







【学习笔记】之数值分析
文章目录
前言
本文为武汉理工大学计算机与人工智能学院大二专业课《数值分析》课程的学习笔记,所用教材为数值分析简明教程第二版(王能超编著),主要涵盖了数值分析的主要知识点与书上重要的例题。
这是笔者的第一篇博客。写这篇博客的起源是笔者在期末复习数值分析这门课时发现网上并没有较为全面的整理,而教材上有些叙述晦涩难懂,有些公式其实只需简单记忆却长篇大论,自学而言十分痛苦(😭😭😭)。而我在复习完这门课后对这门课有了较为深刻的理解,通过期末考试,我又更加了解了数值分析的考试重难点,验证了自己笔记的全面性与有效性,最终也取得了90+的成绩。
真诚希望这篇博客能帮助到正在预习/复习数值分析的你,如果文章有什么错误,欢迎指出😊!
引论
基本概念
科学计算:用电子计算机进行科学技术计算,简称细算。
数值分析:研究科学计算中各类数学问题的数值计算方法。
解析解:严格的公式(例如x= 5 \sqrt{5} 5 ); 数值解: x=2.236。
精确解:计算过程没有误差 ; 近似解:计算结果不准确。
算法
秦九韶算法 :迭代法求解多项式,大概了解即可,不懂的网上搜就行啦!
二分法 : ∣ x ∗ − x k ∣ ⩽ 1 2 ( b k − a k ) = 1 2 k + 1 ( b − a ) |x^{\ast }-x_{k}|\leqslant \tfrac{1}{2}(b^{k}-a^{k})=\tfrac{1}{2^{k+1}}(b-a) ∣x∗−xk∣⩽21(bk−ak)=2k+11(b−a)。
算法的稳定性:在输入或参数扰动下,输出的响应是否趋于有界或稳定状态。
算法的收敛性:数值计算方法在迭代过程中,得到的结果是否趋于准确解。
误差
观测误差:测量或实验中存在的误差。
模型误差:实际问题建立为数学模型时产生的误差。
截断误差:近似解(计算部分)与精确解之间的误差。
舍入误差:计算过程中取有限位数引入的误差。
(绝对)误差限:
e
=
x
−
x
∗
e=x-x^{\ast }
e=x−x∗;
∣
e
∣
=
∣
x
−
x
∗
∣
⩽
ε
|e|=|x-x^{\ast }|\leqslant \varepsilon
∣e∣=∣x−x∗∣⩽ε
x
x
x :近似值;
ε
\varepsilon
ε :绝对误差限、误差限、精度。
有效数字:近似值
x
x
x的误差限是它某一位的半个单位,则精确到这一位。
计算有效数字:
若
x
=
±
0.
a
1
a
2
a
3
⋯
a
n
×
1
0
m
x=\pm 0.a_{1} a_{2}a_{3}\cdots a_{n}\times 10^{m}
x=±0.a1a2a3⋯an×10m ;
∣
x
−
x
∗
∣
⩽
1
2
×
1
0
m
−
l
|x-x^{\ast }|\leqslant\frac{1}{2}\times 10^{m-l}
∣x−x∗∣⩽21×10m−l;
1
⩽
l
⩽
n
1\leqslant l\leqslant n
1⩽l⩽n
则
x
x
x 有
l
l
l 位有效数字。
相对误差:
∣
e
x
∣
=
∣
e
r
∣
=
∣
x
−
x
∗
∣
x
⩽
ε
|\frac{e}{x}|=|e_{r}|=\frac{|x-x^{\ast }|}{x}\leqslant \varepsilon
∣xe∣=∣er∣=x∣x−x∗∣⩽ε
ε
\varepsilon
ε :相对误差限
数值计算的注意事项
避免两个近似的数相减:两个值相近的近似数相减,可能会造成有效数字的严重损失,在实际计算时需加工计算公式,以避免这种情况发生。
避免大数吃小数:先算较小的数。
绝对值小的数不做除数。
第一章 插值方法
基本概念
近似函数 P ( x ) P(x) P(x)取给定的离散数据,称之为在 f ( x ) f(x) f(x)的插值函数。
代数插值:代数多项式作为插值函数。代数插值存在唯一性。
唯一性的证明:
设所求插值多项式为
p
n
(
x
)
=
a
0
+
a
1
x
+
a
2
x
2
+
⋯
+
a
n
x
n
p_{n}(x)=a_{0}+a_{1}x+a_{2}x^{2}+\cdots +a_{n}x^{n}
pn(x)=a0+a1x+a2x2+⋯+anxn,代入得范德蒙行列式,故得定理:
p
n
(
x
)
p_{n}(x)
pn(x)存在且唯一。
⇒
\Rightarrow
⇒即对于同一个插值条件,用插值方法插值出的插值函数一定相同。
模型结构 :基函数 + + +系数。
泰勒插值
插值条件:知 f ( k ) ( x 0 ) , ( k = 0 , 1 , ⋯ , n ) f^{(k)}(x_{0}),(k=0,1,\cdots ,n) f(k)(x0),(k=0,1,⋯,n)
泰勒插值函数满足 x 0 x_{0} x0处导数值与原函数相同。
插值函数: p n ( x ) = f ( x 0 ) + f ( ˊ x 0 ) ( x − x 0 ) + f ′ ′ ( x 0 ) 2 ! ( x − x 0 ) 2 + ⋯ + f ( n ) ( x 0 ) n ! ( x − x 0 ) n p_{n}(x)= f(x_{0})+{f}\'(x_{0})(x-x_{0})+\frac{f^{''}(x_{0})}{2!}(x-x_{0})^{2}+\cdots +\frac{f^{(n)} (x_{0})}{n!}(x-x_{0})^{n} pn(x)=f(x0)+f(ˊx0)(x−x0)+2!f′′(x0)(x−x0)2+⋯+n!f(n)(x0)(x−x0)n
泰勒余项定理: ε = f ( x ) − p n ( x ) = f ( n + 1 ) ( ξ ) ( n + 1 ) ! ( x − x 0 ) n + 1 , ξ ∈ [ a , b ] \varepsilon =f(x)-p_{n}(x)=\frac{f^{(n+1)(\xi )}}{(n+1)!}(x-x_{0})^{n+1},\xi \in [a,b] ε=f(x)−pn(x)=(n+1)!f(n+1)(ξ)(x−x0)n+1,ξ∈[a,b]
(泰勒插值了解即可,不是重点)
拉格朗日插值
插值条件:知
f
(
x
i
)
=
y
i
(
i
=
0
,
1
,
⋯
,
n
)
f(x_{i})=y_{i}(i=0,1,\cdots ,n)
f(xi)=yi(i=0,1,⋯,n)
称
x
i
x_{i}
xi为插值节点。
拉格朗日插值函数满足插值节点处函数值与原函数相同。即 p n ( x i ) = y i , ( i = 0 , 1 , ⋯ , n ) p_{n}(x_{i})=y_{i},(i=0,1,\cdots ,n) pn(xi)=yi,(i=0,1,⋯,n)
拉格朗日线性插值(一次插值)
知 ( x 0 , y 0 ) , ( x 1 , y 1 ) (x_{0},y_{0}),(x_{1},y_{1}) (x0,y0),(x1,y1)。
作一次式 p 1 ( x ) = y 0 + y 1 − y 0 x 1 − x 0 ( x − x 0 ) p_{1}(x)=y_{0}+\frac{y_{1}-y_{0}}{x_{1}-x_{0}}(x-x_{0}) p1(x)=y0+x1−x0y1−y0(x−x0)
即 p 1 ( x ) = x − x 1 x 0 − x 1 y 0 + x − x 0 x 1 − x 0 y 1 p_{1}(x) =\frac{x-x_{1}}{x_{0}-x_{1}}y_{0}+\frac{x-x_{0}}{x_{1}-x_{0}}y_{1} p1(x)=x0−x1x−x1y0+x1−x0x−x0y1
其中 x − x 1 x 0 − x 1 , x − x 0 x 1 − x 0 \frac{x-x_{1}}{x_{0}-x_{1}},\frac{x-x_{0}}{x_{1}-x_{0}} x0−x1x−x1,x1−x0x−x0为插值基函数。插值基函数具有的性质为:取该插值节点时值为1,取其他插值节点时值为0.
