







YOLOv3讲解
一、YOLOv3 核心架构与创新
YOLOv3(2018年发布)在YOLOv2基础上进行了全面升级,通过多尺度预测、更强大的骨干网络和优化的分类损失函数,显著提升了检测精度,尤其是小目标检测能力,同时保持了实时性能。
二、YOLOv3 网络结构详解
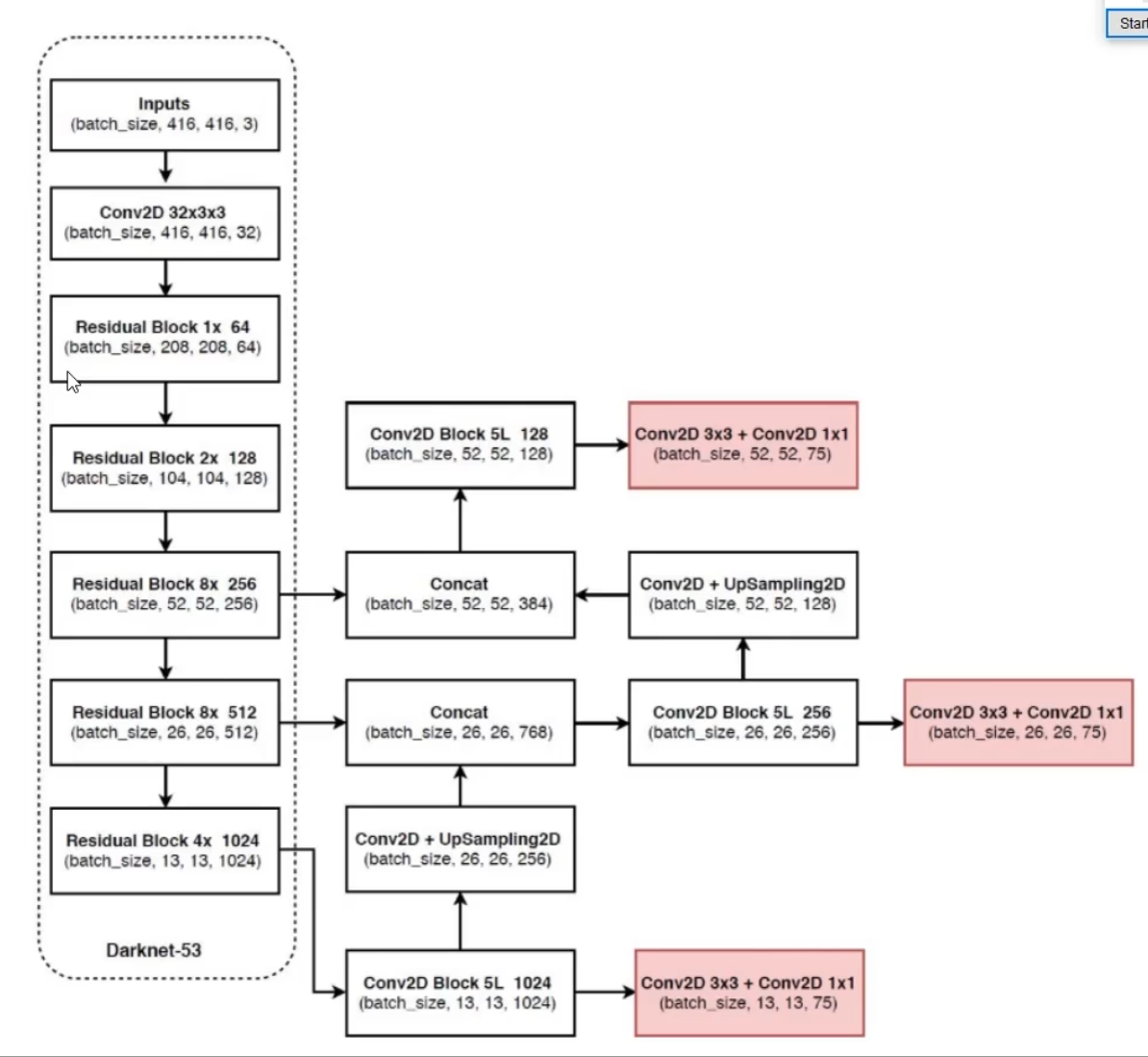
1. 骨干网络:Darknet-53
- 设计目标:
结合ResNet的残差结构与YOLOv2的Darknet-19,在保证计算效率的同时增强特征提取能力。 - 结构特点:
-
包含53个卷积层,引入残差块(Residual Block)(如
1×1和3×3卷积堆叠后跨层连接),缓解梯度消失问题。
-
仅使用
1×1和3×3卷积核,简化网络设计。 -
移除全连接层,采用全局平均池化进行分类(仅用于预训练)。
-
- 优势:
- 比Darknet-19更深,特征表达能力更强,同时参数量少于ResNet-101/152。
- 在ImageNet上达到82.7%的top-5准确率,速度比ResNet快。
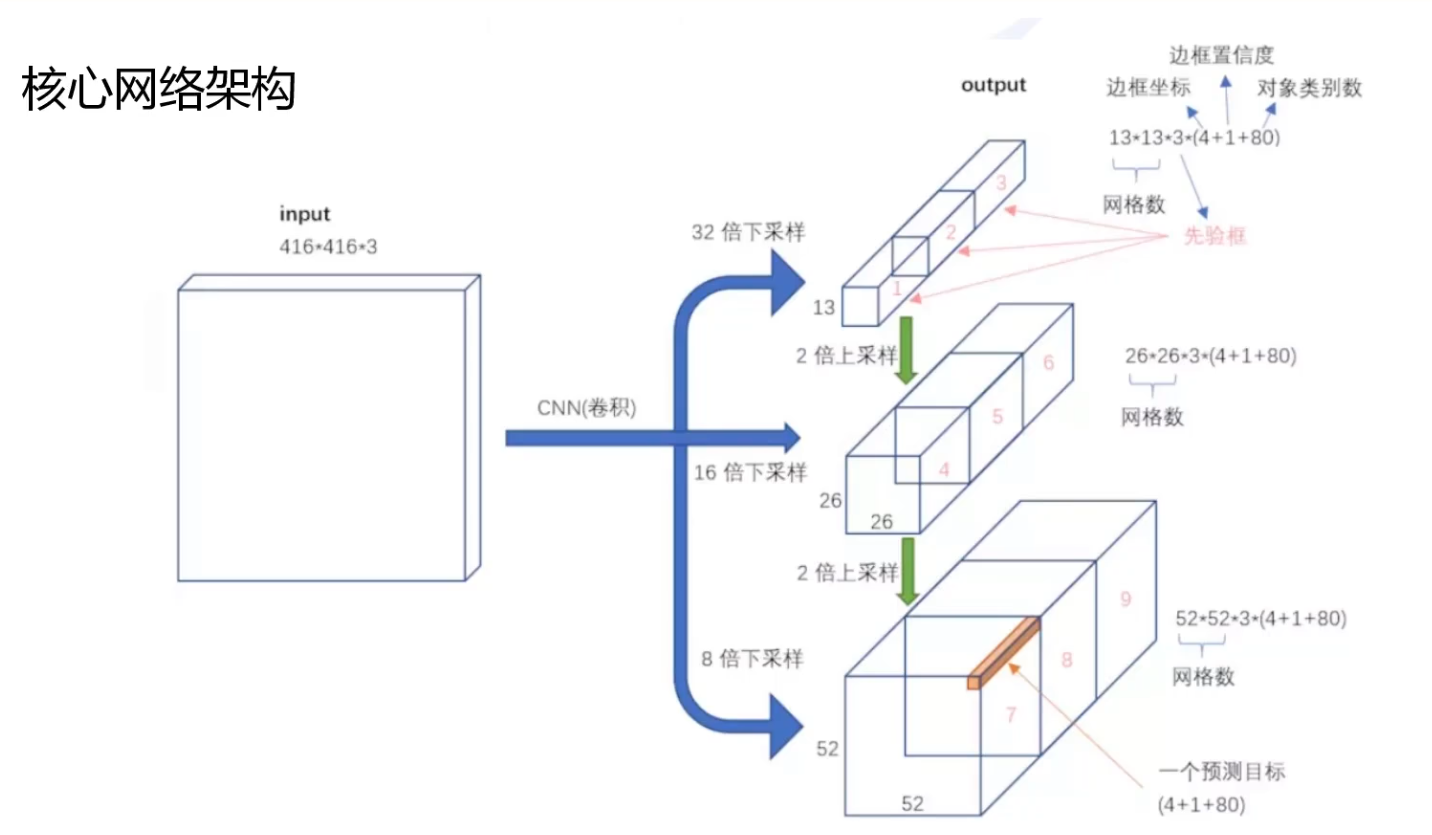
2. 多尺度预测(FPN结构)
-
YOLOv2问题:
仅依赖单一尺度(13×13)或融合少量浅层特征,对小目标检测能力有限。 -
YOLOv3改进:
-
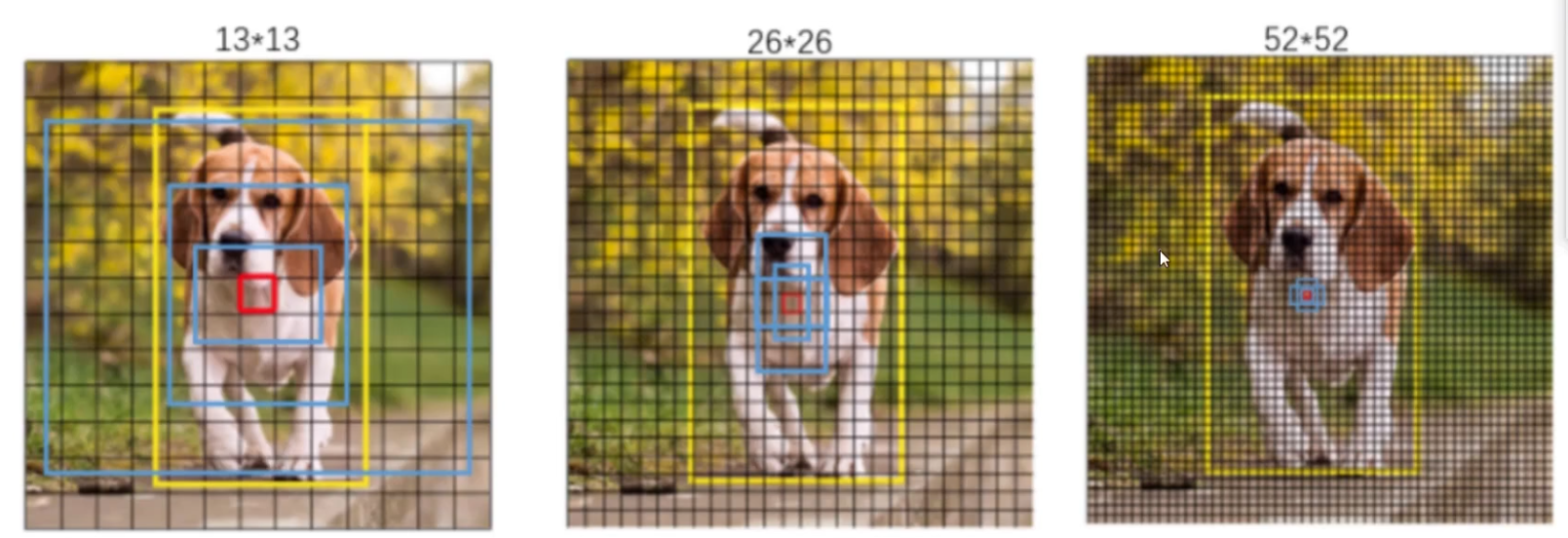
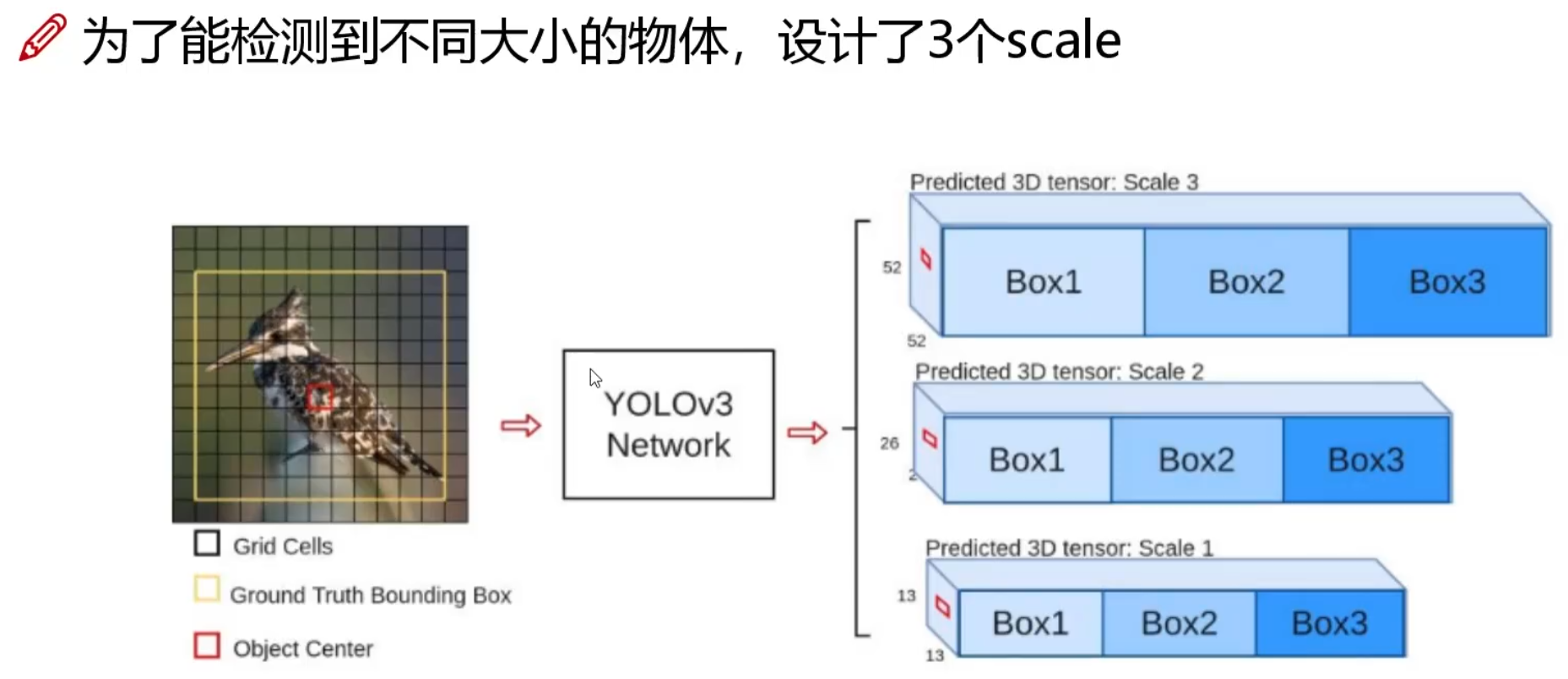
采用特征金字塔网络(FPN),在三个不同尺度上预测边界框:
- 大目标:13×13特征图(下采样32倍),感受野最大。
- 中等目标:26×26特征图(下采样16倍),融合前层特征。
- 小目标:52×52特征图(下采样8倍),保留细粒度信息。
-
每个尺度使用3种锚框(共9种,通过K-means聚类生成),例如:
13×13: 大锚框 (116×90, 156×198, 373×326) 26×26: 中锚框 (30×61, 62×45, 59×119) 52×52: 小锚框 (10×13, 16×30, 33×23)
-
-
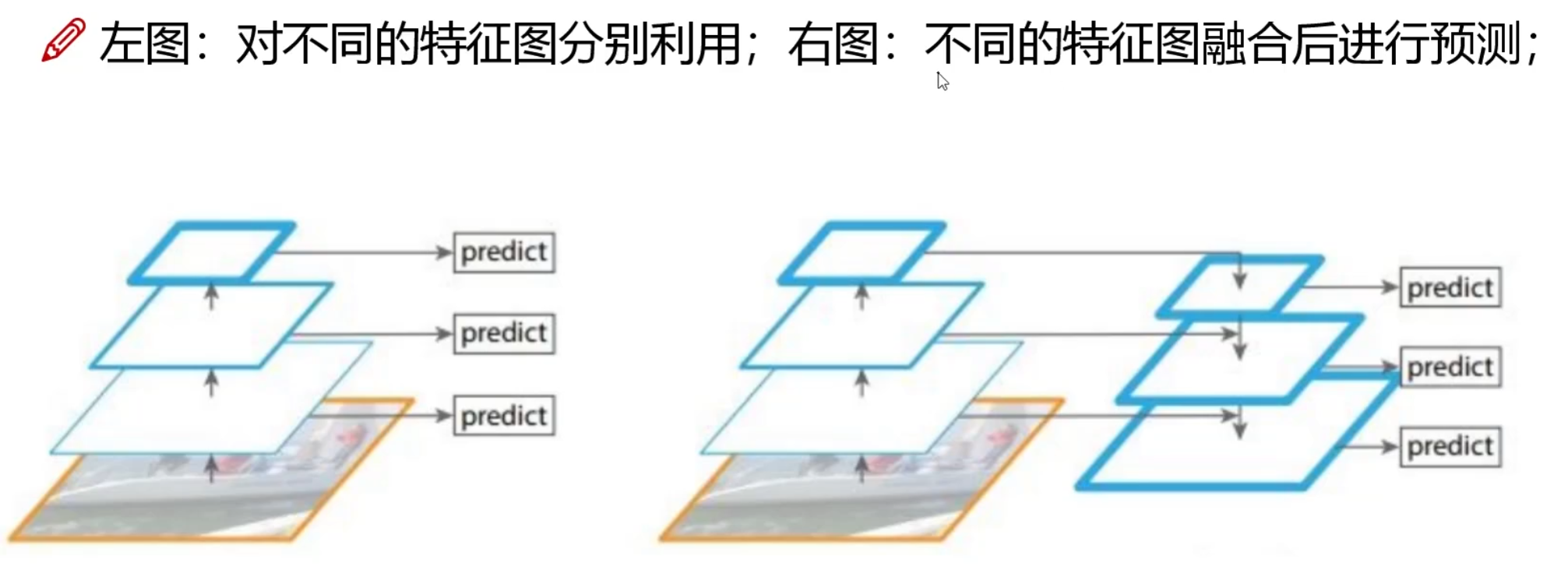
特征融合方式:
通过上采样(UpSampling)和跳跃连接(Skip Connection),将深层语义信息与浅层空间信息结合。例如,将13×13特征图上采样后与26×26特征图拼接,再用于预测。
3. 边界框预测机制
-
与YOLOv2的延续:
仍使用锚框机制,通过逻辑回归预测边界框中心偏移量 ( t x , t y ) (t_x, t_y) (tx,ty)、宽高缩放 ( t w , t h ) (t_w, t_h) (tw,th) 和置信度 t o t_o to,公式与YOLOv2一致:

-
改进点:
- 每个尺度的每个网格预测3个边界框(YOLOv2为5个),但通过多尺度融合,总锚框数量更多(3×3=9种 vs. YOLOv2的5种)。
- 引入逻辑回归(Logistic Regression)对每个锚框进行二分类,判断是否包含目标,替代YOLOv2的单一置信度预测。
4. 分类损失函数改进
- YOLOv2的问题:
使用Softmax多分类,假设类别互斥(如“狗”和“猫”不能同时存在),不适用于多标签场景。 - YOLOv3改进:
-
采用独立的二元逻辑分类器(Binary Logistic Classifier),每个类别使用单独的sigmoid函数进行预测,允许目标具有多个标签(如“人”和“骑车的人”)。
-
损失函数为二元交叉熵(Binary Cross-Entropy):
