







1.对数组进行分区
(1)创建数组:val a1 = Array(1,2,3,4)
(2)对数组进行分区:val p1 = sc.parallelize(a1, 2)
(3)查询分区数量:p1.partitions.size
(4)查询每个分区的元素:p1.glom.collect
(5)查询全部数据:p1.collect

2.创建RDD
1中(1)(2)两步可以替换成val p1 = sc.makeRDD(List(1,2,3,4),2)

sc 指的是 Spark context,也就是Spark上下文。在spark-shell启动的时候有这个解释。
3.从文件读取数据
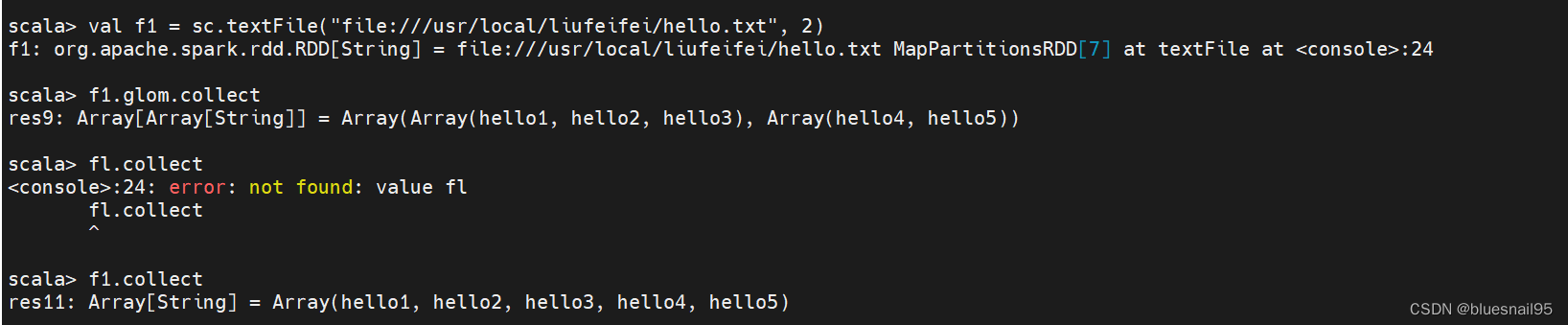
val f1 = sc.textFile(“file:///usr/local/liufeifei/hello.txt”, 2)
以行为单位读取数据

