







前言
阅读时间:4分钟左右
众所周知,社区几乎没有反爬策略,于是我们可以轻松地开发一个爬虫。
(脚本,采集的数据放到了最后)
编写
1.确定非置顶帖子名字的xpath
首先,在登录状态下进入社区https://bbs.zkaq.cn/
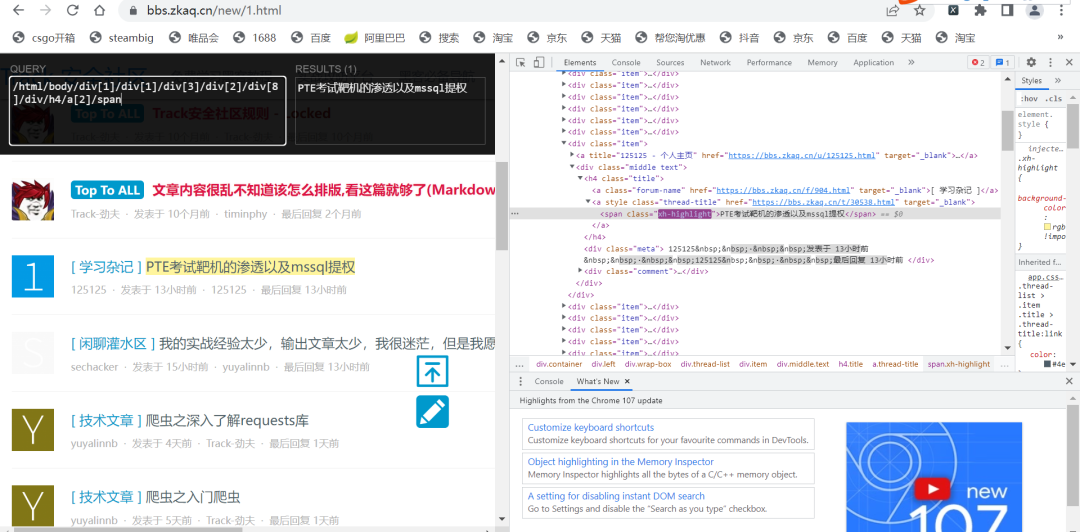
我们的目标是爬取每一页的每个帖子,但是不包含重复的置顶帖子,我们这里将使用绝对路径的方法。我们看一下源码,找到帖子名字所在的位置检查,然后右键,copy,copy xpath。但是这个复制出来的是位置,不是值,所以要增加text()。另一方面,我们只选中了一个帖子名字,那么怎么选中除了置顶的所有的帖子名字呢?
-
/html/body/div[1]/div[1]/div[3]/div[2]/div[8]/div/h4/a[2]/span
这就是图中的PTE考试靶机什么的xpath位置,可以看见这里有很多切片,那么我们可以尝试去除任意切片,观察选中的帖子。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 750
750

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









