







1.背景
- 会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力
- 一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中,makefile定义了一系列的 规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂 的功能操作
- makefile带来的好处就是——“自动化编译”,一旦写好,只需要一个make命令,整个工程完全自动编 译,极大的提高了软件开发的效率。
- make是一个命令工具,是一个解释makefile中指令的命令工具,一般来说,大多数的IDE都有这个命 令,比如:Delphi的make,Visual C++的nmake,Linux下GNU的make。可见,makefile都成为了一 种在工程方面的编译方法。
- make是一条命令,makefile是一个文件,两个搭配使用,完成项目自动化构建
2.make/Makefile
2.1.见一见make/Makefile是怎么工作的
make是一个命令,Makefile是一个文件,当前目录下的文件
可以写makefile也可以写Makeile

![]()
我们在里面写下

第一行的意思就是mycode.c编译成名字叫mycode的可执行程序,这个叫依赖关系
第二行是怎么编译,这个是依赖方法
完成了以后,我们再也不用使用gcc命令来编译了

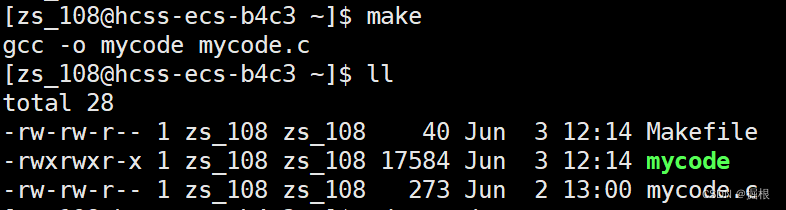
直接生成了一个可执行程序
后面我们不想要可执行程序mycode了,我们直接打开Makefile

这样子我们就删掉了那个可执行程序

我们写代码就不用gcc了
我们系统自动存在make命令
它和Makefile一起配对使用的

我们现在了解make/Makefile是怎么使用的了
那么问题来了
2.2.什么是依赖关系?什么是依赖方法?
我们看个例子就明白了
- 假如你是个在校大学生,快要到月底了,这时候你可能就要打电话给你爸要生活费了。你打电话给你爸爸,说 "爸,我是你儿子。",这就是表明依赖关系。你打电话告诉你爸你是他儿子的时候,实际上你的潜台词就是 "我要依赖你"。
- 你给你爸打电话说:"爸我是你儿子",说完就把电话一挂,对于你爸来说会一脸懵逼 —— "这孩子今天怎么了,这是被绑架了?",你爸就不太清楚了。也就是说,你在打电话时只是表明了依赖关系,但你并没有达到你想要做的目的(要下个月的生活费),所以正确的方法应该是:"爸,我是你儿子,我要下个月的生活费。",你表达了你是谁,并且要求给你打钱。
- 我是你儿子 —— 表明了 "依赖关系",因为依赖关系的存在,所以才能给你打钱。
- 打钱 —— 就是 "依赖方法",当你把依赖关系和依赖方法表明时,你就能达到要钱的目的。
- 依赖关系不对,依赖方法再对也没有用,比如你的舍友给你爸打电话,说:"我是你儿子的舍友,给我打钱!",你爸绝对不会打钱的。
- 依赖方法表明了,依赖方法不正确同样没有用,比如你打电话给你爸:说:"我是你儿子,给我打钱我要充游戏!",你爸也不会给你打钱的!
通过上面的比喻,相信你已经知道什么是依赖关系和依赖方法了,他们必须都为真。
依赖关系和依赖方法都要为真,才能达成要钱的目的!
依赖关系:我们上面mycode的形成需要依赖于mycode.c
依赖方法:只有依赖关系可不够,还需要指明怎么依赖
上面那个依赖关系是简写的,下面我们故意写点繁琐的
我们把上面那个修改成下面这个更繁琐的
我们报存,去使用它
这个好像没有什么问题
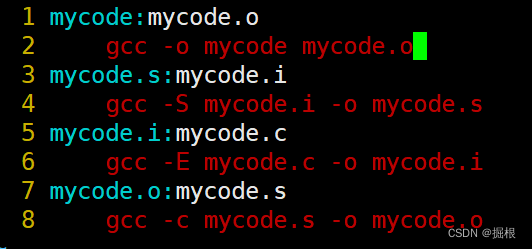
我们看看啊,我们书写的时候是从上往下写的,但是它是从下面往上执行的,为什么呢?