拉格朗日抛物插值(二次插值)
知 ( x 0 , y 0 ) , ( x 1 , y 1 ) , ( x 2 , y 2 ) (x_{0},y_{0}),(x_{1},y_{1}), (x_{2},y_{2}) (x0,y0),(x1,y1),(x2,y2)。求作 p 2 ( x ) p_{2}(x) p2(x)。
可设 p 2 ( x ) = l 0 ( x ) y 0 + l 1 ( x ) y 1 + l 2 ( x ) y 2 p_{2}(x)=l_{0}(x)y_{0}+l_{1}(x)y_{1}+l_{2}(x)y_{2} p2(x)=l0(x)y0+l1(x)y1+l2(x)y2
由基函数性质:
l
0
(
x
)
l_{0}(x)
l0(x)满足
l
0
(
x
0
)
=
1
,
l
0
(
x
1
)
=
l
0
(
x
2
)
=
0
l_{0}(x_{0})=1,l_{0}(x_{1})=l_{0}(x2)=0
l0(x0)=1,l0(x1)=l0(x2)=0
求解易知:
{
l
0
(
x
)
=
(
x
−
x
1
)
(
x
−
x
2
)
(
x
0
−
x
1
)
(
x
0
−
x
2
)
l
1
(
x
)
=
(
x
−
x
0
)
(
x
−
x
2
)
(
x
1
−
x
0
)
(
x
1
−
x
2
)
l
2
(
x
)
=
(
x
−
x
0
)
(
x
−
x
1
)
(
x
2
−
x
0
)
(
x
2
−
x
1
)
\left\{\begin{matrix} l_{0}(x)=\frac{(x-x_{1})(x-x_{2})}{(x_{0}-x_{1})(x_{0}-x_{2})} \\ l_{1}(x)=\frac{(x-x_{0})(x-x_{2})}{(x_{1}-x_{0})(x_{1}-x_{2})} \\ l_{2}(x)=\frac{(x-x_{0})(x-x_{1})}{(x_{2}-x_{0})(x_{2}-x_{1})} \end{matrix}\right.
⎩
⎨
⎧l0(x)=(x0−x1)(x0−x2)(x−x1)(x−x2)l1(x)=(x1−x0)(x1−x2)(x−x0)(x−x2)l2(x)=(x2−x0)(x2−x1)(x−x0)(x−x1)
∴ p n ( x ) = ( x − x 1 ) ( x − x 2 ) ( x 0 − x 1 ) ( x 0 − x 2 ) y 0 + ( x − x 0 ) ( x − x 2 ) ( x 1 − x 0 ) ( x 1 − x 2 ) y 1 + ( x − x 0 ) ( x − x 1 ) ( x 2 − x 0 ) ( x 2 − x 1 ) y 2 \therefore p_{n}(x)=\frac{(x-x_{1})(x-x_{2})}{(x_{0}-x_{1})(x_{0}-x_{2})}y_{0}+\frac{(x-x_{0})(x-x_{2})}{(x_{1}-x_{0})(x_{1}-x_{2})}y_{1}+\frac{(x-x_{0})(x-x_{1})}{(x_{2}-x_{0})(x_{2}-x_{1})}y_{2} ∴pn(x)=(x0−x1)(x0−x2)(x−x1)(x−x2)y0+(x1−x0)(x1−x2)(x−x0)(x−x2)y1+(x2−x0)(x2−x1)(x−x0)(x−x1)y2
拉格朗日一般情形
知 ( x 0 , y 0 ) , ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x n , y n ) (x_{0},y_{0}),(x_{1},y_{1}), (x_{2},y_{2}),\cdots ,(x_{n},y_{n}) (x0,y0),(x1,y1),(x2,y2),⋯,(xn,yn)。求作 p 2 ( x ) p_{2}(x) p2(x)
构造插值基函数
l
k
(
x
)
,
(
k
=
0
,
1
,
⋯
,
n
)
l_{k}(x),(k=0,1,\cdots ,n)
lk(x),(k=0,1,⋯,n)是n次多项式.
由之前的插值基函数容易归纳得:
l
k
(
x
)
=
∏
j
=
0
,
j
≠
k
n
x
−
x
j
x
k
−
k
l_{k}(x)=\prod_{j=0,j\neq k}^{n}\frac{x-x_{j}}{x_{k}-k_{}}
lk(x)=∏j=0,j=knxk−kx−xj
得到拉格朗日插值公式
∴ p n ( x ) = ∑ k = 0 n ( ∏ j = 0 , j ≠ k n x − x j x k − x j ) y k \therefore p_{n}(x)=\sum_{k=0}^{n}(\prod_{j=0,j\neq k}^{n}\frac{x-x_{j}}{x_{k}-x_{j}})y_{k} ∴pn(x)=∑k=0n(∏j=0,j=knxk−xjx−xj)yk
-再次归纳拉格朗日基函数性质-
(1)
l
i
(
x
j
)
=
{
1
,
j
=
i
0
,
j
≠
i
(
i
,
j
=
0
,
1
,
⋯
,
n
)
l_{i}(x_{j})=\left\{\begin{matrix} 1,j=i \\0,j\neq i \end{matrix}\right. (i,j=0,1,\cdots ,n)
li(xj)={1,j=i0,j=i(i,j=0,1,⋯,n)
(2)
∑
i
=
0
n
l
i
(
x
)
≡
1
\sum_{i=0}^{n}l_{i}(x)\equiv 1
∑i=0nli(x)≡1
(3) l 0 ( x ) , l 1 ( x ) , l 2 ( x ) , ⋯ , l n ( x ) l_{0}(x),l_{1}(x),l_{2}(x),\cdots ,l_{n}(x) l0(x),l1(x),l2(x),⋯,ln(x)线性无关
插值余项
1、拉格朗日余项定理:
R
n
(
x
)
=
f
(
x
)
−
p
n
(
x
)
=
f
(
n
+
1
)
(
ξ
)
(
n
+
1
)
!
∏
k
=
0
n
(
x
−
x
k
)
R_{n}(x)=f(x)-p_{n}(x)=\frac{f^{(n+1)}(\xi )}{(n+1)!}\prod_{k=0}^{n}(x-x_{k})
Rn(x)=f(x)−pn(x)=(n+1)!f(n+1)(ξ)∏k=0n(x−xk)
ξ
\xi
ξ与
x
x
x有关,由
x
0
,
x
1
,
⋯
,
x
n
x_{0},x_{1},\cdots ,x_{n}
x0,x1,⋯,xn和
x
x
x界定,
ξ
∈
[
a
,
b
]
\xi \in [a,b]
ξ∈[a,b]
-拉格朗日余项定理的证明-
证:
设
R
n
(
t
)
=
f
(
t
)
−
p
n
(
t
)
=
c
⋅
ω
(
t
)
,
ω
(
t
)
=
∏
k
=
0
n
(
t
−
x
k
)
R_{n}(t)=f(t)-p_{n}(t)=c\cdot \omega (t),\omega (t)=\prod_{k=0}^{n}(t-x_{k})
Rn(t)=f(t)−pn(t)=c⋅ω(t),ω(t)=∏k=0n(t−xk)
令
f
(
t
)
−
p
n
(
t
)
−
c
⋅
ω
(
t
)
=
0
f(t)-p_{n}(t)-c\cdot \omega (t)=0
f(t)−pn(t)−c⋅ω(t)=0
易知:
t
=
x
0
,
x
1
,
⋯
,
x
n
t=x_{0},x_{1},\cdots ,x_{n}
t=x0,x1,⋯,xn和
t
=
x
t=x
t=x满足
由罗尔定理:
f
(
n
+
1
)
(
t
)
−
p
n
(
n
+
1
)
(
t
)
−
c
(
n
+
1
)
!
=
0
f^{(n+1)}(t)-p_{n}^{(n+1)}(t)-c(n+1)!=0
f(n+1)(t)−pn(n+1)(t)−c(n+1)!=0存在一个零点
ξ
\xi
ξ
∴
c
=
f
(
n
+
1
)
(
ξ
)
−
p
n
(
n
+
1
)
(
ξ
)
(
n
+
1
)
!
=
f
(
n
+
1
)
(
ξ
)
(
n
+
1
)
!
\therefore c=\frac{f^{(n+1)}(\xi )-p_{n}^{(n+1)}(\xi)}{(n+1)!}=\frac{f^{(n+1)}(\xi )}{(n+1)!}
∴c=(n+1)!f(n+1)(ξ)−pn(n+1)(ξ)=(n+1)!f(n+1)(ξ)
证毕!
