







上一章 我们讲述了套接字的半断开,下面 我们将讲述域名和网络地址
1.DNS是对IP地址和域名相互转换的系统。那什么是域名呢?

即域名就是一个IP地址的取代,一个“名字”。

DNS服务器负责将域名的虚拟地址转换为真实的IP地址,每个计算机都有着默认的DNS服务器地址,在进入一个网站时,这个默认DNS服务器就负责获取该域名对应的真实的IP地址。
但是计算机的默认DNS服务器不是知道网络中所有的域名对应的IP地址,所以其会访问其他的DNS服务器,以至于获得IP地址。具体如下图:
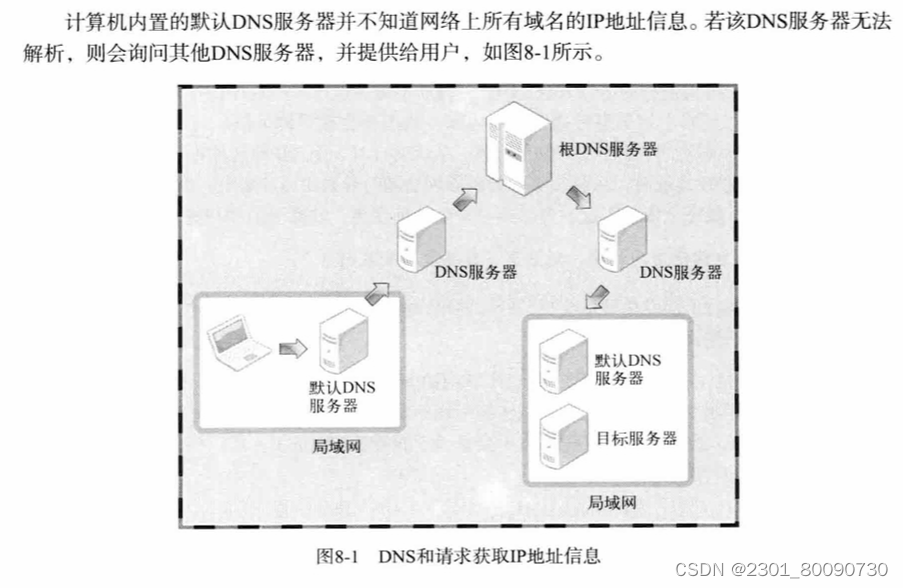

那在程序中有必要使用域名吗?

即,IP地址比域名变化概率更高,如果每次IP地址变化时,都要重新更改,这样是不好的。
下面介绍利用域名(字符串类)来获得IP地址的函数:

获得的信息是存入hostent结构体当中,类比调用ACCEPT函数。下面介绍的是该结构体的结构。


h_lengh保存的是网络地址的长度,如果是IPV4,则保存的是4,如果是IPV6 则是16.
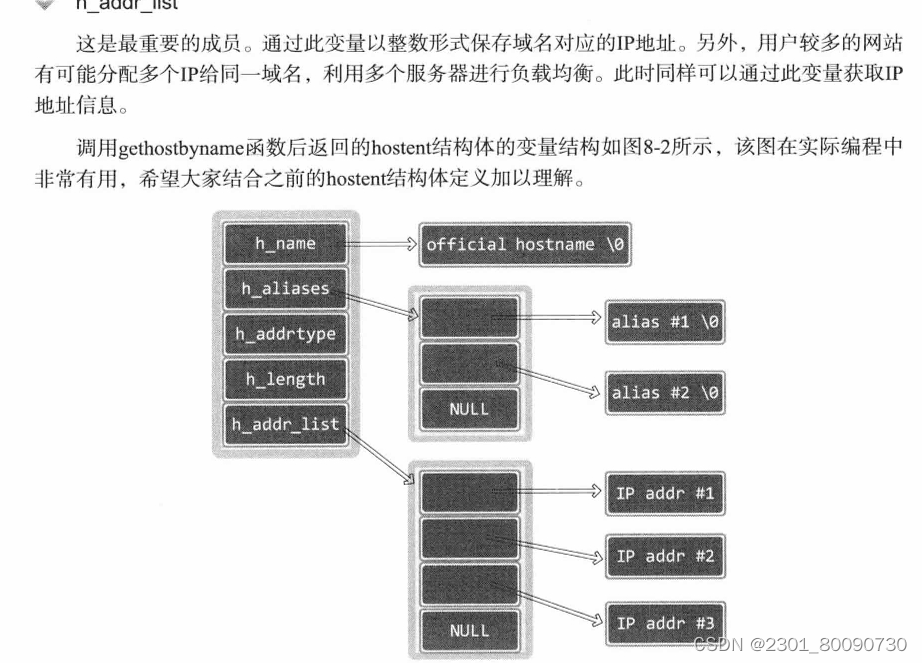
注意的是h_aliases是域名,可能是多个,h_addr_list是网络地址,可能是多个。
如下是简单的代码演示:
#include<iostream>
#include<unistd.h>
#include<arpa/inet.h>
#include<netdb.h>
int main(int argc,char* argv[]){
int i=0;
struct hostent* host;
if(argc!=2){
std::cout<<"error"<<std::endl;
exit(1);
}
host=gethostbyname(argv[1]);
std::cout<<"the name is:"<<host->h_name<<std::endl;
for(;host->h_aliases[i];i++){
std::cout<<host->h_aliases[i]<<std::endl;
}
std::cout<<(host->h_addrtype)<<std::endl;
for(int j=0;host->h_addr_list[j];j++){
std::cout<<(inet_ntoa(*(struct in_addr*)host->h_addr_list[j]))<<std::endl;
}
return 0;
}虽然只看hostent结构体中的h_addr_list是指针数组,但字符串指针数组实际指向的是in_addr结构体变量地址值而非字符串,所以要进行转化。(先是指针转化 再是解引用,解引用后是结构体变量, 再是转换为字符串类)
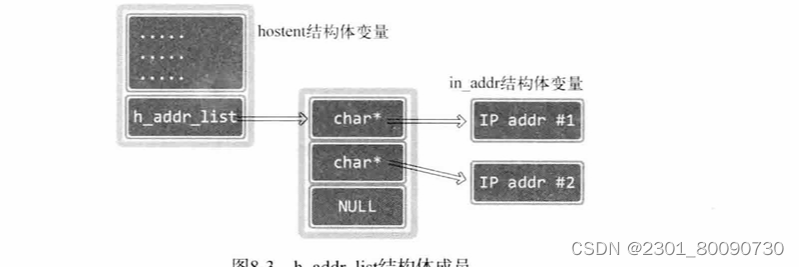

