







switch语句
C++中的switch语句用于根据不同的条件执行相应的代码块。其语法如下:
switch (expression) {
case constant1:
// code block
break;
case constant2:
// code block
break;
...
default:
// code block
break;
}
switch语句首先对expression求值,expression是一个表达式,可以是整数、字符或枚举类型。
switch把expression表达式的值转换成整数类型,根据expression的值,程序执行与之匹配的case标签下的代码块。
如果表达式和某个case标签的值匹配成功,程序从该标签之后的第一条语句开始执行,直到到达了switch的结尾或者是遇到一条break语句为止。
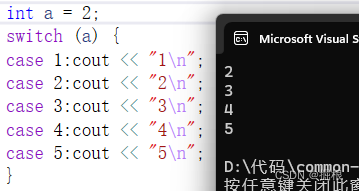
没有匹配成功,程序将执行default标签下的代码块。
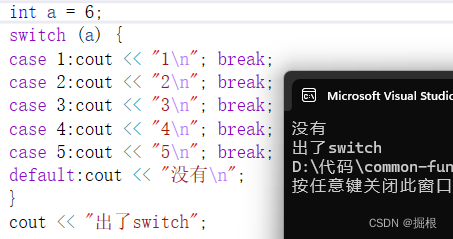
如果没有default标签,程序将跳过整个switch语句。

case语句
case关键字和它对应的值一起被称为case标签(case label)。case标签必须是整型常量表达式:
char ch = getval();
int ival =42;
switch(ch){
case 3.14://错误:case标签不是一个整数
case ival://错误:case标签不是一个常量
//..
任何两个case 标签的值不能相同,否则就会引发错误。

另外,default 也是一种特殊的case标签,关于它的知识将在下面介绍。
switch 内部的控制流
理解程序在case标签之间的执行流程非常重要。
如果某个case标签匹配成功,将从该标签开始往后顺序执行所有case分支,除非程序显式地中断了这一过程,否则直到switch的结尾处才会停下来。
要想避免执行后续case分支的代码,我们必须显式地告诉编译器终止执行过程。大多数情况下,在下一个case 标签之前应该有一条break语句。