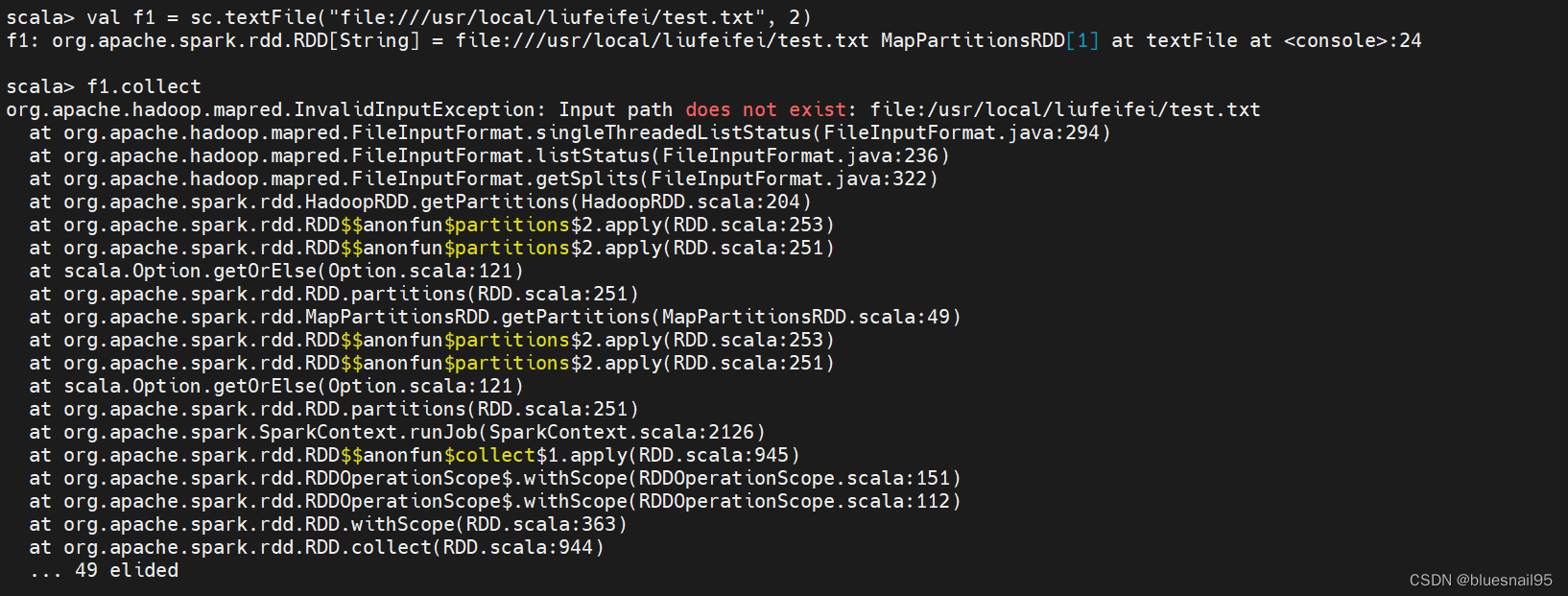
当读取的文件不存在,调用sc.textFile方法并不会立刻报错,而是等到执行collect方法时才会报错。
4.transformation操作–map
val r1 = sc.makeRDD(List(1,2,3,4),2)
val r2 = r1.map{num=>num*2}
r2.collect
r2.glom.collect

5.transformation操作-flatMap
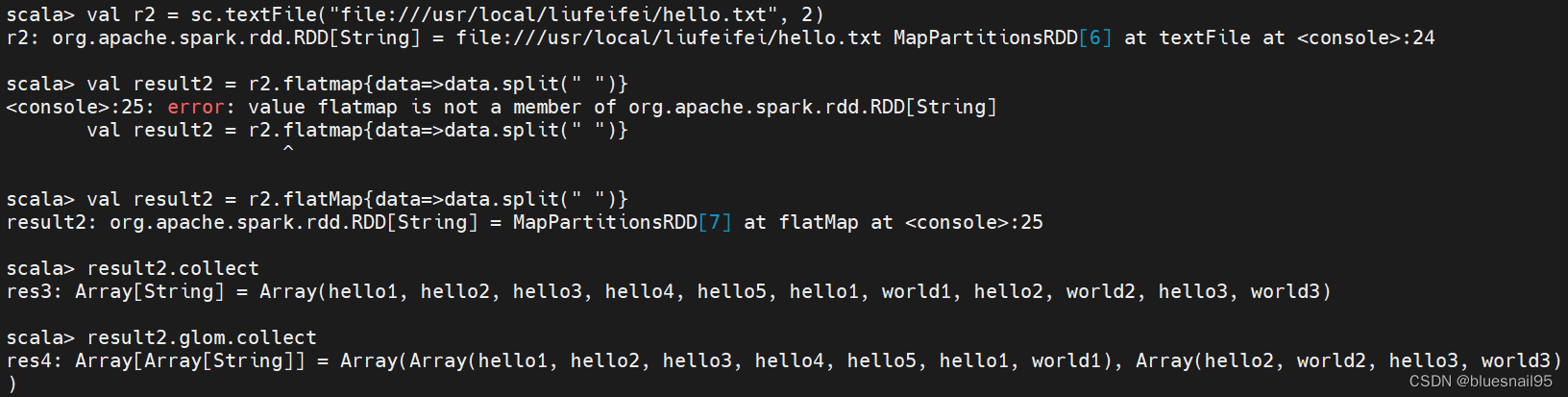
val r2 = sc.textFile(“file:///usr/local/liufeifei/hello.txt”, 2)
val result2 = r2.flatMap{data=>data.split(" ")}

