






目录
10.使用键值对 RDD 的 keys 和 values 方法
11.使用键值对 RDD 的 reduceByKey ()方法
12.使用键值对 RDD 的 groupByKey ()方法
15.使用 combineByKey ()方法合并相同键的值
19.first()/head()/take()takeAsList(): 获取若干条记录
20.collec()lcollectAsList(): 获取所有数据
(4) selectExpr()方法:对指定字段进行特殊处理
1.使用map()方法转换数据
map ()方法是一种基础的 RDD 转换操作,可以对 RDD 中的每一个数据元素通过某种函数进行转换并返回新的 RDD 。 map ()方法是懒操作,不会立即进行计算。
转换操作是创建 RDD 的第二种方法,通过转换已有 RDD 生成新的 RDD 。因为 RDD 是一个不可变的集合,所以如果对 RDD 数据进行了某种转换,那么会生成一个新的 RDD 。例如,通过一个存放了5个 Int 类型的数据元素的列表创建一个 RDD ,可通过 map()方法对每一个元素进行平方运算,结果会生成一个新的 RDD,代码如下图所示

2.使用 sortBy ()方法进行排序
sortBy ()方法用于对标准 RDD 进行排序,有3个可输入参数,说明如下。
(1)第1个参数是一个函数 f :( T )=> K ,左边是要被排序对象中的每一个元素,右边返回的值是元素中要进行排序的值。
(2)第2个参数是 ascending ,决定排序后 RDD 中的元素是升序的还是降序的,默认是 true ,即升序排序,如果需要降序排序则需要将参数的值设置为 false 。
(3)第3个参数是 numPartitions ,决定排序后的 RDD 的分区个数,默认排序后的分区个数和排序之前的分区个数相等,即 this . partitions . size 。