然而,也有一些时候默认的switch行为才是程序真正需要的。
每个case标签只能对应一个值,但是有时候我们希望两个或更多个值共享同一组操作。
此时,我们就故意省略掉break语句,使得程序能够连续执行若干个case标签。
例如,也许我们想统计的是所有元音字母出现的总次数:
unsigned vowelCnt =0;
switch (ch){
//出现了a、e、i、o或u中的任意一个都会将vowelCnt的值加1
case 'a':
case 'e':
case 'i':
case ‘o':
case 'u':
++vowe1Cnt;
break;}
在上面的代码中,几个case标签连写在一起,中间没有break语句。因此只要ch是元音字母,不管到底是五个中的哪一个都执行相同的代码。
C++程序的形式比较自由,所以case标签之后不一定非得换行。把几个case标签写在一行里,强调这些case代表的是某个范围的值:
switch(ch)
{
//另一种合法的书写形式
case 'a':case 'e': case 'i':case 'o': case'u':
++vowe1Cnt;
break;
}
一般不要省略case分支最后的break语句。如果没写 break语句,最好一段注释说清楚程序的逻辑。
漏写break 容易引发缺陷
有一种常见的错觉是程序只执行匹配成功的那个case分支的语句。
例如,下面程序的统计结果是错误的:
// 警告:不正确的程序逻辑!
switch (ch) {
case 'a’: 个部
++aCnt;// 此处应该有一条 break语句
case 'e':
++eCnt;//此处应该有一条break语句 协
case 'i':
++iCnt;//此处应该有一条break语句
case 'o':
++oCnt;// 此处应该有一条 break语句
case‘u’;
++uCnt;
}
要想理解这段程序的执行过程,不妨假设ch的值是‘e'。此时,程序直接执行case'e标签后面的代码,该代码把eCnt的值加1。接下来,程序将跨越case标签的边界,接着递增iCnt、oCnt和uCnt。
尽管 switch 语句不是非得在最后一个标签后面写上 break,但是为了安全起见,最好这么做。因为这样的话,即使以后再增加新的case分支,也不用再在前面补充break 语句了。
default标签
如果没有任何一个 case 标签能匹配上switch表达式的值,程序将执行紧跟在default 标签(default label)后面的语句。
例如,可以增加一个计数值来统计非元音字母的数量,只要在default分支内不断递增名为otherCnt的变量就可以了:
// 如果ch是一个元音字母,将相应的计数值加1
switch (ch) {
case 'a': case 'e': case 'i': case 'o': case 'u':
++vowelCnt;
break;
default:
++otherCnt;
break;
}在这个版本的程序中,如果 ch不是元音字母,就从 default 标签开始执行并把otherCnt加1
即使不准备在default 标签下做任何工作,定义一个 default 标签也是有用的。其目的在于告诉程序的读者,我们已经考虑到了默认的情况,只是目前什么也没做。
标签不应该孤零零地出现,它后面必须跟上一条语句或者另外一个case标签。
如果switch结构以一个空的default标签作为结束,则该default标签后面必须跟上一条空语句或一个空块。
switch 内部的变量定义
如前所述,switch的执行流程有可能会跨过某些case标签。如果程序跳转到了某个特定的case,则switch结构中该case标签之前的部分会被忽略掉。这种忽略掉一部分代码的行为引出了一个有趣的问题:如果被略过的代码中含有变量的定义该怎么办?
答案是:如果在某处一个带有初值的变量位于作用域之外,在另一处该变量位于作用域之内,则从前一处跳转到后一处的行为是非法行为。
case true:
// 因为程序的执行流程可能绕开下面的初始化语句,所以该switch 语句不合法
string file_name; //错误:控制流绕过一个隐式初始化的变量
int ival = 0; //错误:控制流绕过一个显式初始化的变量
int jval; // 正确:因为jval没有初始化
break;
case false:
// 正确:jval虽然在作用域内,但是它没有被初始化
jval - next_num(); //正确:给jval赋一个值
if (file_name.empty()) //file_name在作用城内,但是没有被初始化
假设上述代码合法,则一旦控制流直接跳到false分支,也就同时略过了变量file_name和ival的初始化过程。
此时这两个变量位于作用域之内,跟在false之后的代码试图在尚未初始化的情况下使用它们,这显然是行不通的。
因此C++语言规定,不允许跨过变量的初始化语句直接跳转到该变量作用域内的另一个位置。
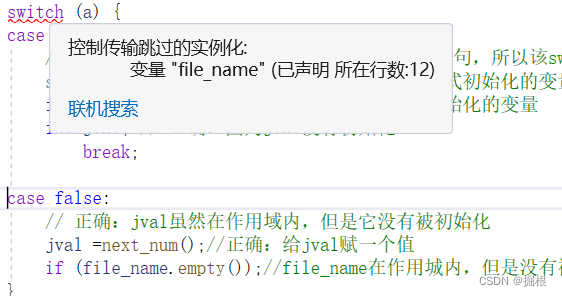
如果需要为某个case分支定义并初始化一个变量,我们应该把变量定义在块内,从而确保后面的所有case标签都在变量的作用域之外,这样子别的case标签就不能用到这个变量了
case true:
{
正确:声明语句位于语句块内部
string file_name = get_file_name ()
//...}
break;
case false:
if(file_name.empty())//错误:file_name不在作用域之内注意:
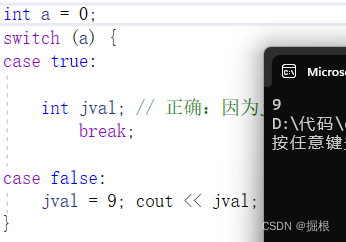
变量不初始化还是可以运行的
#include<iostream>
using namespace std;
int main()
{
int a = 0;
switch (a) {
case true:
int jval; //这是可以的
break;
case false:
jval = 9; cout << jval;
}
}
C++语言规定,不允许跨过变量的初始化语句直接跳转到该变量作用域内的另一个位置
#include<iostream>
using namespace std;
int main()
{
int a = 0;
switch (a) {
case true:
int jval=8; //这是错误的
break;
case false:
cout << jval;
}
} 















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