上面是通过域名获得IP地址 下面将介绍通过IP地址获得域名的gethostbyaddr函数。

#include<iostream>
#include<unistd.h>
#include<arpa/inet.h>
#include<netdb.h>
#include<string.h>
int main(int argc,char* argv[]){
int i=0;
struct hostent* host;
if(argc!=2){
std::cout<<"error"<<std::endl;
exit(1);
}
struct sockaddr_in addr;
memset(&addr,0,sizeof(addr));
addr.sin_addr.s_addr=inet_addr(argv[1]);
host=gethostbyaddr((char*)&addr.sin_addr,4,AF_INET);//先定义一个sockaddr_in结构体变量 存入ip地址 传入函数时转化为char*
std::cout<<"the name is:"<<host->h_name<<std::endl;
for(;host->h_aliases[i];i++){
std::cout<<host->h_aliases[i]<<std::endl;
}
std::cout<<(host->h_addrtype)<<std::endl;
for(int j=0;host->h_addr_list[j];j++){
std::cout<<(inet_ntoa(*(struct in_addr*)host->h_addr_list[j]))<<std::endl;
}
return 0;
}注意要转化为char*指针类 这个很重要
下面讲述套接字的多种选择:
套接字对应的协议层有多种选择 如下图:
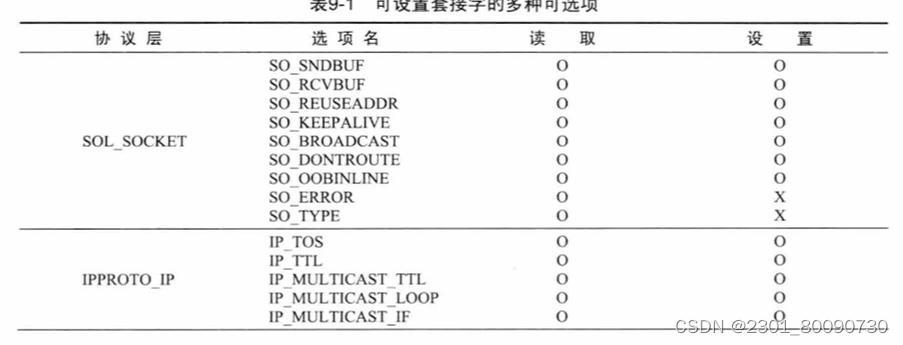
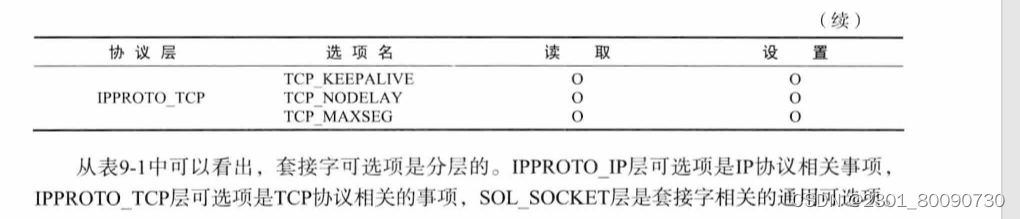
下面将介绍读取和设置套接字类型的函数:
读取函数

注意第四个参数保存了函数的查看结果,第五个参数存储的是查询结构的字节数。
修改函数


注意第四个参数是向套接字传递要修改的信息的信息的地址,第五个参数是字节数。
套接字的类型只能在创造时决定,以后不能改变。
下面是代码套接字的类型演示:
#include<iostream>
#include<unistd.h>
#include<sys/wait.h>
#include<cstring>
#include<fcntl.h>
#include<sys/socket.h>
using namespace std;
int main(int argc,char* argv[]){
int tcp_sock,udp_sock;
tcp_sock=socket(PF_INET,SOCK_STREAM,0);
udp_sock=socket(PF_INET,SOCK_DGRAM,0);
socklen_t size;
int sock_tpe;
int satat;
satat=getsockopt(tcp_sock,SOL_SOCKET,SO_TYPE,(void*)&sock_tpe,&size);//这个的返回值是来判断函数是否判断套接字类型成功
cout<<"the sock type is:"<<sock_tpe<<endl;
satat=getsockopt(udp_sock,SOL_SOCKET,SO_TYPE,(void*)&sock_tpe,&size);
cout<<"the sock type is:"<<sock_tpe<<endl;
return 0;
}
注意如上代码套接字的可选类型的是SO_TYPE。
运行结果如下:

下面将介绍IO缓冲区相关的函数:

代码演示的是缓冲区的读取;
#include<iostream>
#include<unistd.h>
#include<sys/wait.h>
#include<cstring>
#include<fcntl.h>
#include<sys/socket.h>
using namespace std;
int main(int argc,char* argv[]){
int sock;
int rev_buf,sed_buf,state;
socklen_t size;
sock=socket(PF_INET,SOCK_STREAM,0);
size=sizeof(sed_buf);
state=getsockopt(sock,SOL_SOCKET,SO_SNDBUF,(void*)&sed_buf,&size);//得到的输出缓冲区的大小存入 sed_buf中
size=sizeof(rev_buf);
state=getsockopt(sock,SOL_SOCKET,SO_RCVBUF,(void*)&rev_buf,&size);//SO_SNDBUF SO_RCVBUF都是可选 得到的输入缓冲区的大小存入 rev_buf中
cout<<"the output is:"<<sed_buf<<endl;
cout<<"the input is"<<rev_buf<<endl;
return 0;
}下面代码演示的是缓冲区的修改:
#include<iostream>
#include<unistd.h>
#include<sys/wait.h>
#include<cstring>
#include<fcntl.h>
#include<sys/socket.h>
using namespace std;
int main(int argc,char* argv[]){
int sock;
int rev_buf=1024*3,sed_buf=1024*3,state;
socklen_t size;
sock=socket(PF_INET,SOCK_STREAM,0);
state=setsockopt(sock,SOL_SOCKET,SO_SNDBUF,(void*)&sed_buf,sizeof(sed_buf));
state=setsockopt(sock,SOL_SOCKET,SO_RCVBUF,(void*)&rev_buf,sizeof(rev_buf));//修改缓冲区的大小
state=getsockopt(sock,SOL_SOCKET,SO_SNDBUF,(void*)&sed_buf,&size);
state=getsockopt(sock,SOL_SOCKET,SO_RCVBUF,(void*)&sed_buf,&size);//不论是set 还是got 对应的都要强制转换指针类型
cout<<"the output is:"<<sed_buf<<endl;
cout<<"the input is"<<rev_buf<<endl;
return 0;
}
注意set和get函数第四个参数的地址要强制转换为VOID*类的指针。
让我们再回忆下关闭套接字的四次握手协议,首先一方发出关闭请求,另一方同意后发出同意请求,该方接受后不会立即关闭。如果一方立刻关闭后,另一方发出关闭请求时,无法收到ACK并且无法回应。所以该方收到对方的关闭请求并向对方发送同意消息,对方收到后会关闭套接字后自己才会关闭。(先断开的会经历Time_wait,如果先断开的是服务器段,在这段时间内服务端重启时,bind()函数会调用失败,见下图)。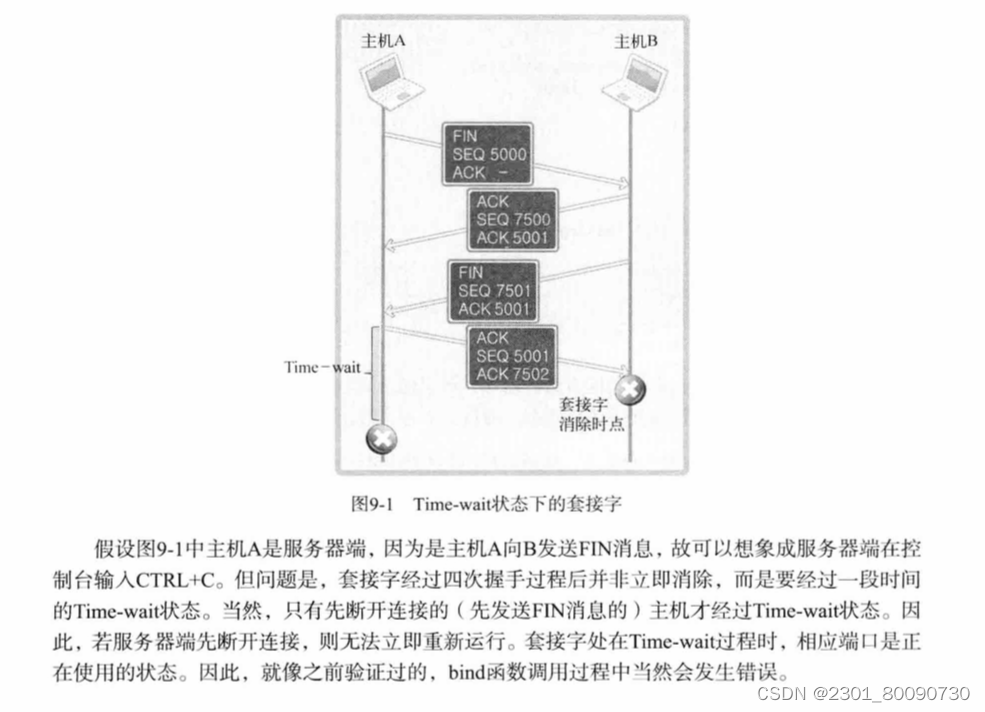

客户端和服务端都会经历TIME_WAIT阶段,但无需关心客户端,因为客户端每次运行时被操作系统自动任意分配。
为什么会有TIME_WAIT呢?