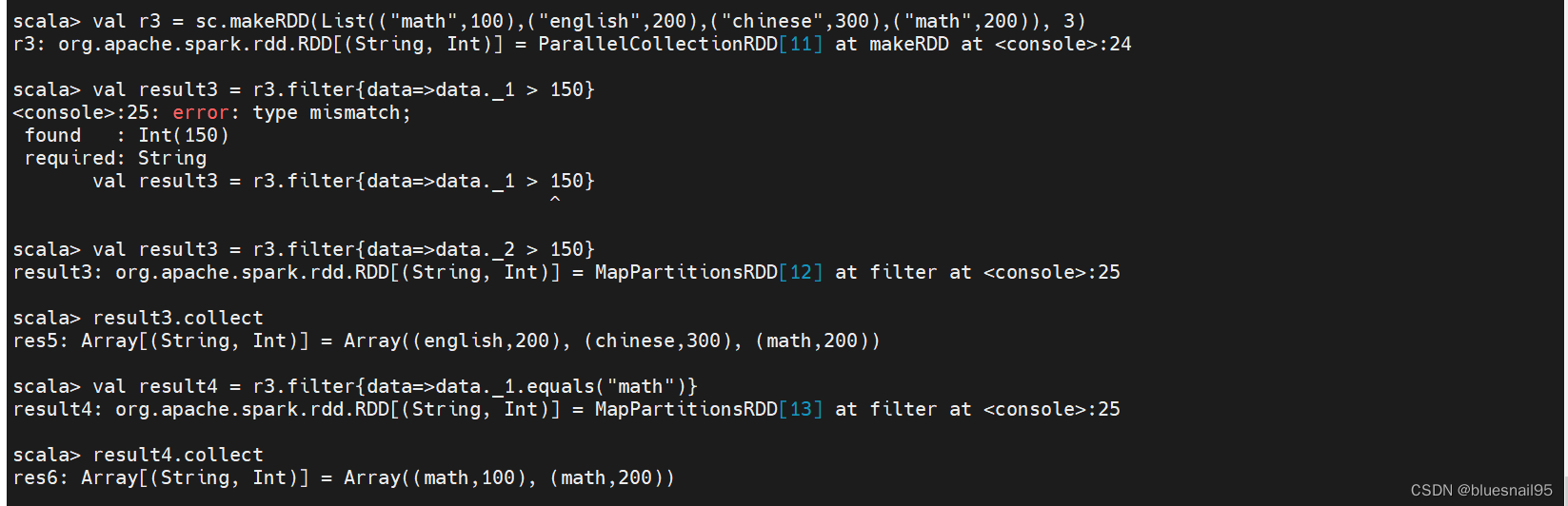
6.transformation操作–filter
val r3 = sc.makeRDD(List((“math”,100),(“english”,200),(“chinese”,300),(“math”,200)), 3)
val result3 = r3.filter{data=>data._2 > 150}
result3.collect
val result4 = r3.filter{data=>data._1.equals(“math”)}
result4.collect
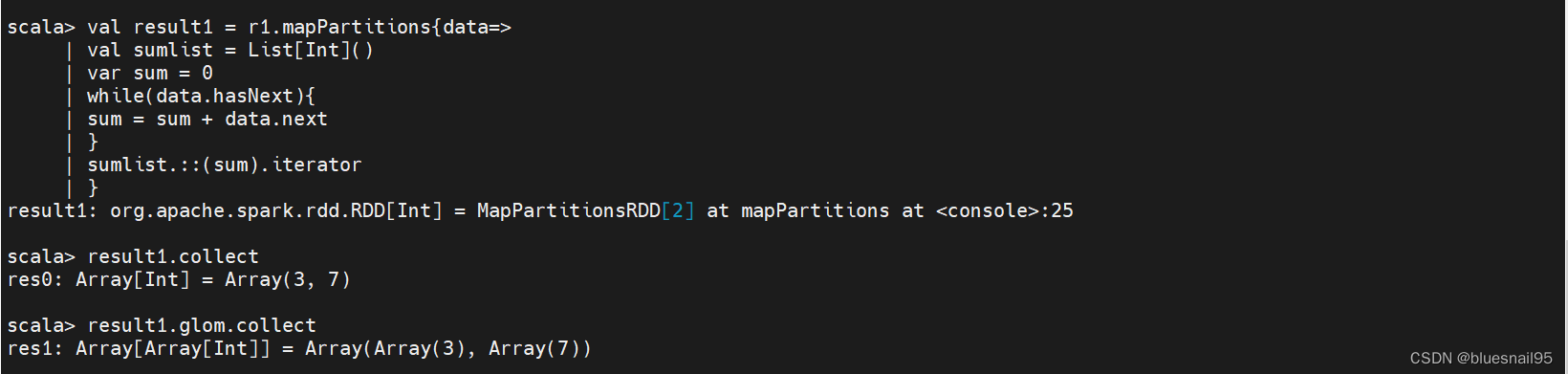
7.transformation操作–mapPartitions
根据各个分区遍历求和。