L c l a s s = − ∑ c ∈ c l a s s e s [ p ( c ) log ( p ^ ( c ) ) + ( 1 − p ( c ) ) log ( 1 − p ^ ( c ) ) ] L_{class} = -\sum_{c \in classes} \left[ p(c) \log(\hat{p}(c)) + (1-p(c)) \log(1-\hat{p}(c)) \right] Lclass=−∑c∈classes[p(c)log(p^(c))+(1−p(c))log(1−p^(c))]
-
- 优势:
- 更适合多标签任务(如COCO数据集)。
- 对长尾分布的类别更鲁棒(避免Softmax的类别竞争问题)。
5. 正负样本分配策略
- YOLOv2的启发式分配:
每个网格仅负责一个目标,IOU最大的锚框为正样本,其他为负样本。 - YOLOv3改进:
- 若一个真实框与某个锚框的IOU超过阈值(如0.5),则该锚框为正样本,允许一个目标由多个锚框负责。
- 忽略IOU介于阈值之间的锚框(不计算分类和定位损失),减少模糊样本的干扰。
6. 训练策略优化
- 预训练:
在ImageNet上使用1000类进行分类预训练,然后微调检测任务。 - 数据增强:
继承YOLOv2的多尺度训练(输入尺寸随机调整),并增加MixUp和CutMix等增强方法,提升模型鲁棒性。 - 学习率调度:
使用余弦退火(Cosine Annealing)动态调整学习率,加速收敛。
三、YOLOv3 对比 YOLOv2 的核心改进
| 改进点 | YOLOv2 | YOLOv3 | 效果/原因 |
|---|---|---|---|
| 骨干网络 | Darknet-19(19卷积层+BN) | Darknet-53(53卷积层+残差结构) | 更深的网络+残差块提升特征表达能力,ImageNet top-5准确率从76.5%→82.7%,参数量更少。 |
| 多尺度预测 | 单尺度(13×13)或融合少量浅层特征 | 三尺度预测(13×13、26×26、52×52) | 小目标检测mAP提升约10%,对不同尺度目标更鲁棒。 |
