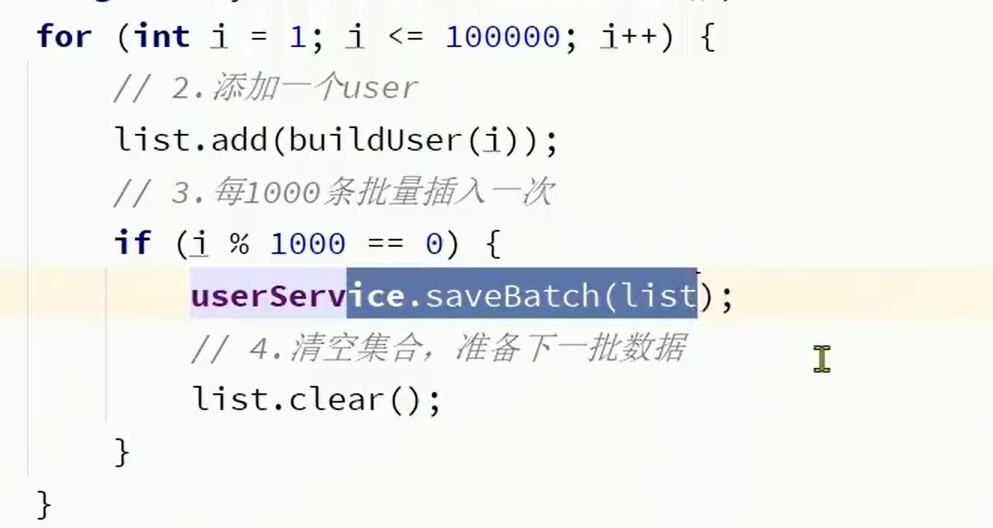
1.5.mp批处理:
业务场景:需要向数据库添加1000000条数据,在什么情况下添加最快:
可能方法:批量添加:

但是,从结果来看,并不符合预期,但其实是mysql的问题,默认情况下rewriteBatchedStatements是false,我们要开启这个配置,并且设置为true。
解决方法:在yaml文件的mysql的jdbc配置后面加上&rewriteBatchedStatements=true即可。
1.6.DB静态工具:
背景:
Service循环调用确实可能导致循环依赖,这通常发生在两个或多个服务相互依赖,形成一个闭环的情况。以下是一个简单的例子来说明这种循环依赖:
假设我们有两个服务:OrderService(订单服务)和UserService(用户服务)。
- OrderService(订单服务):
- 它依赖于UserService,因为当需要保存订单时,可能需要查询用户信息来确保订单与用户关联。
- OrderService有一个方法
saveOrder(),该方法在保存订单之前会调用UserService的getUserById()方法来获取用户信息。
- UserService(用户服务):
- 它也依赖于OrderService,因为可能需要在用户界面中显示用户的订单历史。
- UserService有一个方法
queryOrders(),该方法会调用OrderService的getOrdersByUserId()方法来获取用户的订单列表。
现在,问题出现了:
- 当OrderService需要保存一个订单并查询用户信息时,它会调用UserService的
getUserById()方法。 - 如果在
getUserById()方法的实现中,UserService需要查询用户的订单历史来执行某些逻辑(例如,检查用户是否有未完成的订单以决定是否允许其创建新订单),那么UserService就会调用OrderService的getOrdersByUserId()方法。 - 但是,由于OrderService在调用UserService时可能还没有完全初始化(因为它正在等待UserService的响应),这就可能导致一个循环依赖的情况。
这个时候就有了DB:
DB静态工具主要是用来解决在业务逻辑中可能出现的循环依赖问题。
在复杂的业务逻辑中,不同的Service类之间可能会相互调用,这就有可能出现循环依赖的现象。例如,在查询用户地址时,可能需要验证用户的状态,而在验证用户状态时又可能需要查询用户的地址,这就形成了一个循环。为了避免这种循环依赖,MyBatis-Plus提供了一个静态工具类:Db。
这个Db静态工具类提供了一些与IService中方法签名基本一致的静态方法,可以帮助我们实现CRUD(创建、读取、更新、删除)的功能。例如,我们可以使用Db.getById()方法来获取指定ID的用户信息,而不需要在Service中注入相关的依赖。
因此,通过使用Db静态工具类,我们可以避免在业务逻辑中出现循环依赖的问题,使代码更加精简且易于理解。
举例如下:
假设你有一个User实体,并且想要根据用户ID查询用户信息。通常,你可能会在UserService中注入UserMapper来实现这个功能。但是,使用Db静态工具类,你可以直接执行查询而不需要额外的依赖注入。
import com.baomidou.mybatisplus.core.toolkit.Db;
import com.yourpackage.entity.User;
// 假设这是你的服务类
public class SomeService {
// 使用Db静态工具类查询用户信息
public User getUserById(Long id) {
// 直接使用Db静态工具类执行查询
return Db.selectOne("SELECT * FROM user WHERE id = #{id}", User.class, id);
// 注意:上面的SQL是示例,实际使用时应该根据数据库表和字段来编写
// 另外,对于更复杂的查询,可能需要使用更高级的查询构建器或Wrapper
}
// 其他业务逻辑...
}
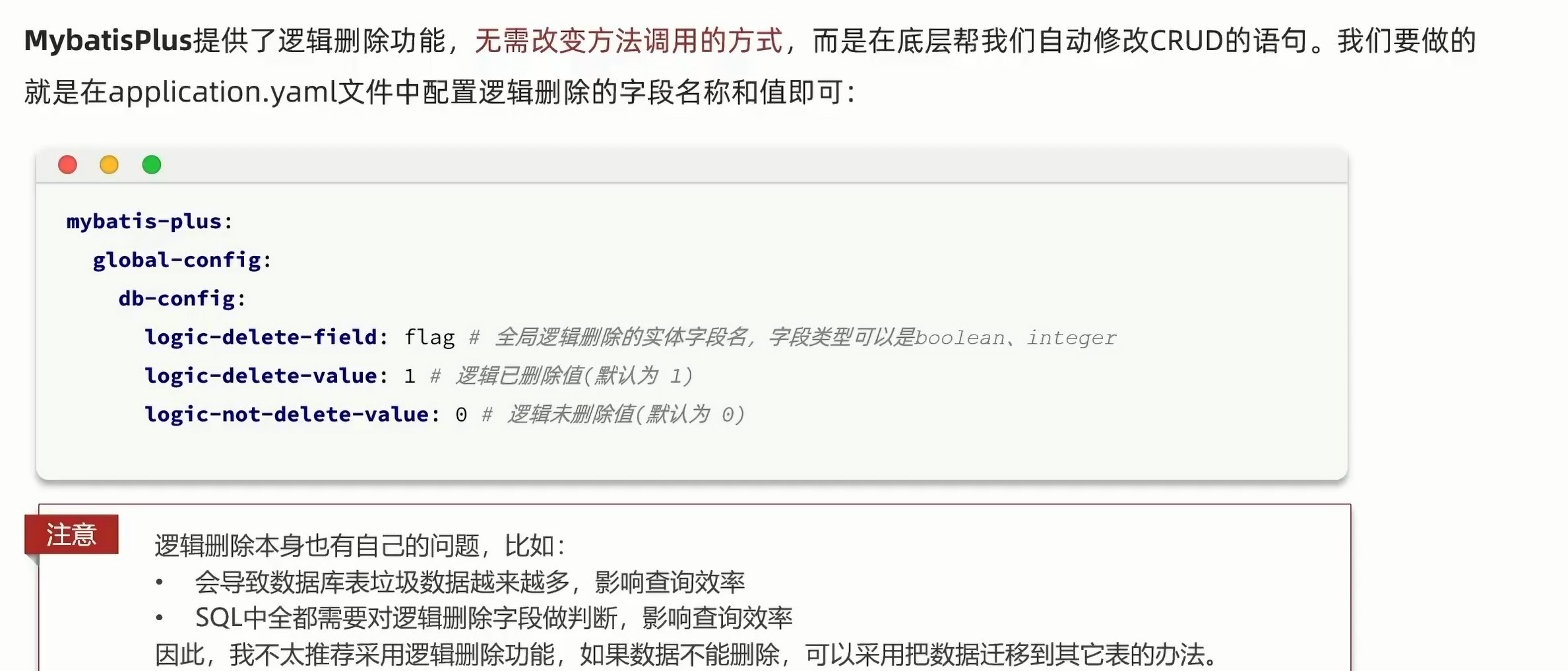
1.7.逻辑删除:
在yaml文件中,可以设置逻辑删除,这样我们可以进行正常的crud,mp会自动忽略或者改变查询这些逻辑删除的数据:
1.8.枚举处理器:
背景:
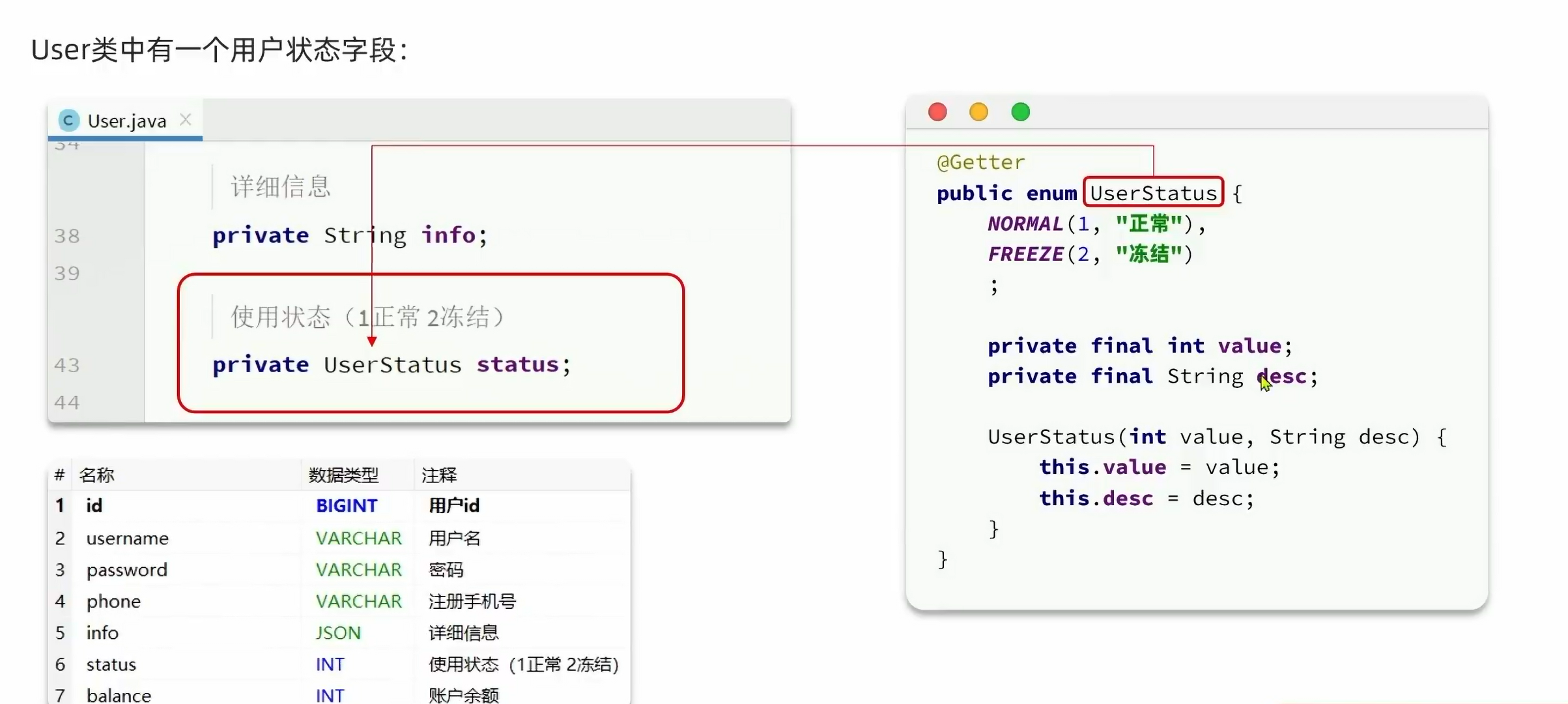
注意,数据库中是int类型,而不是枚举类型,这个时候,mp底层会有默认的枚举处理器来实现相互转换,但是它是怎么判断哪个字段是对应数据库的呢:
我们可以给目标字段加上@EnumValue注解,然后加上全局处理器:
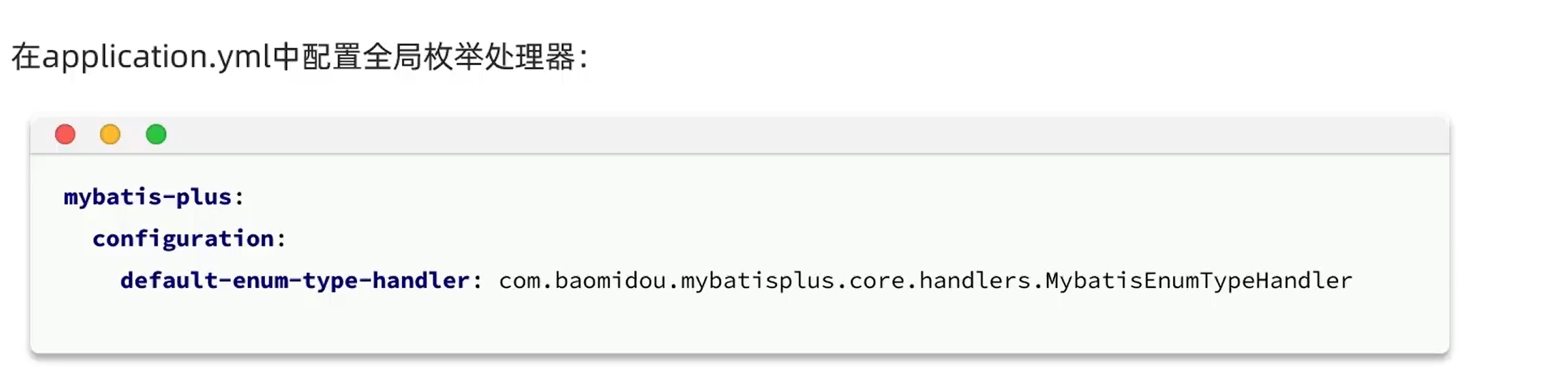
现在,就实现了java与数据库之间的枚举类型处理器,但是返回前端的数据没有被指明,有可能是1,有可能是冻结,所以我们可以在要返回的字段上面加上@JsonValue即可。
1.9.JSON处理器:
在数据库中,有的字段的属性可能是JSON,即多个字段的集合,那么我们在java代码中想取出它的字段,我们就必须把它设计成对象,这种情况下,解析可能会出现异常。所以我们只能用自定义的JSON处理器:

如图,我们要在字段上面加上TableField注解。然后在类上开启自动的结果映射。
1.10.分页插件:

二:部署:
2.1.部署准备:
在此之前,两个容器的挂载细节如下:
nginx:
docker run -d \
--name nginx \
-p 18080:18080 \
-p 18081:18081 \
-v /root/nginx/html:/usr/share/nginx/html \
-v /root/nginx/nginx.conf:/etc/nginx/nginx.conf \
--network heima \
nginx
这条命令是用来在Docker中运行一个名为nginx的容器,并指定了一些参数和选项:
-d:表示在后台运行容器--name nginx:为容器指定一个名称为nginx-p 18080:18080 -p 18081:18081:将容器的端口18080和18081映射到宿主机的对应端口上-v /root/nginx/html:/usr/share/nginx/html:将宿主机的目录/root/nginx/html挂载到容器内的/usr/share/nginx/html目录,用于存放nginx的静态文件-v /root/nginx/nginx.conf:/etc/nginx/nginx.conf:将宿主机的nginx配置文件挂载到容器内的nginx配置文件目录中--network heima:将容器连接到名为heima的网络中,以便与其他容器进行通信
最后,指定要运行的镜像为nginx,这样就创建了一个带有自定义配置和静态文件目录的nginx容器。
mysql:
docker run -d \
--name mysql \
-p 3307:3306 \
-e TZ=Asia/Shanghai \
-e MYSQL_ROOT_PASSWORD=123 \
-v /root/mysql/data:/var/lib/mysql \
-v /root/mysql/init:/docker-entrypoint-initdb.d \
-v /root/mysql/conf:/etc/mysql/conf.d \
mysql
这个Docker命令是用来在容器中运行一个MySQL数据库实例的:
-d: 这个参数告诉Docker在后台运行容器。--name mysql: 这个参数指定容器的名称为"mysql"。-p 3307:3306: 这个参数将容器的3306端口映射到主机的3307端口,这样可以通过主机的3307端口访问MySQL服务。-e TZ=Asia/Shanghai: 这个参数设置容器的时区为亚洲/上海。-e MYSQL_ROOT_PASSWORD=123: 这个参数设置MySQL的root用户的密码为"123"。-v /root/mysql/data:/var/lib/mysql: 这个参数将主机的/root/mysql/data目录挂载到容器的/var/lib/mysql目录,用于持久化存储MySQL的数据。-v /root/mysql/init:/docker-entrypoint-initdb.d: 这个参数将主机的/root/mysql/init目录挂载到容器的/docker-entrypoint-initdb.d目录,用于在容器启动时初始化数据库。-v /root/mysql/conf:/etc/mysql/conf.d: 这个参数将主机的/root/mysql/conf目录挂载到容器的/etc/mysql/conf.d目录,用于提供MySQL的配置文件。
总之,这个命令会创建一个名为"mysql"的MySQL容器,配置了时区、root密码、数据持久化目录、初始化脚本目录和配置文件目录。
DockerCompose:

语法对比:

多个容器语法如下:
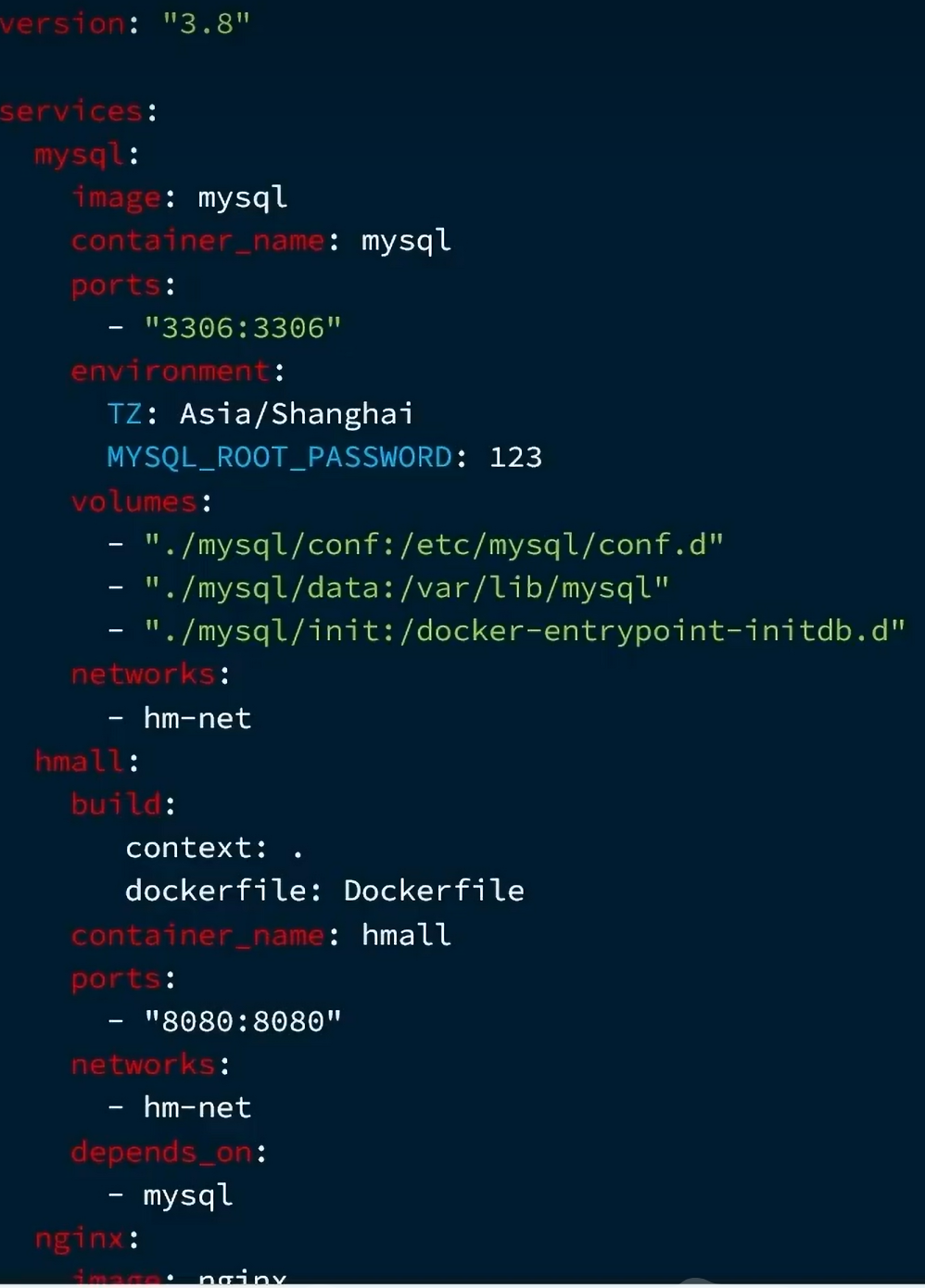
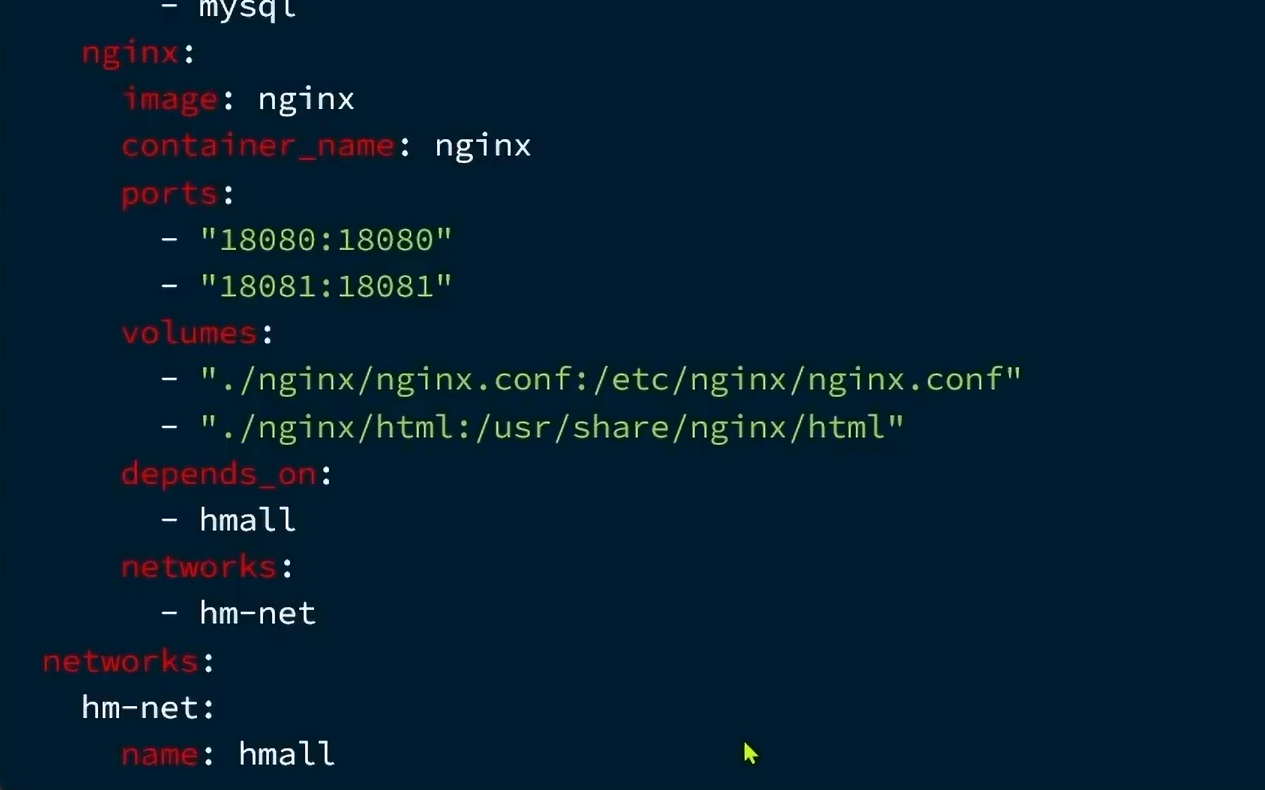
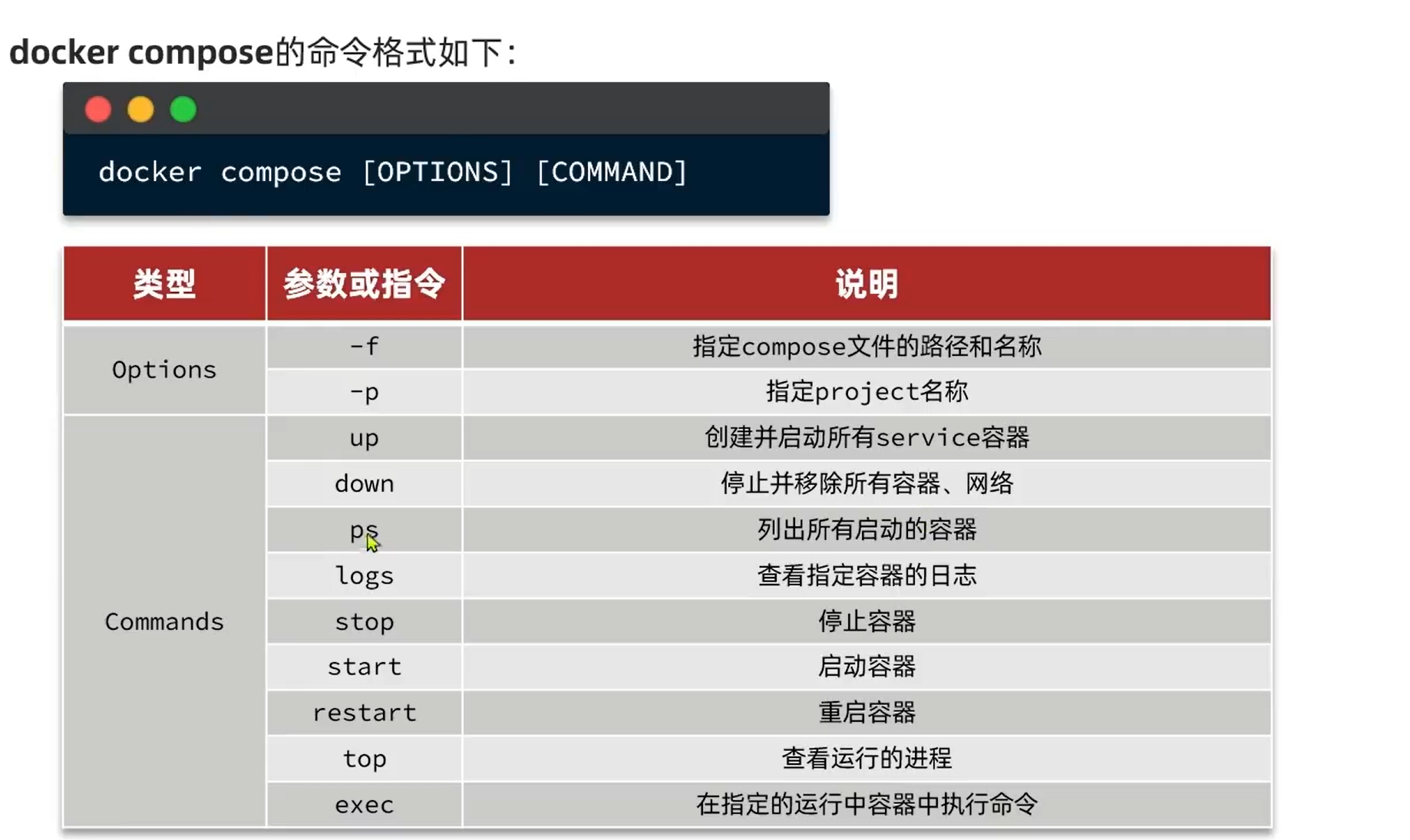
2.2.启动:
2.2.1.后端:
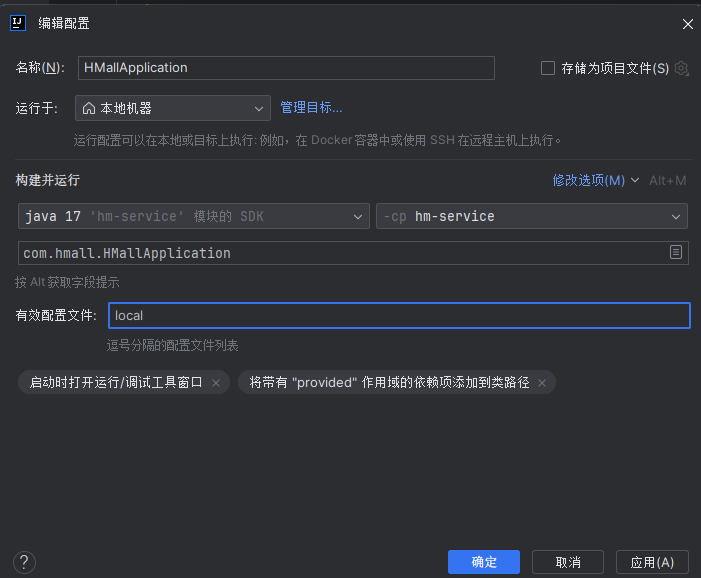
IDEA中的代码我们设置了开发环境为dev,事实上在linux上面才为dev,windows上面为local环境,当然,我们不应该改变代码,而是在windows的IDEA中改变开发环境:
2.2.2.前端:
注意,前端的运行目录必须是全中文的。用cmd输入一下命令:
start nginx.exe
三:认识微服务:
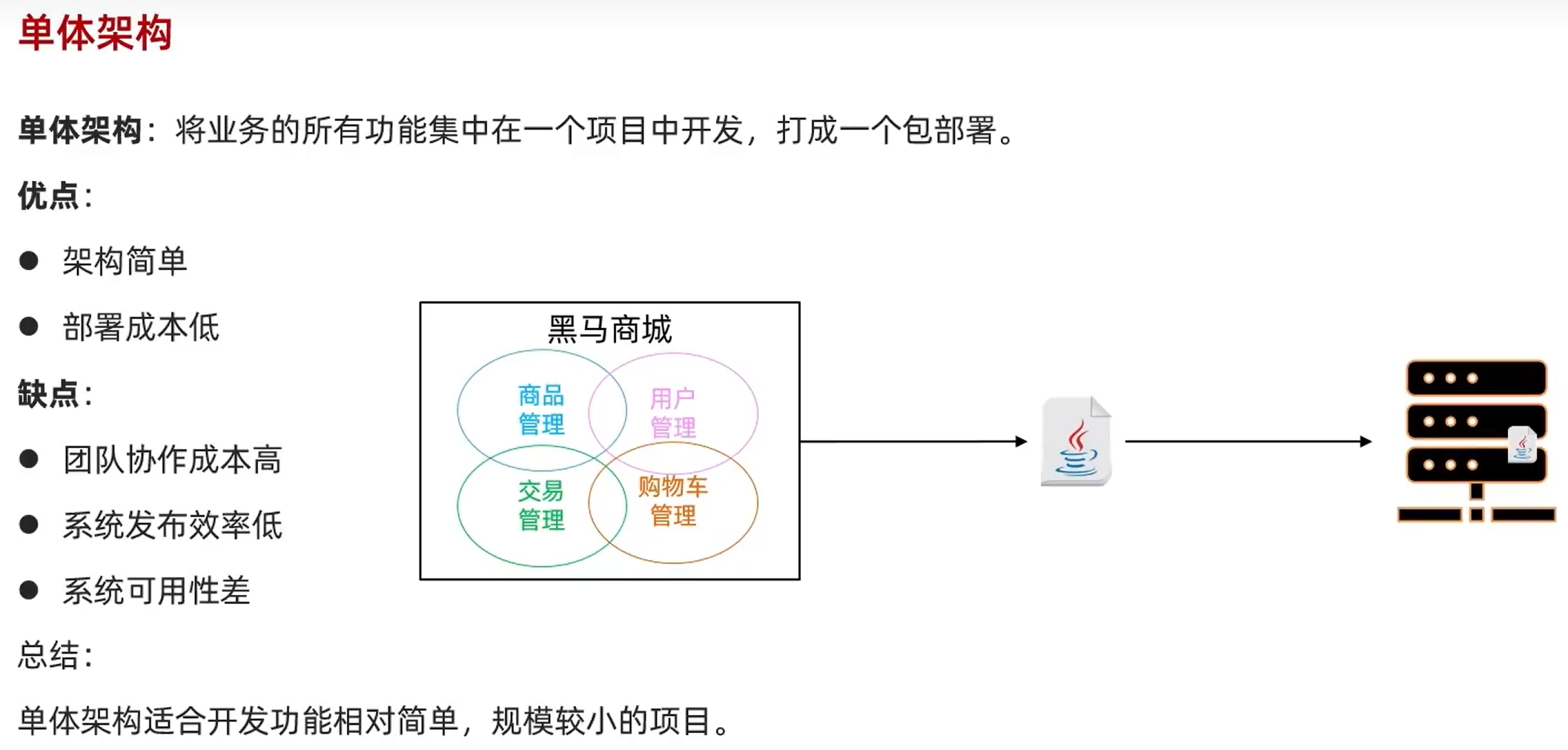
3.1.单体架构:
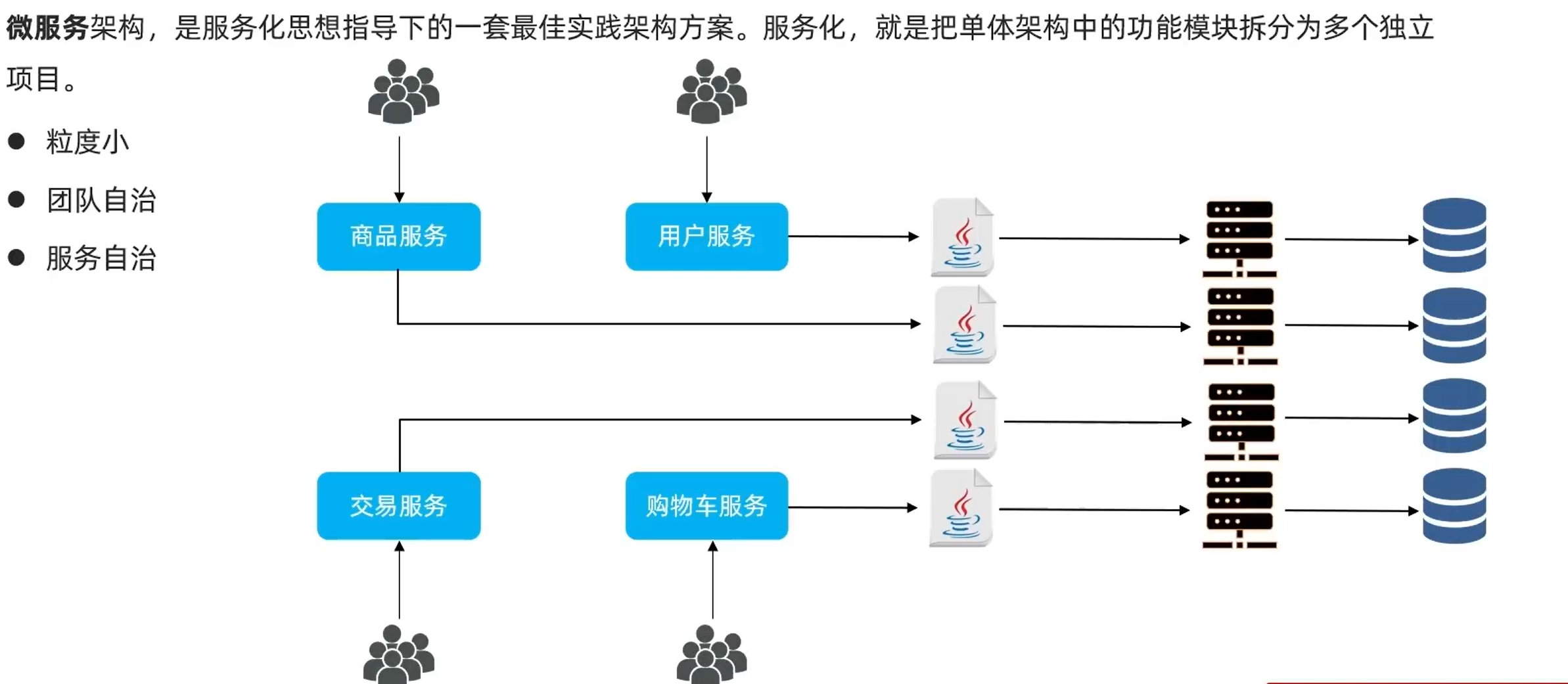
3.2.认识微服务:
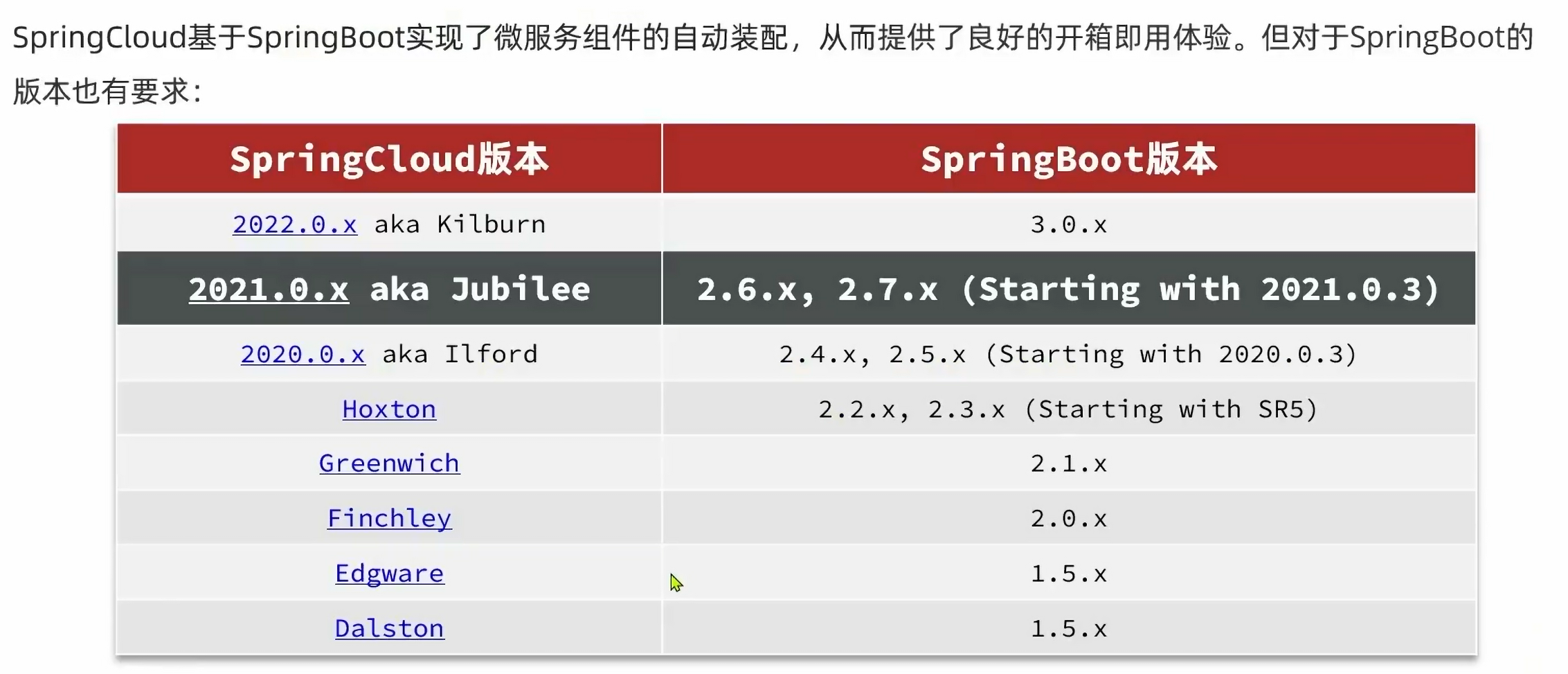
3.3.SpringCloud:
Spring Cloud是一个开源的微服务框架,它基于Spring框架,为开发者提供了一套完整的微服务解决方案。Spring Cloud提供了一系列的工具和库,帮助开发者快速构建分布式系统,包括服务注册与发现、负载均衡、断路器、分布式配置等功能。通过Spring Cloud,开发者可以更轻松地构建和管理微服务架构,实现高可用、可扩展和弹性的分布式系统。

