







目录
【PTA】图的邻接矩阵存储和遍历 见https://blog.csdn.net/2301_80216181/article/details/143446819?spm=1001.2014.3001.5501
1. 题目描述
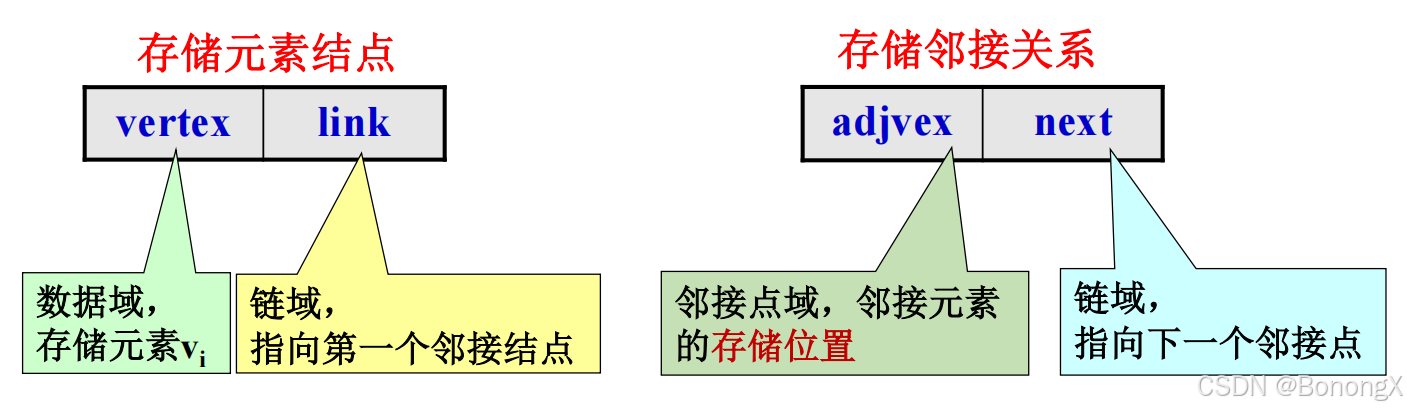
图的邻接表存储用一个一维数组存储各顶点数据元素,用边结点构成的单链表存储元素之间的邻接关系。
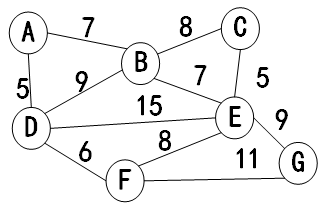
如上无向加权图,图中顶点数据元素为“A-Z”之间的单个字符,为了使遍历输出结果唯一,现要求顶点数据元素按由小到大(ASCII码)的顺序存储,单链表中的边结点同样按由小到大有序排列。例如,对于上述加权图,数据元素按照A、B、C、D、E、F、G 的顺序存储,在顶点A的边链表中,第1个是(A,B)边生成的边结点,第2个是(A,D)边生成的边结点。依附于边的权值为整数,且大于0。使用C或C++编写算法,实现:
(1)以领接表为存储结构,按照输入数据建立加权图;
(2)从第1个顶点出发(A),按照深度优先搜索算法输出各顶点数据;
(3)从第1个顶点出发(A),按照广度优先搜索算法输出各顶点数据;
(4)计算并输出个顶点的度,按顶点存储顺序输出。
1.1 输入格式
输入分为以下几行,第1行为图的顶点数,第2行为图的边数,第3行及以后为图的各个边依附的顶点及其权值。
1.2 输出格式
输出分为以下行,第1行为深度优先遍历序列,第2行为广度优先遍历序列,其后为各顶点及其度。
1.3 输入样例
如上图的输入格式为:
7
11
A B 7
A D 5
B C 8
B D 9
B E 7
C E 5
D E 15
D F 6
E F 8
E G 9
F G 11
1.4 输出样例
如上图的输出为:
DFS: A B C E D F G
BFS: A B D C E F G
A:2
B:4
C:2
D:4
E:5
F:3
G:2
其中"DFS:","BFS:","B:","C:"等为提示标志,序列" A B C E D F G"的每个字符前面有一个空格。