第一个参数是必须输入的,而后面的两个参数可以不输入。例如,通过一个存放了3个二元组的列表创建一个 RDD ,对元组的第二个值进行降序排序,分区个数设置为1,代码如下图所示

3.使用 collect ()方法查询数据
collect ()方法是一种行动操作,可以将 RDD 中所有元素转换成数组并返回到 Driver 端,适用于返回处理后的少量数据。因为需要从集群各个节点收集数据到本地,经过网络传输,并且加载到 Driver 内存中,所以如果数据量比较大,会给网络传输造成很大的压力。因此,数据量较大时,尽量不使用 collect ()方法,否则可能导致 Driver 端出现内存溢出问题。 collect ()方法有以下两种操作方式。
(1) collect :直接调用 collect 返回该 RDD 中的所有元素,返回类型是一个 Array [ T ]数组,这是较为常用的一种方式。
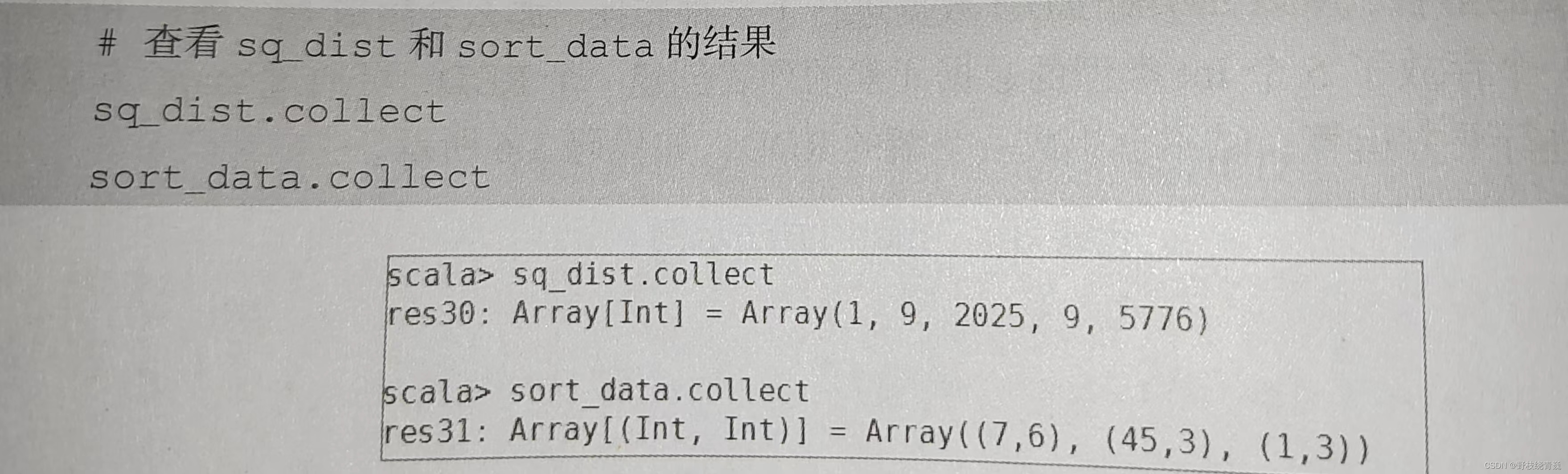
使用 collect ()方法查看 sq _ dist 和 sort _ data 的结果, 分别返回了经过平方运算后的 Int 类型的数组和对元组第二个值进行降序排列后的数组。
(2) collect [ U : ClassTag ]( f : PartialFunction [ T , U ]): RDD [ U ]。这种方式需要提供一个标准的偏函数,将元素保存至一个 RDD 中。首先定义一个函数 one ,用于将 collect 方法得到的数组中数值为1的值替换为" one ",将其他值替换为" other "。创建一个只有3个 Int 类型数据的 RDD ,在使用 collect ()方法时将 one 函数作为参数,代码如下图所示