| 锚框机制 | 5种锚框(全局共享) | 9种锚框(3个尺度各3种) | 更细粒度的锚框设计,覆盖更广的尺度范围,召回率提升。 |
| 分类损失函数 | Softmax多分类(类别互斥) | 二元逻辑分类器(多标签独立预测) | 支持多标签任务,对非互斥类别更友好,如COCO数据集中的“人”和“骑车的人”。 |
| 特征融合 | Passthrough层(简单通道叠加) | FPN结构(上采样+跳跃连接) | 更复杂的特征金字塔,有效融合深层语义与浅层细节。 |
| 正负样本分配 | 启发式分配(IOU最大的锚框为正样本) | 基于IOU阈值(>0.5为正,<阈值忽略) | 减少模糊样本干扰,优化训练稳定性。 |
| 小目标检测 | 较弱(依赖单一尺度) | 显著提升(52×52特征图专门检测小目标) | 在COCO数据集上,小目标AP从10%→19%。 |
| 训练策略 | 多尺度训练(320×320~608×608) | 多尺度+MixUp/CutMix数据增强 | 增强模型对数据扰动的鲁棒性,提升泛化能力。 |
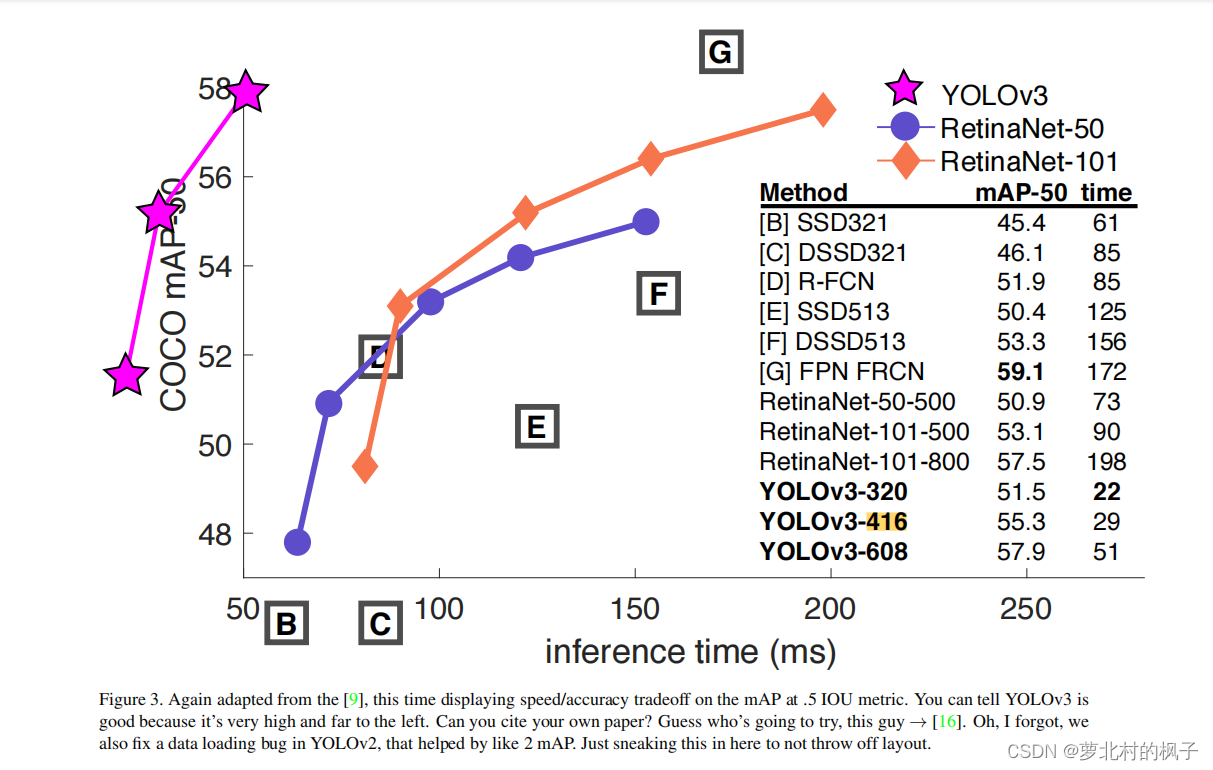
| 检测精度(COCO mAP) | 约57.9%(YOLO9000) | 约57.9%(相同参数量下),但APS更高 | 在相同参数量下保持精度,小目标检测能力更强。 |
| 速度与精度平衡 | FPS≈67(416×416) | FPS≈32(416×416) | 速度略有下降(因多尺度预测),但精度提升显著,尤其在小目标和多标签场景。 |
四、YOLOv3 性能总结
- 精度:
- 在COCO数据集上,YOLOv3达到57.9%的mAP(与YOLOv2相近),但小目标AP从10%提升至19%。
- 在VOC数据集上,mAP@0.5达到87%,接近SSD和Faster R-CNN的水平。
- 速度:
- 在Titan X上,输入416×416时FPS约32,仍保持实时性。
- 优势:
- 多尺度设计使其在不同尺寸目标上均有良好表现。
- 多标签分类更符合实际应用需求(如监控场景中的多属性识别)。
- 模型架构灵活性:可通过调整输入尺寸平衡速度与精度(如输入320×320时FPS达91)。
五、YOLOv3 的局限性
- 精度瓶颈:
单阶段检测器在小目标和密集目标检测上仍落后于两阶段方法(如FPN+Mask R-CNN)。 - 损失函数设计:
定位损失仍使用简单的均方误差,未考虑IOU/GIOU等更先进的度量(后续YOLOv4引入CIOU损失)。 - 后处理依赖:
仍需NMS进行后处理,对密集重叠目标处理效果有限(后续YOLOv5引入Soft-NMS和IoU-aware机制)。
总结
YOLOv3通过多尺度预测、二元逻辑分类器和更强大的骨干网络,显著提升了小目标检测能力和多标签分类性能,同时保持了YOLO系列的实时性优势。其设计思想(如特征金字塔、多标签分类)成为后续目标检测模型的标配,为YOLOv4、v5等版本奠定了基础。
残差连接(Residual Connection)
一、核心概念与起源
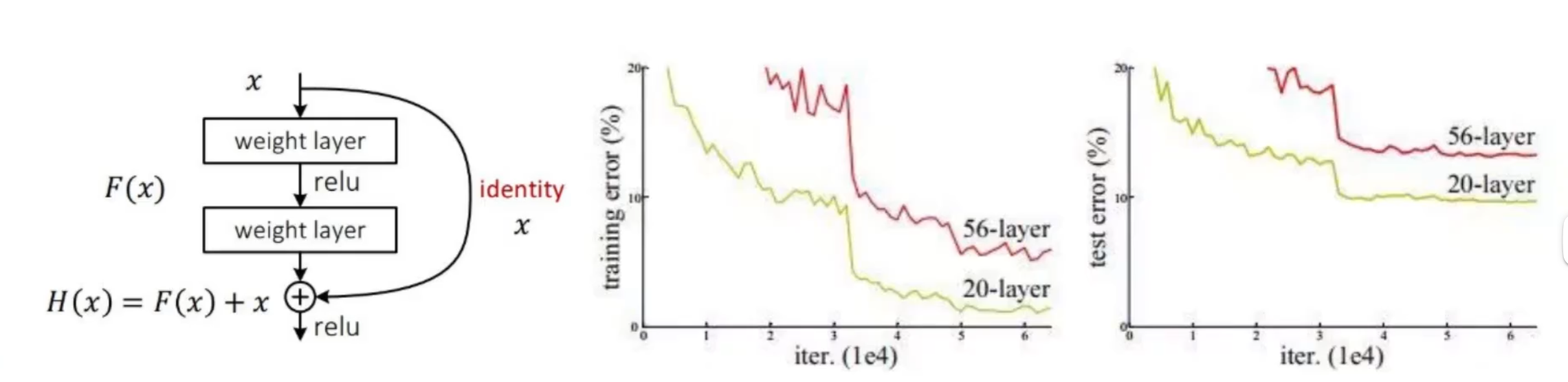
残差连接(Residual Connection)是一种跨层跳跃连接技术,其核心思想是让输入信号绕过一个或多个网络层,直接与输出相加,形成残差学习的路径。该技术由何恺明团队于2015年在ResNet中首次提出,旨在解决深层网络训练中的梯度消失和网络退化问题。
核心公式:
假设某层的输入为 ( x ),经过非线性变换后的输出为 ( F(x) ),则残差连接的输出为:
H
(
x
)
=
F
(
x
)
+
x
H(x) = F(x) + x
H(x)=F(x)+x
其中 ( F(x) ) 称为残差映射,表示输入 ( x ) 与输出 ( H(x) ) 之间的差异。网络只需学习残差 ( F(x) = H(x) - x ),而非直接学习复杂的 ( H(x) ),从而显著降低训练难度。