如上:先传输的FIN消息的主机会经历Time_wait消息。
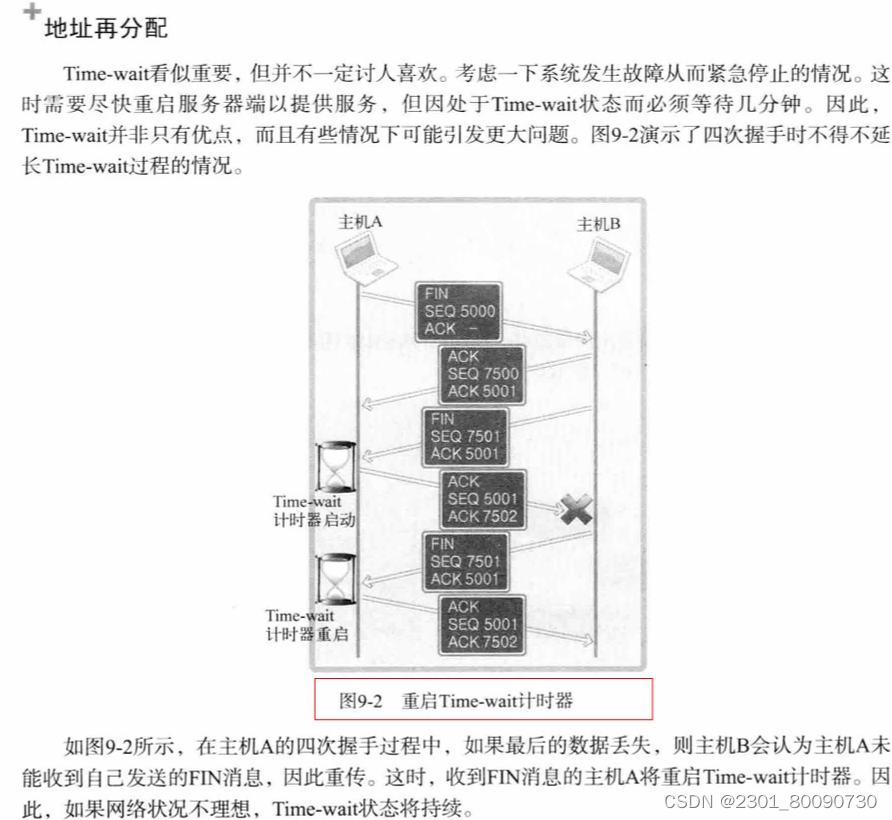
从上面我们已经知道如果服务器先断开再重启后会bind()error,要等几分钟,那么如何避免此事情发生呢?

 下面将简单介绍NAGLE算法:
下面将简单介绍NAGLE算法:
此算法是防止数据包过多而发生网络过载,下图将展示使用和未使用NAGLE算法传输数据的情况。
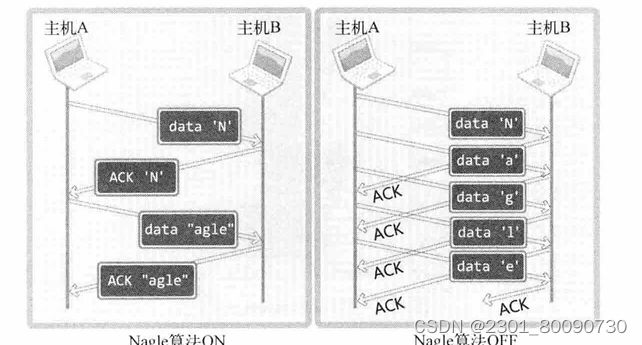
左边是使用了NAGLE算法,TCP套接字默认使用NAGLE算法,如图:当其收到上一次传输的ACK后才会才会传递接下来的数据。一共只要四个数据包。

虽然使用NAGLE算法能提升网络流量,但是会限制传输速度,禁用NAGLE算法会大规模提高传输速度。

如上方法可以禁用。















 6010
6010

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