4.使用 flatMap ()方法转换数据
flatMap ()方法将函数参数应用于 RDD 之中的每一个元素,将返回的迭代器(如数组、列表等)中的所有元素构成新的 RDD 。使用 flatMap ()方法时先进行 map (映射)再进行 flat (扁平化)操作,数据会先经过跟 map ()方法一样的操作,为每一条输入返回一个迭代器(可迭代的数据类型),然后将所得到的不同级别的迭代器中的元素全部当成同级别的元素,返回一个元素级别全部相同的 RDD 。这个转换操作通常用来切分单词。
例如,分别用 map ()方法和 flatMap ()方法分割字符串。用 map ()方法分割后,每个元素对应返回一个迭代器,即数组。 flatMap ()方法在进行同 map ()方法一样的操作后,将3个迭代器的元素扁平化(压成同一级别),保存在新 RDD 中,代码如下图所示

5.使用 take ()方法查询某几个值
take ( N )方法用于获取 RDD 的前 N 个元素,返回数据为数组。 take ()与 collect ()方法的原理相似, collect ()方法用于获取全部数据, take ()方法获取指定个数的数据。获取 RDD 的前5个元素, 代码如下图所示

6.使用 union ()方法合并多个 RDD
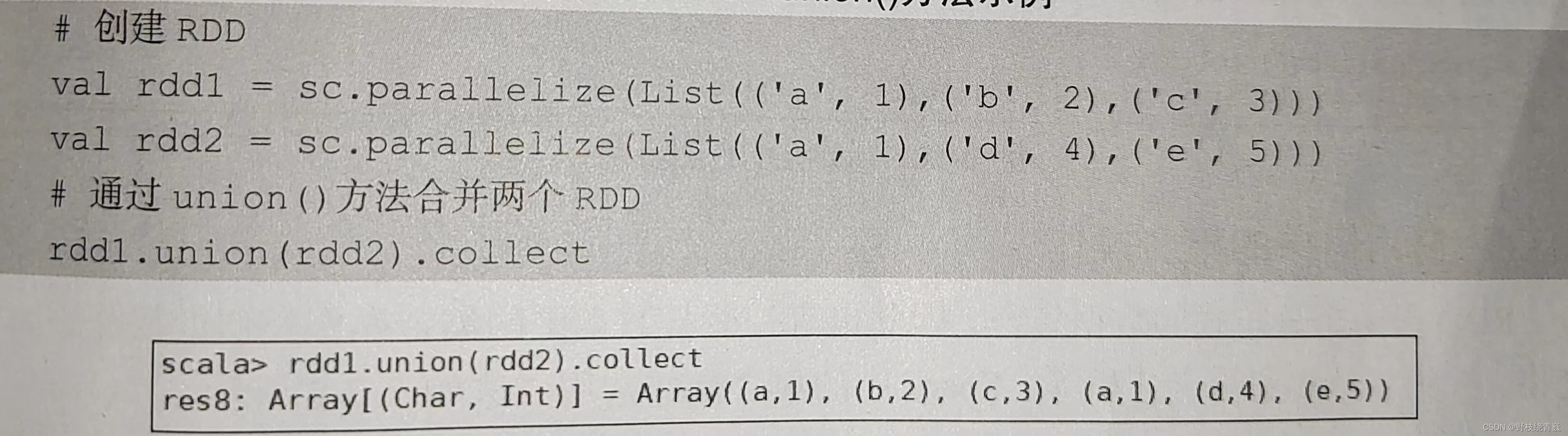
union方法是一种转换操作,用于将两个 RDD 合并成一个,不进行去重操作,而且两个 RDD 中每个元素中的值的个数、数据类型需要保持一致。创建两个存放二元组的 RDD ,通过 union ()方法合并两个 RDD ,不处理重复数据,并且每个二元组的值的个数、数据类型都是一致的,代码如下图所示
7.使用 filter ()方法进行过滤
filter ()方法是一种转换操作,用于过滤 RDD 中的元素。 filter ()方法需要一个参数,这个参数是一个用于过滤的函数,该函数的返回值为 Boolean 类型。 filter ()方法将返回值为 true 的元素保留,将返回值为 false 的元素过滤掉,最后返回一个存储符合过滤条件的所有元素的新 RDD 。
创建一个 RDD ,并且过滤掉每个元组第二个值小于等于1的元素,代码如下图所示