二、残差连接的核心作用
-
缓解梯度消失
传统深层网络中,梯度通过链式法则逐层传递时易因连乘效应衰减至零。残差连接通过捷径路径(Shortcut Connection)为梯度提供直接回传通道,使得底层网络层仍能获得足够梯度更新。数学上,反向传播时梯度为:∂ Loss ∂ x = ∂ Loss ∂ H ( x ) ⋅ ( ∂ F ( x ) ∂ x + 1 ) \frac{\partial \text{Loss}}{\partial x} = \frac{\partial \text{Loss}}{\partial H(x)} \cdot \left( \frac{\partial F(x)}{\partial x} + 1 \right) ∂x∂Loss=∂H(x)∂Loss⋅(∂x∂F(x)+1)
即使 ∂ F ( x ) ∂ x \frac{\partial F(x)}{\partial x} ∂x∂F(x) 很小,恒等项 ( 1 ) 仍能保证梯度有效传递。 -
信息保留与复用
残差连接允许输入 ( x ) 直接参与输出计算,避免深层网络因多层变换导致的信息丢失。例如,在YOLOv3的Darknet-53中,浅层的边缘信息通过残差连接与深层语义特征融合,提升小目标检测能力。 -
支持更深的网络结构
ResNet通过残差连接训练出152层的网络,而传统网络在30层后即出现性能退化。残差连接使网络深度增加时仍能保持训练稳定性和准确率。
三、残差块(Residual Block)的结构设计
残差块是残差连接的具体实现单元,通常包含以下组件:
-
基础残差块(Basic Block)
- 结构:两个3×3卷积层,中间插入BN和激活函数(如ReLU),输入 ( x ) 通过捷径连接直接与输出相加。
- 应用场景:ResNet-18/34等较浅网络。
-
瓶颈残差块(Bottleneck Block)