val result1 = r1.mapPartitions{data=>
val sumlist = List[Int]()
var sum = 0
while(data.hasNext){
sum = sum + data.next
}
sumlist.::(sum).iterator
}
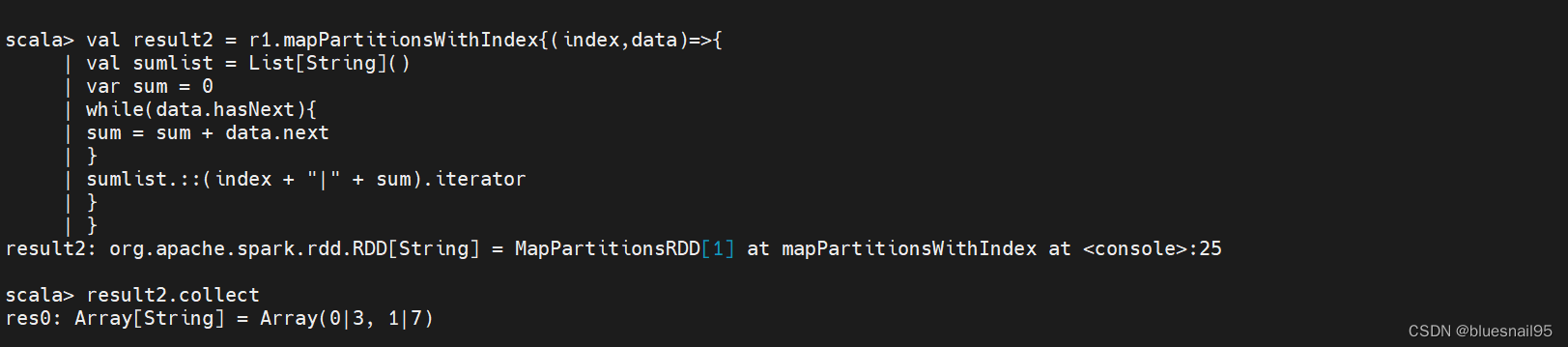
8.transformation操作–mapPartitionsWithIndex
根据分区遍历
val result2 = r1.mapPartitionsWithIndex{(index,data)=>{
val sumlist = List[String]()
var sum = 0
while(data.hasNext){