四:微服务拆分:
4.1.微服务拆分原则:


4.2.项目拆分方法:
4.2.1.独立project:
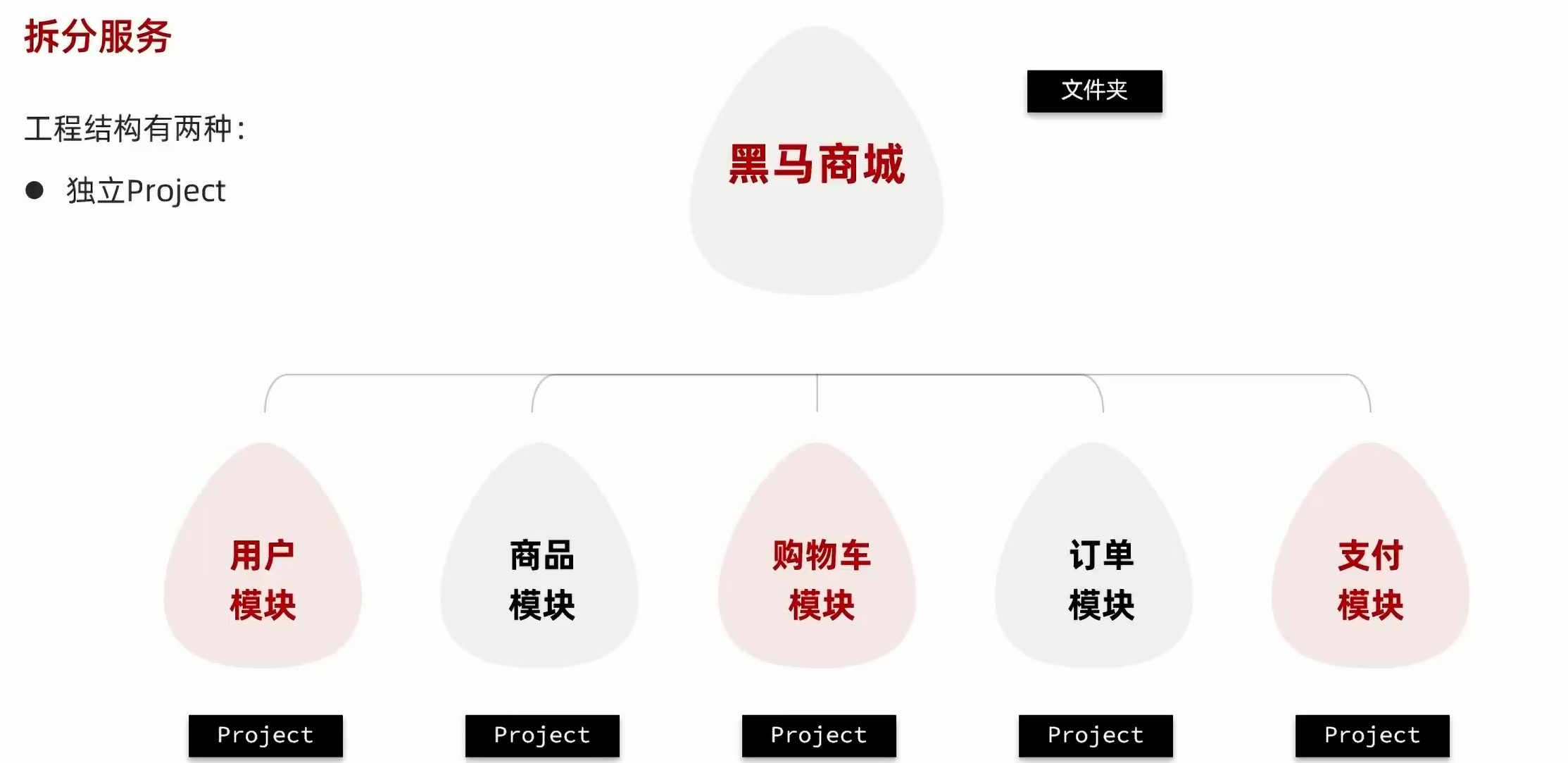
即每个微服务都是一个单独的项目,该方式适用于大型项目结构。
4.2.2.maven聚合:
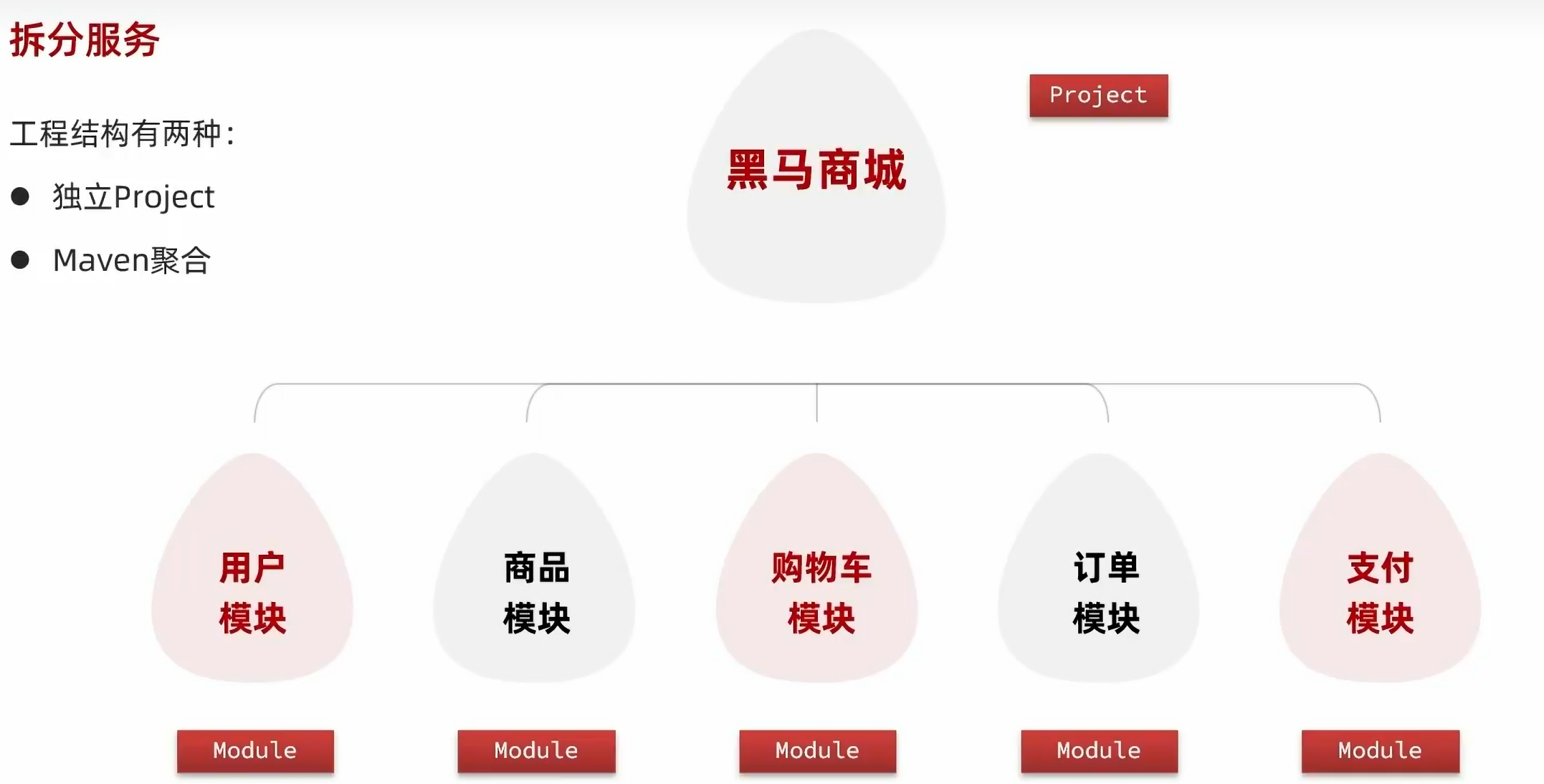
该方法适用于中小型项目。
本项目使用第二种方法。
4.3.项目拆分:
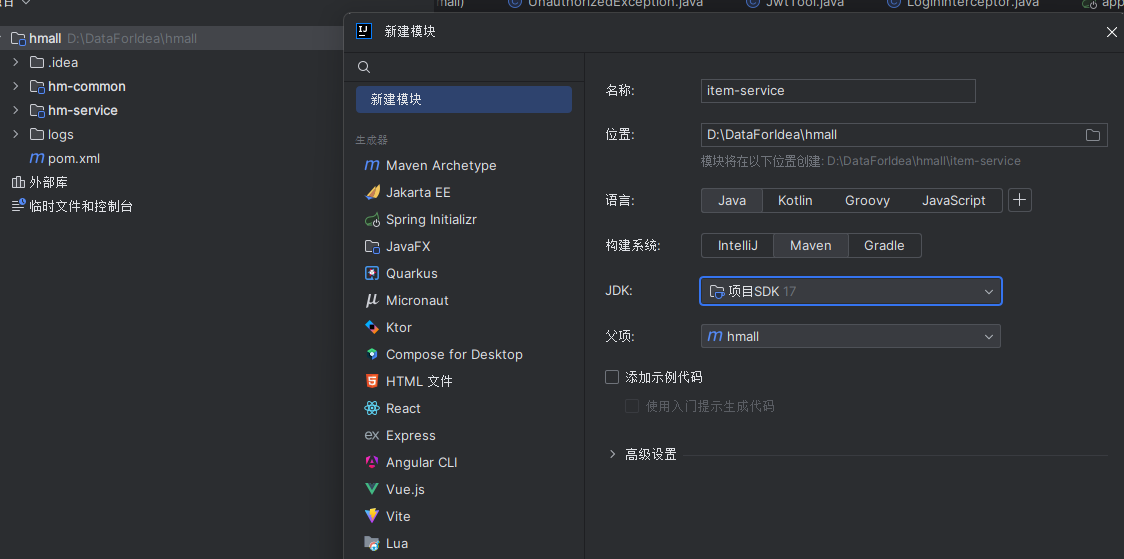
具体步骤如下:
3.1.在父工程下,创建一个新的modole:
3.2.在pom中添加依赖:
也可以复制其它子工程的pom,但是要删除不需要的依赖。
3.3.添加启动与编写项目配置:

注意,记得给新模块设置一个新的端口,并且更改一些配置。
3.4.创建新的数据库(表):
在实际的微服务中,我们会创建不同的数据库来模拟数据隔离,在这里,为了方便,我们创建新的表来模拟数据隔离:
导入成功!
3.5.编写主要逻辑:
建议按照依赖顺序。
3.6.测试使用:
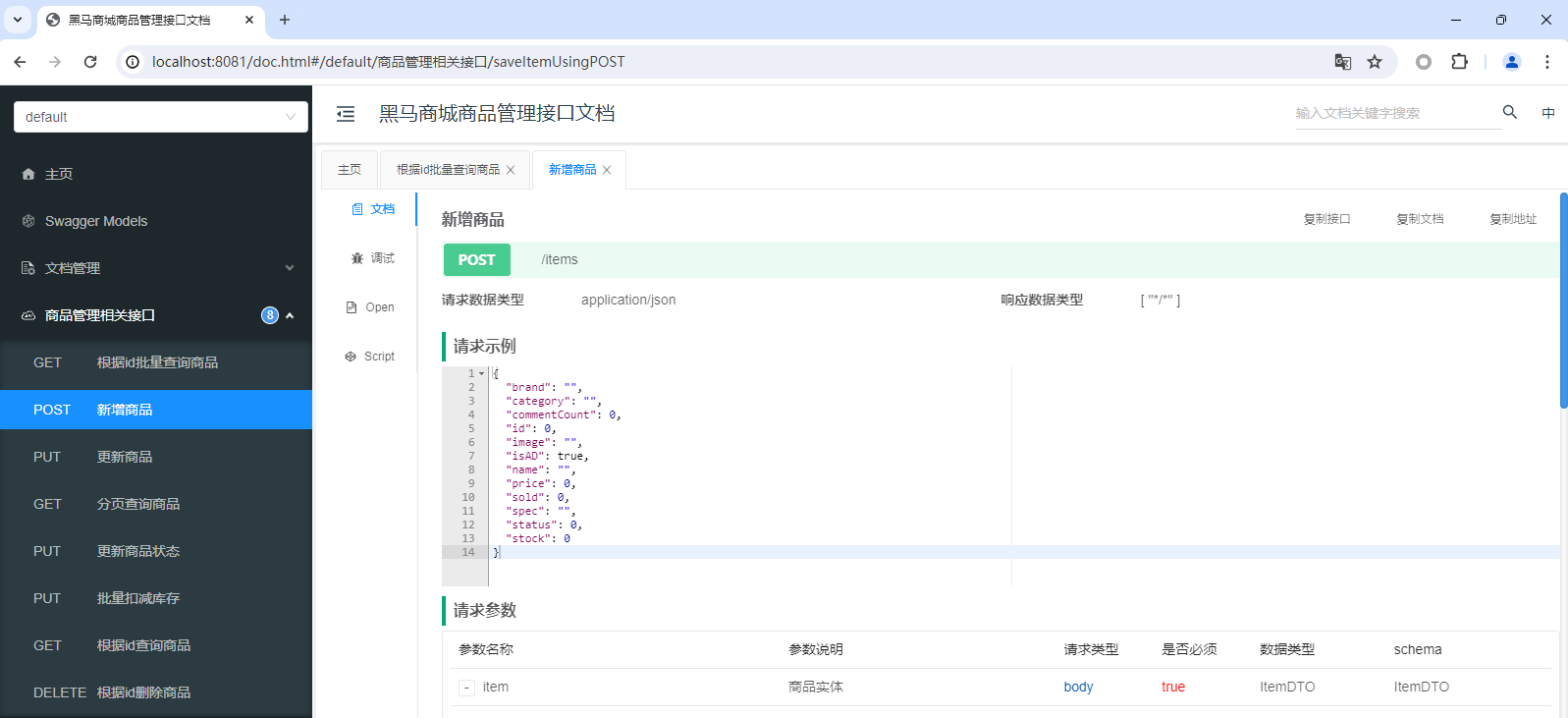
输入/doc.html测试knife4j。
4.4.远程调用:
问题引入:我们将项目拆分为若干个小项目,对于每个项目,它们有不同的数据库,那么它们怎么互通信息?
答:通过网络调用。
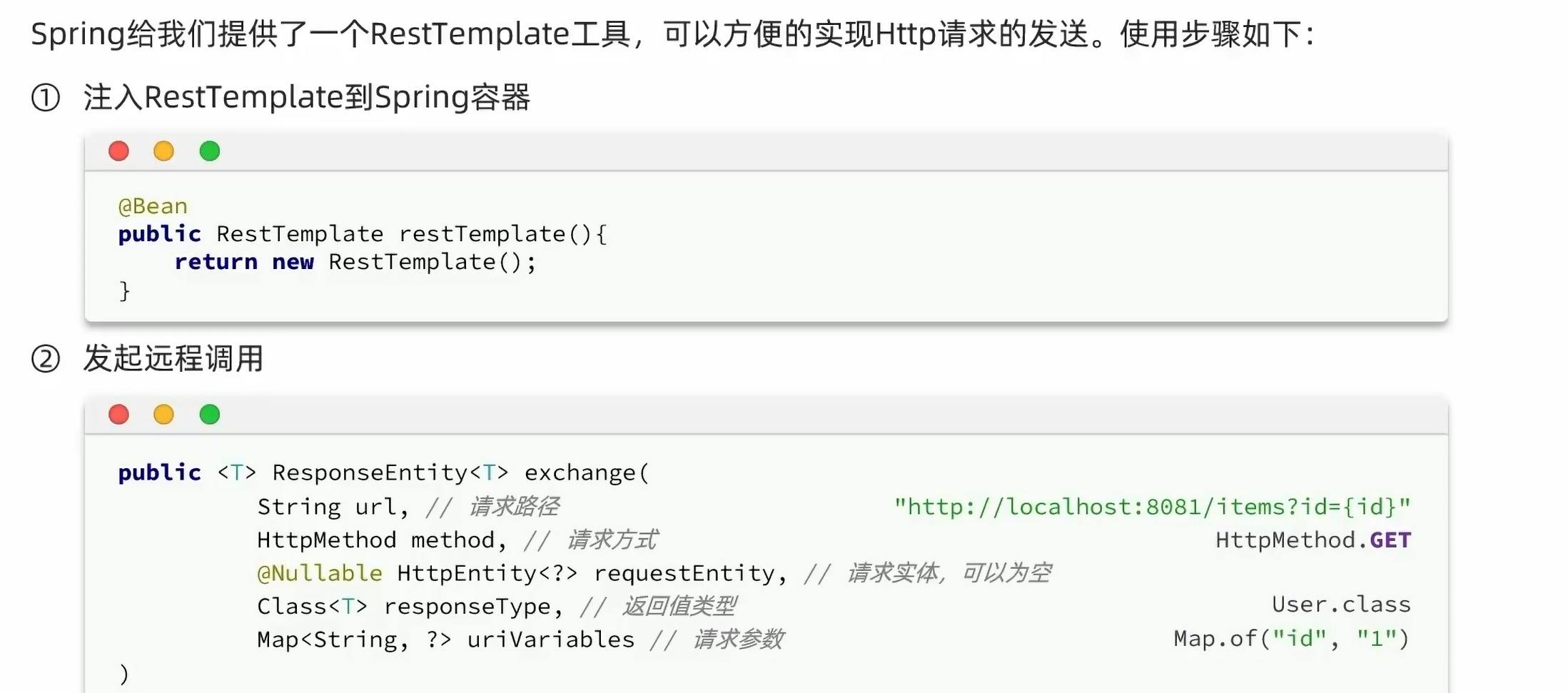
下面我们来实现一下这个代码:
bean的装配:
@Bean
public RestTemplate restTemplate(){
return new RestTemplate();
}
bean的注入:
@RequiredArgsConstructor
...
private final RestTemplate restTemplate;
虽然,spring可以通过@Autowired与@Resource自动装配,但是一般情况下,它更建议我们使用构造函数,所以我们这里使用lombok的注解:@RequiredArgsConstructor可以用在类上,相当于使用final修饰符的类变量被初始化,且类中存在一个构造函数,这样就可以给想要构造函数的字段加上final,并且未初始化,就可以享受自动生成的便捷了。
业务代码:
ResponseEntity<List<ItemDTO>> response = restTemplate.exchange(
"http://localhost:8081/items?ids={ids}",
HttpMethod.GET,
null,
new ParameterizedTypeReference<List<ItemDTO>>() {},
Map.of("ids", CollUtils.join(itemIds, ","))
);
if (!response.getStatusCode().is2xxSuccessful()){
return;
}
List<ItemDTO> items = response.getBody();
-
方法概述:
- 该代码段的主要目的是从
http://localhost:8081/items这个URL获取多个ItemDTO对象的列表,其中这些对象的ID是通过一个查询参数ids传递的。 - 使用
RestTemplate的exchange方法来发送一个HTTP GET请求,并期望返回一个List<ItemDTO>类型的响应体。
- 该代码段的主要目的是从
-
代码分解:
- URL模板:
"http://localhost:8081/items?ids={ids}"这是一个URL模板,其中
{ids}是一个占位符,稍后会被实际的值替换。- HTTP方法:
HttpMethod.GET这表示我们要发送一个HTTP GET请求。
- 请求体:
null因为这是一个GET请求,所以没有请求体。
- 响应类型:
new ParameterizedTypeReference<List<ItemDTO>>() {}在 Java 中,由于类型擦除,泛型在运行时会被擦除,这意味着如果你在调用时只传递一个普通的
List.class或new TypeReference<List<ItemDTO>>(){}(注意这里TypeReference是 Jackson 库中的类,而不是 Spring 的),那么运行时将无法知道List里面的具体类型是什么。为了解决这个问题,
ParameterizedTypeReference(这是 Spring 框架提供的一个类)允许你创建一个带有实际类型参数的匿名子类,从而在运行时保留类型信息。这样,当RestTemplate收到响应并尝试将其反序列化为 Java 对象时,它可以知道期望的具体类型,从而能够正确地转换数据。在你的例子中,
new ParameterizedTypeReference<List<ItemDTO>>() {}告诉RestTemplate你期望的响应体是一个ItemDTO对象的列表。当RestTemplate收到响应后,它会尝试将这个响应体反序列化为一个List<ItemDTO>类型的对象。- 请求参数:
Map.of("ids", CollUtils.join(itemIds, ","))这里创建了一个Map来存储URL模板中的占位符的实际值。
CollUtils.join(itemIds, ",")可能是一个将itemIds(一个集合或数组)转换为由逗号分隔的字符串的方法(注意:CollUtils不是Java标准库中的类,可能是某个库或自定义的工具类)。- 发送请求并获取响应:
ResponseEntity<List<ItemDTO>> response = ...使用上述信息,
RestTemplate会发送请求,并返回一个ResponseEntity对象,该对象包含响应的状态码、头部和正文。- 检查状态码:
if (!response.getStatusCode().is2xxSuccessful()){ return; }在继续处理之前,代码首先检查响应的状态码是否是2xx(表示成功)系列。如果不是,则方法直接返回,不执行后续的代码。
- 获取响应体:
List<ItemDTO> items = response.getBody();如果状态码是2开头,那么代码会从
ResponseEntity对象中提取响应体,并将其存储在items列表中。