- 结构:1×1卷积(降维)→ 3×3卷积(特征提取)→ 1×1卷积(升维),输入 ( x ) 与输出相加。
- 优势:通过降维减少计算量,适用于ResNet-50/101/152等深层网络。
-
Darknet-53中的残差块
- 结构:1×1卷积(降维)→ 3×3卷积(升维),输入与输出相加。
- 作用:在YOLOv3中构建53层Darknet-53网络,通过23个残差块提升特征提取能力,同时保持实时性。
四、残差连接的关键技术细节
-
维度匹配
捷径连接要求输入 ( x ) 与输出 ( F(x) ) 的维度一致。若维度不同,需通过以下方式调整:- 1×1卷积:调整通道数(如ResNet中的维度匹配)。
- 零填充:保持空间尺寸一致(如YOLOv3中部分残差块)。
-
激活函数选择
- ReLU:在残差块内部使用,增加非线性表达能力。
- 无激活函数:残差加法后不使用激活函数,避免破坏残差学习的特性。
-
与归一化层的结合
- Post-Norm:残差加法后进行层归一化(Layer Normalization),如原始Transformer架构。
- Pre-Norm:归一化层置于子层前,缓解深层网络梯度消失问题,成为现代Transformer的主流选择(如GPT-3)。
五、残差连接在YOLOv3中的具体应用
-
主干网络Darknet-53
- 结构:53层卷积网络,包含23个残差块,每个残差块由1×1和3×3卷积组成。
- 作用:
- 残差连接允许网络加深至53层,提升特征提取能力(ImageNet Top-1准确率77.2%)。
- 全卷积结构支持任意尺寸输入,输出3个尺度特征图(13×13、26×26、52×52),用于多尺度检测。
-
多尺度特征融合
- 特征金字塔(FPN):通过上采样和残差连接融合浅层与深层特征。例如,13×13特征图经上采样后与26×26特征图拼接,增强小目标检测能力。