8.使用 distinct ()方法进行去重
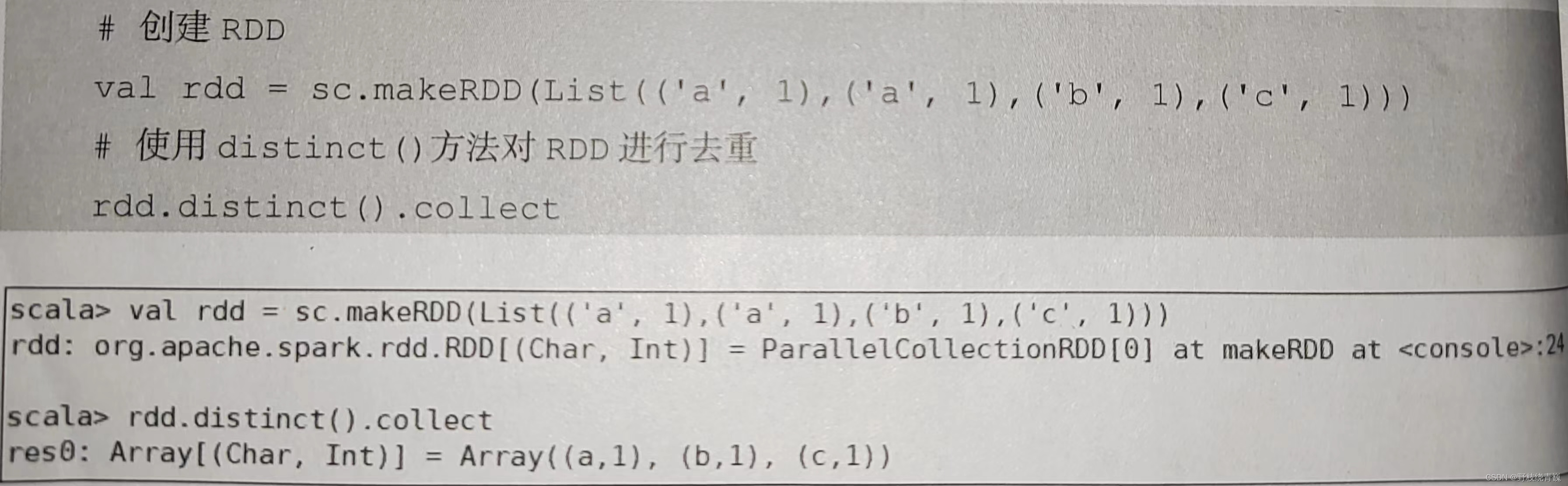
distinct ()方法是一种转换操作,用于 RDD 的数据去重,去除两个完全相同的元素,没有参数。创建一个带有重复数据的 RDD ,并使用 distinct ()方法去重,代码如下图所示
9.集合操作常用方法
(1)intersection ()方法
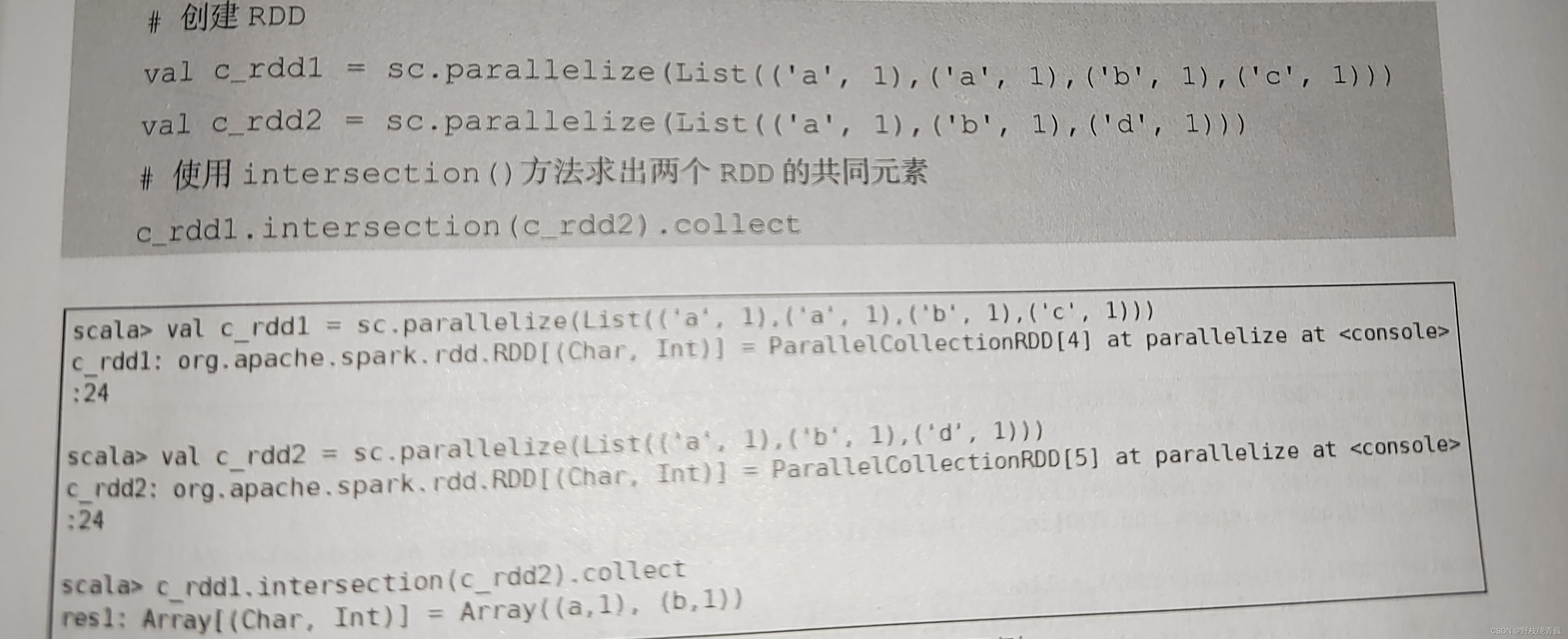
intersection ()方法用于求出两个 RDD 的共同元素,即找出两个 RDD 的交集,参数是另一个 RDD ,先后顺序与结果无关。创建两个 RDD ,其中有相同的元素,通过 intersection ()方法求出两个 RDD 的交集,代码如下图所示
(2) subtract ()方法