2、误差的事后估计(了解即可):
方法:
若给
x
0
,
x
1
,
x
2
x_{0},x_{1},x_{2}
x0,x1,x2对
x
x
x进行插值,则用
x
0
,
x
1
x_{0},x_{1}
x0,x1插值出
y
1
y_{1}
y1,用
x
0
,
x
2
x_{0},x_{2}
x0,x2插值出
y
2
y_{2}
y2。
可用
y
2
−
y
1
y_{2}-y_{1}
y2−y1估计
y
1
y_{1}
y1 的误差。
这种直接用计算结果估计误差的方法叫做事后估计法。
牛顿插值
意义:具有承袭性的显示插值公式。(解决了拉格朗日插值每增加一个插值节点,所有的插值基函数都需要重新算的问题)
承袭性
当插值节点为一个,即 x 0 x_{0} x0时,有 p 0 ( x ) = f ( x 0 ) p_{0}(x)=f(x_{0}) p0(x)=f(x0)。
当插值节点为两个,即 x 0 , x 1 x_{0},x_{1} x0,x1时,有 p 1 ( x ) = p 0 ( x ) + f ( x 1 ) − f ( x 0 ) x 1 − x 0 ( x − x 0 ) p_{1}(x)=p_{0}(x)+{\color{Red} \frac{f(x_{1})-f(x_{0})}{x_{1}-x_{0}}}(x-x_{0}) p1(x)=p0(x)+x1−x0f(x1)−f(x0)(x−x0)。
当插值节点为三个,即 x 0 , x 1 , x 2 x_{0},x_{1},x_{2} x0,x1,x2时,有 p 2 ( x ) = p 1 ( x ) + f ( x 2 ) − f ( x 0 ) x 2 − x 0 − f ( x 1 ) − f ( x 0 ) x 1 − x 0 x 2 − x 1 ( x − x 0 ) ( x − x 1 ) p_{2}(x)=p_{1}(x)+{\color{Red} \frac{\frac{f(x_{2})-f(x_{0})}{x_{2}-x_{0}}-\frac{f(x_{1})-f(x_{0})}{x_{1}-x_{0}}}{x_{2}-x_{1}}}(x-x_{0})(x-x_{1}) p2(x)=p1(x)+x2−x1x2−x0f(x2)−f(x0)−x1−x0f(x1)−f(x0)(x−x0)(x−x1)
每增加一个插值节点,插值函数在之前的基础上增加一项,这种利用之前的计算结果的性质即为承袭性。
差商
即为增加的每一项的前面的系数(插值基函数)
零阶差商
f
(
x
0
)
f(x_{0})
f(x0)
一阶差商
f
(
x
0
,
x
1
)
=
f
(
x
1
)
−
f
(
x
0
)
x
1
−
x
0
f(x_{0},x_{1})=\frac{f(x_{1})-f(x_{0})}{x_{1}-x_{0}}
f(x0,x1)=x1−x0f(x1)−f(x0)
二阶差商
f
(
x
0
,
x
1
,
x
2
)
=
f
(
x
1
,
x
2
)
−
f
(
x
0
,
x
1
)
x
2
−
x
0
f(x_{0},x_{1},x_{2})=\frac{f(x_{1},x_{2})-f(x_{0},x_{1})}{x_{2}-x_{0}}
f(x0,x1,x2)=x2−x0f(x1,x2)−f(x0,x1)
n阶差商的递推定义:
f
(
x
0
,
x
1
,
⋯
,
x
n
)
=
f
(
x
1
,
⋯
,
x
n
)
−
f
(
x
0
,
⋯
,
x
n
−
1
)
x
n
−
x
0
f(x_{0},x_{1},\cdots ,x_{n})=\frac{f(x_{1},\cdots ,x_{n})-f(x_{0},\cdots ,x_{n-1})}{x_{n}-x_{0}}
f(x0,x1,⋯,xn)=xn−x0f(x1,⋯,xn)−f(x0,⋯,xn−1)
故可画出差商表一步一步计算差商:(对照公式多看几个就可以发现计算的方法,对角线上的值即为插值所需的差商)

n阶差商的显示表达式: f ( x 0 , x 1 , ⋯ , x n ) = ∑ k = 0 n f ( x k ) ∏ j = 0 , j ≠ k n ( x k − x j ) f(x_{0},x_{1},\cdots ,x_{n})=\sum_{k=0}^{n}\frac{f(x_{k})}{\prod_{j=0,j\neq k}^{n}(x_{k}-x_{j})} f(x0,x1,⋯,xn)=∑k=0n∏j=0,j=kn(xk−xj)f(xk)。(这个有时间就记一下,没时间把差商表的计算搞熟就行)
-差商的性质-
差商的对称性:差商的值与节点的排列顺序无关
差商和导数的关系(了解即可):设
f
(
x
)
∈
C
n
[
a
,
b
]
,
x
j
∈
[
a
,
b
]
,
j
=
0
,
1
,
⋯
,
n
f(x)\in C^{n}[a,b],x_{j}\in [a,b],j=0,1,\cdots ,n
f(x)∈Cn[a,b],xj∈[a,b],j=0,1,⋯,n为相异节点,则
f
(
x
0
,
x
1
,
⋯
,
x
n
)
=
1
n
!
f
(
n
)
(
ξ
)
,
ξ
∈
(
a
,
b
)
f(x_{0},x_{1},\cdots ,x_{n})=\frac{1}{n!}f^{(n)}(\xi ),\xi \in (a,b)
f(x0,x1,⋯,xn)=n!1f(n)(ξ),ξ∈(a,b)
牛顿插值公式
P n ( x ) = f ( x 0 ) + f ( x 0 , x 1 ) ( x − x 0 ) + f ( x 0 , x 1 , x 2 ) ( x − x 0 ) ( x − x 1 ) + ⋯ + f ( x 0 , x 1 , ⋯ x n ) ( x − x 0 ) ( x − x 1 ) ⋯ ( x − x n − 1 ) P_{n}(x)=f(x_{0})+f(x_{0},x_{1})(x-x_{0})+f(x_{0},x_{1},x_{2})(x-x_{0})(x-x_{1})+\cdots +f(x_{0},x_{1},\cdots x_{n})(x-x_{0})(x-x_{1})\cdots (x-x_{n-1}) Pn(x)=f(x0)+f(x0,x1)(x−x0)+f(x0,x1,x2)(x−x0)(x−x1)+⋯+f(x0,x1,⋯xn)(x−x0)(x−x1)⋯(x−xn−1)
余项:
P
(
x
)
=
f
(
x
0
,
x
1
,
⋯
x
n
,
x
)
(
x
−
x
0
)
(
x
−
x
1
)
⋯
(
x
−
x
n
)
P(x)=f(x_{0},x_{1},\cdots x_{n},x)(x-x_{0})(x-x_{1})\cdots (x-x_{n})
P(x)=f(x0,x1,⋯xn,x)(x−x0)(x−x1)⋯(x−xn)
牛顿公式是拉格朗日公式的一种变形,余项等价。
故有
f
(
x
0
,
x
1
,
⋯
x
n
)
=
f
(
n
)
(
ξ
)
(
n
)
!