- 锚框分配:每个尺度检测头对应3个锚框(共9个),通过残差连接传递的特征更丰富,提升召回率。
-
训练策略
- 多尺度训练:输入尺寸动态调整为320×320至608×608,残差连接确保深层网络在不同尺度下仍能稳定训练。
- 标签平滑:对类别标签添加噪声(如0.1),缓解过拟合,残差连接的稳定性对此策略有辅助作用。(10%的标签会被随机修改)
六、残差连接的优势与局限性
-
优势
- 训练稳定性:解决深层网络梯度消失和退化问题,支持训练数百层的网络。
- 特征复用:保留输入信息,避免深层特征丢失,适用于小目标检测等复杂任务。
- 参数效率:残差块通过降维减少计算量,例如Darknet-53的参数量(61M)仅为ResNet-152(60M)的1.02倍,但速度更快。
-
局限性
- 计算量增加:残差连接引入额外的加法操作,可能略微增加推理时间。
- 结构复杂度:需精心设计残差块的维度匹配和连接方式,否则可能导致性能下降。
七、残差连接的扩展与变种
-
密集连接(DenseNet)
- 每个层与之前所有层直接相连,特征复用更彻底,但参数量较大。
-
分组残差(ResNeXt)
- 将卷积层分组,平衡计算量与特征多样性,提升模型效率。
-
动态残差(Dynamic Residual)
- 引入门控机制动态控制残差路径的权重,增强模型灵活性。
八、总结
残差连接是深度学习领域的革命性技术,其通过残差学习和捷径路径彻底改变了深层网络的训练范式。在YOLOv3中,残差连接与Darknet-53的结合不仅提升了特征提取能力,还通过多尺度检测和特征融合显著增强了小目标检测性能。尽管存在一定局限性,残差连接仍是现代神经网络(如Transformer、UNet)的核心组件,其思想为后续模型优化提供了重要启示。
我崇拜流浪、变化和幻想,不愿将我的爱钉在地球某处。 —赫尔曼·黑塞



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