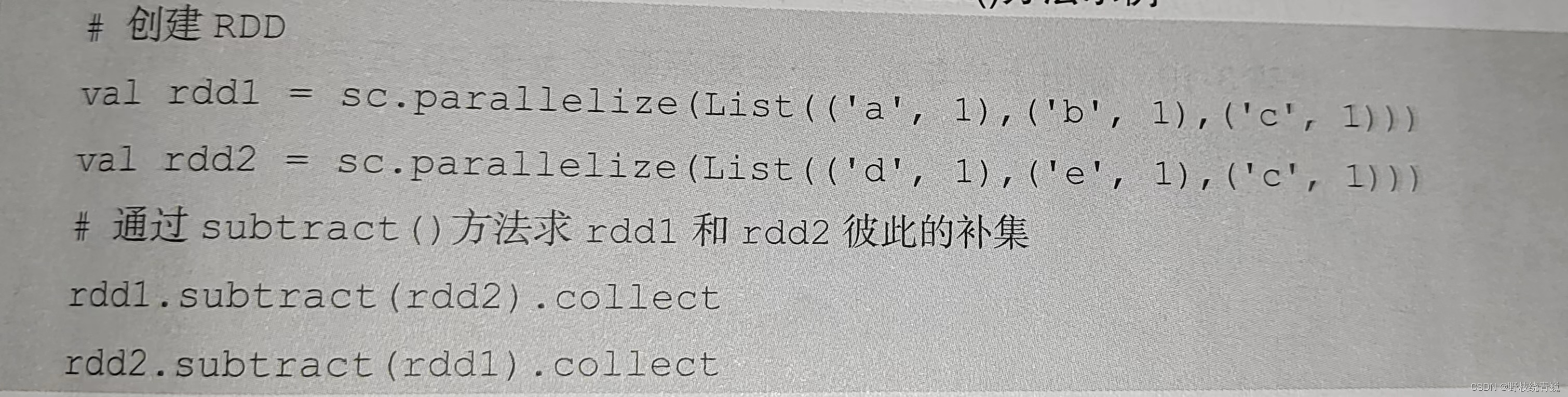
subtract ()方法用于将前一个 RDD 中在后一个 RDD 出现的元素删除,可以认为是求补集的操作,返回值为前一个 RDD 去除与后一个 RDD 相同元素后的剩余值所组成的新的 RDD 。两个 RDD 的顺序会影响结果。创建两个 RDD ,分别为rdd1和rdd2,包含相同元素和不同元素,通过 subtract ()方法求rdd1和rdd2彼此的补集,代码如下图所示
(3) cartesian ()方法
cartesian ()方法可将两个集合的元素两两组合成一组,即求笛卡儿积。假设集合 A 有5个元素,集合 B 有10个元素,集合 A 的每个元素都会和集合 B 的每个元素组合成一组,结果会返回50个元素组合。例如,创建两个 RDD ,分别有4个元素,通过 cartesian ()方法求两个 RDD 的笛卡儿积,代码如下图所示