sum = sum + data.next
}
sumlist.::(index + "|" + sum).iterator
}
}
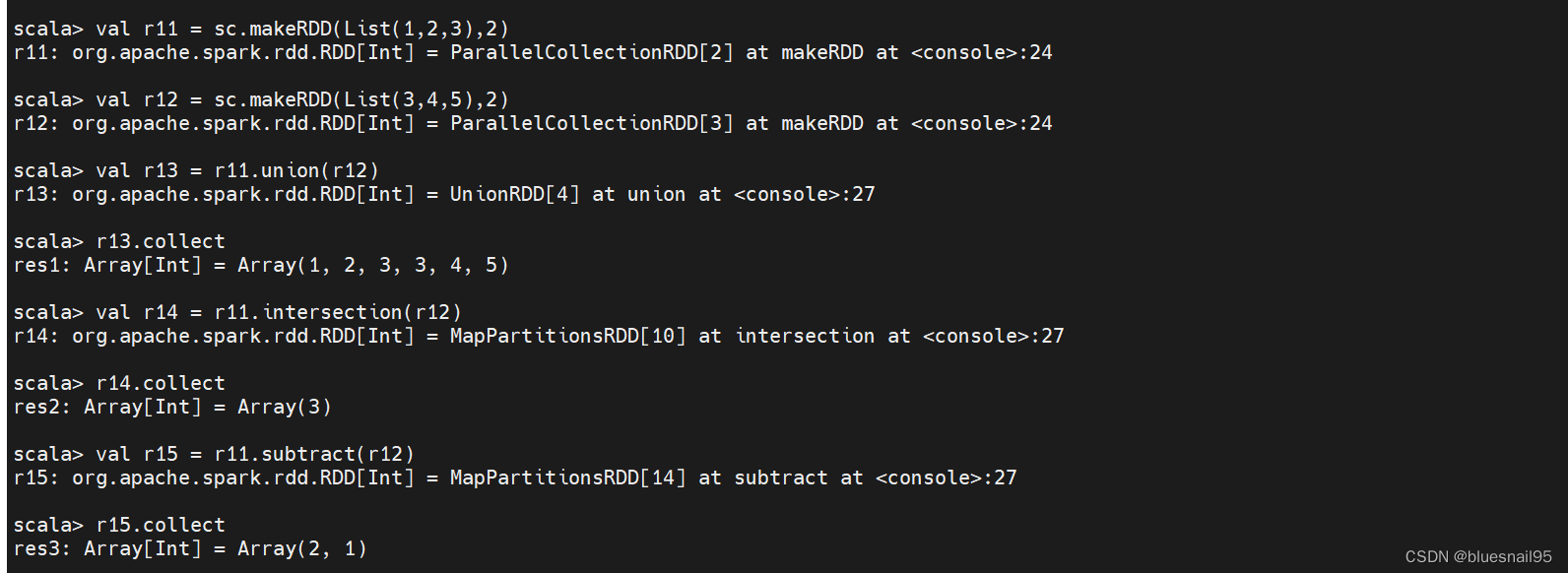
9.union、intersection、subtract、distinct操作
val r11 = sc.makeRDD(List(1,2,3),2)
val r12 = sc.makeRDD(List(3,4,5),2)
val r13 = r11.union(r12)
r13.collect
val r14 = r11.intersection(r12)
r14.collect
val r15 = r11.subtract(r12)
r15.collect
val r16 = r11.union(r12).distinct