4.5.注册中心原理:
远程调用问题分析:
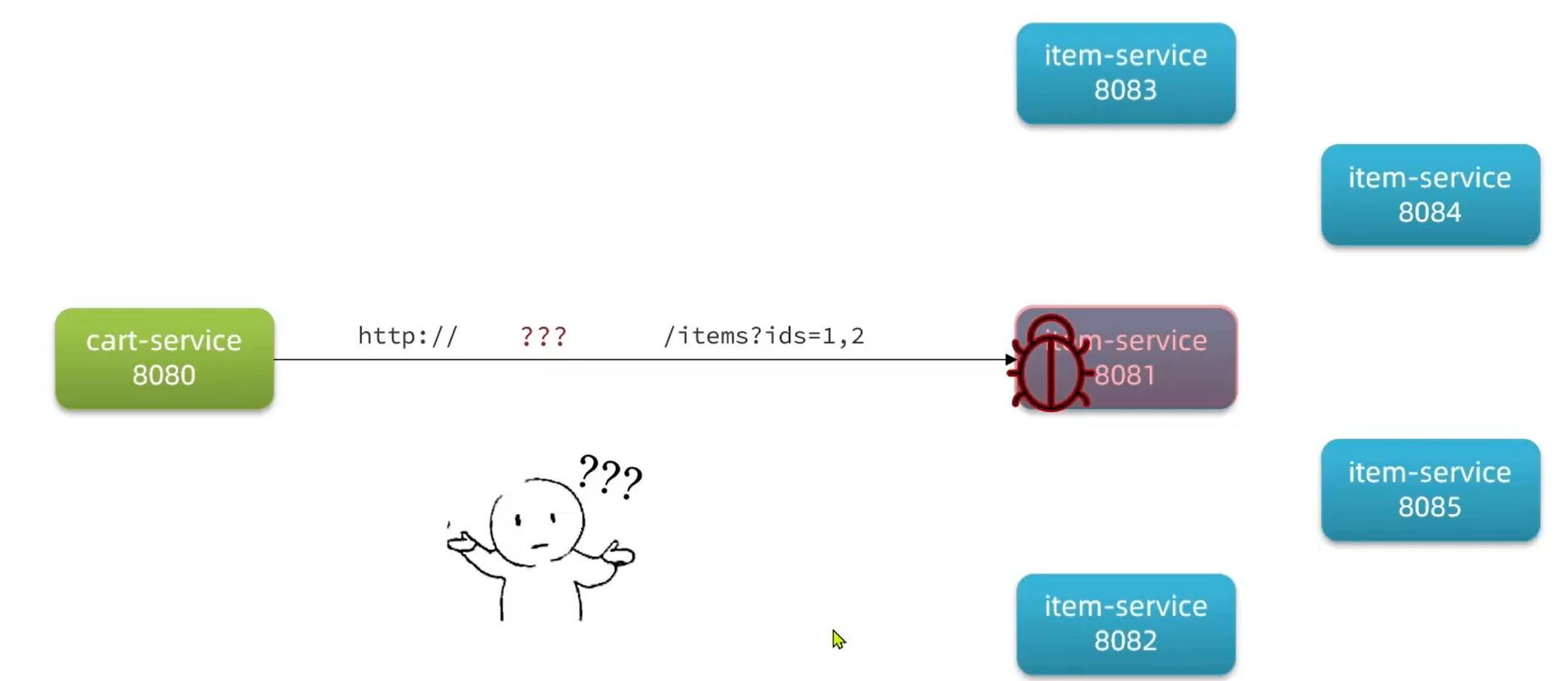
1.如果到时候是负载均衡,那么上面的将端口,服务器写死了,那不就相当于单实例吗?
2.如果该单实例宕机了,那又该怎么办?
注册中心原理:
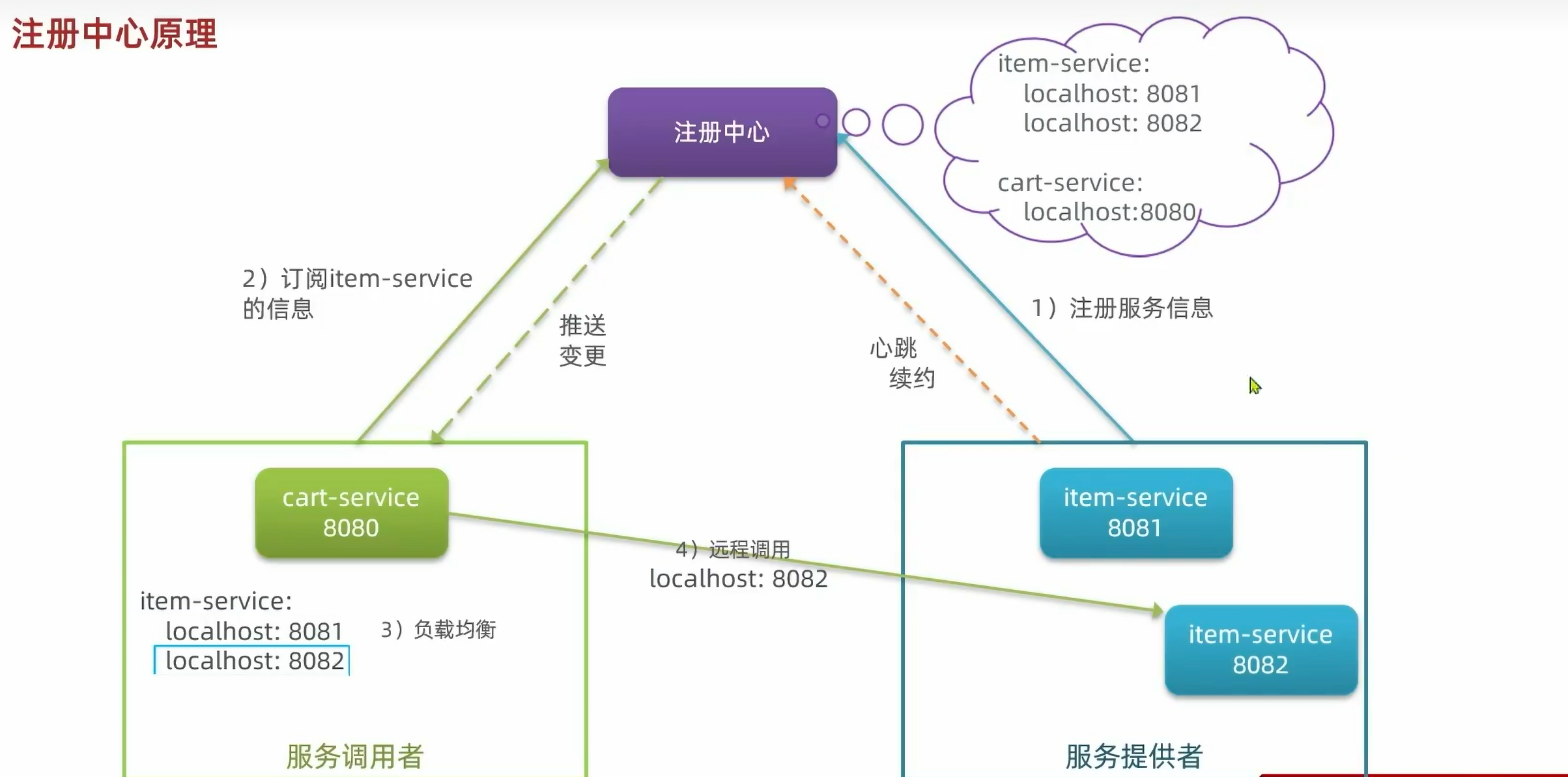

4.6.注册中心——Nacos:
首先,我们要去为它配置数据源:
docker部署:
配置文件:
PREFER_HOST_MODE=hostname
MODE=standalone
SPRING_DATASOURCE_PLATFORM=mysql
MYSQL_SERVICE_HOST=192.168.6.128
MYSQL_SERVICE_DB_NAME=nacos
MYSQL_SERVICE_PORT=3307
MYSQL_SERVICE_USER=root
MYSQL_SERVICE_PASSWORD=123
MYSQL_SERVICE_DB_PARAM=characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai
docker run:
docker run -d \
--name nacos \
--env-file ./nacos/custom.env \
-p 8848:8848 \
-p 9848:9848 \
-p 9849:9849 \
--restart=always \
nacos/nacos-server:v2.1.0-slim

输入:ip+8848/nacos即可来到登录页面。
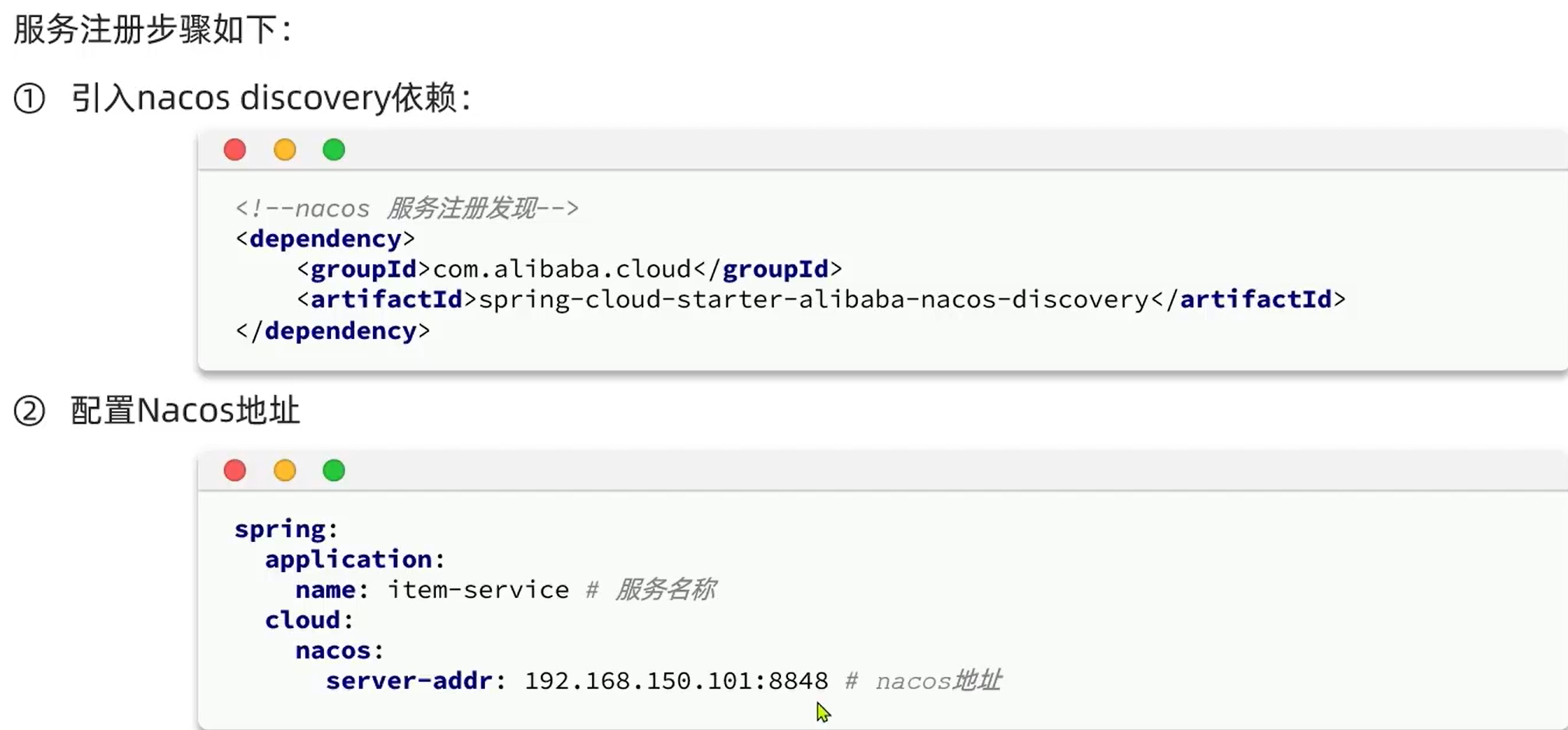
4.7.服务注册:

单实例下显示如下:
4.8.服务发现:
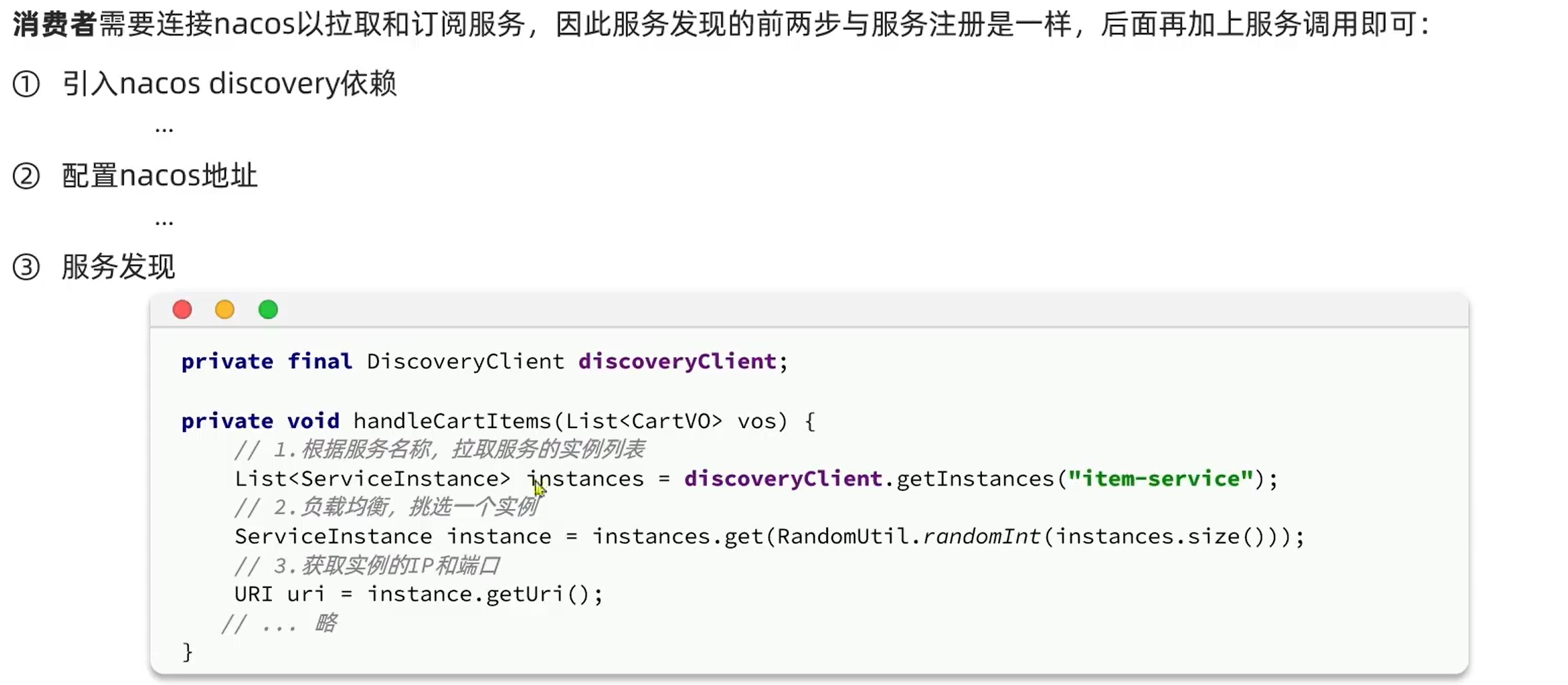
改进后的代码如下:
List<ServiceInstance> instances = discoveryClient.getInstances("item-service");
if(CollUtils.isEmpty(instances)){
return;
}
ServiceInstance instance = instances.get(RandomUtil.randomInt(instances.size()));
// 2.查询商品
ResponseEntity<List<ItemDTO>> response = restTemplate.exchange(
instance.getUri() + "/items?ids={ids}",
HttpMethod.GET,
null,
new ParameterizedTypeReference<List<ItemDTO>>() {},
Map.of("ids", CollUtils.join(itemIds, ","))
);
4.7.OpenFeign:
4.7.1.基础使用:
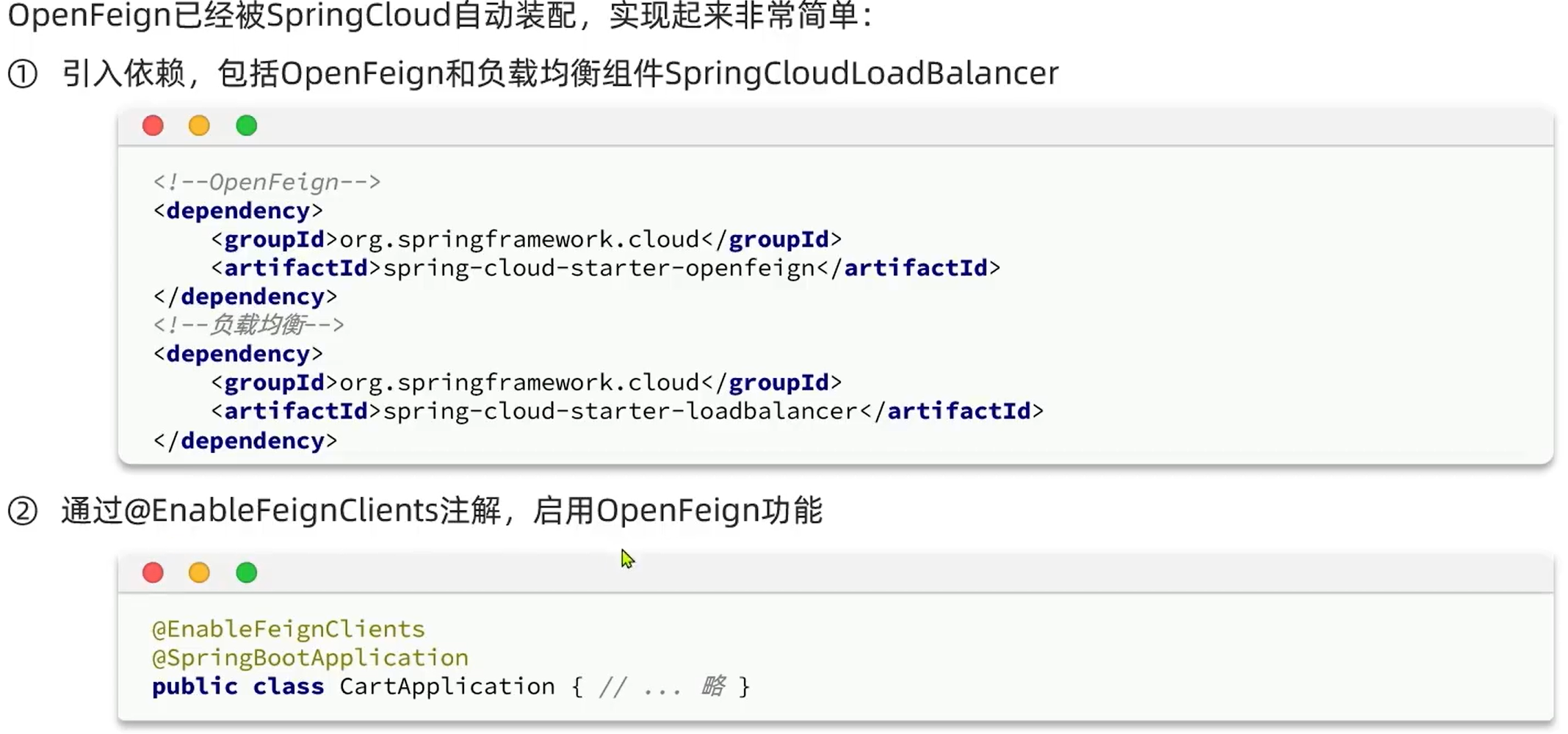
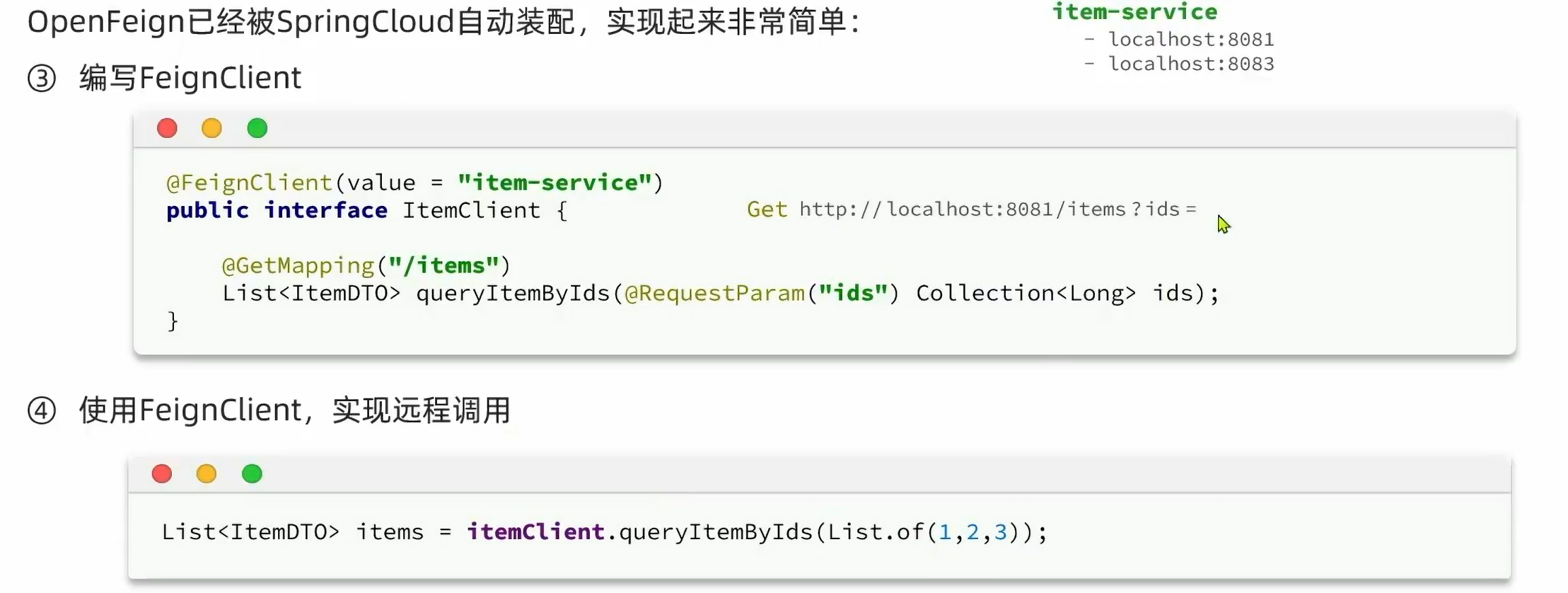
在cart-service中,定义一个新的接口,编写Feign客户端:
其中代码如下:
package com.hmall.cart.client;
import com.hmall.cart.domain.dto.ItemDTO;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import java.util.List;
@FeignClient("item-service")
public interface ItemClient {
@GetMapping("/items")
List<ItemDTO> queryItemByIds(@RequestParam("ids") Collection<Long> ids);
}
这里只需要声明接口,无需实现方法。接口中的几个关键信息:
@FeignClient("item-service"):声明服务名称@GetMapping:声明请求方式@GetMapping("/items"):声明请求路径@RequestParam("ids") Collection<Long> ids:声明请求参数List<ItemDTO>:返回值类型
有了上述信息,OpenFeign就可以利用动态代理帮我们实现这个方法,并且向http://item-service/items发送一个GET请求,携带ids为请求参数,并自动将返回值处理为List<ItemDTO>。
我们只需要直接调用这个方法,即可实现远程调用了。举例:
List<ItemDTO> items = itemClient.queryItemByIds(itemIds);
成功如图。
4.7.2:连接池:

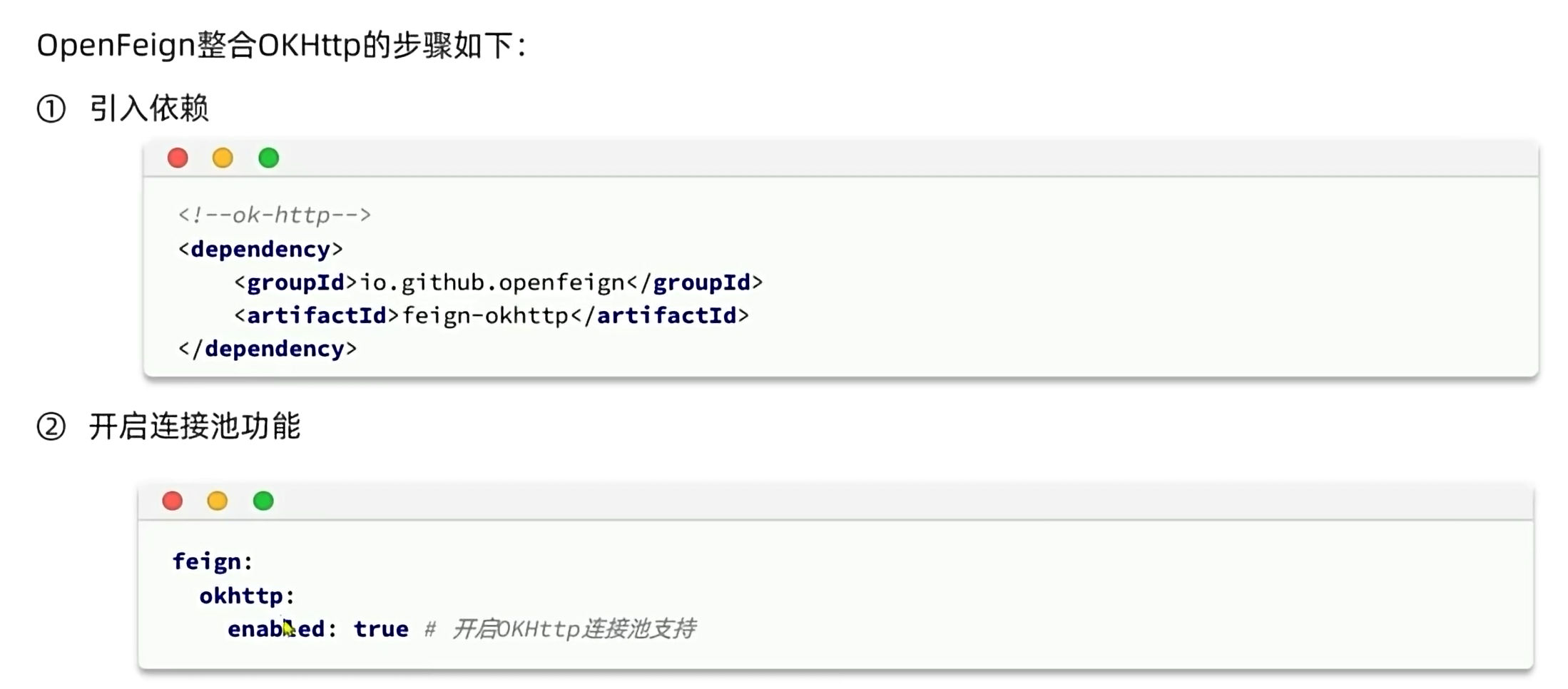
OkHttp 在性能优化方面主要有以下几个特点:
- 连接池管理:OkHttp 实现了连接池管理,可以重用已经建立的网络连接,减少连接的建立和关闭所带来的开销,提升网络请求的效率。连接池可以维护多个可重用的连接,避免频繁地创建和断开连接,从而减少网络请求的延迟。
- 请求复用:OkHttp 支持请求复用机制,可以复用相同主机的请求,避免每次请求都建立新的连接,从而减少了网络请求的时间消耗。通过请求复用,可以减少TCP连接的建立和关闭次数,节省网络资源和提升性能。
- 响应缓存:OkHttp 支持响应缓存机制,可以缓存服务器返回的响应数据,避免重复的网络请求,提升应用的性能和响应速度。合理地使用响应缓存可以减少对服务器的请求次数,减轻服务器负担,同时加快用户获取数据的速度。
4.7.3:问题分析:
如果多个微服务都需要使用同一个微服务的功能,那岂不是这些微服务都要写一个Client?所以我们用下面的方法来解决:
第一种:
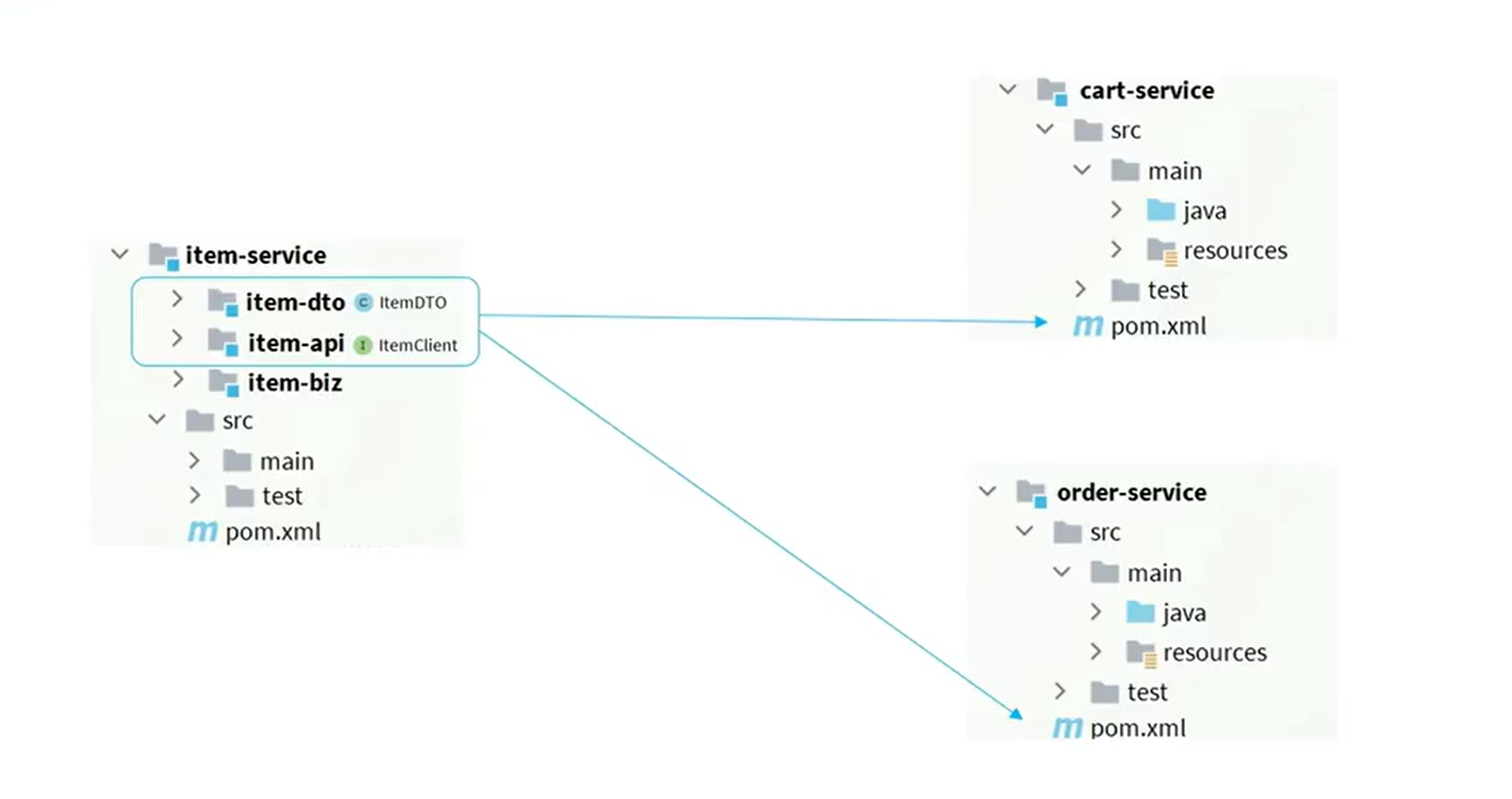
那一个服务自己完成代码,其他的服务调用即可,但是拆分结构复杂。
第二种:
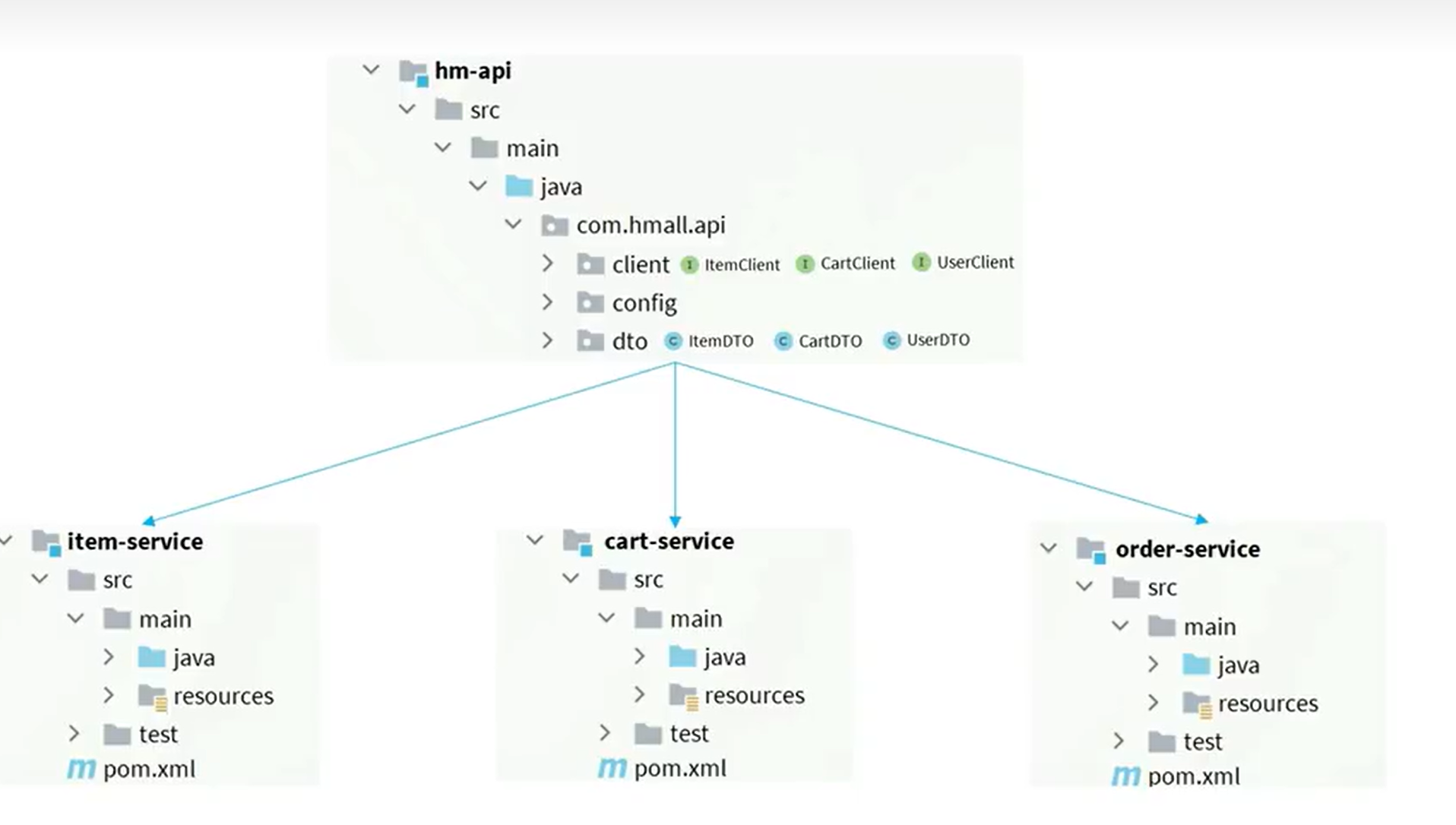
抽离公共使用。
这里我们使用第二种方法:
先创建好api模块:
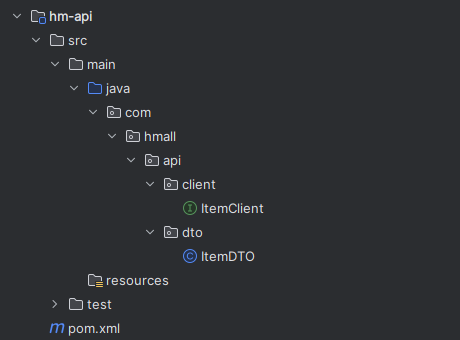
然后在需要的模块中引用依赖:
<dependency>
<groupId>org.example</groupId>
<artifactId>hm-api</artifactId>
<version>1.0.0</version>
</dependency>
新的问题:之前的bean只能在cart中扫描,扫描不到api中的bean,解决方法如下:
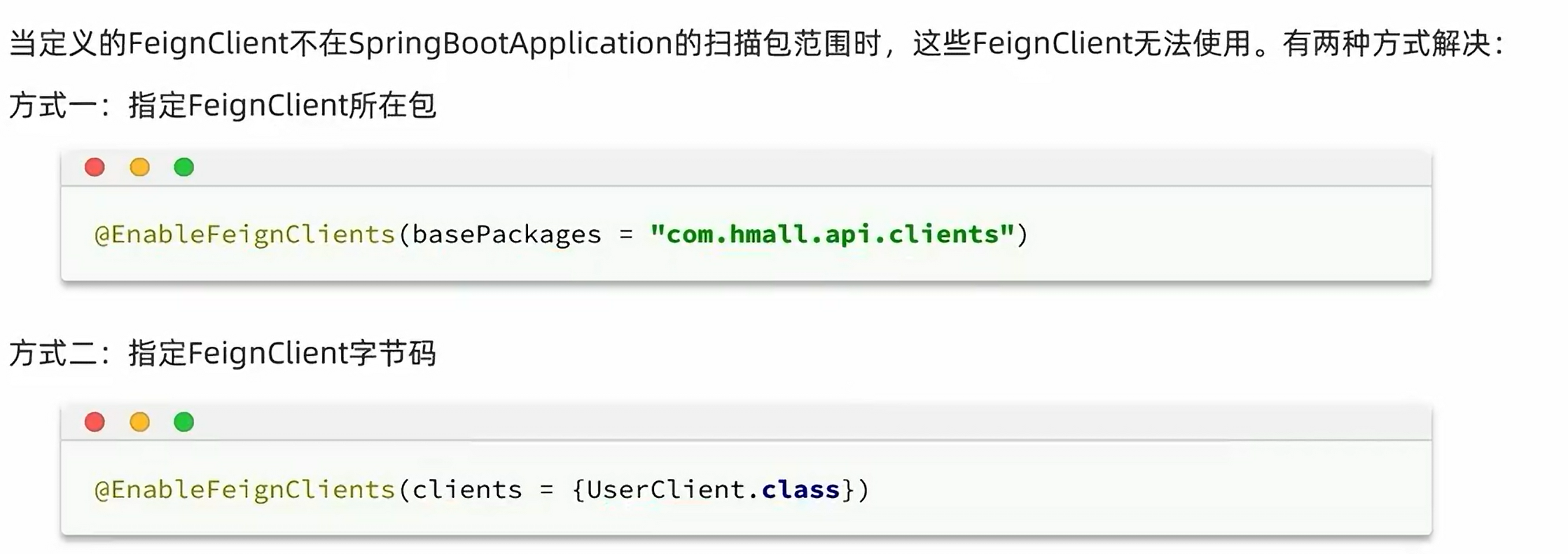
@EnableFeignClients(basePackages = "com.hmall.api.client")
@MapperScan("com.hmall.cart.mapper")
@SpringBootApplication
public class CartApplication {
public static void main(String[] args) {
SpringApplication.run(CartApplication.class, args);
}
@Bean
public RestTemplate restTemplate(){
return new RestTemplate();
}
}
被调用者要把自己被调用的接口写入一个通用的api模块即client并且在上面用注解表明他关联哪个service,还可以配置降级流程。而调用接口的实现细节在service里面实现,除此之外,调用者要引入api依赖,并且使用注解@EnableFeignClients表明启用该功能并且扫描注册api中的bean,这样就可以直接实现远程调用了。
4.7.3:日志:

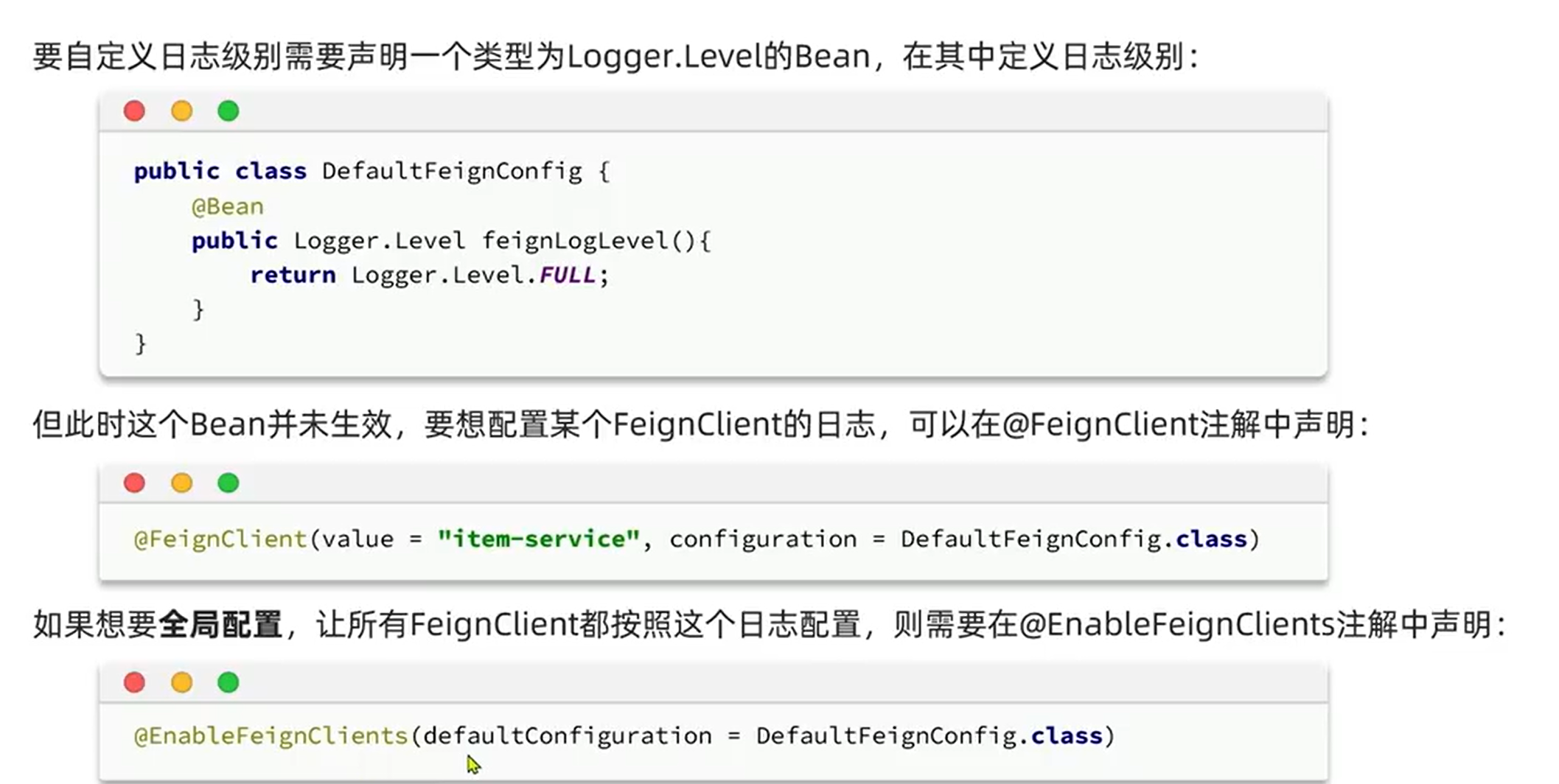
可以看API中的结构,里面有许多服务端,等待其他模块的调用,我们可以在这些服务端上面使用配置,这样的话,只会在那个服务上面生效,而我们可以认为API模块其实是存在于所有引用了他的模块中,Config也在,所以可以直接在其他模块的启动类中配置全局。
五:网关:
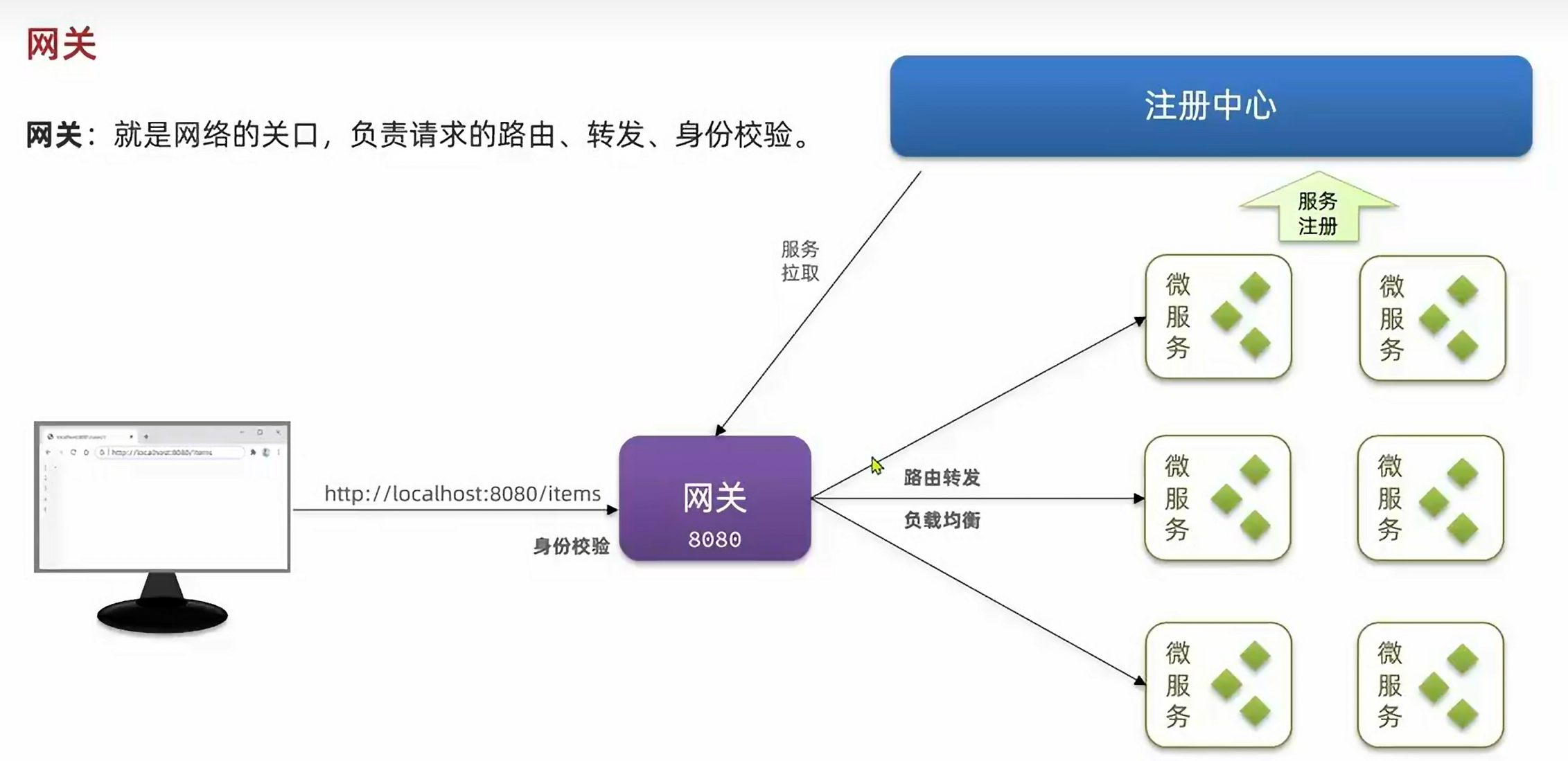
5.1.认识网关:
问题:在上面我们后端有如此多的服务器实例,那么前端怎么知道请求要访问到那里去呢,这个问题的解决就是网关:

5.2.快速入门:
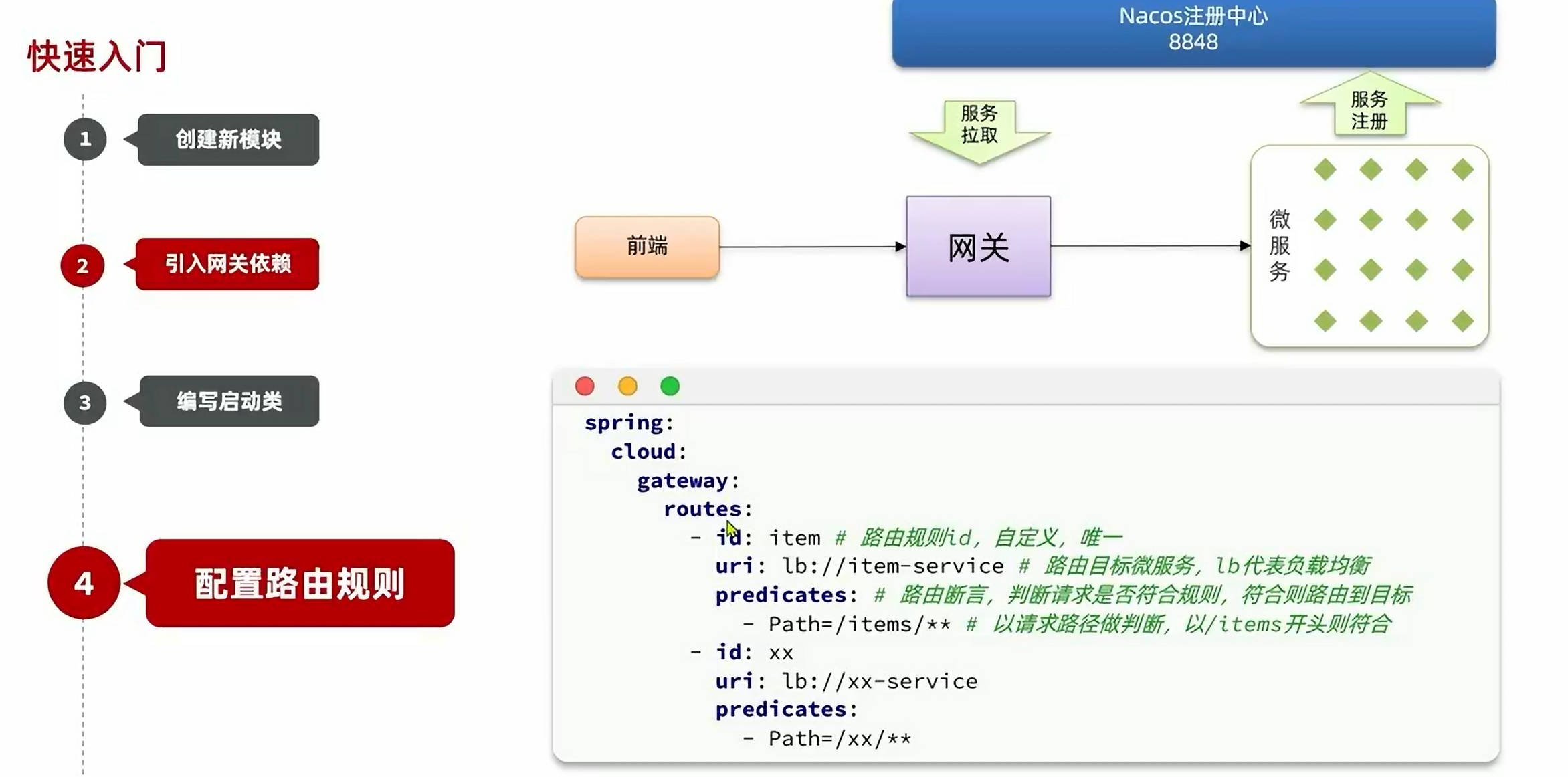
引入依赖:
<!--网关-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
创建好启动类后,配置路由,新的yaml文件如下:
server:
port: 8080
spring:
application:
name: gateway
cloud:
nacos:
server-addr: 192.168.150.101:8848
gateway:
routes:
- id: item # 路由规则id,自定义,唯一
uri: lb://item-service # 路由的目标服务,lb代表负载均衡,会从注册中心拉取服务列表
predicates: # 路由断言,判断当前请求是否符合当前规则,符合则路由到目标服务
- Path=/items/**,/search/** # 这里是以请求路径作为判断规则
- id: cart
uri: lb://cart-service
predicates:
- Path=/carts/**
- id: user
uri: lb://user-service
predicates:
- Path=/users/**,/addresses/**
- id: trade
uri: lb://trade-service
predicates:
- Path=/orders/**
- id: pay
uri: lb://pay-service
predicates:
- Path=/pay-orders/**
5.3.路由属性:

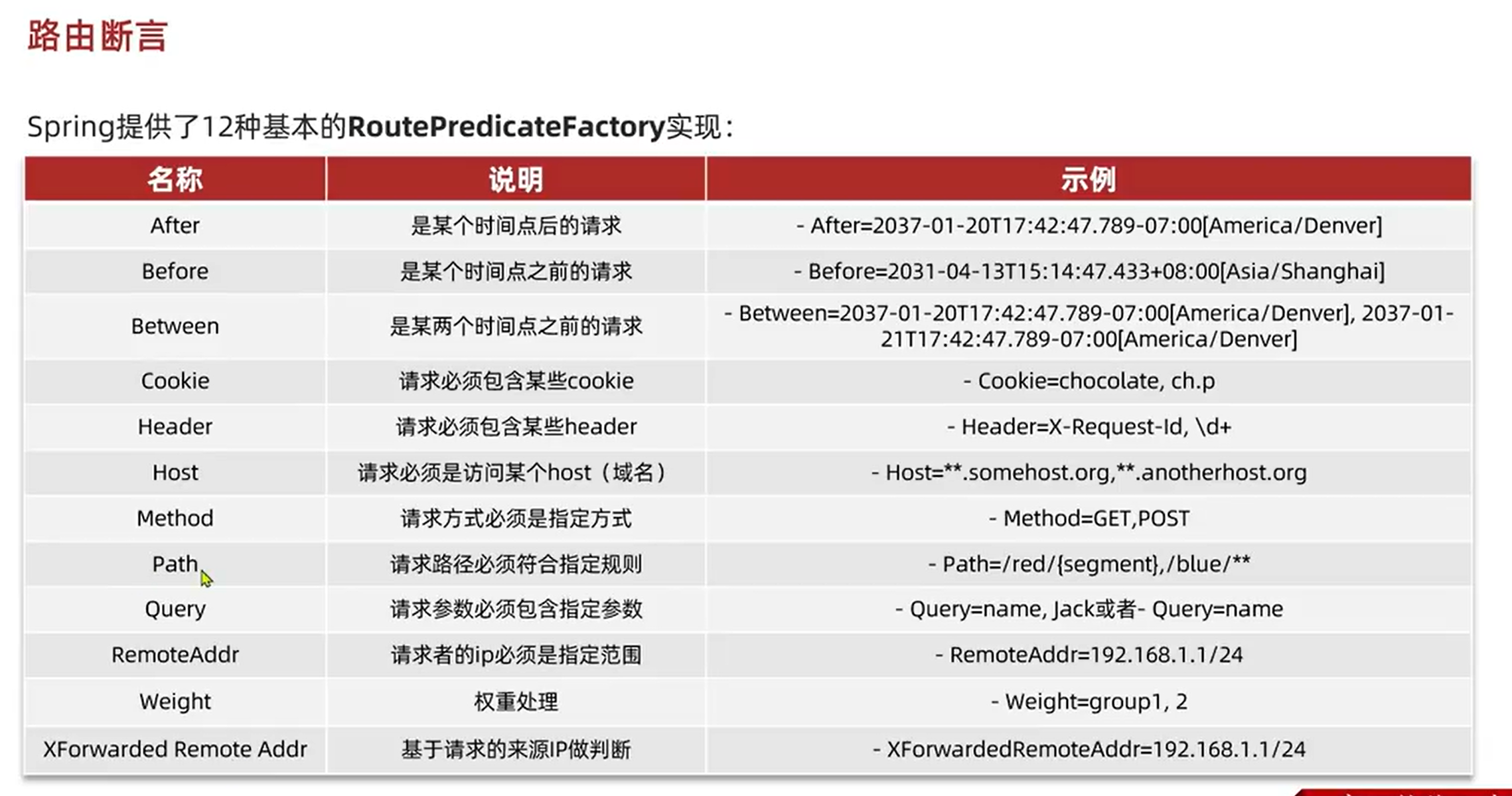

如果想配置一个对所有都生效的过滤器,可以用default-filters,并且该过滤器与routes同级。
5.4.网关登录验证:
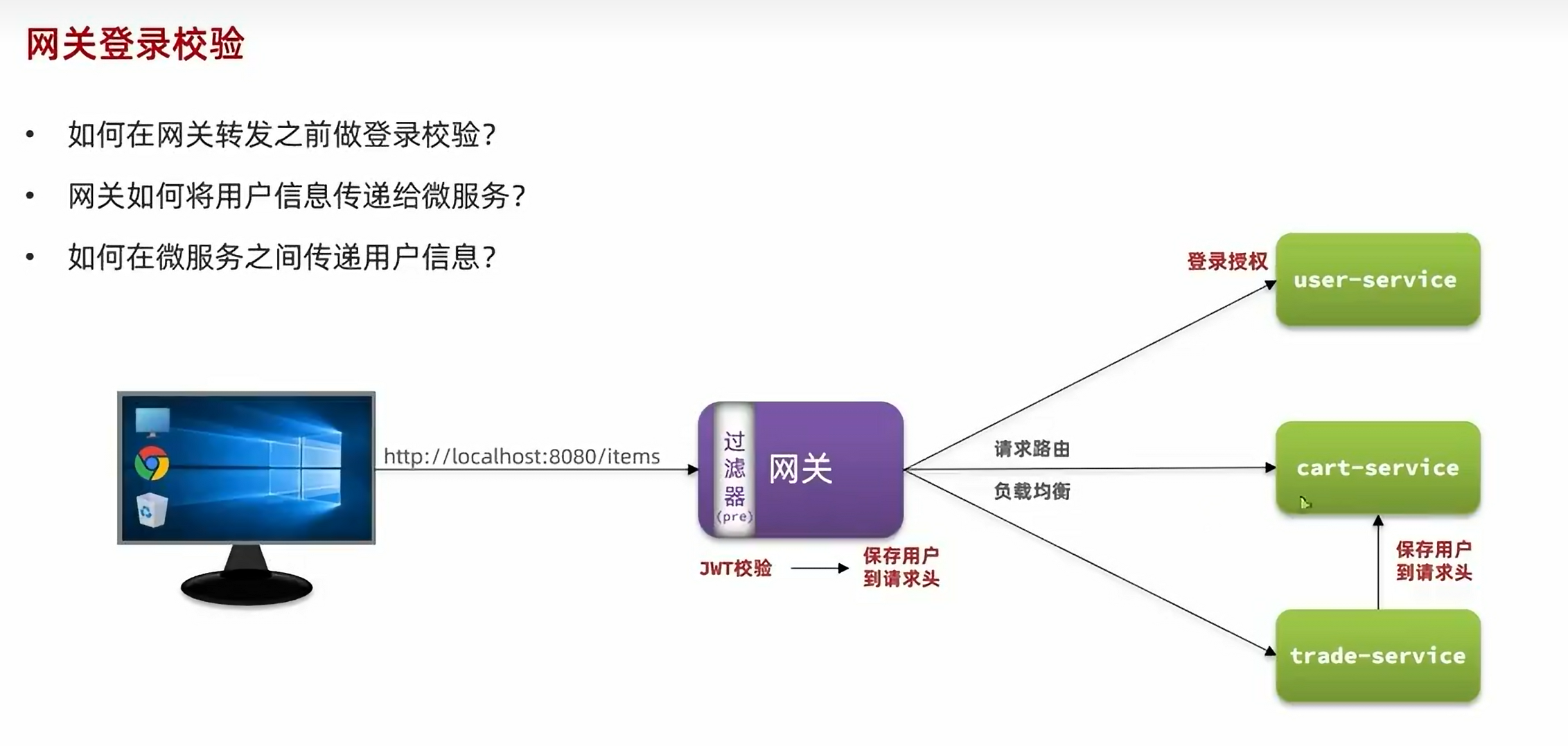
单体架构时我们只需要完成一次用户登录、身份校验,就可以在所有业务中获取到用户信息。而微服务拆分后,每个微服务都独立部署,不再共享数据。也就意味着每个微服务都需要做登录校验,这显然不可取。
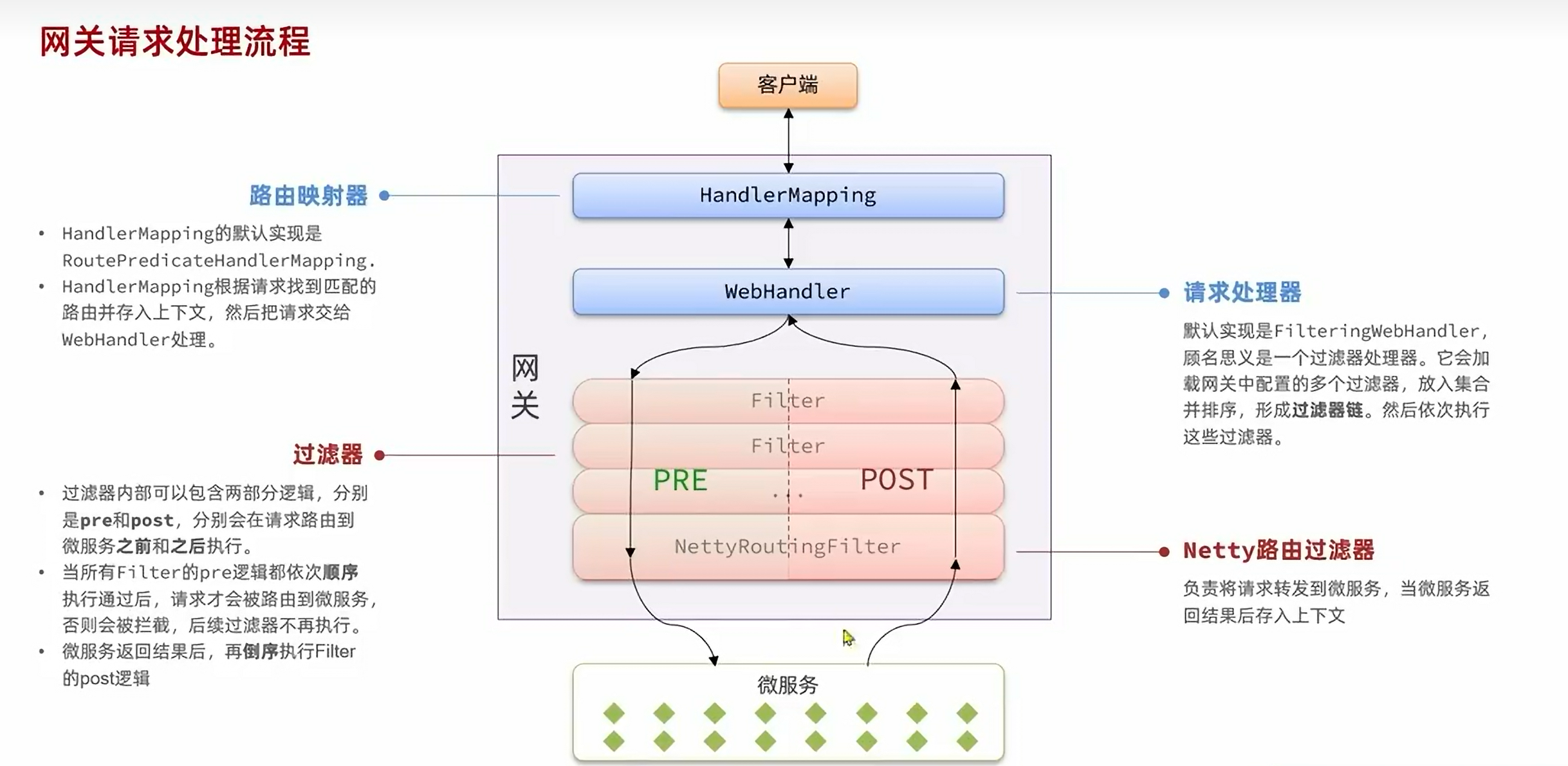
登录校验必须在请求转发到微服务之前做,因此必须在PRE阶段完成。
5.4.1.自定义过滤器:

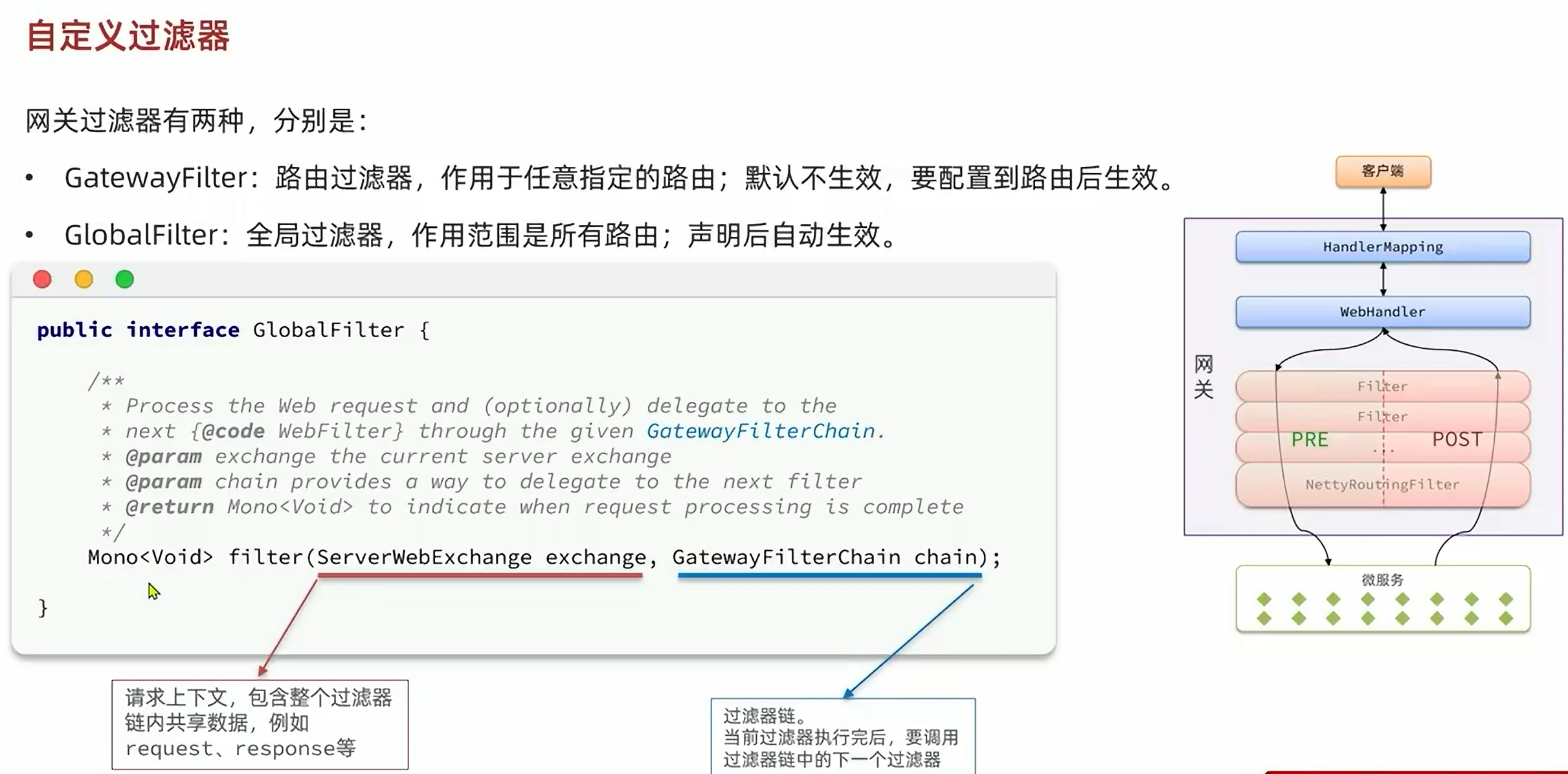
(1):自定义GlobalFilter
自定义GlobalFilter则简单很多,直接实现GlobalFilter即可,而且也无法设置动态参数:
@Component
public class PrintAnyGlobalFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 编写过滤器逻辑
System.out.println("未登录,无法访问");
// 放行
// return chain.filter(exchange);
// 拦截
ServerHttpResponse response = exchange.getResponse();
response.setRawStatusCode(401);
return response.setComplete();
}
@Override
public int getOrder() {
// 过滤器执行顺序,值越小,优先级越高
return 0;
}
}
(2):自定义GatewayFilter:
自定义GatewayFilter不是直接实现GatewayFilter,而是实现AbstractGatewayFilterFactory。最简单的方式是这样的:
@Component
public class PrintAnyGatewayFilterFactory extends AbstractGatewayFilterFactory<Object> {
@Override
public GatewayFilter apply(Object config) {
return new GatewayFilter() {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 获取请求
ServerHttpRequest request = exchange.getRequest();
// 编写过滤器逻辑
System.out.println("过滤器执行了");
// 放行
return chain.filter(exchange);
}
};
}
}
注意:该类的名称一定要以GatewayFilterFactory为后缀!
在yaml配置中这样使用:
spring:
cloud:
gateway:
default-filters:
- PrintAny # 此处直接以自定义的GatewayFilterFactory类名称前缀类声明过滤器
另外,这种过滤器还可以支持动态配置参数,不过实现起来比较复杂,示例:
@Component
public class PrintAnyGatewayFilterFactory // 父类泛型是内部类的Config类型
extends AbstractGatewayFilterFactory<PrintAnyGatewayFilterFactory.Config> {
@Override
public GatewayFilter apply(Config config) {
// OrderedGatewayFilter是GatewayFilter的子类,包含两个参数:
// - GatewayFilter:过滤器
// - int order值:值越小,过滤器执行优先级越高
return new OrderedGatewayFilter(new GatewayFilter() {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 获取config值
String a = config.getA();
String b = config.getB();
String c = config.getC();
// 编写过滤器逻辑
System.out.println("a = " + a);
System.out.println("b = " + b);
System.out.println("c = " + c);
// 放行
return chain.filter(exchange);
}
}, 100);
}
// 自定义配置属性,成员变量名称很重要,下面会用到
@Data
static class Config{
private String a;
private String b;
private String c;
}
// 将变量名称依次返回,顺序很重要,将来读取参数时需要按顺序获取
@Override
public List<String> shortcutFieldOrder() {
return List.of("a", "b", "c");
}
// 返回当前配置类的类型,也就是内部的Config
@Override
public Class<Config> getConfigClass() {
return Config.class;
}
}
然后在yaml文件中使用:
spring:
cloud:
gateway:
default-filters:
- PrintAny=1,2,3 # 注意,这里多个参数以","隔开,将来会按照shortcutFieldOrder()方法返回的参数顺序依次复制
上面这种配置方式参数必须严格按照shortcutFieldOrder()方法的返回参数名顺序来赋值。
还有一种用法,无需按照这个顺序,就是手动指定参数名:
spring:
cloud:
gateway:
default-filters:
- name: PrintAny
args: # 手动指定参数名,无需按照参数顺序
a: 1
b: 2
c: 3
下面我们就基于第一种方法来实现过滤器校验:
@RequiredArgsConstructor
@Component
public class AuthGlobalFilter implements GlobalFilter, Ordered {
private final AuthProperties properties;
private final JwtTool jwtTool;
private final AntPathMatcher antPathMatcher = new AntPathMatcher();
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
//获取
ServerHttpRequest request = exchange.getRequest();
// 判断
if(isExclude(request.getPath().toString())){
// 无需拦截,直接放行
return chain.filter(exchange);
}
//获取token
String token = null;
List<String> headers = request.getHeaders().get("authorization");
if(headers != null && !headers.isEmpty()){
token = headers.get(0);
}
//检验
Long userId = null;
try{
userId = jwtTool.parseToken(token);
}catch (UnauthorizedException e) {
ServerHttpResponse response = exchange.getResponse();
response.setStatusCode(HttpStatus.UNAUTHORIZED);
return response.setComplete();
}
System.out.println("userId = " + userId);
return chain.filter(exchange);
}
private boolean isExclude(String antPath) {
for (String pathPattern : properties.getExcludePaths()) {
if(antPathMatcher.match(pathPattern, antPath)){
return true;
}
}
return false;
}
@Override
public int getOrder() {
// 过滤器执行顺序,值越小,优先级越高
return 0;
}
}
5.4.2.自定义拦截器
接下来,再实现用户信息的转发:
为什么需要将token传递给后端微服务
尽管API Gateway可以对外部请求进行认证和授权,但在实际应用中,将JWT token传递给后端微服务是非常重要的。原因如下:
1. 后端微服务的安全性
API Gateway验证了请求的合法性并路由到相应的微服务后,后端微服务仍然需要知道请求的来源以及相关的用户信息,以确保其安全性。例如,有些微服务可能需要根据用户角色或权限执行不同的逻辑。
2. 微服务的自治性
每个微服务都应该是自治的,即它们应该能够独立处理自己的认证和授权逻辑。如果所有认证和授权逻辑都在API Gateway中处理,而后端微服务完全依赖于Gateway的判断,那么后端微服务在安全性上会存在一定的风险。
3. 避免绕过API Gateway
在一些情况下,内部服务之间的请求可能会绕过API Gateway直接访问某个微服务。如果后端微服务不自行验证JWT token,这些绕过API Gateway的请求将无法被验证,从而带来安全风险。
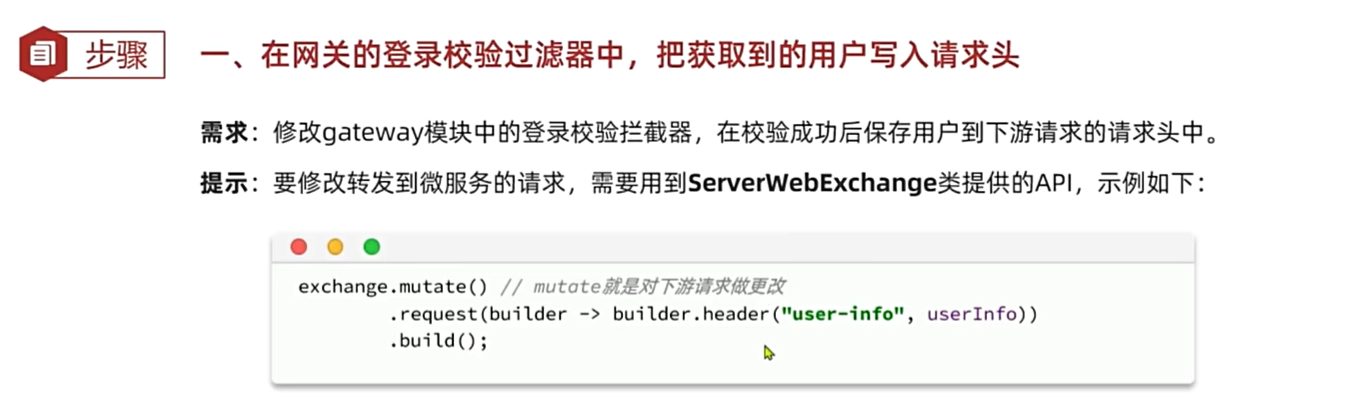
String userInfo = userId.toString();
ServerWebExchange swe = exchange.mutate().request(builder -> builder.header("user-info", userInfo)).build();
return chain.filter(swe);
mutate() 方法在 Spring WebFlux 中用于创建一个新的构建器对象,以便对现有的 ServerHttpRequest 或 ServerWebExchange 进行修改,而不会直接改变原始对象。这种方法遵循不可变对象的设计模式,通过创建新的对象来体现修改后的状态。mutate() 方法用于创建一个构建器(builder)对象。这个构建器可以用来添加、修改或删除请求的各个部分,然后生成一个新的、修改后的对象。
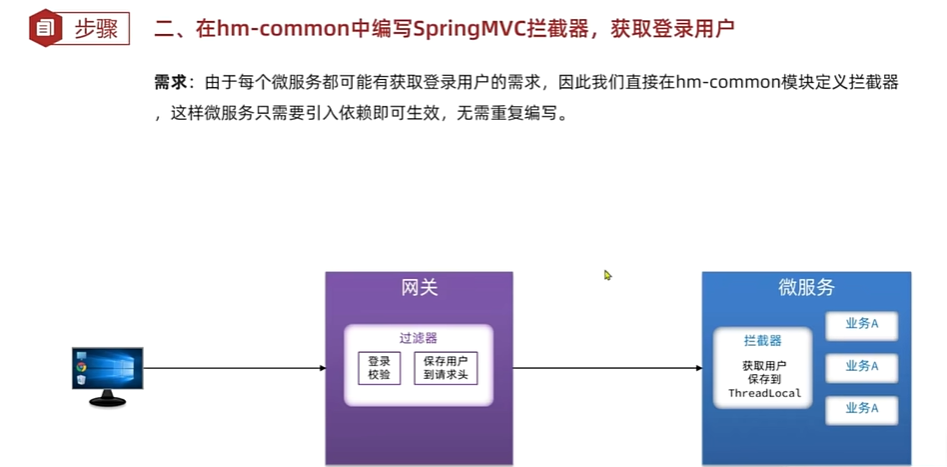
拦截器的逻辑如下:
public class UserInfoInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 1.获取请求头中的用户信息
String userInfo = request.getHeader("user-info");
// 2.判断是否为空
if (StrUtil.isNotBlank(userInfo)) {
// 不为空,保存到ThreadLocal
UserContext.setUser(Long.valueOf(userInfo));
}
// 3.放行
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
// 移除用户
UserContext.removeUser();
}
}
配置拦截器:
@Configuration
@ConditionalOnClass(DispatcherServlet.class)
public class MvcConfig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new com.hmall.common.interceptor.UserInfoInterceptor());
}
}
gateway不是基于springMvc的,所以该MvcConfig不应该生效。通过使用@ConditionalOnClass(DispatcherServlet.class),表示仅对包含了springMvc的核心类(DispatcherServlet)的微服务生效。
注意,现在还是不会生效,因为它所在的包是com.hmall.common.config,与其它微服务的扫描包不一致,无法被扫描到,因此无法生效。基于SpringBoot的自动装配原理,我们要将其添加到resources目录下的META-INF/spring.factories文件中:
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.hmall.common.config.MyBatisConfig,\
com.hmall.common.config.MvcConfig,\
com.hmall.common.config.JsonConfig
注意,common包没有启动类的,所以不能直接扫描。
5.4.3.OpenFeign传递用户:
问题:当我们把信息存储在了Usertext中,那不同微服务彼此调用的时候,为什么会失效呢?
A:因为,在每次走网关的请求结束后,会删除Usertext中的用户信息,但是对于不同微服务彼此的调用来说,它并不是走的网关,而是走的OpenFeign,是没有携带用户信息的。
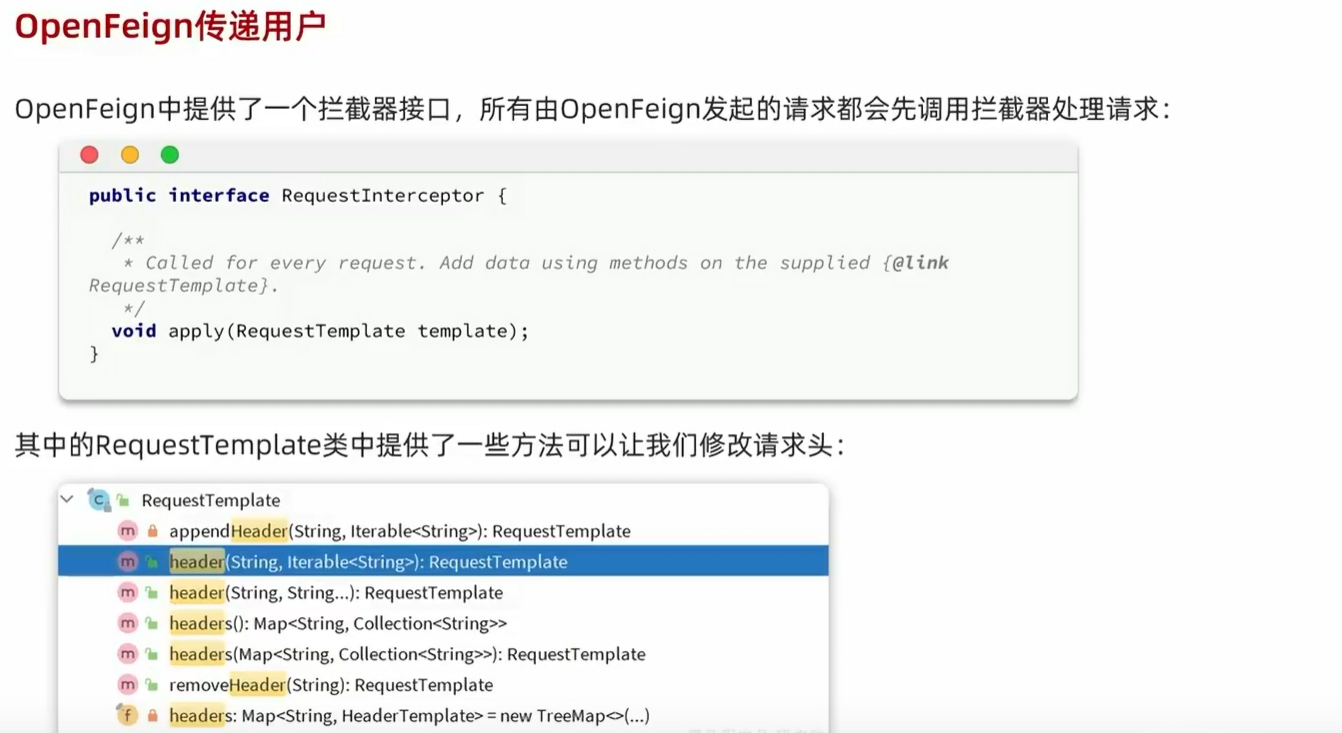
public class DefaultFeignConfig {
@Bean
public Logger.Level feignLogLevel(){
return Logger.Level.FULL;
}
@Bean
public RequestInterceptor userInfoRequestInterceptor(){
return new RequestInterceptor() {
@Override
public void apply(RequestTemplate template) {
Long userId = UserContext.getUser();
if (userId != null){
template.header("user-info", userId.toString());
}
}
};
}
}
配置如上。
5.5.配置管理:
现在的问题:
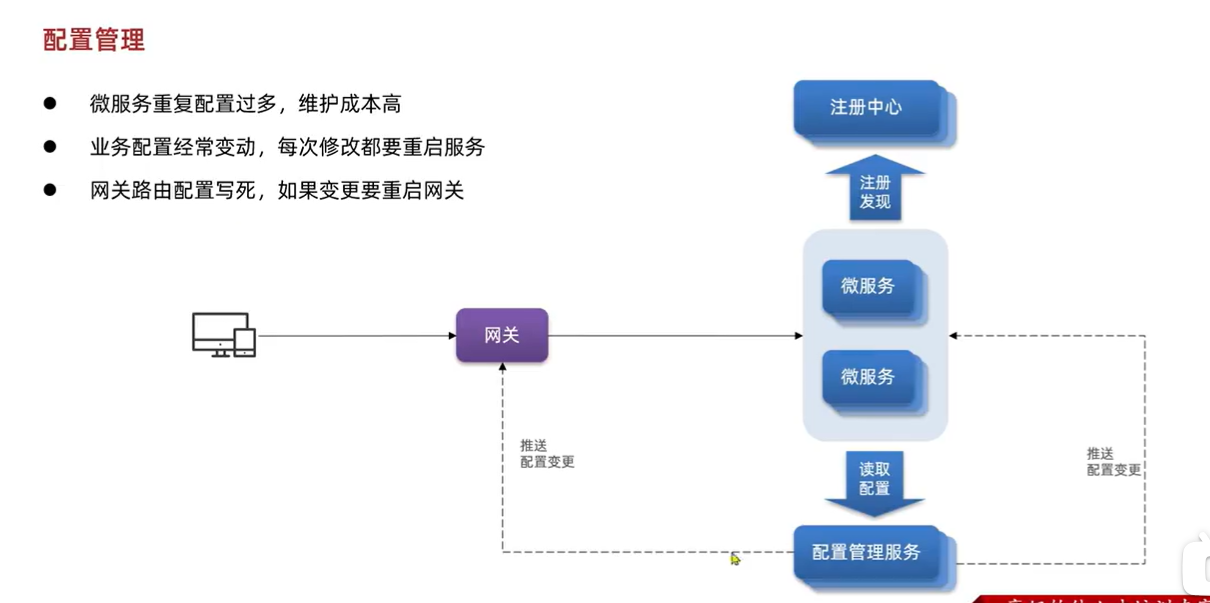
5.5.1.配置共享:
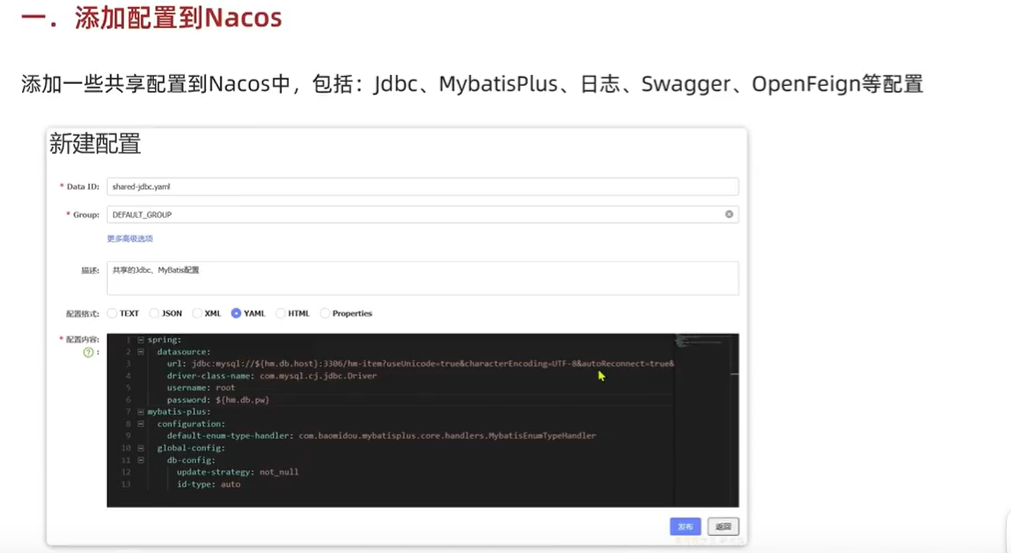
下面举例几种共享配置:
spring:
datasource:
url: jdbc:mysql://${hm.db.host:192.168.150.101}:${hm.db.port:3306}/${hm.db.database}?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
driver-class-name: com.mysql.cj.jdbc.Driver
username: ${hm.db.un:root}
password: ${hm.db.pw:123}
mybatis-plus:
configuration:
default-enum-type-handler: com.baomidou.mybatisplus.core.handlers.MybatisEnumTypeHandler
global-config:
db-config:
update-strategy: not_null
id-type: auto
数据库ip:通过${hm.db.host:192.168.150.101}配置了默认值为192.168.150.101,同时允许通过${hm.db.host}来覆盖默认值数据库端口:通过${hm.db.port:3306}配置了默认值为3306,同时允许通过${hm.db.port}来覆盖默认值数据库database:可以通过${hm.db.database}来设定,无默认值
knife4j:
enable: true
openapi:
title: ${hm.swagger.title:黑马商城接口文档}
description: ${hm.swagger.description:黑马商城接口文档}
email: ${hm.swagger.email:zhanghuyi@itcast.cn}
concat: ${hm.swagger.concat:虎哥}
url: https://www.itcast.cn
version: v1.0.0
group:
default:
group-name: default
api-rule: package
api-rule-resources:
- ${hm.swagger.package}
注意,这里的swagger相关配置我们没有写死,例如:
title:接口文档标题,我们用了${hm.swagger.title}来代替,将来可以有用户手动指定email:联系人邮箱,我们用了${hm.swagger.email:``zhanghuyi@itcast.cn``},默认值是zhanghuyi@itcast.cn,同时允许用户利用${hm.swagger.email}来覆盖。
问题提出:
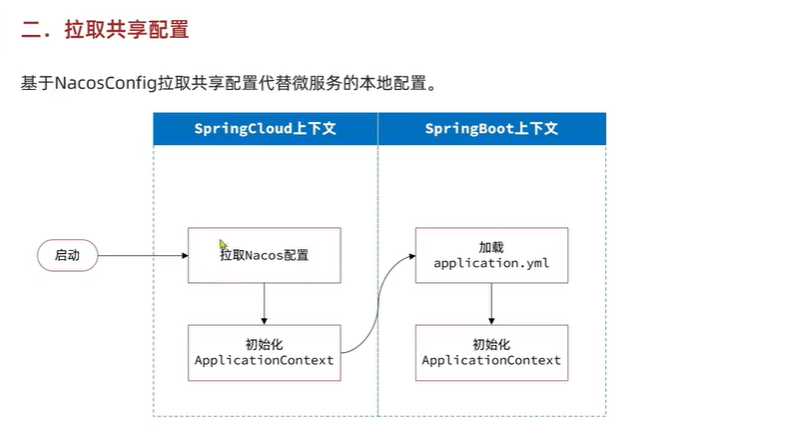
当我们刚开始拉取nacos配置的时候,application.yml还没有被读取,那么他是怎么获取到nacos的ip的?
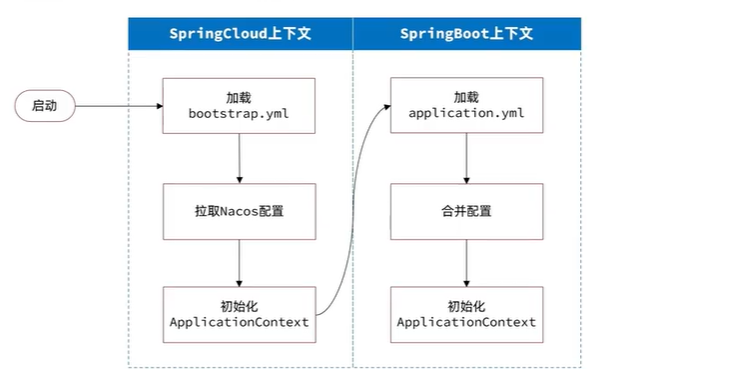
加上这个配置就OK了。
因此,微服务整合Nacos配置管理的步骤如下:
1)引入依赖:
在cart-service模块引入依赖:
<!--nacos配置管理-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!--读取bootstrap文件-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>
2)新建bootstrap.yaml
在cart-service中的resources目录新建一个bootstrap.yaml文件:
spring:
application:
name: cart-service # 服务名称
profiles:
active: dev
cloud:
nacos:
server-addr: 192.168.6.128 # nacos地址
config:
file-extension: yaml # 文件后缀名
shared-configs: # 共享配置
- dataId: shared-jdbc.yaml # 共享mybatis配置
- dataId: shared-log.yaml # 共享日志配置
- dataId: shared-swagger.yaml # 共享日志配置
3)修改application.yaml
由于一些配置挪到了bootstrap.yaml,因此application.yaml需要修改为:
server:
port: 8082
feign:
okhttp:
enabled: true # 开启OKHttp连接池支持
hm:
swagger:
title: 购物车服务接口文档
package: com.hmall.cart.controller
db:
database: hm-cart
重启服务,发现所有配置都生效了。
5.5.2.配置热更新:


在cart-service中新建一个属性读取类:
package com.hmall.cart.config;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
@Data
@Component
@ConfigurationProperties(prefix = "hm.cart")
public class CartProperties {
private Integer maxAmount;
}
接着,在业务中使用该属性加载类:
private void checkCartsFull(Long userId) {
Long count = lambdaQuery().eq(Cart::getUserId, userId).count();
if (count >= cartProperties.getMaxAmount()) {
throw new BizIllegalException(StrUtil.format("用户购物车课程不能超过{}", 10));
}
}
配置如下:
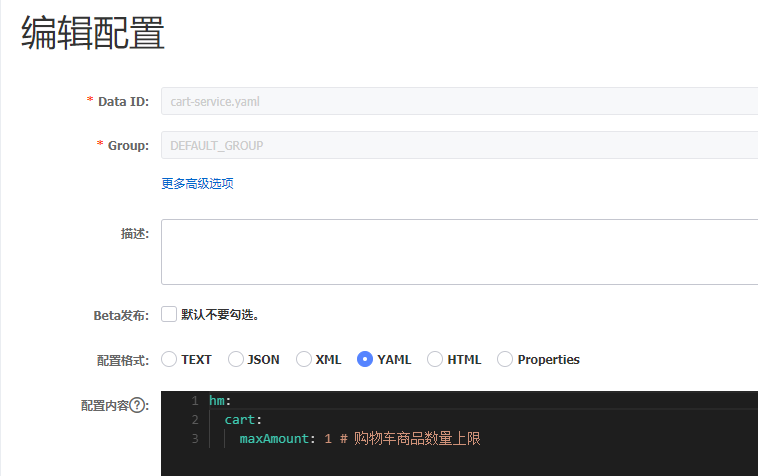
注意命名要符合规则。
5.5.3.动态路由
网关的路由配置全部是在项目启动时由org.springframework.cloud.gateway.route.CompositeRouteDefinitionLocator在项目启动的时候加载,并且一经加载就会缓存到内存中的路由表内(一个Map),不会改变。也不会监听路由变更,所以,我们无法利用上节课学习的配置热更新来实现路由更新。
因此,我们必须监听Nacos的配置变更,然后手动把最新的路由更新到路由表中。这里有两个难点:
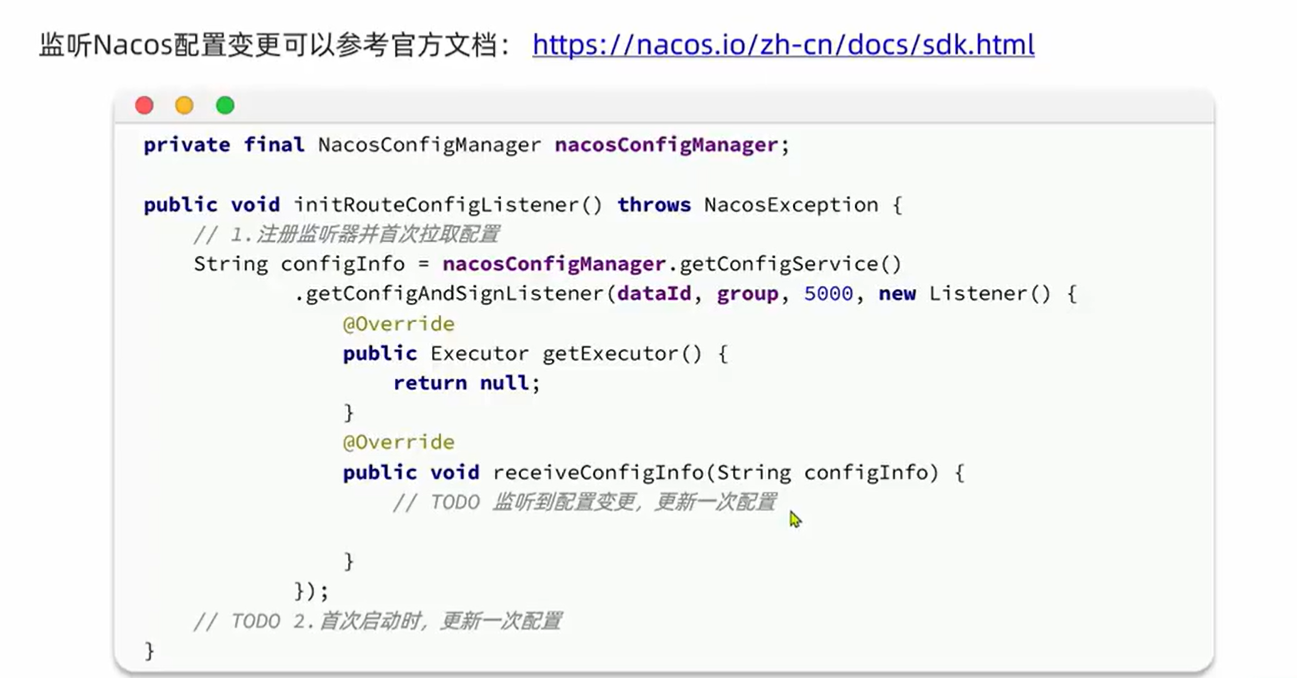
代码如下:
@Slf4j
@Component
@RequiredArgsConstructor
public class DynamicRouteLoader {
private final RouteDefinitionWriter writer;
private final NacosConfigManager nacosConfigManager;
// 路由配置文件的id和分组
private final String dataId = "gateway-routes.json";
private final String group = "DEFAULT_GROUP";
// 保存更新过的路由id
private final Set<String> routeIds = new HashSet<>();
@PostConstruct
public void initRouteConfigListener() throws NacosException {
// 1.注册监听器并首次拉取配置
String configInfo = nacosConfigManager.getConfigService()
.getConfigAndSignListener(dataId, group, 5000, new Listener() {
@Override
public Executor getExecutor() {
return null;
}
@Override
public void receiveConfigInfo(String configInfo) {
updateConfigInfo(configInfo);
}
});
// 2.首次启动时,更新一次配置
updateConfigInfo(configInfo);
}
private void updateConfigInfo(String configInfo) {
log.debug("监听到路由配置变更,{}", configInfo);
// 1.反序列化
List<RouteDefinition> routeDefinitions = JSONUtil.toList(configInfo, RouteDefinition.class);
// 2.更新前先清空旧路由
// 2.1.清除旧路由
for (String routeId : routeIds) {
writer.delete(Mono.just(routeId)).subscribe();
}
routeIds.clear();
// 2.2.判断是否有新的路由要更新
if (CollUtils.isEmpty(routeDefinitions)) {
// 无新路由配置,直接结束
return;
}
// 3.更新路由
routeDefinitions.forEach(routeDefinition -> {
// 3.1.更新路由
writer.save(Mono.just(routeDefinition)).subscribe();
// 3.2.记录路由id,方便将来删除
routeIds.add(routeDefinition.getId());
});
}
}
详细解释
@PostConstruct注解:- 该注解用于在 Spring Bean 完全初始化之后执行一些初始化操作。也就是说,当该 Bean 被创建并注入依赖之后,
initRouteConfigListener方法会被自动调用。
- 该注解用于在 Spring Bean 完全初始化之后执行一些初始化操作。也就是说,当该 Bean 被创建并注入依赖之后,
initRouteConfigListener方法:- 这个方法注册了一个 Nacos 配置监听器,并在首次启动时获取配置和更新配置。
详细步骤
-
获取 Nacos 配置服务:
nacosConfigManager.getConfigService()返回一个ConfigService实例,它用于与 Nacos 配置中心交互。
-
注册监听器并获取配置:
getConfigAndSignListener(dataId, group, 5000, new Listener() {...})方法:- 参数解释:
dataId:Nacos 配置的唯一标识符,用于区分不同的配置。group:配置分组,用于组织和管理配置。5000:超时时间,单位为毫秒,即在5秒内完成配置获取。new Listener() {...}:匿名内部类实现了Listener接口,用于监听配置变更。
- 返回值:返回配置的内容
configInfo,即当前 Nacos 配置中心存储的配置内容。
- 参数解释:
-
Listener接口实现:getExecutor()方法:- 返回值为
null,表示使用 Nacos 客户端默认的线程池。
- 返回值为
receiveConfigInfo(String configInfo)方法:- 当 Nacos 配置中心的配置发生变化时,这个方法会被调用,参数
configInfo是新的配置内容。 - 调用
updateConfigInfo(configInfo)方法来处理新的配置内容。
- 当 Nacos 配置中心的配置发生变化时,这个方法会被调用,参数
-
首次启动时更新配置:
updateConfigInfo(configInfo)方法:- 在首次启动时,立即调用
updateConfigInfo方法,使用从 Nacos 配置中心获取的配置内容来更新配置。
- 在首次启动时,立即调用
总结
该代码片段的主要功能是在 Spring 应用启动时,通过 Nacos 配置中心注册一个监听器,并在首次启动时获取配置并应用。监听器会在配置发生变化时自动更新配置。这种机制确保了应用程序能够动态地响应配置变化,而不需要重启应用。
然后在nacos上面动态添加路由信息:
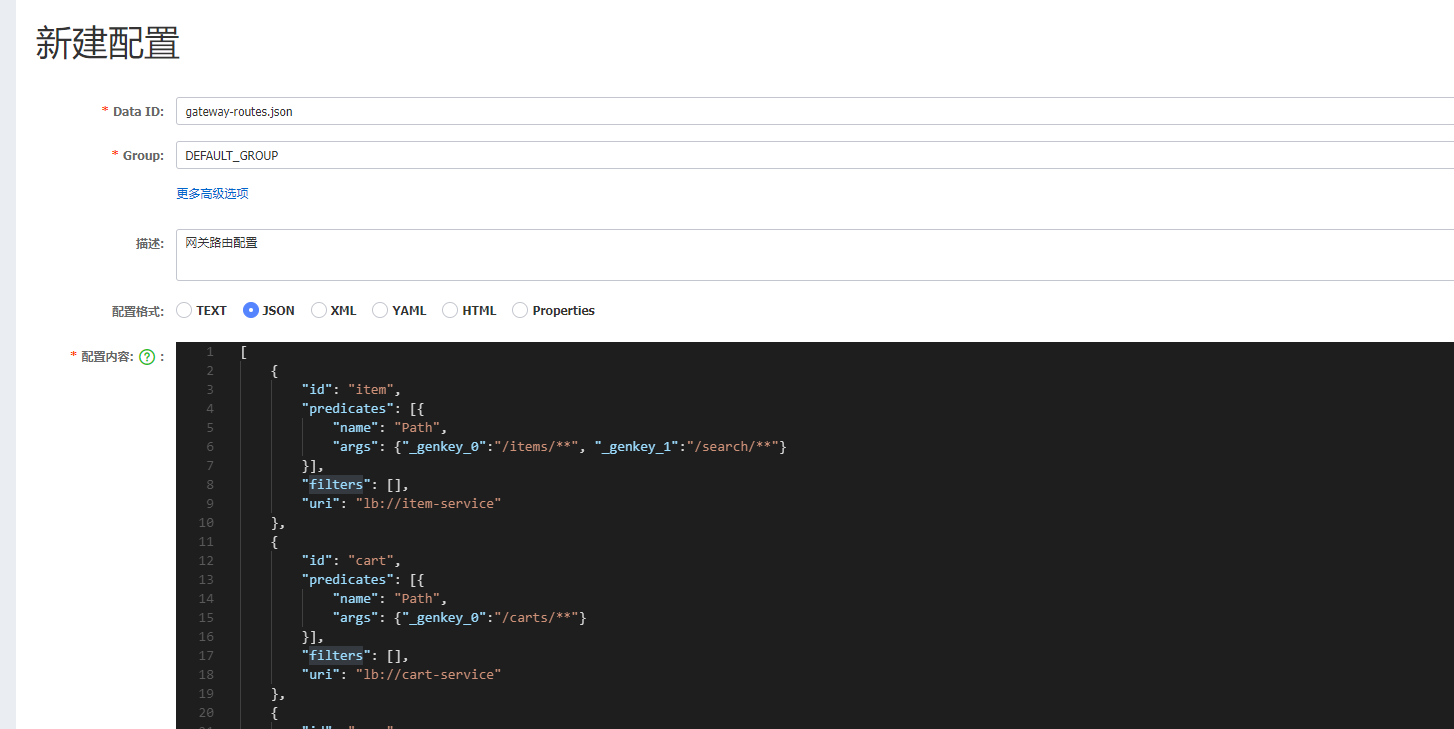
六:微服务保护与分布式事务:
6.1.雪崩问题:
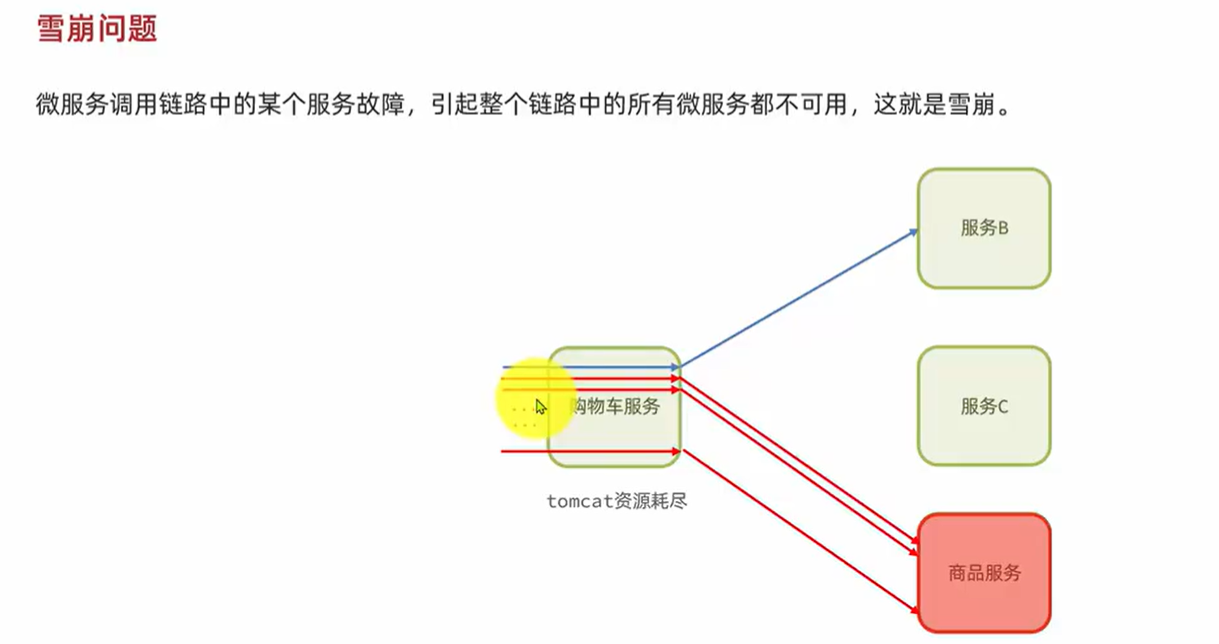
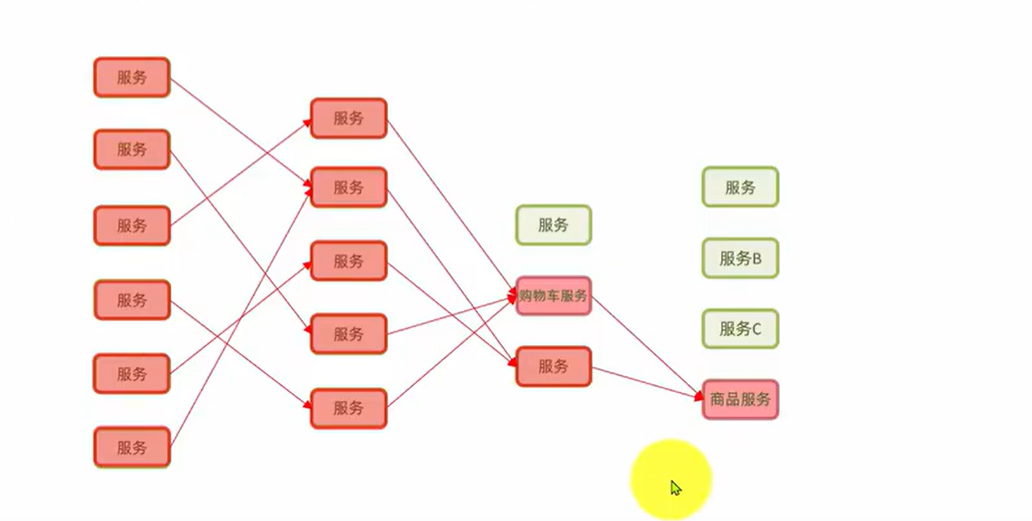
甚至出现级联失败。
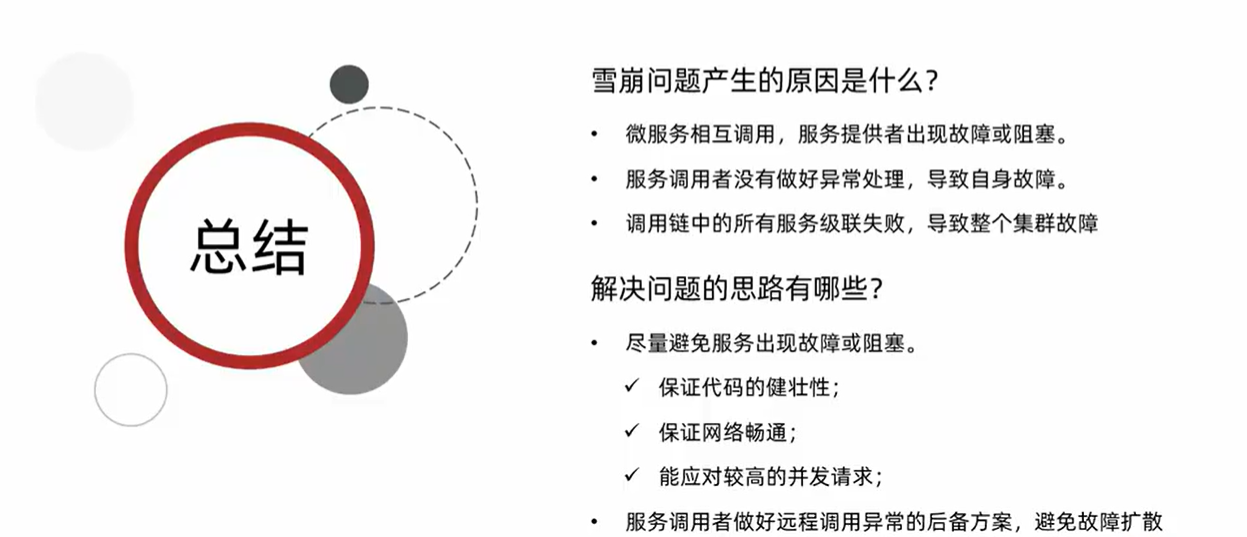
解决方案:
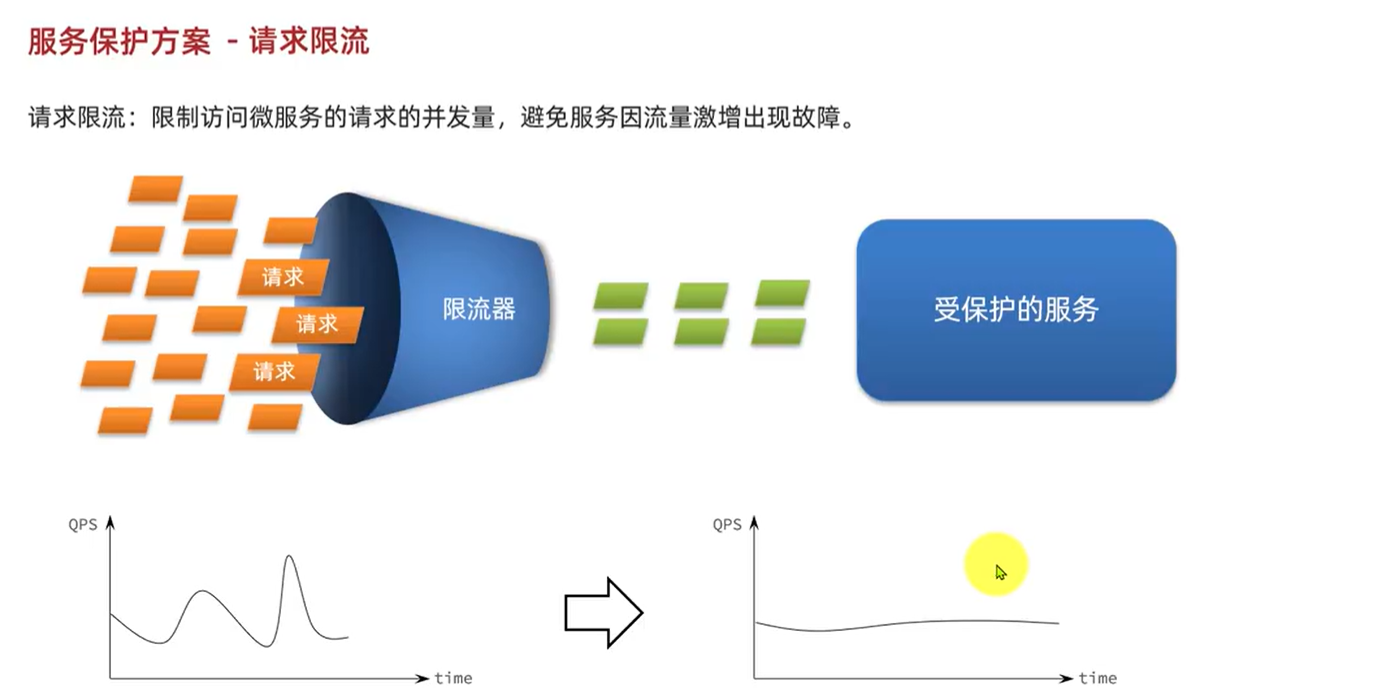
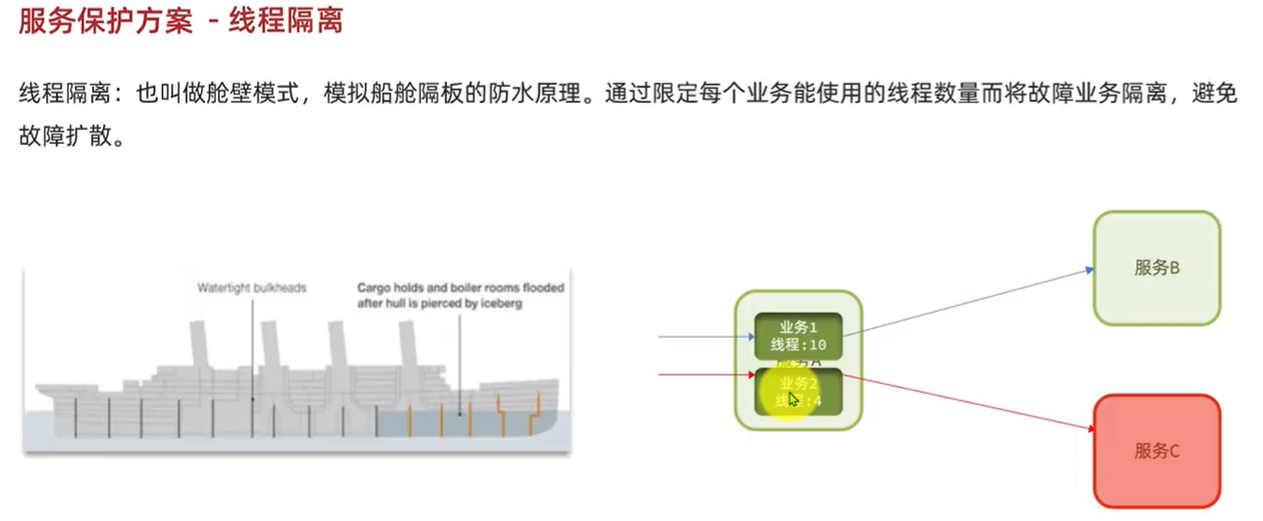
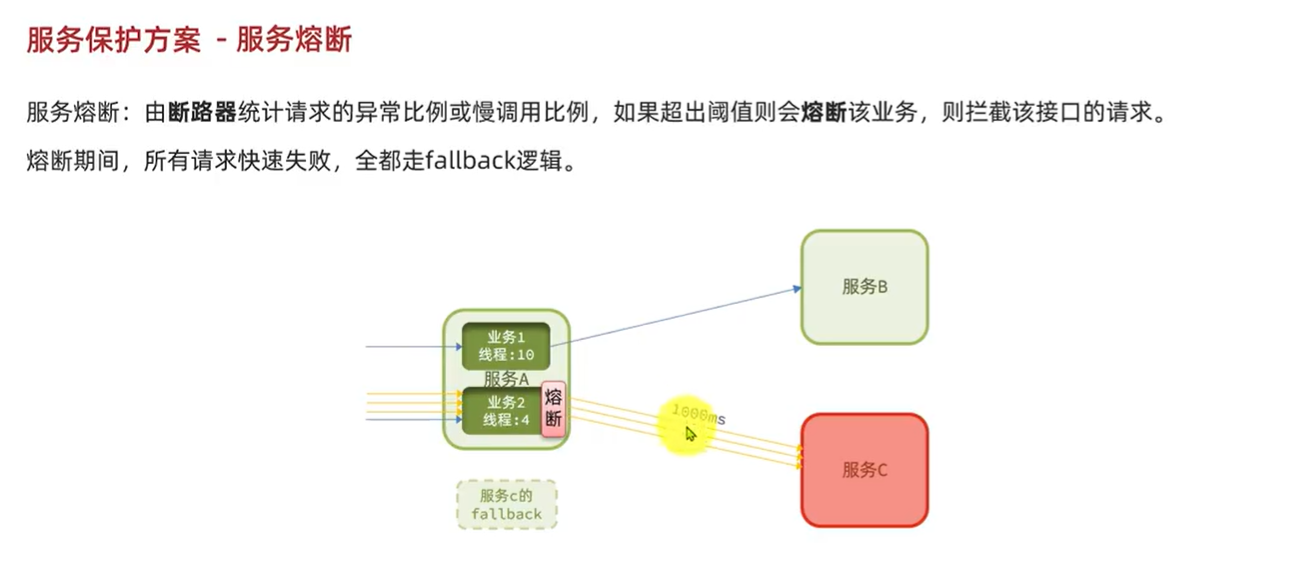