代码长度限制:16 KB
时间限制:400 ms
内存限制:64 MB
栈限制:8192 KB
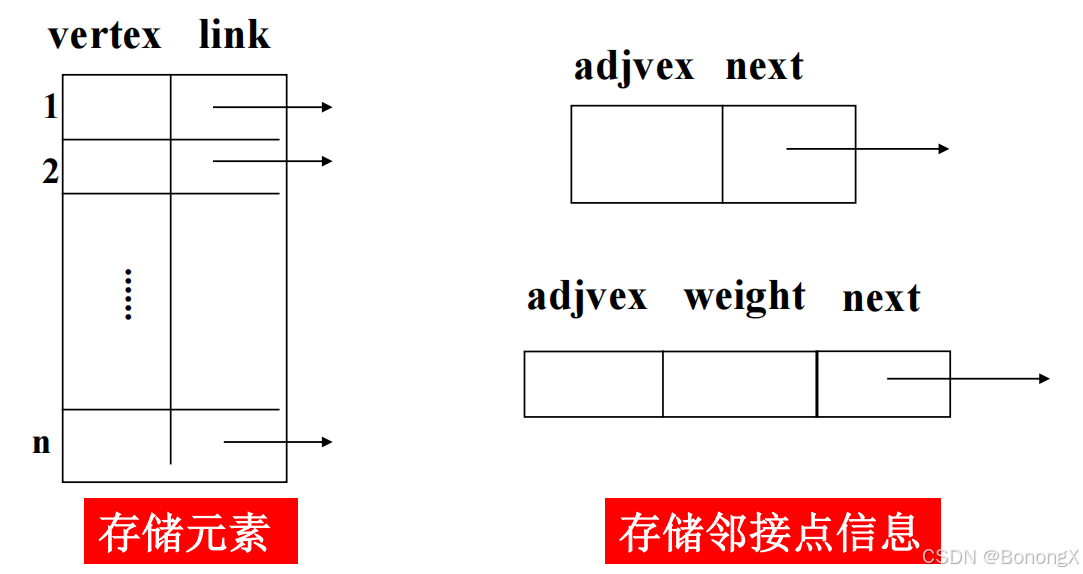
2. 图的邻接表存储结构
2.1 存储方式
用连续的地址空间存储图的数据元素,用单链表存储元素之间的
邻接
关系。
// 边的定义
typedef struct ENode{
int V1, V2; // 有向边<V1, V2>
int Weight; // 权重
}ENode, *PtrToENode;
typedef PtrToENode Edge;
// 邻接点的定义
typedef struct AdjVNode{
int AdjV; // 邻接点下标
int Weight; // 边权重
PtrToAdjVNode Next;// 指向下一个邻接点的指针
}AdjVNode, *PtrToAdjVNode;
// 顶点表头结点的定义
typedef struct Vnode{
PtrToAdjVNode FirstEdge; // 边表头指针
char Data; // 存顶点的数据
// 注意:很多情况下,顶点无数据,此时Data可以不用出现
} AdjList[MaxVertexNum]; // AdjList是邻接表类型
// 图结点的定义
typedef struct GNode{
int Nv; // 顶点数
int Ne; // 边数
AdjList G; // 邻接表
}GNode, *PtrToGNode;
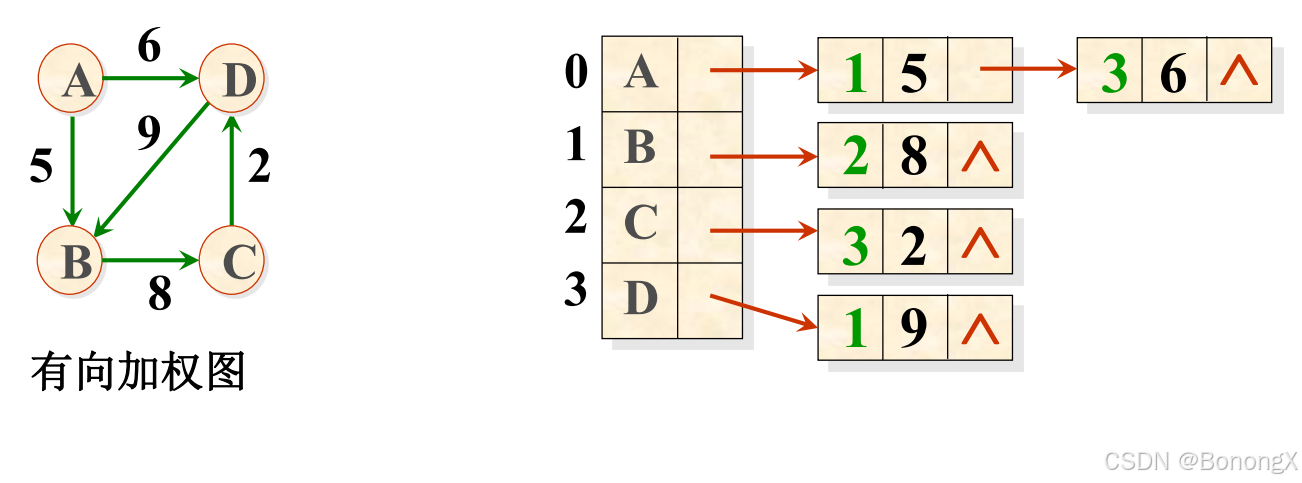
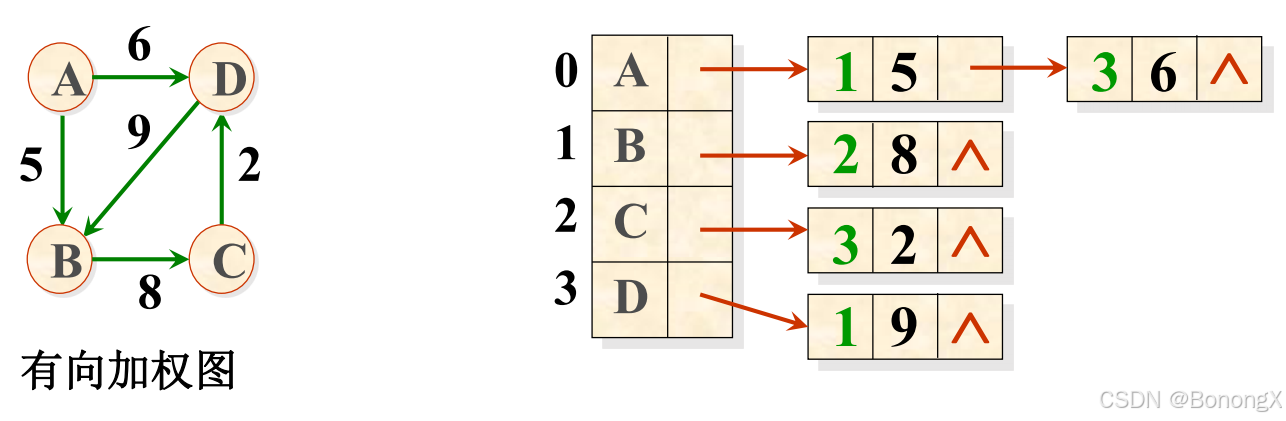
typedef PtrToGNode LGraph; // 以邻接表方式存储的图类型 2.2 举例
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 592
592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