10.使用键值对 RDD 的 keys 和 values 方法
键值对 RDD ,包含键和值两个部分。 Spark 提供了两种方法,分别获取键值对 RDD 的键和值。 keys 方法返回一个仅包含键的 RDD , values 方法返回一个仅包含值的 RDD 。通 keys 和 values 方法分别查看 words 的键与值,代码如下图所示

11.使用键值对 RDD 的 reduceByKey ()方法
当数据集以键值对形式展现时,合并统计键相同的值是很常用的操作。 reduceByKey ()方法用于合并具有相同键的值,作用对象是键值对,并且只对键的值进行处理。 reduceByKey (方法需要接收一个输入函数,键值对 RDD 相同键的值会根据函数进行合并,并创建一个新的 RDD 作为返回结果。在进行处理时, reduceByKey ()方法将相同键的前两个值传给输入函数,产生一个新的返回值,新产生的返回值与 RDD 中相同键的下一个值组成两个元素,再传给输入函数,直到最后每个键只有一个对应的值为止。 reduceByKey )方法不是一种行动操作,而是一种转换操作
定义一个含有多个相同键的键值对 RDD ,使用 reduceByKey ()方法对每个键的值进行求和,代码 如下图所示

12.使用键值对 RDD 的 groupByKey ()方法
groupByKey ()方法用于对具有相同键的值进行分组,可以对同一组的数据进行计数、求和等操作。对于一个由类型 K 的键和类型 V 的值组成的 RDD ,通过 groupByKey ()方法得到的 RDD 类型是[ K , Iterable [ V ]]。
对 rdd _1根据键进行分组,查看分组中的值,并对每个分组的值的数量进行统计,代码如下图所示

13.使用join ()方法链接两个RDD
join ()方法用于根据键对两个 RDD 进行内连接,将两个 RDD 中键相同的数据的值存放在一个元组中,最后只返回两个 RDD 中都存在的键的连接结果。例如,在两个 RDD 中分别有键值对( K , V )和( K , W ),通过 join ()方法连接会返回( K ,( V , W ))。
创建两个 RDD ,含有相同键和不同的键,通过 join ()方法进行内连接,代码如下图所示

14.使用 zip ()方法组合两个 RDD
zip ()方法用于将两个 RDD 组合成键值对 RDD ,要求两个 RDD 的分区数量以及元素数
量相同,否则会抛出异常。
将两个非键值对 RDD 组合成一个键值对 RDD ,两个 RDD 的元素个数和分区个数都相同,代码如下图所示

15.使用 combineByKey ()方法合并相同键的值
combineByKey0方法是 Spark 中一个比较核心的高级方法,键值对的一些其他高级方法的底层均是使用 combineByKey ()方法实现的,如 groupBy - Key ()方法、 reduceByKey ()方法等。
combineByKey ()方法用于将键相同的数据合并,并且允许返回与输入数据的类型不同的返回值, combineByKey ()方法的使用方式如下。
combineByKey ( createCombiner , mergeValue , mergeCombiners , numPartitions = None )
16.使用 lookup ()方法查找指定键的值
lookup ( key : K )方法用于返回键值对 RDD 指定键的所有对应值。例如,通过 lookup ()方法查询 test 中键为 panda 的所有对应值,代码为:test.lookup("panda")
17.printSchema: 输出数据模式
创建DataFrame对象后,一-般 会查看DataFrame 的数据模式。使用printSchema函数可以查看DataFrame数据模式,输出列的名称和类型。查看DataFrame对象movies的数据模式,代码如下:movies.printSchema
18.show(): 查看数据
使用show()方法可以查看DaFame数据,使用show0方法查看DataFrame对象movies中的数据,show0方法 与show(rue)方法查询到的结果一样, 只显示前20条记录,并且最多只显示20个字符。如果需要显示所有字符,那么需要使用show(false)方法。show0方法默认只显示前20条记录。若需要查看前numRows条记录则可以使用show(numRows:Int)方法,如通过“movies.show(5)”命令查看movies前5条记录。