6.2.Sentinel:
下载好客户端后,输入以下命令启动:
java -Dserver.port=8090 -Dcsp.sentinel.dashboard.server=localhost:8090 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard.jar
再加入以下依赖:
<!--sentinel-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
在yaml中加上:
spring:
cloud:
sentinel:
transport:
dashboard: localhost:8090
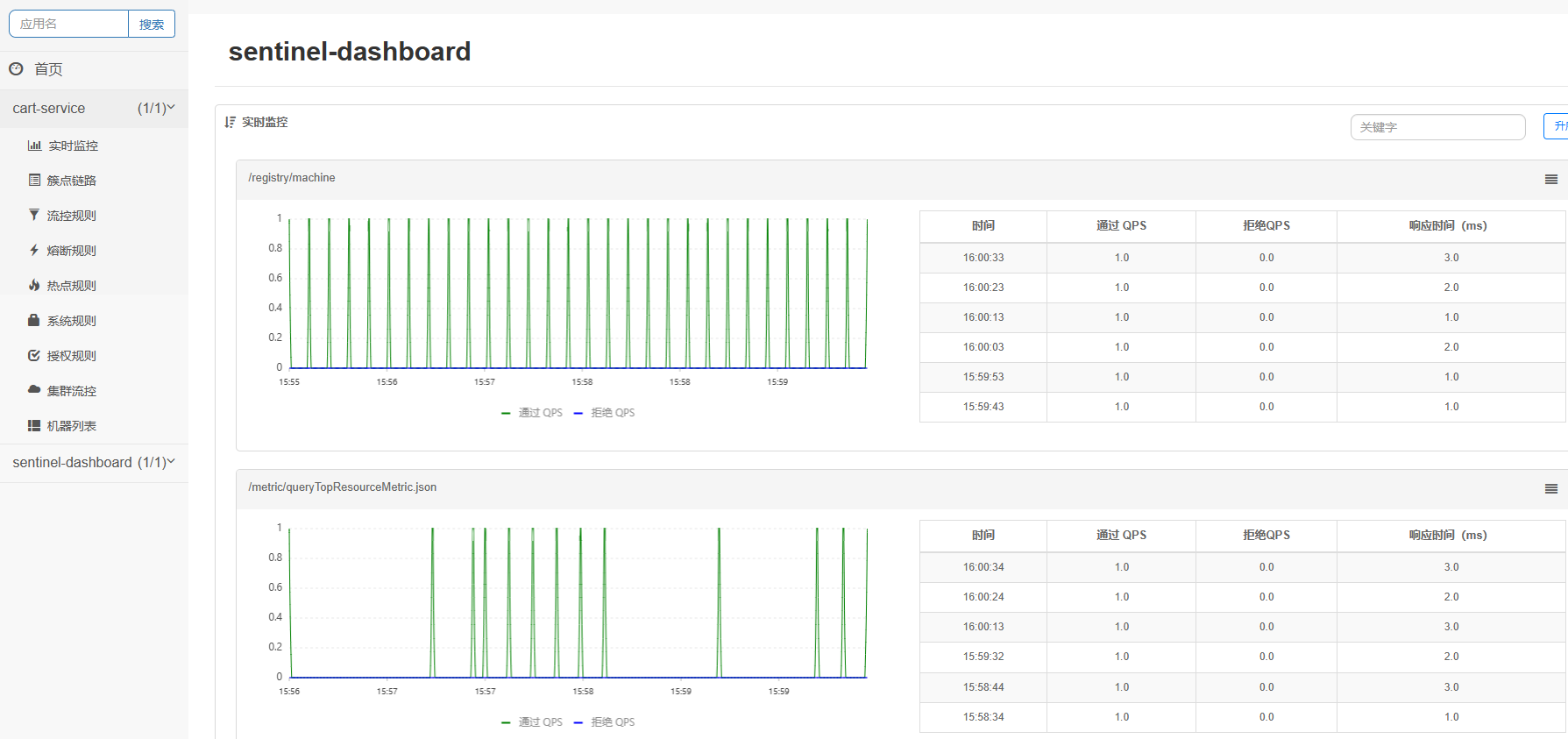
此时即可实现监控。
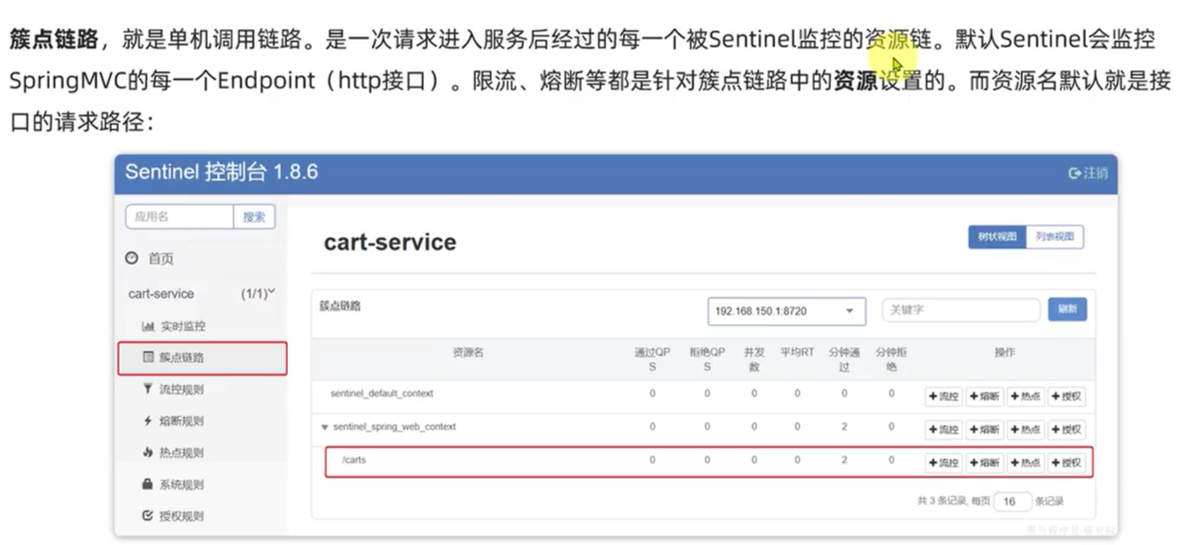
不过,需要注意的是,我们的SpringMVC接口是按照Restful风格设计,因此购物车的查询、删除、修改等接口全部都是/carts路径。所以我们可以选择打开Sentinel的请求方式前缀,把请求方式 + 请求路径作为簇点资源名:
首先,在cart-service的application.yml中添加下面的配置:
spring:
cloud:
sentinel:
transport:
dashboard: localhost:8090
http-method-specify: true # 开启请求方式前缀
然后,重启服务,通过页面访问购物车的相关接口,可以看到sentinel控制台的簇点链路发生了变化:
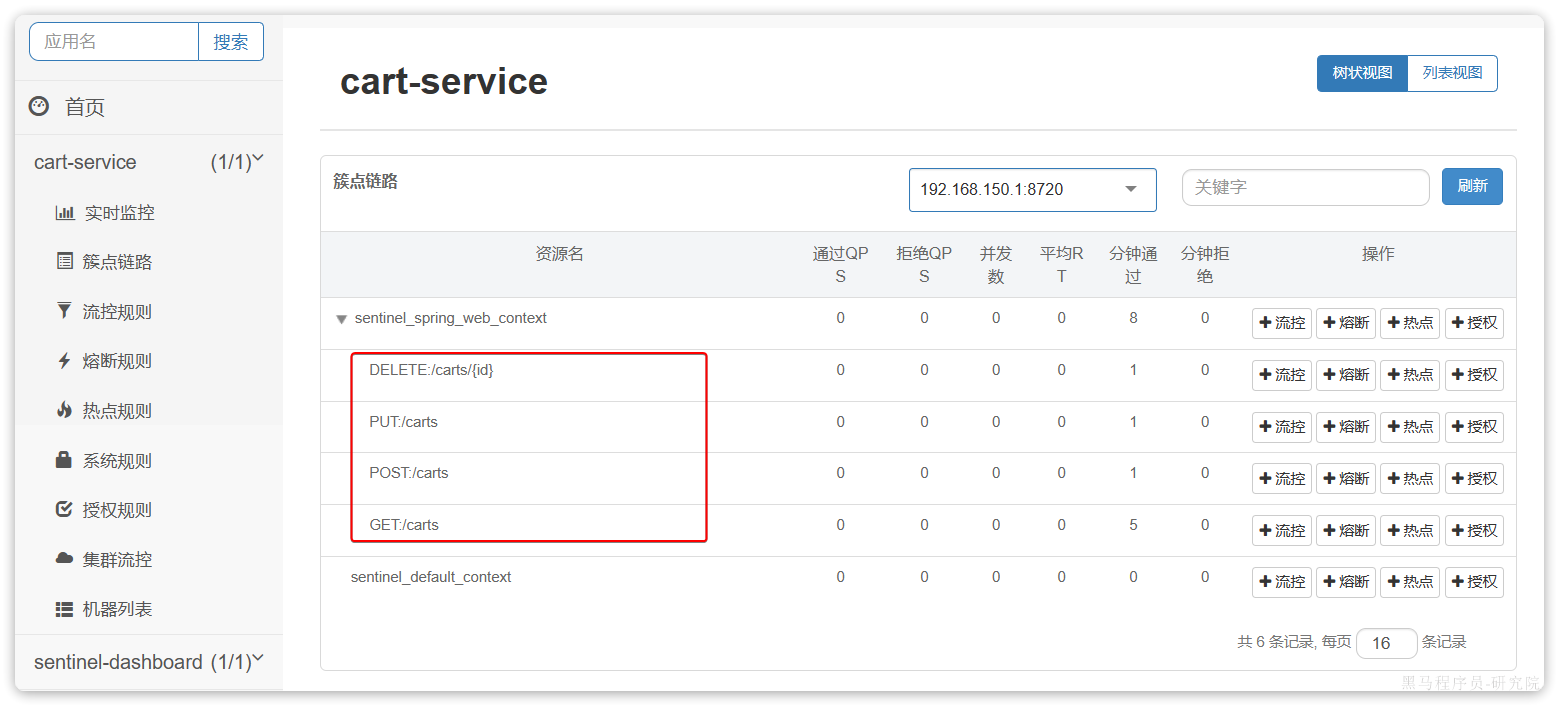
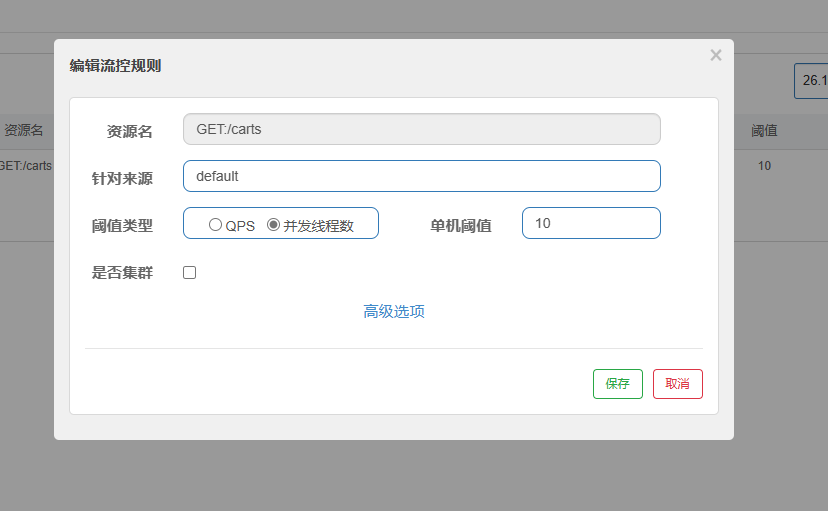
6.2.1.请求限流:
在簇点链路后面点击流控按钮,即可对其做限流配置:
在弹出的菜单中这样填写:
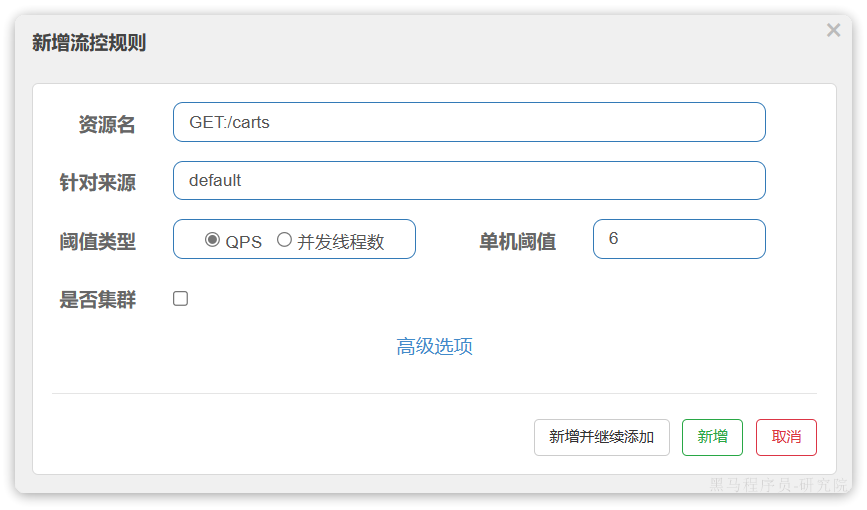
这样就把查询购物车列表这个簇点资源的流量限制在了每秒6个,也就是最大QPS为6.
通过测试,可以看到限流成功:
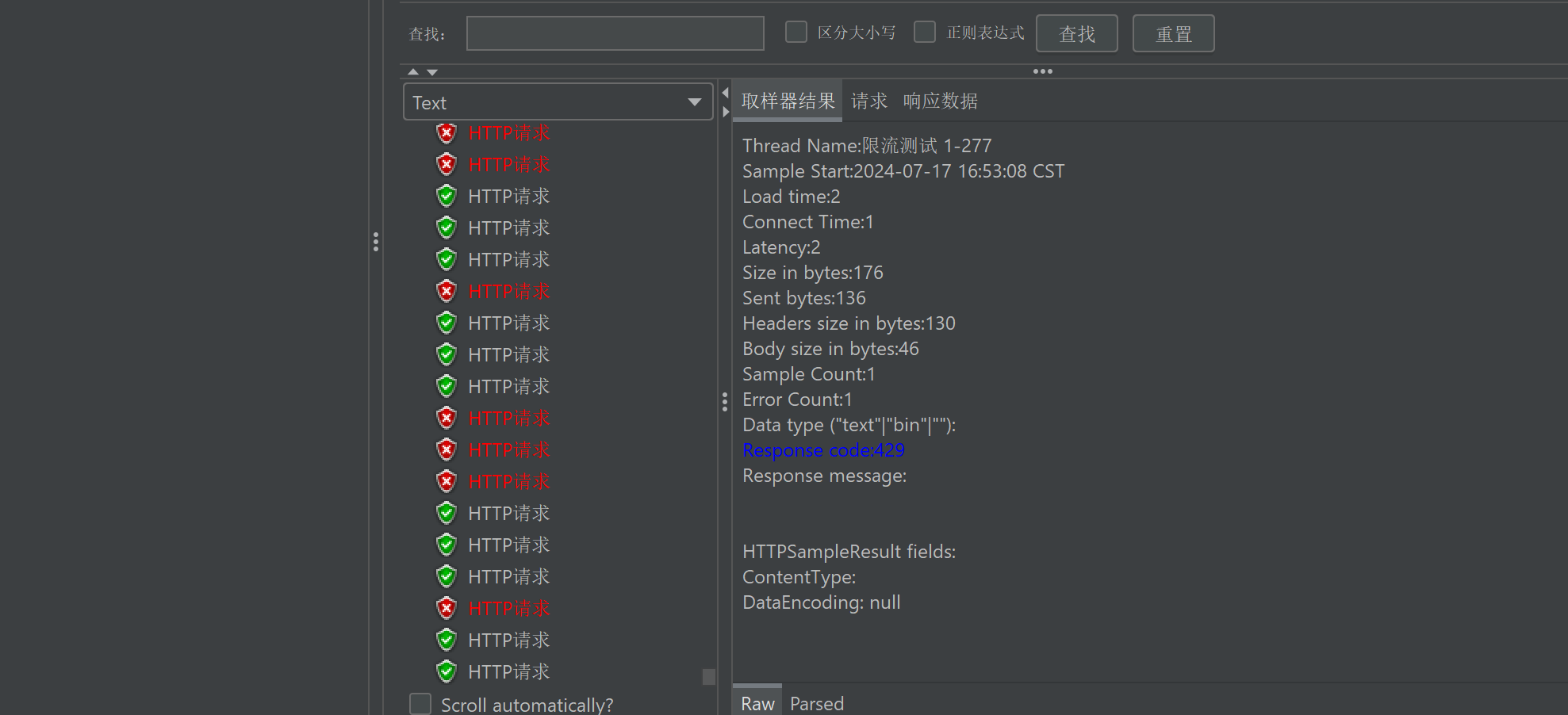
6.2.2.线程隔离:
限流可以降低服务器压力,尽量减少因并发流量引起的服务故障的概率,但并不能完全避免服务故障。一旦某个服务出现故障,我们必须隔离对这个服务的调用,避免发生雪崩。
补充:当我们去测试时,需要注意的是,默认情况下SpringBoot项目的tomcat最大线程数是200,允许的最大连接是8492,单机测试很难打满。所以我们需要配置一下cart-service模块的application.yml文件,修改tomcat连接:
server:
port: 8082
tomcat:
threads:
max: 50 # 允许的最大线程数
accept-count: 50 # 最大排队等待数量
max-connections: 100 # 允许的最大连接
此时,若不进行隔离,那么测试一个sleep处理的慢接口时,可能会导致其他的正常接口变慢。因为线程都被它抢占了。
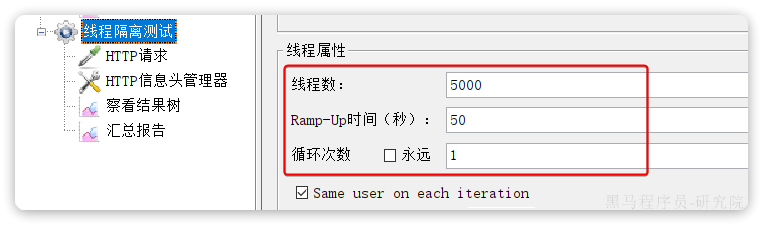
修改后我们利用Jemeter测试,每秒发送100个请求:
最终测试结果如下:
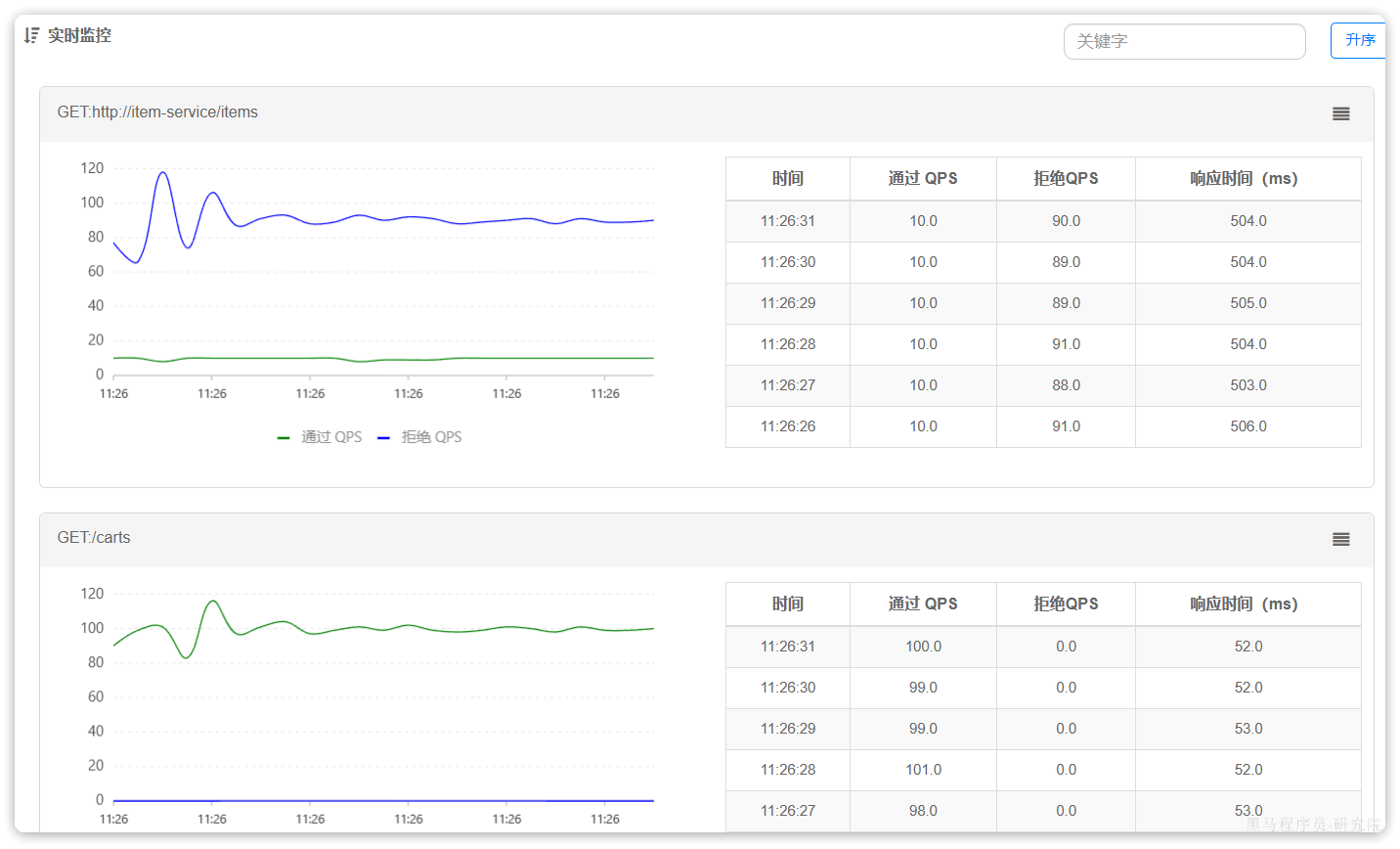
进入查询购物车的请求每秒大概在100,而在查询商品时却只剩下每秒10左右,符合我们的预期。
6.2.3.服务熔断:
几个问题:
第一,超出的QPS上限的请求就只能抛出异常,从而导致购物车的查询失败。但从业务角度来说,即便没有查询到最新的商品信息,购物车也应该展示给用户,用户体验更好。也就是给查询失败设置一个降级处理逻辑。
第二,由于查询商品的延迟较高(模拟的500ms),从而导致查询购物车的响应时间也变的很长。这样不仅拖慢了购物车服务,消耗了购物车服务的更多资源,而且用户体验也很差。对于商品服务这种不太健康的接口,我们应该直接停止调用,直接走降级逻辑,避免影响到当前服务。也就是将商品查询接口熔断。
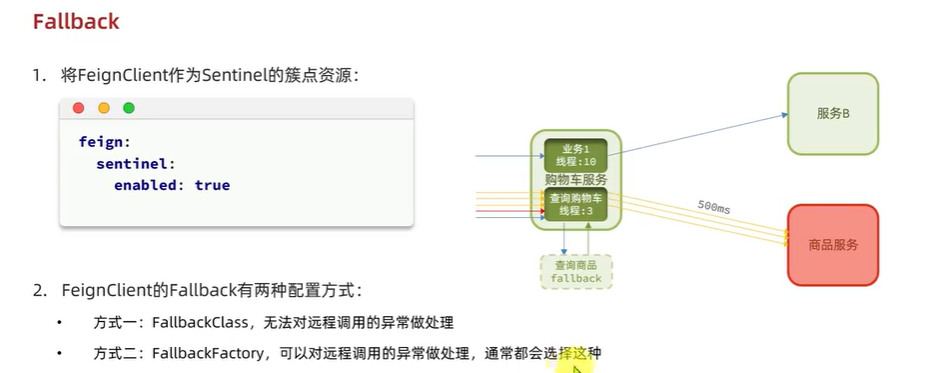
步骤一:在hm-api模块中给ItemClient定义降级处理类,实现FallbackFactory:
package com.hmall.api.client.fallback;
import com.hmall.api.client.ItemClient;
import com.hmall.api.dto.ItemDTO;
import com.hmall.api.dto.OrderDetailDTO;
import com.hmall.common.exception.BizIllegalException;
import com.hmall.common.utils.CollUtils;
import lombok.extern.slf4j.Slf4j;
import org.springframework.cloud.openfeign.FallbackFactory;
import java.util.Collection;
import java.util.List;
@Slf4j
public class ItemClientFallback implements FallbackFactory<ItemClient> {
@Override
public ItemClient create(Throwable cause) {
return new ItemClient() {
@Override
public List<ItemDTO> queryItemByIds(Collection<Long> ids) {
log.error("远程调用ItemClient#queryItemByIds方法出现异常,参数:{}", ids, cause);
// 查询购物车允许失败,查询失败,返回空集合
return CollUtils.emptyList();
}
@Override
public void deductStock(List<OrderDetailDTO> items) {
// 库存扣减业务需要触发事务回滚,查询失败,抛出异常
throw new BizIllegalException(cause);
}
};
}
}
实现接口
implements FallbackFactory<ItemClient>:这个类实现了FallbackFactory<ItemClient>接口。FallbackFactory是一个用于创建服务降级逻辑的工厂接口,当远程调用失败时,使用这个工厂创建一个降级的客户端实例。
方法 create
public ItemClient create(Throwable cause):这个方法用于创建一个ItemClient的降级实例。当远程调用失败时,会调用这个方法,并传递异常cause。降级逻辑在这个方法中定义。
内部匿名类 ItemClient
return new ItemClient():返回一个匿名实现了ItemClient接口的类。这个匿名类中实现了ItemClient接口的方法,并定义了具体的降级逻辑。
方法 queryItemByIds
-
public List<ItemDTO> queryItemByIds(Collection<Long> ids)这是ItemClient接口中的方法之一。降级逻辑记录一条错误日志并返回一个空的集合。由于查询购物车的操作允许失败,因此降级时返回空集合,而不是抛出异常。log.error("远程调用ItemClient#queryItemByIds方法出现异常,参数:{}", ids, cause); return CollUtils.emptyList();
方法 deductStock
-
public void deductStock(List<OrderDetailDTO> items)这是ItemClient接口中的另一个方法。降级逻辑记录错误日志后抛出一个自定义异常BizIllegalException。库存扣减是一个重要的业务操作,需要确保事务一致性,因此如果调用失败,必须触发事务回滚,所以这里直接抛出异常。throw new BizIllegalException(cause);
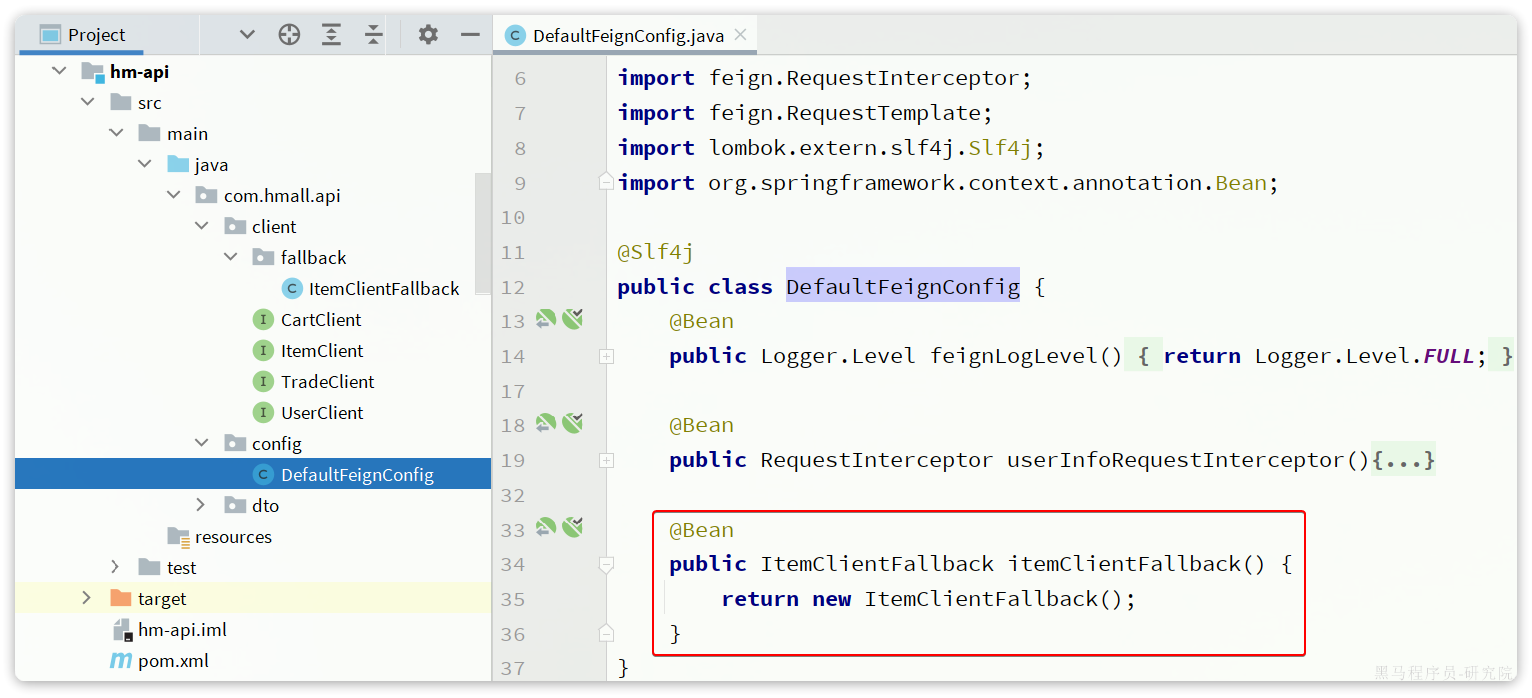
步骤二:在hm-api模块中的com.hmall.api.config.DefaultFeignConfig类中将ItemClientFallback注册为一个Bean:
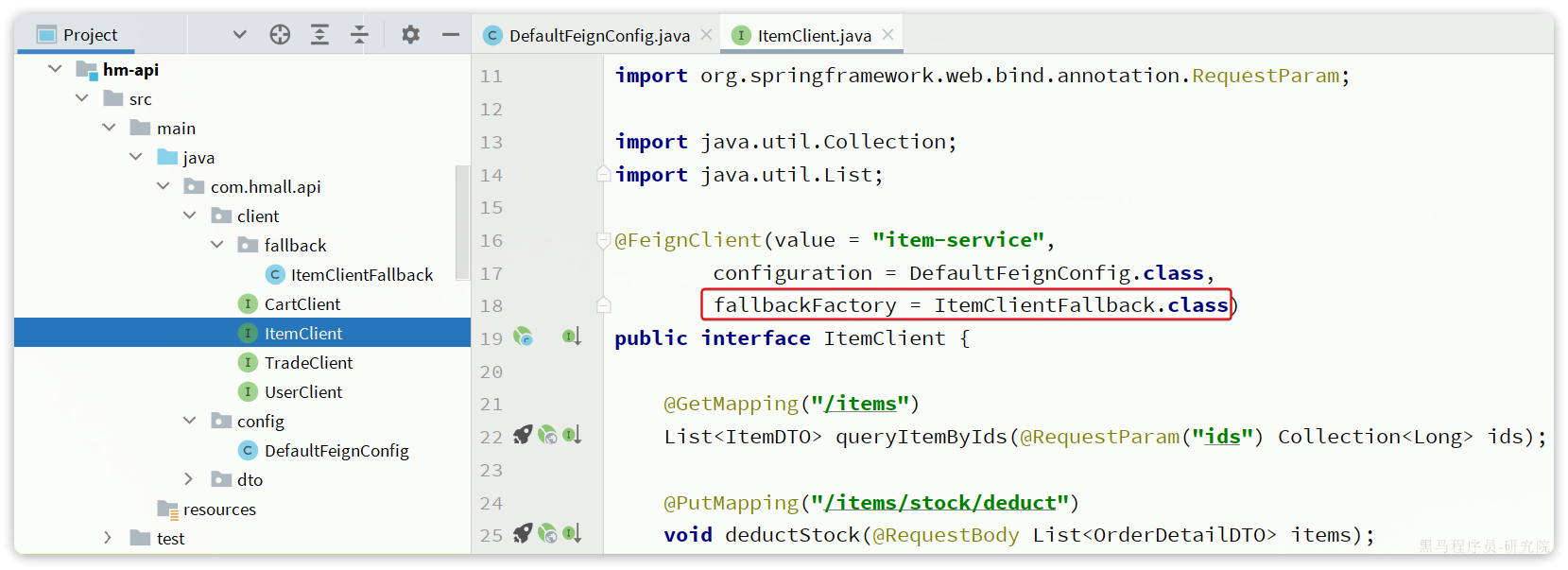
步骤三:在hm-api模块中的ItemClient接口中使用ItemClientFallbackFactory:
重启后,再次测试,发现被限流的请求不再报错,走了降级逻辑:
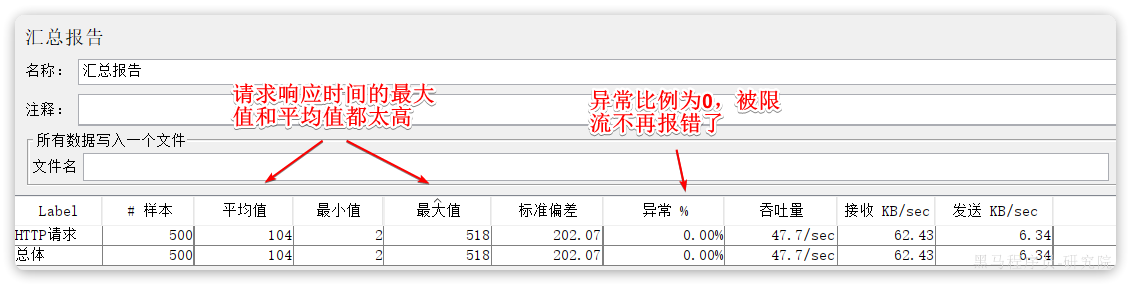
但是未被限流的请求延时依然很高:
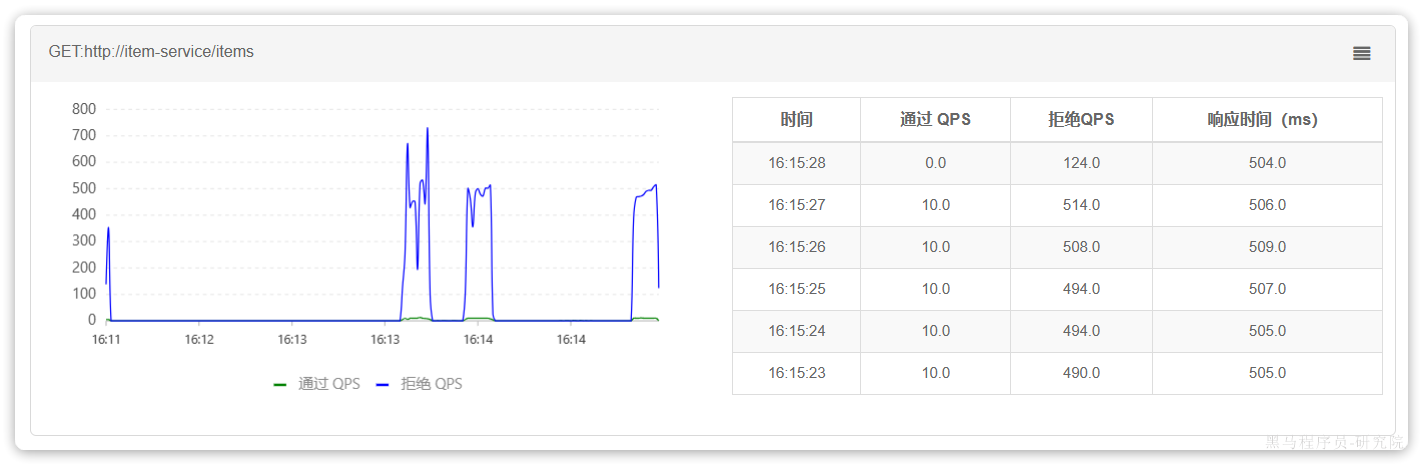
导致最终的平局响应时间较长。
总结,这里模拟的是cart-service调用item-service失败,因此配置的降级处理是Item-service,但是因为cart-service调用,所以流簇监控开启要开启到cart上。
此时可以看到http请求全部正确,只是有的数据为null而已。
服务熔断:
查询商品的RT较高(模拟的500ms),从而导致查询购物车的RT也变的很长。这样不仅拖慢了购物车服务,消耗了购物车服务的更多资源,而且用户体验也很差。
对于商品服务这种不太健康的接口,我们应该停止调用,直接走降级逻辑,避免影响到当前服务。也就是将商品查询接口熔断。当商品服务接口恢复正常后,再允许调用。这其实就是断路器的工作模式了。
Sentinel中的断路器不仅可以统计某个接口的慢请求比例,还可以统计异常请求比例。当这些比例超出阈值时,就会熔断该接口,即拦截访问该接口的一切请求,降级处理;当该接口恢复正常时,再放行对于该接口的请求。
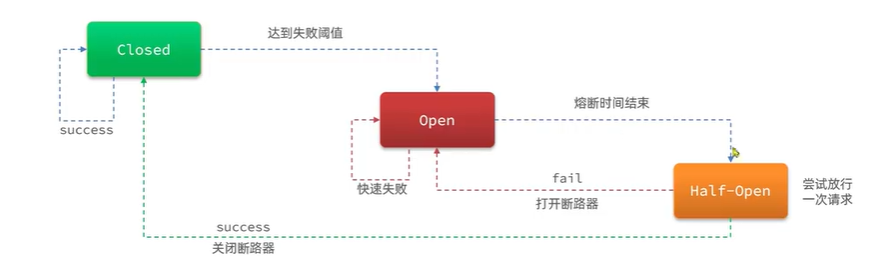
断路器的工作状态切换有一个状态机来控制:
状态机包括三个状态:
- closed:关闭状态,断路器放行所有请求,并开始统计异常比例、慢请求比例。超过阈值则切换到open状态
- open:打开状态,服务调用被熔断,访问被熔断服务的请求会被拒绝,快速失败,直接走降级逻辑。Open状态持续一段时间后会进入half-open状态
- half-open:半开状态,放行一次请求,根据执行结果来判断接下来的操作。
- 请求成功:则切换到closed状态
- 请求失败:则切换到open状态
我们可以在控制台通过点击簇点后的**熔断**按钮来配置熔断策略:
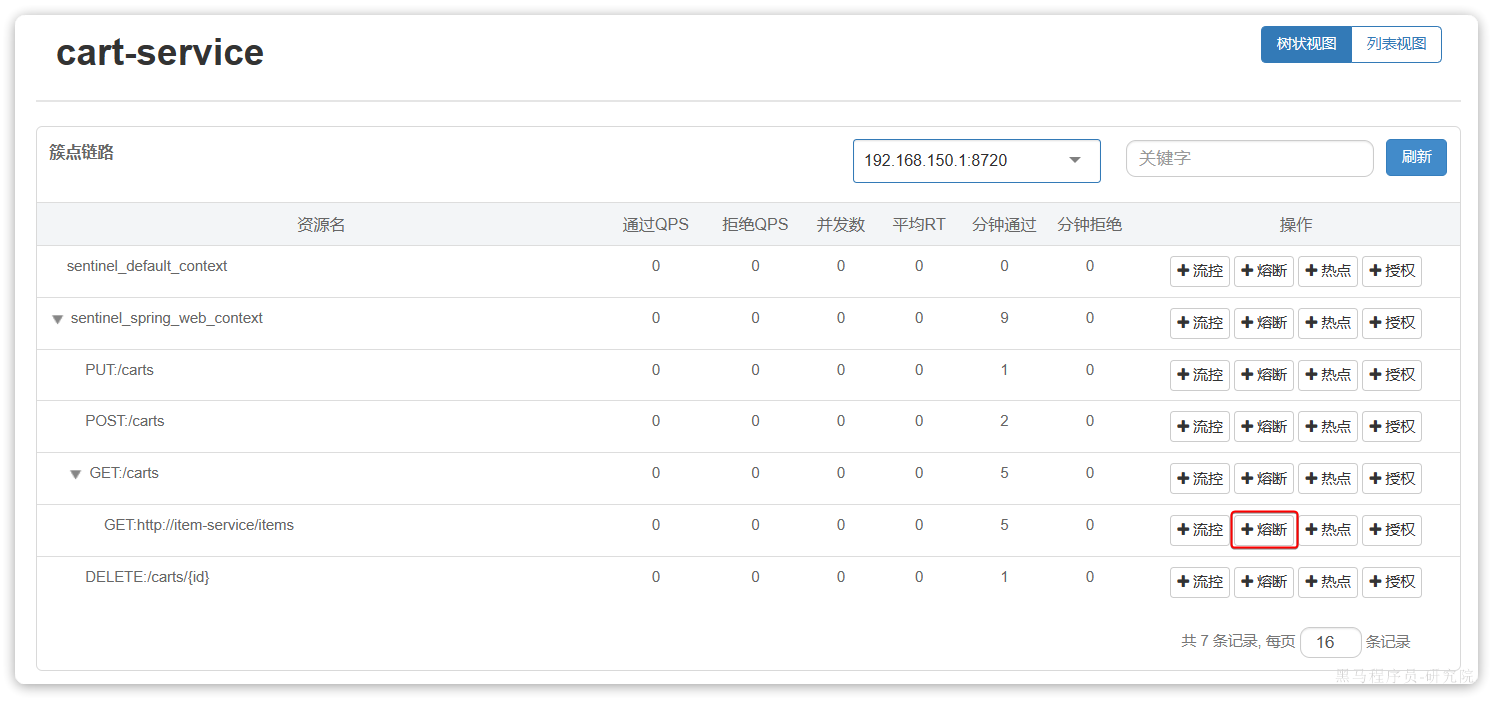
在弹出的表格中这样填写:
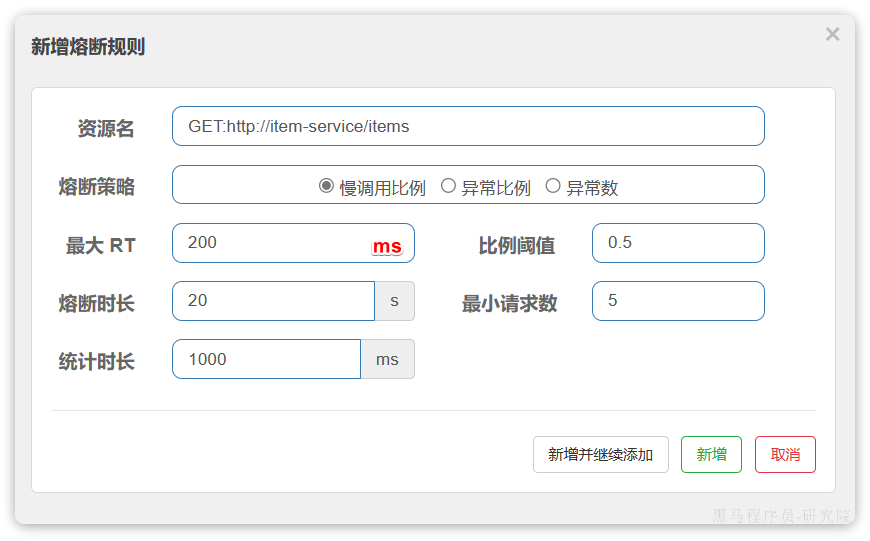
这种是按照慢调用比例来做熔断,上述配置的含义是:
- RT超过200毫秒的请求调用就是慢调用
- 统计最近1000ms内的最少5次请求,如果慢调用比例不低于0.5,则触发熔断
- 熔断持续时长20s
配置完成后,再次利用Jemeter测试,可以发现:
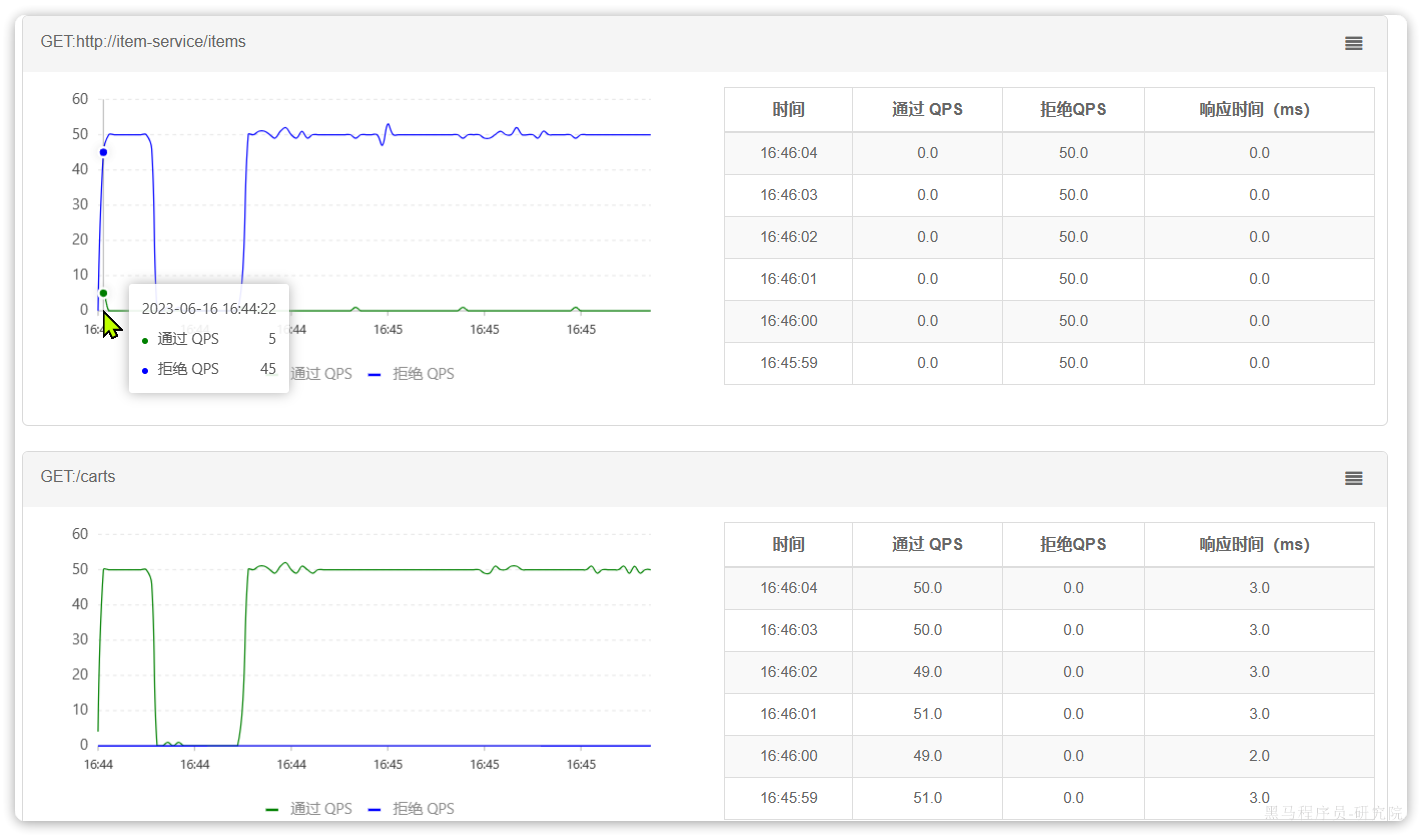
在一开始一段时间是允许访问的,后来触发熔断后,查询商品服务的接口通过QPS直接为0,所有请求都被熔断了。而查询购物车的本身并没有受到影响。
此时整个购物车查询服务的平均RT影响不大:

6.3.分布式事务:
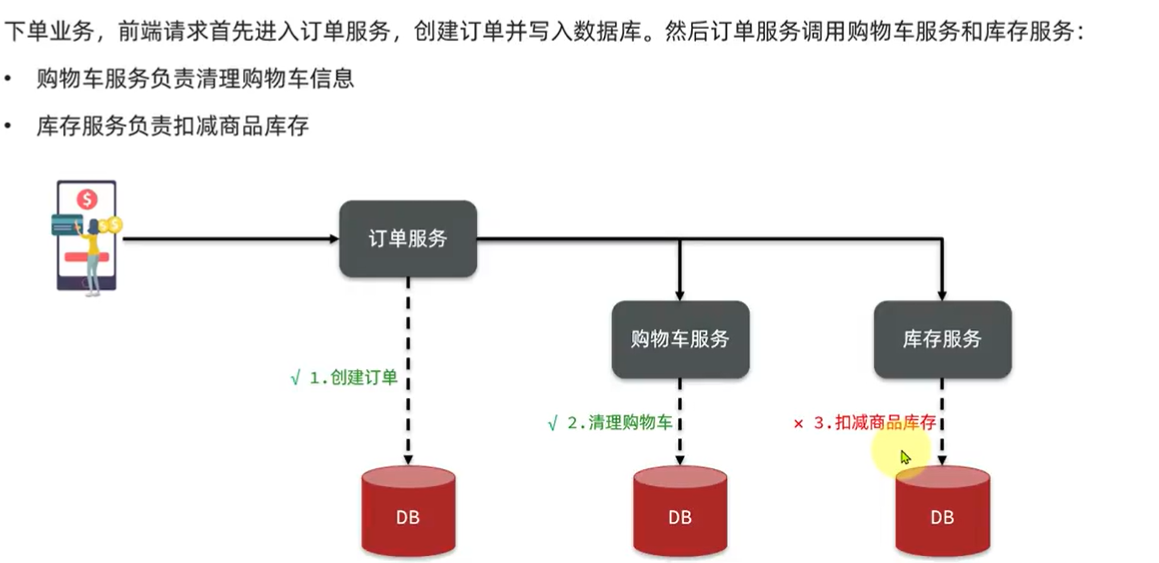
此时就会破坏acid的特性。
补充:原子性(atomicity,或称不可分割性)、一致性(consistency)、隔离性(isolation,又称独立性)、持久性(durability)。
6.3.1.认识Seata:
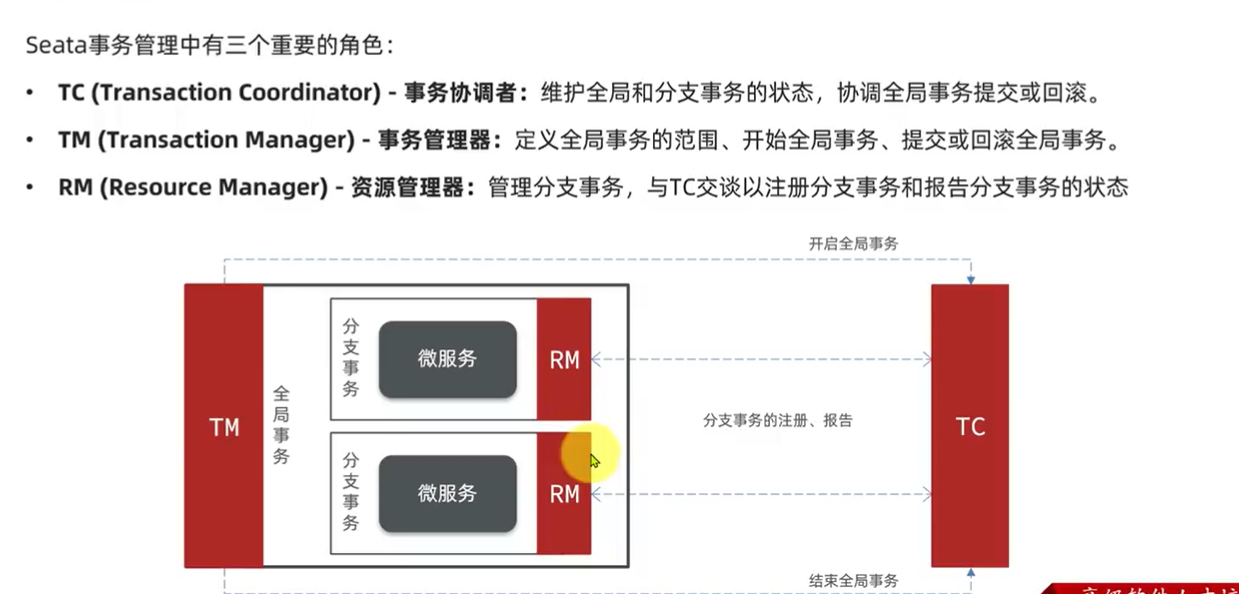
6.3.2.XA模式:
Seata支持四种不同的分布式事务解决方案:
- XA
- TCC
- AT
- SAGA
这里我们以XA模式和AT模式来给大家讲解其实现原理。
XA 规范 是 X/Open 组织定义的分布式事务处理(DTP,Distributed Transaction Processing)标准,XA 规范 描述了全局的TM与局部的RM之间的接口,几乎所有主流的数据库都对 XA 规范 提供了支持。
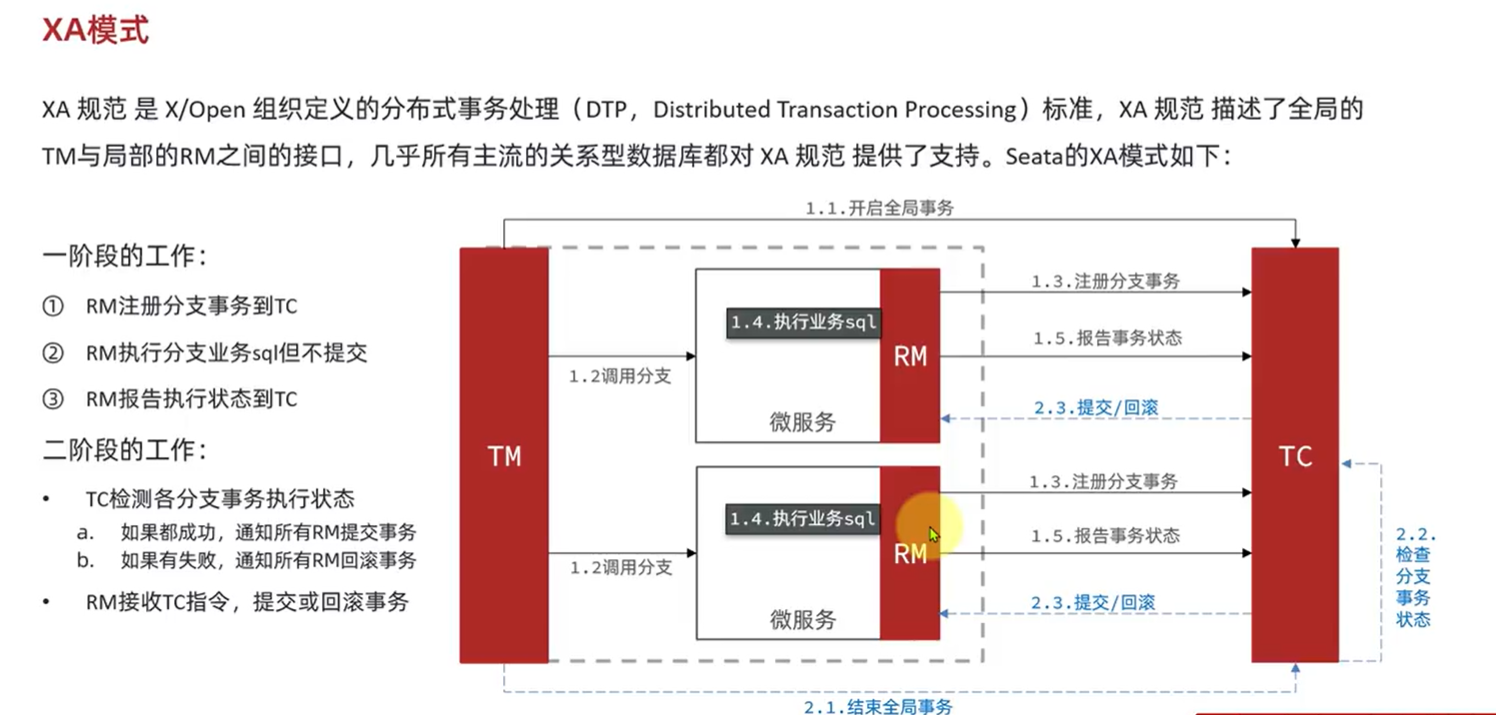
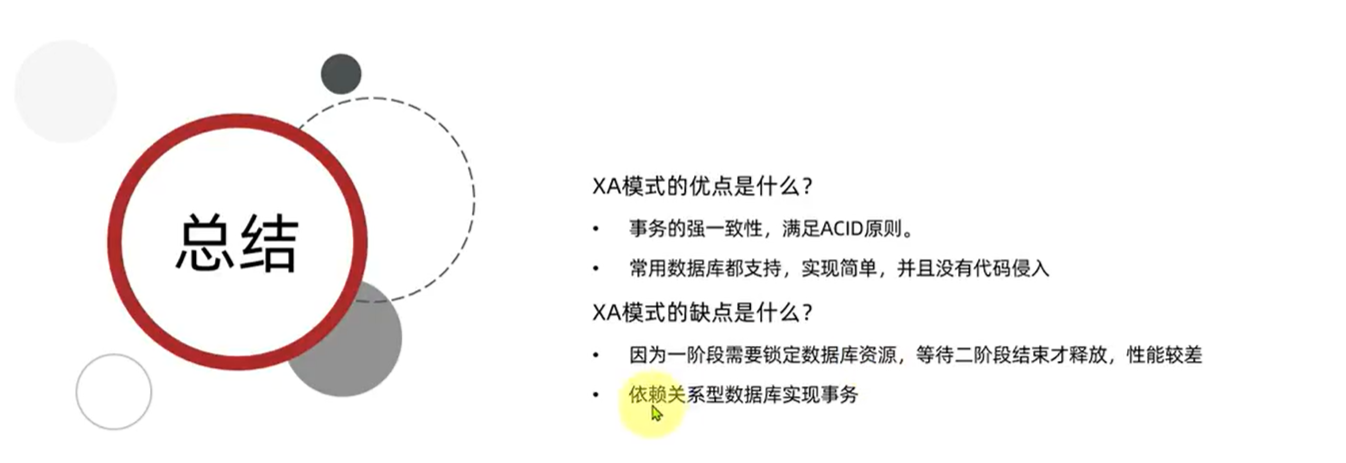
首先,我们要在配置文件中指定要采用的分布式事务模式。我们可以在Nacos中的共享shared-seata.yaml配置文件中设置:
seata:
data-source-proxy-mode: XA
其次,我们要利用@GlobalTransactional标记分布式事务的入口方法:
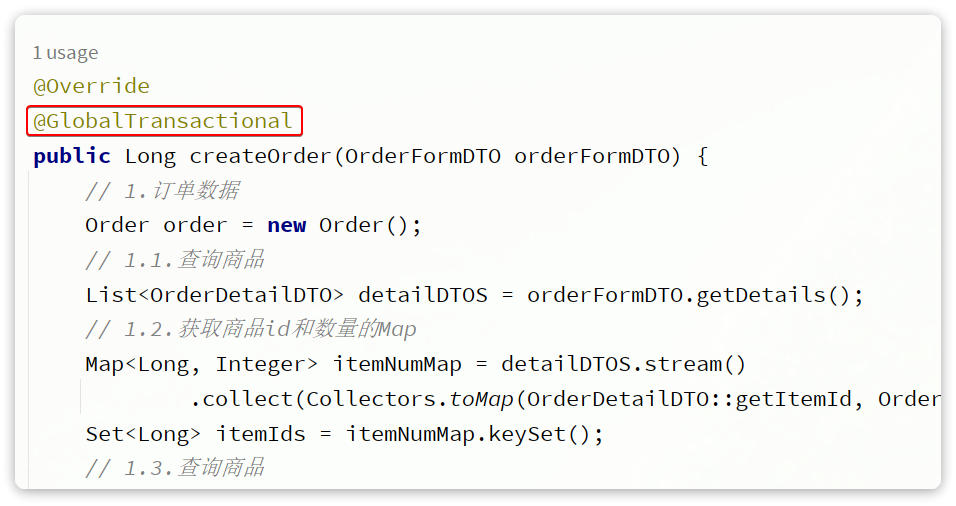
当然,还要在小的事务上面加上@Transactional注解。
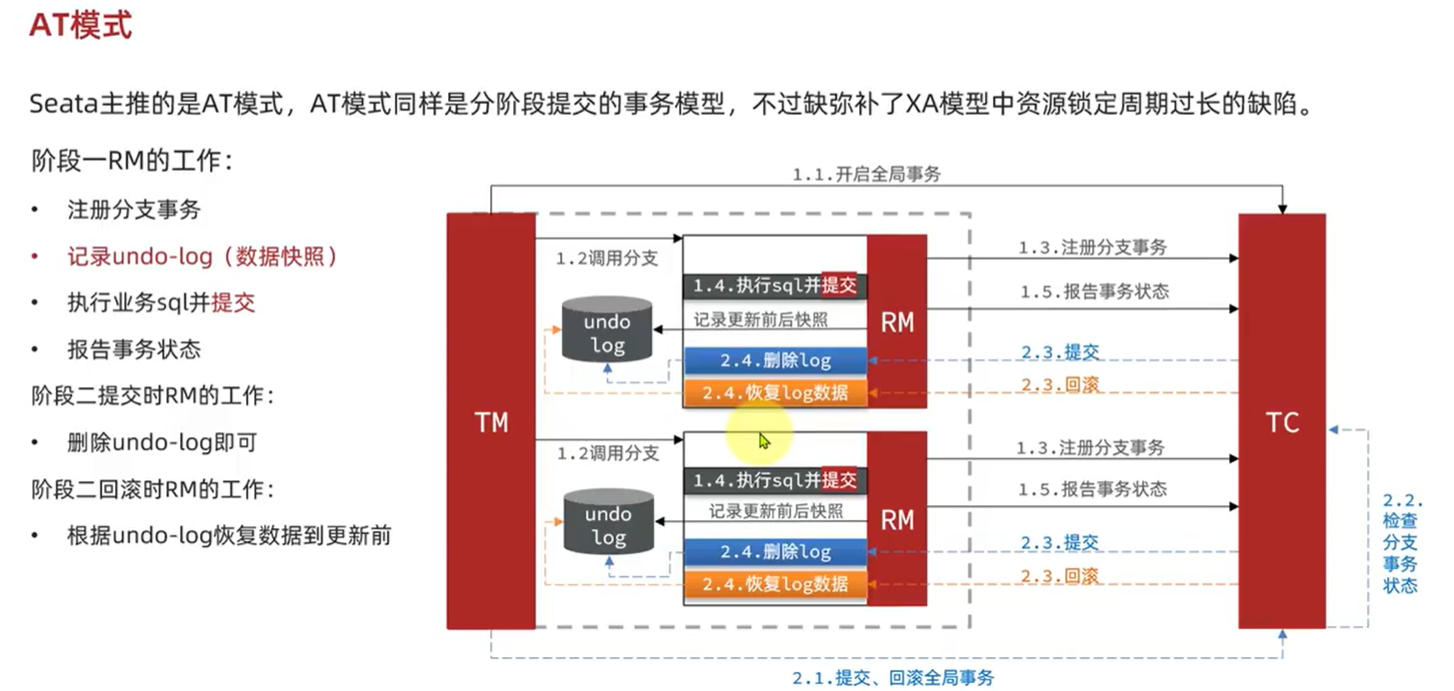
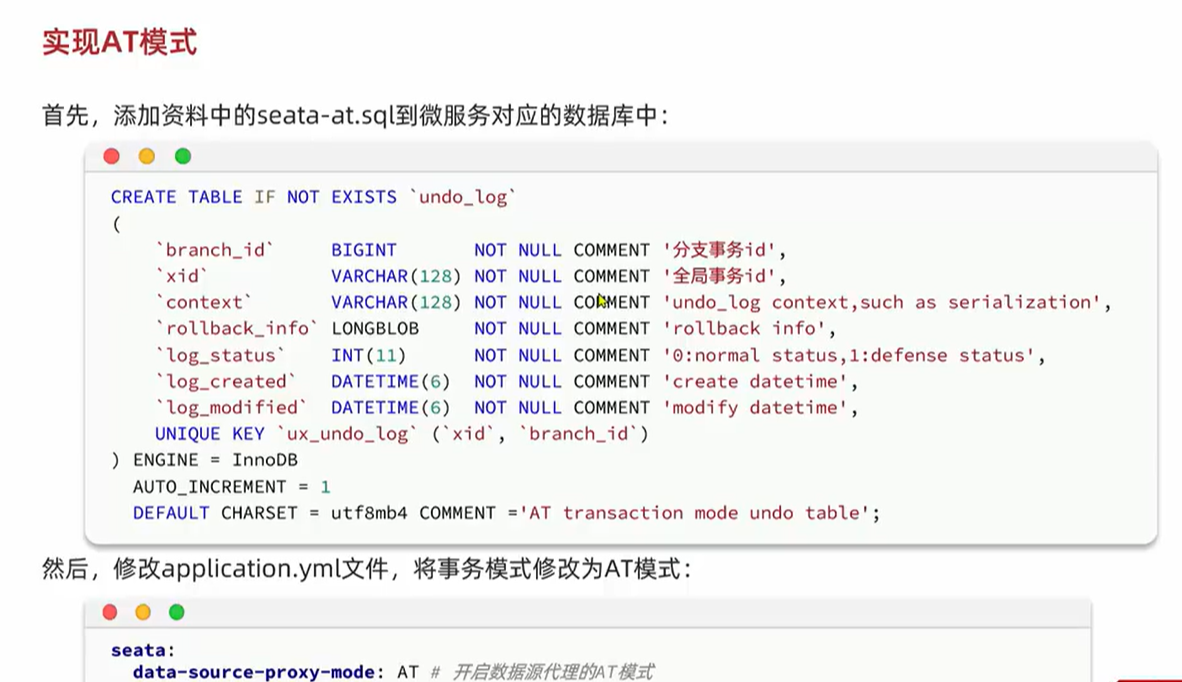
6.3.2.AT模式:
AT模式同样是分阶段提交的事务模型,不过缺弥补了XA模型中资源锁定周期过长的缺陷。



















 167万+
167万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