,
ξ
∈
[
min
x
i
,
max
x
i
]
f(x_{0},x_{1},\cdots x_{n})=\frac{f^{(n)}(\xi )}{(n)!},\xi \in [\textbf{min}x_{i},\textbf{max}x_{i}]
f(x0,x1,⋯xn)=(n)!f(n)(ξ),ξ∈[minxi,maxxi]
若固定
x
0
x_{0}
x0且
x
1
,
x
2
,
⋯
x
n
x_{1},x_{2},\cdots x_{n}
x1,x2,⋯xn趋近
x
0
x_{0}
x0,则牛顿插值公式的极限为泰勒插值公式。
拉格朗日插值为泰勒插值的离散形式。
牛顿插值公式例题
教材P56,T17
给定函数
f
(
x
)
=
x
3
−
4
x
f(x)=x^{3}-4x
f(x)=x3−4x,试建立关于节点
x
i
=
i
+
1
(
i
=
0
,
1
,
2
,
⋯
,
5
)
x_{i}=i+1(i=0,1,2,\cdots ,5)
xi=i+1(i=0,1,2,⋯,5)的差商表,并列出关于节点
x
0
,
x
1
,
x
2
,
x
3
x_{0},x_{1},x_{2},x_{3}
x0,x1,x2,x3的插值多项式。
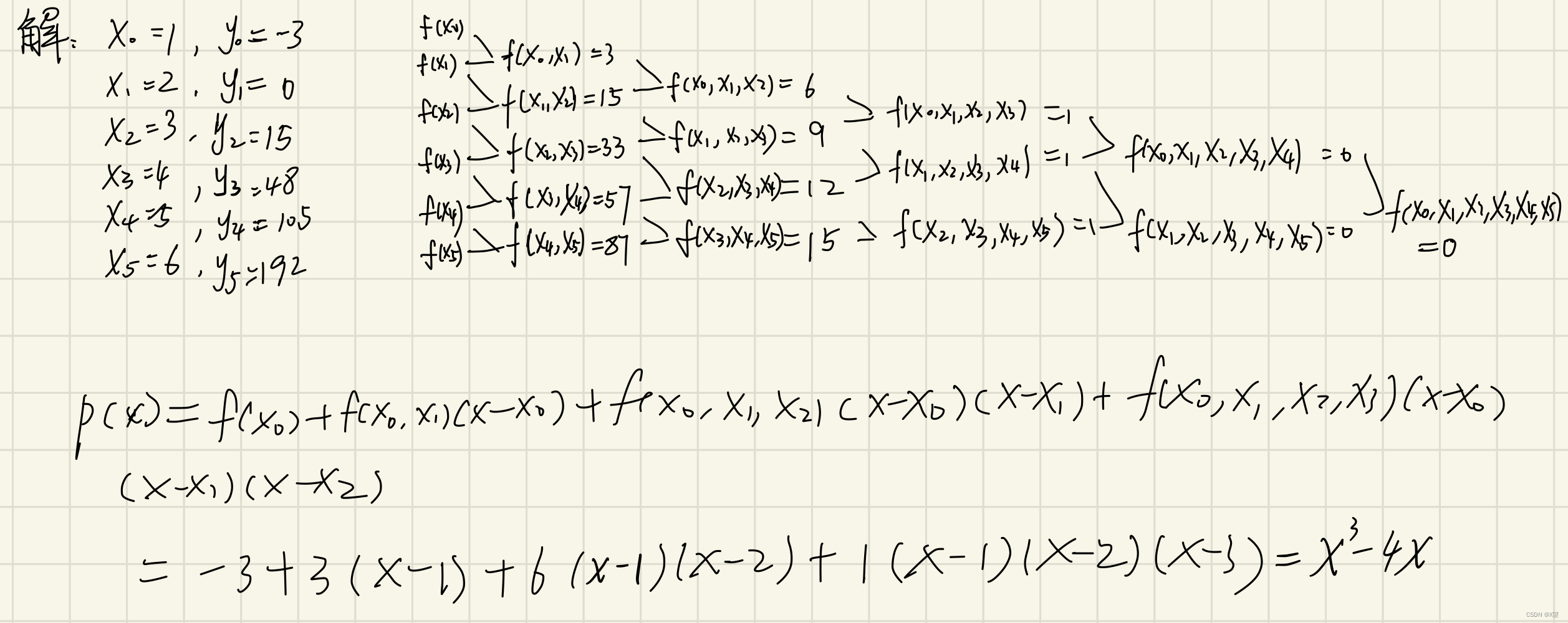
埃尔米特插值(切触插值)
意义:不仅满足插值节点处函数值相同,也满足(一阶)导数值相同。
最简单的方法其实是待定系数法,即先将函数设出来,再把题目所给条件代入,求解出系数。
这里提出两点三次Hermit插值公式。 (有能力尽可能记下来。)
插值条件:知
f
(
x
0
)
,
f
′
(
x
0
)
,
f
(
x
1
)
,
f
′
(
x
1
)
f(x_{0}),f^{'}(x_{0}),f(x_{1}),f^{'}(x_{1})
f(x0),f′(x0),f(x1),f′(x1),求三次多项式。
令
h
=
x
1
−
x
0
h=x_{1}-x_{0}
h=x1−x0
则
P
3
(
x
)
=
y
0
φ
0
(
x
−
x
0
h
)
+
y
1
φ
1
(
x
−
x
0
h
)
+
h
y
0
′
ψ
0
(
x
−
x
0
h
)
+
h
y
1
′
ψ
1
(
x
−
x
0
h
)
P_{3}(x)=y_{0}\varphi_{0}(\frac{x-x_{0}}{h})+y_{1}\varphi_{1}(\frac{x-x_{0}}{h})+hy^{'}_{0}\psi _{0}(\frac{x-x_{0}}{h})+hy^{'}_{1}\psi _{1}(\frac{x-x_{0}}{h})
P3(x)=y0φ0(hx−x0)+y1φ1(hx−x0)+hy0′ψ0(hx−x0)+hy1′ψ1(hx−x0)
φ
0
(
x
)
=
(
x
−
1
)
2
(
2
x
+
1
)
,
φ
1
(
x
)
=
x
2
(
−
2
x
+
3
)
\varphi_{0}(x)=(x-1)^{2}(2x+1),\varphi_{1}(x)=x^{2}(-2x+3)
φ0(x)=(x−1)2(2x+1),φ1(x)=x2(−2x+3)
ψ
0
(
x
)
=
x
(
x
−
1
)
2
,
ψ
1
(
x
)
=
x
2
(
x
−
1
)
\psi _{0}(x)=x(x-1)^{2},\psi _{1}(x)=x^{2}(x-1)
ψ0(x)=x(x−1)2,ψ1(x)=x2(x−1)
分段插值
龙格现象
龙格现象:当n增大时,插值函数
P
n
(
x
)
P_{n}(x)
Pn(x)在两端会发生激烈的震荡。因此,在大范围内使用高次插值,逼近的效果往往不理想。
解决龙格现象:分段低次插值,对每两个数据点之间的小区间进行低次多项式插值。
分段插值的意义是解决龙格现象。
分段线性插值
将所有数据点用折线连起来。
分段三次Hermit插值
在每个小区间进行两点三次 Hermit插值。
三次样条插值
满足插值函数二阶连续可导。
给出
f
(
x
0
)
,
f
(
x
1
)
,
f
(
x
1
)
,
⋯
f(x_{0}),f(x_{1}),f(x_{1}),\cdots
f(x0),f(x1),f(x1),⋯
易知若有n段小区间,则有4n个未知量,但仅有 4n-2个方程,故需补充2个边界条件。
第一类边界条件:给定两端一阶导数值。
S
′
(
x
0
+
)
=
f
0
′
,
S
′
(
x
n
−
)
=
f
n
′
S^{'}(x_{0}^{+})=f^{'}_{0},S^{'}(x_{n}^{-})=f^{'}_{n}
S′(x0+)=f0′,S′(xn−)=fn′。
第二类边界条件:给定两端二阶导数值。
S
′
′
(
x
0
+
)
=
f
0
′
′
,
S
′
′
(
x
n
−
)
=
f
n
′
′
S^{''}(x_{0}^{+})=f^{''}_{0},S^{''}(x_{n}^{-})=f^{''}_{n}
S′′(x0+)=f0′′,S′′(xn−)=fn′′。
f
0
′
′
=
f
n
′
′
=
0
f^{''}_{0}=f^{''}_{n}=0
f0′′=fn′′=0称为自然边界条件
第三类边界条件:周期边界条件,即
x
n
−
x
0
x_{n}-x_{0}
xn−x0是一个周期。
(其实三次样条插值速成的话了解这些就够了,如果真的碰到了题目要算,待定系数法还是yyds。公式法太复杂,速成的话不建议去记。)
曲线拟合
设法构造⼀条曲线(即拟合曲线)反映所给数据点总的趋势,以消除所给数据的局部波动。
直线拟合的最小二乘法
设所给数据点
(
x
i
,
y
i
)
,
(
i
=
1
,
2
,
⋯
,
N
)
(x_{i},y_{i}),(i=1,2,\cdots,N)
(xi,yi),(i=1,2,⋯,N)的分布大致成一条直线,
N
≫
2
N\gg2
N≫2
则
y
^
=
a
+
b
x
i
,
i
=
1
,
2
,
⋯
,
N
\hat{y}=a+bx_{i},i=1,2,\cdots,N
y^=a+bxi,i=1,2,⋯,N,表示拟合直线
残差:
e
i
=
y
−
y
i
^
e_{i}=y-\hat{y_{i}}
ei=y−yi^,衡量拟合好坏的重要标志
三大准则:
(1)
m
a
x
i
∣
e
∣
=
m
i
n
\underset{i}{max}|e|=min
imax∣e∣=min
(2)
∑
i
∣
e
i
∣
=
m
i
n
\sum_{i}^{}|e_{i}|=min
∑i∣ei∣=min(最佳一致逼近)
(3)
∑
i
e
2
=
m
i
n
\sum_{i}^{}e^{2}=min
∑ie2=min(最佳平方逼近,最小二乘)
直线拟合的最小二乘法求解
{ a N + b ∑ x i = ∑ y i a ∑ x i + b ∑ x i 2 = ∑ x i y i ⇒ { a = b = \left\{\begin{matrix} aN+b\sum x_{i}=\sum y_{i} \\a\sum x_{i}+b\sum x_{i}^{2}=\sum x_{i}y_{i} \end{matrix}\right.\Rightarrow \left\{\begin{matrix} a= \\b= \end{matrix}\right. {aN+b∑xi=∑yia∑xi+b∑xi2=∑xiyi⇒{a=b=
第二章 数值积分
机械求积公式的形式
梯形公式: ∫ a b f ( x ) d x ≈ ( b − a ) [ f ( a ) + f ( b ) ] 2 \int_{a}^{b}f(x)dx\approx (b-a)\frac{[f(a)+f(b)]}{2} ∫abf(x)dx≈(b−a)2[f(a)+f(b)] 一次代数精度
中矩形公式: ∫ a b f ( x ) d x ≈ ( b − a ) f ( a + b 2 ) \int_{a}^{b}f(x)dx\approx (b-a)f(\frac{a+b}{2}) ∫abf(x)dx≈(b−a)f(2a+b) 一次代数精度
辛普生公式: ∫ a b f ( x ) d x ≈ ( b − a ) [ f ( a ) + 4 f ( a + b 2 ) + f ( b ) ] 6 \int_{a}^{b}f(x)dx\approx (b-a)\frac{[f(a)+4f(\frac{a+b}{2})+f(b)]}{6} ∫abf(x)dx≈(b−a)6[f(a)+4f(2a+b)+f(b)] 三次代数精度