19.first()/head()/take()takeAsList(): 获取若干条记录
获取DataFrame若干条记录除了使用show0方法之外,还可以使用frst()、head()、take()、takeAsList()方法。分别使用first()、 head()、 take()、takeAsList(方法查看movies中前几条记录)。frst0和head0方法的功能类似,以Row或Array[Row]的形式返回一条或多条数据。take0和takeAsList()方法则会将获得的数据返回Driver 端,为避免Driver提示OutofMemoryError,数据量比较大时不建议使用这两个方法。

20.collec()lcollectAsList(): 获取所有数据
collect0方法可以查询DataFrame中所有的数据,并返回一一个数组,collectAsList0方法和collect0方法类似,可以查询DataFrame中所有的数据,但是返回的是列表。分别使用collect0和collectAsList0方法查看movies所有数据。

21.DataFrame查询操作
(1)where()方法
DataFrame可以使用where(conditionExpr:String)方法查询符合指定条件的数据,参数中可以使用and或or。where(方法的返回结果仍然为DataFrame。

(2)filter0方法
DataFrame还可以使用filter0方 法筛选出符合条件的数据。

(3)select()方法:获取指定字段值
select()方法根据传人的String类型字段名获取对应的值,并返回一个DataFrame对象

(4) selectExpr()方法:对指定字段进行特殊处理
在实际业务中,可能需要对某些字段进行特殊处理,如为某个字段取别名、对某个字段的数据进行四舍五人等。DataFrame 提供了selectExpr()方法,可以对指定字段取别名或调用UDF函数对其进行其他处理。selectExpr()方法传人String类型的参数,返回一个DataFrame对象。

(5)col()/apply()方法
col()和apply()方法也可以获取DataFrame指定字段,但只能获取一个字段,并且返回的是-一个 Column对象。

(6)limit()方法
limit()方法可以获取指定DataFrame数据的前n条记录。不同于take()与head()方法,limit()方法不是行动操作,因此并不会直接返回查询结果,需要结合show0方法或其他行动操作才可以显示结果。

(7)orderBy()/sort()方法
orderBy()方法用于根据指定字段对数据进行排序,默认为升序排序。若要求降序排序,orderBy()方法的参数可以使用“desc("字段名称")” 或“$"字段名称" .desc",也可以在指定字段前面加“-”。
sort ()方法也可以根据指定字段对数据进行排序,用法与orderBy0方法一样。使用 sort ()
方法根据 userld 字段对 user 对象进行升序排序。



(8)groupBy()方法
使用groupBy()方法可以根据指定字段对数据进行分组操作。groupBy()方法的输人参数既可以是String类型的字段名,也可以是Column对象。

(9) join()方法
数据并不一定都存放在同一个表中,也有可能存放在两个或两个以上的表中。根据业务需求,有时候需要连接两个表才可以查询出业务所需的数据。DataFrame 提供了join()方法用于连接两个表。

22.map()方法 (一对一映射)
map()方法可通过一个函数重新计算列表中的所有元素,并且返回一个包含相同数目元素的新列表。例如,定义一个Int类型列表,列表中的元素为 1~5,使用 map()方法对列表中的元素进行平方计算
23.flatMap()方法 (一对多映射)
flatMap()方法结合了 map()方法和 flatten()方法的功能,接收一个可以处理嵌套列表的函数,再对返回结果进行连接
24.groupBy()方法
groupBy ()方法可对集合中的元素进行分组操作,返回的结果是一个映射。对 1~10根据奇偶性进行分组,因此 groupBy ()方法传入的参数是一个计算偶数的函数,得到的结果是一个映射,包含两个键值对,键为 false 对应的值为奇数列表,键为true对应的值为偶数列表















 4946
4946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