10.groupBy和groupByKey操作
val r1 = sc.makeRDD(List((“math”,100), (“chinese”,200), (“english”,100),(“math”,20)))
val result1 = r1.groupByKey
result1.collect
val result2 = r1.groupBy{value=>value._1}
result2.collect
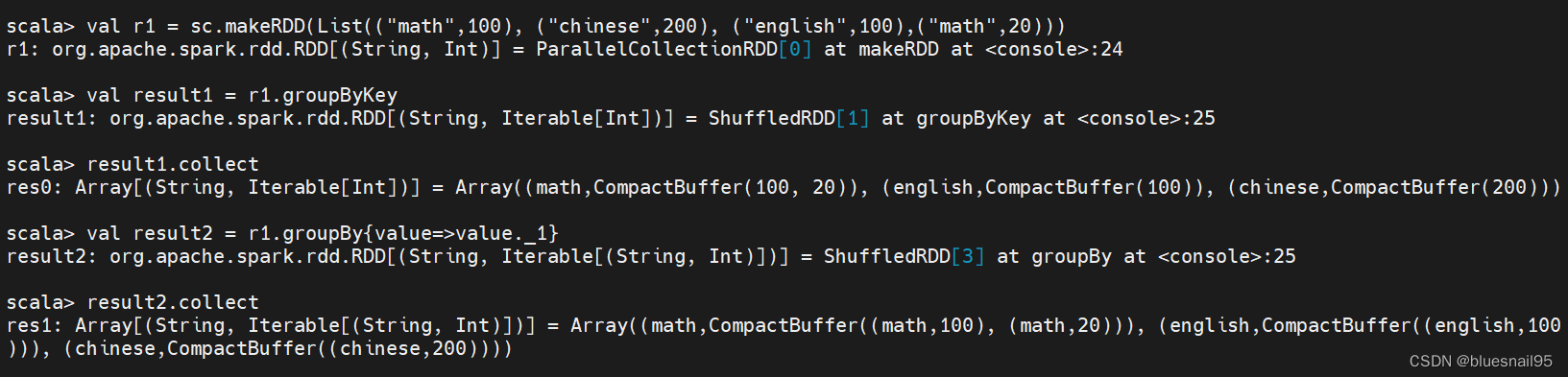
key和value调换顺序后,再根据key分组
val r2 = sc.makeRDD(List((100,“math”), (200,“chinese”), (100,“english”),(20,“math”)))
val result3 = r2.map{value=>(value._2, value._1)}.groupByKey
result3.collect