机械求积的一般形式: ∫ a b f ( x ) d x ≈ ∑ k = 0 n A k f ( x k ) \int_{a}^{b}f(x)dx\approx \sum_{k=0}^{n}A_{k}f(x_{k}) ∫abf(x)dx≈∑k=0nAkf(xk)
x k : x_{k}: xk: 求积节点; A k : A_{k}: Ak: 求积系数/伴随求积节点 x k x_{k} xk的权。
优点:仅为具体函数值的计算,避开求原函数。
代数精度
概念:若求积公式对一切次数 ≤ m的多项式准确,但对m+1次多项式不准确,称它具有 m次代数精度。
代数精度例题
教材P80例1
试检验下列求积公式的代数精度。
∫
0
1
f
(
x
)
d
x
≈
2
3
f
(
1
4
)
−
1
3
f
(
1
2
)
+
2
3
f
(
3
4
)
\int_{0}^{1}f(x)dx\approx \frac{2}{3}f(\frac{1}{4})-\frac{1}{3}f(\frac{1}{2})+\frac{2}{3}f(\frac{3}{4})
∫01f(x)dx≈32f(41)−31f(21)+32f(43)

求积公式的设计
即确定求积公式的未知系数。
基于代数精度进行设计,并需指明构造出的求积公式实际的精度。
注:充分利用对称性。
求积公式设计例题
教材P82,T1
试设计求积公式
∫
0
1
f
(
x
)
d
x
≈
A
0
f
(
1
4
)
+
A
1
f
(
1
2
)
+
A
2
f
(
3
4
)
\int_{0}^{1}f(x)dx\approx A_{0}f(\frac{1}{4})+A_{1}f(\frac{1}{2})+A_{2}f(\frac{3}{4})
∫01f(x)dx≈A0f(41)+A1f(21)+A2f(43)

教材P81,T4
构造下列形式的插值型求积公式,并指明代数精度。
∫
0
1
f
(
x
)
d
x
≈
A
0
f
(
1
4
)
+
A
1
f
(
1
2
)
+
A
2
f
(
3
4
)
\int_{0}^{1}f(x)dx\approx A_{0}f(\frac{1}{4})+A_{1}f(\frac{1}{2})+A_{2}f(\frac{3}{4})
∫01f(x)dx≈A0f(41)+A1f(21)+A2f(43)

插值型求积公式系数计算:
A
k
=
∫
0
1
l
k
(
x
)
d
x
A_{k}=\int_{0}^{1}l_{k}(x)dx
Ak=∫01lk(x)dx,
l
k
(
x
)
l_{k}(x)
lk(x)为拉格朗日插值基函数。
等步长机械求积公式
等步长:求积节点间距相等
柯特斯公式: C = 1 90 [ 7 f ( x 0 ) + 32 f ( x 1 ) + 12 f ( x 2 ) + 32 f ( x 3 ) + 7 f ( x 4 ) ] C=\frac{1}{90}[7f(x_{0})+32f(x_{1})+12f(x_{2})+32f(x_{3})+7f(x_{4})] C=901[7f(x0)+32f(x1)+12f(x2)+32f(x3)+7f(x4)]。
复化梯形公式: T n = h 2 [ f ( a ) + 2 ∑ i = 1 n − 1 f ( x i ) + f ( b ) ] T_{n}=\frac{h}{2}[f(a)+2\sum_{i=1}^{n-1}f(x_{i})+f(b)] Tn=2h[f(a)+2∑i=1n−1f(xi)+f(b)]。
复化辛普生公式: S n = h 6 [ f ( a ) + 4 ∑ i = 1 n − 1 f ( x i + 1 2 ) + 2 ∑ i = 1 n − 1 f ( x i ) + f ( b ) ] S_{n}=\frac{h}{6}[f(a)+4\sum_{i=1}^{n-1}f(x_{i+\frac{1}{2}})+2\sum_{i=1}^{n-1}f(x_{i})+f(b)] Sn=6h[f(a)+4∑i=1n−1f(xi+21)+2∑i=1n−1f(xi)+f(b)]。 ( x i + 1 2 x_{i+\frac{1}{2}} xi+21为 x k x_{k} xk与 x k + 1 x_{k+1} xk+1中点)
等步长机械求积公式例题
P95,T9
设已给出
f
(
x
)
=
1
+
e
−
x
s
i
n
4
x
f(x)=1+e^{-x}sin4x
f(x)=1+e−xsin4x的数据表
| x x x | 0.00 | 0.25 | 0.50 | 0.75 | 1.00 |
|---|---|---|---|---|---|
| f ( x ) f(x) f(x) | 1.00000 | 1.65534 | 1.55152 | 1.06666 | 0.72159 |
分别用复化梯形法,复化辛普生法与柯特斯法求积分
I
=
∫
0
1
f
(
x
)
d
x
I=\int_{0}^{1}f(x)dx
I=∫01f(x)dx的近似值。

龙贝格算法(变步长加速求积)
龙贝格公式(线性组合实现加速):
T 2 n = 1 2 T n + h 2 ∑ k = 0 n − 1 f ( x k + 1 2 ) T_{2n}=\frac{1}{2}T_{n}+\frac{h}{2}\sum_{k=0}^{n-1}f(x_{k+\frac{1}{2}}) T2n=21Tn+2h∑k=0n−1f(xk+21)
S n = 4 3 T 2 n − 1 3 T n S_{n}=\frac{4}{3}T_{2n}-\frac{1}{3}T_{n} Sn=34T2n−31Tn
C n = 16 15 S 2 n − 1 15 S n C_{n}=\frac{16}{15}S_{2n}-\frac{1}{15}S_{n} Cn=1516S2n−151Sn
R n = 64 63 C 2 n − 1 63 C n R_{n}=\frac{64}{63}C_{2n}-\frac{1}{63}C_{n} Rn=6364C2n−631Cn
高斯公式
选取求积节点
x
k
(
k
=
1
,
2
,
⋯
,
n
)
x_{k}(k=1,2,\cdots,n)
xk(k=1,2,⋯,n)使
∫
−
1
1
f
(
x
)
d
x
≈
∑
k
=
1
n
A
k
f
(
x
k
)
\int_{-1}^{1}f(x)dx\approx \sum_{k=1}^{n}A_{k}f(x_{k})
∫−11f(x)dx≈∑k=1nAkf(xk)有
2
n
−
1
2n-1
2n−1 次代数精度,则为高斯型求积公式(是代数精度最高的求积公式)。
x
k
x_{k}
xk:高斯点,
A
k
A_{k}
Ak:高斯系数
一点高斯公式: ∫ − 1 1 f ( x ) d x ≈ 2 f ( 0 ) \int_{-1}^{1}f(x)dx\approx 2f(0) ∫−11f(x)dx≈2f(0)
两点高斯公式: ∫ − 1 1 f ( x ) d x ≈ f ( − 1 3 ) + f ( 1 3 ) \int_{-1}^{1}f(x)dx\approx f(-\frac{1}{\sqrt{3}})+f(\frac{1}{\sqrt{3}}) ∫−11f(x)dx≈f(−31)+f(31)
三点高斯公式: ∫ − 1 1 f ( x ) d x ≈ 5 9 f ( − 3 5 ) + 8 9 f ( 0 ) + 5 9 f ( 3 5 ) \int_{-1}^{1}f(x)dx\approx \frac{5}{9}f(-\sqrt{\frac{3}{5}})+\frac{8}{9}f(0)+\frac{5}{9}f(\sqrt{\frac{3}{5}}) ∫−11f(x)dx≈95f(−53)+98f(0)+95f(53)
-如何找到高斯点-(了解即可)
ω
=
(
x
−
x
1
)
(
x
−
x
2
)
⋯
(
x
−
x
n
)
\omega =(x-x_{1})(x-x_{2})\cdots (x-x_{n})
ω=(x−x1)(x−x2)⋯(x−xn)
∫
−
1
1
P
(
x
)
ω
(
x
)
d
x
=
0
\int_{-1}^{1}P(x)\omega(x)dx=0
∫−11P(x)ω(x)dx=0,即
ω
(
x
)
\omega (x)
ω(x)与⼀切次数
⩽
n
−
1
\leqslant n-1
⩽n−1的多项式
P
(
x
)
P(x)
P(x)正交。
勒让德多项式
(个人感觉不重要)
P
n
(
x
)
=
n
!
(
2
n
)
!
d
n
d
x
n
[
(
x
2
−
1
)
n
]
P_{n}(x)=\frac{n!}{(2n)!}\frac{d^{n}}{d_{x}^{n}}[(x^{2}-1)^{n}]
Pn(x)=(2n)!n!dxndn[(x2−1)n]
A
n
=
2
(
1
−
x
n
2
)
[
p
n
′
(
x
n
)
]
2
A_{n}=\frac{2}{(1-x_{n}^{2})[p_{n}^{'}(x_{n})]^{2}}
An=(1−xn2)[pn′(xn)]22
第三章 常微分方程的差分方法
基本概念
常微分方程求解:
{
y
′
=
f
(
x
,
y
)
y
(
x
0
)
=
y
0
\left\{\begin{matrix} y^{'}=f(x,y) \\y(x_{0})=y_{0} \end{matrix}\right.
{y′=f(x,y)y(x0)=y0 ,求
y
n
y_{n}
yn。
相关定义:
原函数
y
(
x
)
y(x)
y(x),导函数
f
(
x
,
y
)
f(x,y)
f(x,y),准确值
y
(
x
n
)
y(x_{n})
y(xn),近似值
y
n
y_{n}
yn。
单步法 : 计算
y
n
+
1
y_{n+1}
yn+1时只⽤到
y
n
y_{n}
yn
多步法 : 要用前面两个或两个以上的信息量。
整体截断误差:
y
(
x
i
+
1
)
−
y
i
+
1
y(x_{i+1})-y_{i+1}
y(xi+1)−yi+1
局部截断误差:
y
(
x
i
+
1
)
−
[
y
(
x
i
)
+
h
f
(
x
i
,
y
(
x
i
)
)
]
y(x_{i+1})-[y(x_{i})+hf(x_{i},y(x_{i}))]
y(xi+1)−[y(xi)+hf(xi,y(xi))]
欧拉方法
{ 显式: y n + 1 = y n + h f ( x n , y n ) , ( 单步 ) 隐式: y n + 1 = y n + h f ( x n + 1 , y ( x n + 1 ) ) , ( 单步 ) 两步欧拉: y n + 1 = y n − 1 + 2 h f ( x n , y n ) ,(二阶) 梯形欧拉: y n + 1 = y n + h 2 [ f ( x n , y n ) , f ( x n + 1 , y n + 1 ) ] ,(单步) \left\{\begin{matrix} 显式:y_{n+1}=y_{n}+hf(x_{n},y_{n}),(单步) \\隐式:y_{n+1}=y_{n}+hf(x_{n+1},y(x_{n+1})),(单步) \\两步欧拉:y_{n+1}=y_{n-1}+2hf(x_{n},y_{n}),(二阶) \\梯形欧拉:y_{n+1}=y_{n}+\frac{h}{2}[f(x_{n},y_{n}),f(x_{n+1},y_{n+1})],(单步) \end{matrix}\right. ⎩ ⎨ ⎧显式:yn+1=yn+hf(xn,yn),(单步)隐式:yn+1=yn+hf(xn+1,y(xn+1)),(单步)两步欧拉:yn+1=yn−1+2hf(xn,yn),(二阶)梯形欧拉:yn+1=yn+2h[f(xn,yn),f(xn+1,yn+1)],(单步)
欧拉方法例题
教材P124,T3
取
h
=
0.1
h=0.1
h=0.1用欧拉方法求解初值问题
{
y
′
=
1
1
+
x
2
−
2
y
2
y
(
0
)
=
0
\left\{\begin{matrix} y^{'}=\frac{1}{1+x^{2}}-2y^{2} \\y(0)=0 \end{matrix}\right.
{y′=1+x21−2y2y(0)=0,并与精确解
y
=
x
1
+
x
2
y=\frac{x}{1+x^{2}}
y=1+x2x比较计算结果。

改进的欧拉:
{ y ‾ n + 1 = y n + h f ( x n , y n ) y n + 1 = y n + h 2 [ f ( x n , y n ) , f ( x n + 1 , y ‾ n + 1 ) ] \left\{\begin{matrix} \overline{y}_{n+1}=y_{n}+hf(x_{n},y_{n}) \\y_{n+1}=y_{n}+\frac{h}{2}[f(x_{n},y_{n}),f(x_{n+1},\overline{y}_{n+1})] \end{matrix}\right. {yn+1=yn+hf(xn,yn)yn+1=yn+2h[f(xn,yn),f(xn+1,yn+1)] 显式
即(计算用):
{ y p = y n + h f ( x n , y n ) y c = y n + h f ( x n + 1 , y p ) y n + 1 = 1 2 ( y p + y c ) {\color{Red} \left\{\begin{matrix} y_{p}=y_{n}+hf(x_{n},y_{n}) \\y_{c}=y_{n}+hf(x_{n+1},y_{p}) \\y_{n+1}=\frac{1}{2}(y_{p}+y_{c}) \end{matrix}\right.} ⎩ ⎨ ⎧yp=yn+hf(xn,yn)yc=yn+hf(xn+1,yp)yn+1=21(yp+yc)
经典四阶R-K
{ y n + 1 = y n + h 6 ( k 1 + 2 k 2 + 2 k 3 + k 4 ) k 1 = f ( x n , y n ) k 2 = f ( x n + h 2 , y n + h 2 k 1 ) k 3 = f ( x n + h 2 , y n + h 2 k 2 ) k 4 = f ( x n + h , y n + h k 3 ) \left\{\begin{matrix} y_{n+1}=y_{n}+\frac{h}{6}(k_{1}+2k_{2}+2k_{3}+k_{4}) \\k_{1}=f(x_{n},y_{n}) \\k_{2}=f(x_{n}+\frac{h}{2},y_{n}+\frac{h}{2}k_{1}) \\k_{3}=f(x_{n}+\frac{h}{2},y_{n}+\frac{h}{2}k_{2}) \\k_{4}=f(x_{n}+h,y_{n}+hk_{3}) \end{matrix}\right. ⎩ ⎨ ⎧yn+1=yn+6h(k1+2k2+2k3+k4)k1=f(xn,yn)k2=f(xn+2h,yn+2hk1)k3=f(xn+2h,yn+2hk2)k4=f(xn+h,yn+hk3)
方法的评估
方法的收敛性(截断误差):均收敛
方法的稳定性(舍入误差):
{
显式:条件稳定
隐式:绝对稳定
\left\{\begin{matrix} 显式:条件稳定 \\隐式:绝对稳定 \end{matrix}\right.