11.reduceByKey操作
val r1 = sc.makeRDD(List((“math”,100), (“chinese”,200), (“english”,100),(“math”,20)))
val result1 = r1.reduceByKey{(value,x)=>(value+x)}
result1.collect

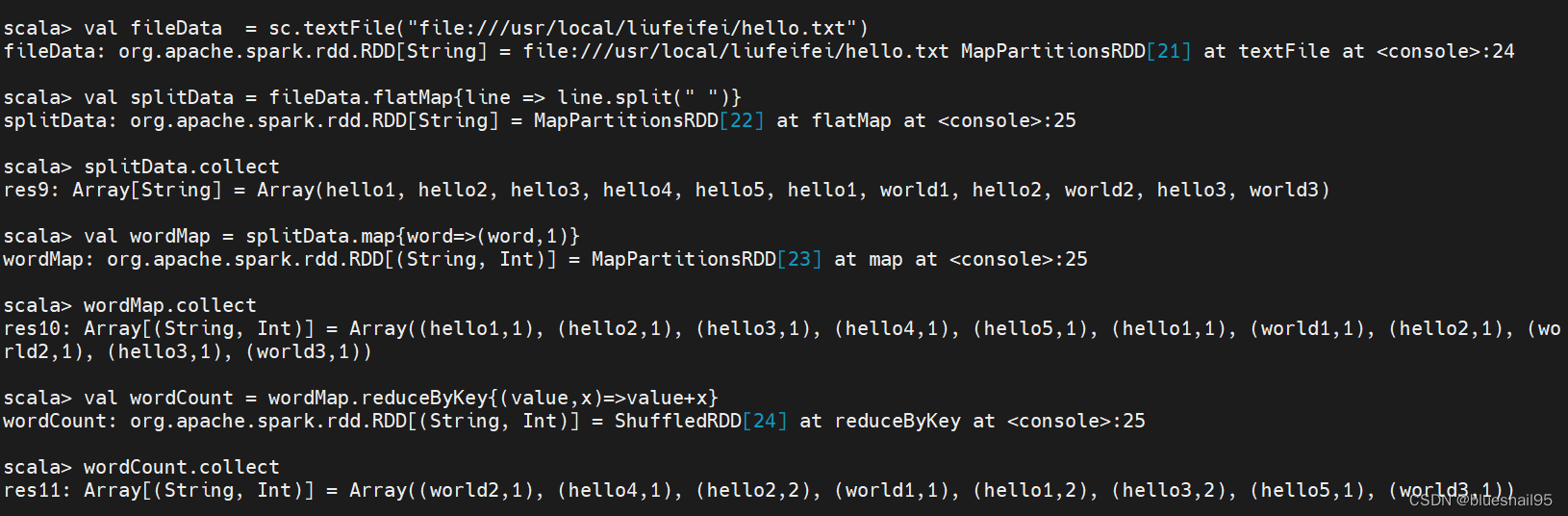
12.统计单词出现的次数
val fileData = sc.textFile(“file:///usr/local/liufeifei/hello.txt”)
val splitData = fileData.flatMap{line => line.split(" ")}
splitData.collect
val wordMap = splitData.map{word=>(word,1)}
wordMap.collect
val wordCount = wordMap.reduceByKey{(value,x)=>value+x}
wordCount.collect
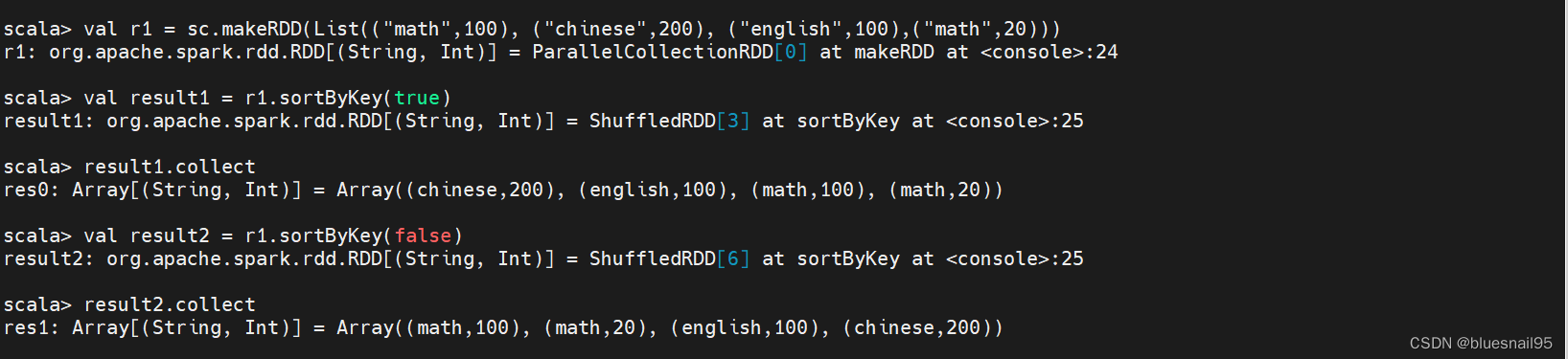
13.sortByKey和sortBy操作
val r1 = sc.makeRDD(List((“math”,100), (“chinese”,200), (“english”,100),(“math”,20)))
val result1 = r1.sortByKey(true)
result1.collect
val result2 = r1.sortByKey(false)
result2.collect
val r1 = sc.makeRDD(List((“math”,100), (“chinese”,200), (“english”,100),(“math”,20)))
val r2 = r1.map{data=>(data._2, data._1)}.sortByKey(true)
val result3 = r2.collect

val r1 = sc.makeRDD(List((“math”,100), (“chinese”,200), (“english”,100),(“math”,20)))
val result1 = r1.sortBy{data=>data._2}
result1.collect

14.coalesce操作
调整分区数量
val r1 = sc.makeRDD(List(1,2,3,4,5,6,7,8),2)
r1.partitions.size
val r2 = r1.coalesce(3,true)
r2.partitions.size

遇到问题:
Unable to connect to the server: net/http: TLS handshake timeout

参考:
Spark 读取文件系统的数据
Spark reduceByKey函数
Spark单词统计示例















 1091
1091











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