{显式:条件稳定隐式:绝对稳定
第四章 非线性方程求根的迭代法
基本概念
非线性方程求根:求
f
(
x
)
=
0
f(x)=0
f(x)=0的根。
迭代法:使用迭代公式反复校正根的近似值,逐次逼近精确值,直到满足精度要求。
原理:对于
f
(
x
)
=
0
f(x)=0
f(x)=0,一般变形为
x
=
φ
(
x
)
→
迭代函数
x=\varphi (x)\to 迭代函数
x=φ(x)→迭代函数
则有
x
1
=
φ
(
x
0
)
,
x
2
=
φ
(
x
1
)
,
⋯
x_{1}=\varphi (x_{0}),x_{2}=\varphi (x_{1}),\cdots
x1=φ(x0),x2=φ(x1),⋯
即
x
k
+
1
=
φ
(
x
k
)
,
k
=
0
,
1
,
2
,
⋯
→
迭代公式
x_{k+1}=\varphi (x_{k}),k=0,1,2,\cdots\to 迭代公式
xk+1=φ(xk),k=0,1,2,⋯→迭代公式
若
x
k
x_{k}
xk收敛,则
x
∗
=
lim
k
→
∞
x
k
x^{\ast }=\displaystyle \lim_{k \to \infty }x_{k}
x∗=k→∞limxk即为
f
(
x
)
=
0
f(x)=0
f(x)=0的根。
迭代函数的收敛性
压缩映像原理
设
φ
(
x
)
\varphi(x)
φ(x)在
[
a
,
b
]
[a,b]
[a,b]上具有连续一阶导数,且
(1)
∀
x
∈
[
a
,
b
]
,
φ
(
x
)
∈
[
a
,
b
]
\forall x\in[a,b],\varphi(x)\in[a,b]
∀x∈[a,b],φ(x)∈[a,b]
(2)
∃
0
⩽
L
<
1
\exists 0\leqslant L<1
∃0⩽L<1,对
∀
x
∈
[
a
,
b
]
\forall x\in[a,b]
∀x∈[a,b],有
∣
φ
′
(
x
)
∣
⩽
L
<
1
|\varphi^{'}(x)|\leqslant L<1
∣φ′(x)∣⩽L<1,
则收敛。(
L
L
L越小,收敛越快)
-误差估计-
{
事后:
∣
x
∗
−
x
k
∣
⩽
1
1
−
L
∣
x
k
+
1
−
x
k
∣
事先:
∣
x
∗
−
x
k
∣
⩽
x
∗
1
−
L
∣
x
1
−
x
0
∣
\left\{\begin{matrix} 事后:|x^{\ast }-x_{k}|\leqslant \frac{1}{1-L}|x_{k+1}-x_{k}| \\事先:|x^{\ast }-x_{k}|\leqslant \frac{x^{\ast }}{1-L}|x_{1}-x_{0}| \end{matrix}\right.
{事后:∣x∗−xk∣⩽1−L1∣xk+1−xk∣事先:∣x∗−xk∣⩽1−Lx∗∣x1−x0∣
局部收敛定理
设 φ ( x ) \varphi(x) φ(x)在 x = φ ( x ) x=\varphi(x) x=φ(x)的根 x ∗ x^{\ast } x∗邻近处有连续的一阶导数,且 ∣ φ ′ ( x ∗ ) ∣ < 1 |\varphi^{'}(x^{\ast})|<1 ∣φ′(x∗)∣<1,则 x k + 1 x_{k+1} xk+1在 x ∗ x^{\ast} x∗邻近处有局部收敛性。
-局部收敛定理的证明-
平方收敛速度
迭代误差:
e
k
=
x
∗
−
x
k
e_{k}=x^{\ast}-x_{k}
ek=x∗−xk
若
e
k
+
1
e
k
p
→
c
,
(
c
为
≠
0
常数
)
\frac{e_{k+1}}{e^{p}_{k}}\to c,(c为\neq0常数)
ekpek+1→c,(c为=0常数),则称迭代过程
p
p
p阶收敛。
p
=
2
p=2
p=2时为平方收敛,此时
φ
′
(
x
∗
)
=
0
,
φ
(
′
′
)
(
x
∗
)
≠
0
\varphi^{'}(x^{\ast})=0,\varphi^{('')}(x^{\ast})\neq0
φ′(x∗)=0,φ(′′)(x∗)=0。
-平方收敛速度的证明-
证:
x
∗
−
x
k
−
1
=
φ
′
(
ξ
)
(
x
∗
−
x
k
)
,
ξ
x^{\ast }-x_{k-1}=\varphi^{'}(\xi )(x^{\ast }-x_{k}),\xi
x∗−xk−1=φ′(ξ)(x∗−xk),ξ界于
x
∗
与
x
k
x^{\ast}与x_{k}
x∗与xk之间且小于1。
若
φ
′
(
x
∗
)
=
0
\varphi^{'}(x^{\ast} )=0
φ′(x∗)=0
将
φ
(
x
k
)
在
x
∗
\varphi(x_{k})在x^{\ast}
φ(xk)在x∗处泰勒展开有
φ
(
x
k
)
=
φ
(
x
∗
)
+
f
′
′
(
ξ
)
2
(
x
k
−
x
∗
)
2
\varphi(x_{k})=\varphi(x^{\ast})+\frac{f^{''(\xi)}}{2}(x_{k}-x^{\ast})^{2}
φ(xk)=φ(x∗)+2f′′(ξ)(xk−x∗)2
即
x
k
−
1
−
x
∗
(
x
k
−
x
∗
)
2
=
f
′
′
(
ξ
)
2
\frac{x_{k-1}-x^{\ast}}{(x_{k}-x^{\ast})^{2}}=\frac{f^{''}(\xi)}{2}
(xk−x∗)2xk−1−x∗=2f′′(ξ)
即
e
k
+
1
e
k
2
→
f
′
′
(
ξ
)
2
\frac{e_{k+1}}{e^{2}_{k}}\to \frac{f^{''}(\xi)}{2}
ek2ek+1→2f′′(ξ)
∴
当
φ
′
(
x
∗
)
=
0
,
φ
(
′
′
)
(
x
∗
)
≠
0
时平方收敛。
\therefore当\varphi^{'}(x^{\ast})=0,\varphi^{('')}(x^{\ast})\neq0时平方收敛。
∴当φ′(x∗)=0,φ(′′)(x∗)=0时平方收敛。
牛顿迭代法
φ ( x ) = x − f ( x ) f ′ ( x ) \varphi(x)=x-\frac{f(x)}{f^{'}(x)} φ(x)=x−f′(x)f(x)
牛顿迭代法的收敛速度至少为平方收敛
牛顿迭代法例题
P137,例5
用牛顿法解方程
x
e
x
−
1
=
0
xe^{x}-1=0
xex−1=0。

牛顿下山法
为防止迭代发散,新加条件 ∣ f ( x k + 1 ) ∣ < ∣ f ( x k ) ∣ |f(x_{k+1})|<|f(x_{k})| ∣f(xk+1)∣<∣f(xk)∣,
则 x k + 1 = x k − λ f ( x k ) f ′ ( x k ) x_{k+1}=x_{k}-\lambda \frac{f(x_{k})}{f^{'}(x_{k})} xk+1=xk−λf′(xk)f(xk)
其中
0
<
λ
⩽
1
0<\lambda\leqslant1
0<λ⩽1称作下山因子,适当选取
λ
\lambda
λ使新加条件成立
选好
x
0
x_{0}
x0后,
λ
\lambda
λ从1开始减半试算,成立则下山成功;若一直不成立,则下山失败,需重选
x
0
x_{0}
x0。
快速弦截法
x k + 1 = x k − f ( x k ) f ( x k ) − f ( x k − 1 ) ( x k − x k − 1 ) x_{k+1}=x_{k}-\frac{f(x_{k})}{f(x_{k})-f(x_{k-1})}(x_{k}-x_{k-1}) xk+1=xk−f(xk)−f(xk−1)f(xk)(xk−xk−1),(两步法)
第六章 线性方程组的直接解法
(将第六章提前讲,作为迭代法的引入。)
线性方程组 A x = b Ax=b Ax=b存在唯一解,求解线性方程组。
直接法:Gauss消去法(需主元全不为0)。(学了线代的应该都会吧,这里就不详细说了😊)
升级版:列主元Gauss消去法。在第K步消元时,在第K列的剩余部分选取主元(选取绝对值最大主元,然后行交换)
多一些比较环节,但算法更稳定,应用最广泛。复杂度:
O
(
n
3
)
O(n^{3})
O(n3)
补充版(不常用):全主元 Gauss 消去法:一开始就完成所有列的主元选择。
第五章 线性方程组的迭代法
直接法的缺点:1.计算量大;2.无法利用系数矩阵的稀疏性。
雅可比迭代公式 (Jacobi)
x i ( k + 1 ) = 1 a i i ( b i − ∑ j = 1 , j ≠ i n a i j x j ( k ) ) , i = 1 , 2 , ⋯ , n x_{i}^{(k+1)}=\frac{1}{a_{ii}}(b_{i}-\sum_{j=1,j\neq i}^{n}a_{ij}x_{j}^{(k)}),i=1,2,\cdots ,n xi(k+1)=aii1(bi−∑j=1,j=inaijxj(k)),i=1,2,⋯,n
高斯-赛德尔迭代(G-S)
用前面已经计算出的新值立刻代替后面的值。
x i ( k + 1 ) = 1 a i i ( b i − ∑ j = 1 i − 1 a i j x j ( k + 1 ) − ∑ j = i + 1 n a i j x j ( k ) ) , i = 1 , 2 , ⋯ , n x_{i}^{(k+1)}=\frac{1}{a_{ii}}(b_{i}-\sum_{j=1}^{i-1}a_{ij}x_{j}^{(k+1)}-\sum_{j=i+1}^{n}a_{ij}x_{j}^{(k)}),i=1,2,\cdots ,n xi(k+1)=aii1(bi−∑j=1i−1aijxj(k+1)−∑j=i+1naijxj(k)),i=1,2,⋯,n
求解线性方程组例题
P156,例1
求解线性方程组
{
10
x
1
−
x
2
−
2
x
3
=
7.2
−
x
1
+
10
x
2
−
2
x
3
=
8.3
−
x
1
−
x
2
+
5
x
3
=
4.2
\left\{\begin{matrix} 10x_{1}-x_{2}-2x_{3}=7.2 \\-x_{1}+10x_{2}-2x_{3}=8.3 \\-x_{1}-x_{2}+5x_{3}=4.2 \end{matrix}\right.
⎩
⎨
⎧10x1−x2−2x3=7.2−x1+10x2−2x3=8.3−x1−x2+5x3=4.2
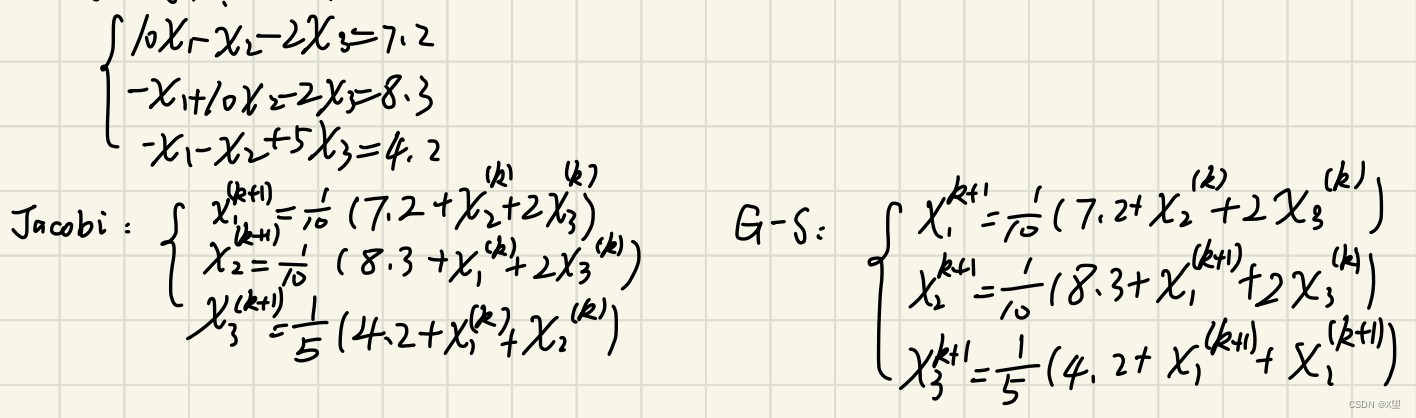
超松弛法(G-S的加速)
将
x
(
k
)
x^{(k)}
x(k)与G-S得
x
(
k
+
1
)
x^{(k+1)}
x(k+1)加权平均
得
x
i
(
k
+
1
)
=
(
1
−
ω
)
x
i
(
k
)
+
ω
a
i
i
(
b
i
−
∑
j
=
1
i
−
1
a
i
j
x
j
(
k
+
1
)
−
∑
j
=
i
+
1
n
a
i
j
x
j
(
k
)
)
,
i
=
1
,
2
,
⋯
,
n
x_{i}^{(k+1)}=(1-\omega )x_{i}^{(k)}+\frac{\omega }{a_{ii}}(b_{i}-\sum_{j=1}^{i-1}a_{ij}x_{j}^{(k+1)}-\sum_{j=i+1}^{n}a_{ij}x_{j}^{(k)}),i=1,2,\cdots ,n
xi(k+1)=(1−ω)xi(k)+aiiω(bi−∑j=1i−1aijxj(k+1)−∑j=i+1naijxj(k)),i=1,2,⋯,n
ω
\omega
ω:松弛因子,
1
<
ω
<
2
1<\omega<2
1<ω<2
迭代法的矩阵表示
A x = b , 令 A = D − L − U , A = [ D − U − L D ] Ax=b,令A=D-L-U,A=\begin{bmatrix} D & -U\\ -L & D \\ \end{bmatrix} Ax=b,令A=D−L−U,A=[D−L−UD]
给定一个初始向量
x
(
k
)
x^{(k)}
x(k),可得迭代格式
x
(
k
+
1
)
=
B
x
(
k
)
+
f
,
k
=
0
,
1
,
2
,
⋯
x^{(k+1)}=Bx^{(k)}+f,k=0,1,2,\cdots
x(k+1)=Bx(k)+f,k=0,1,2,⋯
J
:
B
=
D
−
1
(
L
+
U
)
,
f
=
D
−
1
b
J:B=D^{-1}(L+U),f=D^{-1}b
J:B=D−1(L+U),f=D−1b
G
−
S
:
B
=
(
D
−
L
)
−
1
U
,
f
=
(
D
−
L
)
−
1
b
G-S:B=(D-L)^{-1}U,f=(D-L)^{-1}b
G−S:B=(D−L)−1U,f=(D−L)−1b
定理:对任意初始向量
x
(
0
)
x^{(0)}
x(0),收敛的充要条件为
ρ
(
B
)
<
1
\rho(B)<1
ρ(B)<1
定理:若存在算子范数使
∣
B
∣
<
1
|B|<1
∣B∣<1,则迭代格式收敛
迭代法的收敛性
范数:
向量范数:
∣
∣
x
∣
∣
2
||x||_{2}
∣∣x∣∣2
矩阵范数:
{
F
范数:
∣
A
∣
F
=
(
∑
i
=
1
n
∑
j
=
1
n
a
i
j
2
)
1
2
1
范数:
∣
A
∣
1
=
1
⩽
j
⩽
n
m
a
x
∑
i
=
1
n
∣
a
i
j
∣
(列范数)
x
2
范数:
∣
A
∣
2
=
p
(
A
T
A
)
(谱范数)
∞
范数:
∣
A
∣
∞
=
1
⩽
i
⩽
n
m
a
x
∑
j
=
1
n
∣
a
i
j
∣
(常范数)
\left\{\begin{matrix} F范数: |A|_{F}=(\sum_{i=1}^{n}\sum_{j=1}^{n}a_{ij}^{2})^{\frac{1}{2}} \\ 1范数: |A|_{1}=\underset{max}{1\leqslant j\leqslant n}\sum_{i=1}^{n}|a_{ij}| (列范数)\\ x^{2}范数: |A|_{2}=\sqrt{p(A^{T}A)} (谱范数)\\\infty范数: |A|_{\infty}=\underset{max}{1\leqslant i\leqslant n}\sum_{j=1}^{n}|a_{ij}|(常范数) \end{matrix}\right.
⎩
⎨
⎧F范数:∣A∣F=(∑i=1n∑j=1naij2)211范数:∣A∣1=max1⩽j⩽n∑i=1n∣aij∣(列范数)x2范数:∣A∣2=p(ATA)(谱范数)∞范数:∣A∣∞=max1⩽i⩽n∑j=1n∣aij∣(常范数)
范数的计算例题
A
=
(
1
−
2
−
3
4
)
A=\begin{pmatrix} 1 & -2 \\ -3 & 4 \\ \end{pmatrix}
A=(1−3−24),计算
∣
A
∣
F
,
∣
A
∣
1
,
∣
A
∣
2
,
∣
A
∣
∞
|A|_{F},|A|_{1},|A|_{2},|A|_{\infty}
∣A∣F,∣A∣1,∣A∣2,∣A∣∞

向量序列的收敛:
lim
k
→
∞
∣
∣
x
(
k
)
−
x
∗
∣
∣
2
=
0
\displaystyle \lim_{k \to \infty }||x^{(k)}-x^{\ast }||_{2}=0
k→∞lim∣∣x(k)−x∗∣∣2=0。
矩阵序列的收敛:
lim
k
→
∞
∣
A
k
−
A
∣
=
0
\displaystyle \lim_{k \to \infty }|A_{k}-A|=0
k→∞lim∣Ak−A∣=0,任一矩阵范数均可。
总结
至此,数值分析的内容基本结束了。在整理这篇博客的过程中,我熟悉了Markdown的语法,也重温了数值分析的知识。
感谢您能看到这里,文章中的错误或者您的相关问题,欢迎提出。另有电子版手写笔记,如需要也可以联系我无偿提供。祝学业有成! ╮(╯▽╰)╭

















 4002
4002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