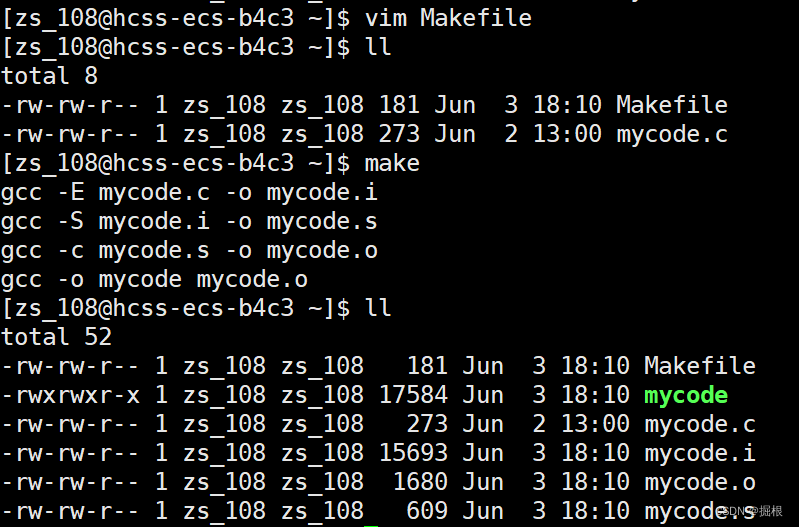
这个是因为make在扫描makefile时是从上往下的,但是当前目录没有提供mycode.o,所以往下先生成mycode.o,而形成mycode.o又要形成mycode.s,依次类推,所以先生成mycode.i,刚好生成mycode.i需要mycode.c,刚好当前目录有
这个过程特别像栈
这个是makefile依赖文件的自动化推导
有人说,它既然能推导,我们要是把它变乱序还能不能推导了?
事实证明,完全没有任何问题!!!!!
我要是故意漏掉一行会怎么样!
结果是不能正常使用
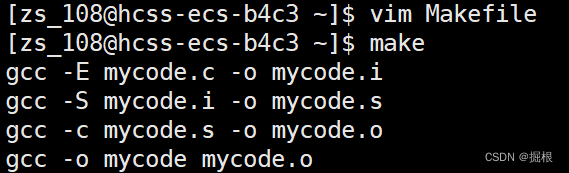

由此,我们得到一个结论:make会自动推导Makefile中的依赖结构,栈式结构
2.3.如何清理make生成的临时文件
我们使用make生成的东西里面有很多临时文件
比如下面的mycode.i,mycode.o,mycode.s文件
我们需要引入一个东西来清理这些临时文件
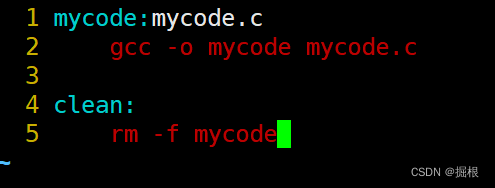
我们打开Makefile
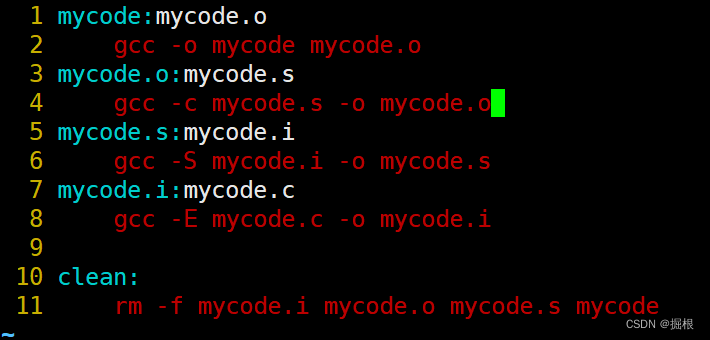
clean没有依赖关系,只执行删除功能
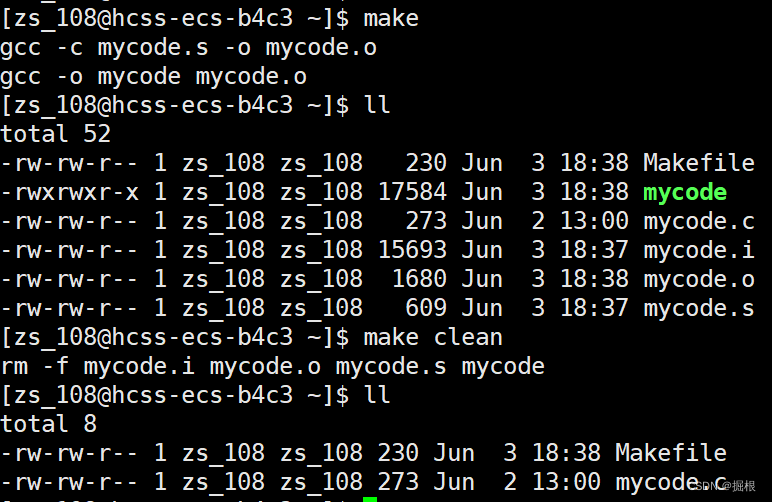
很好,全删除了
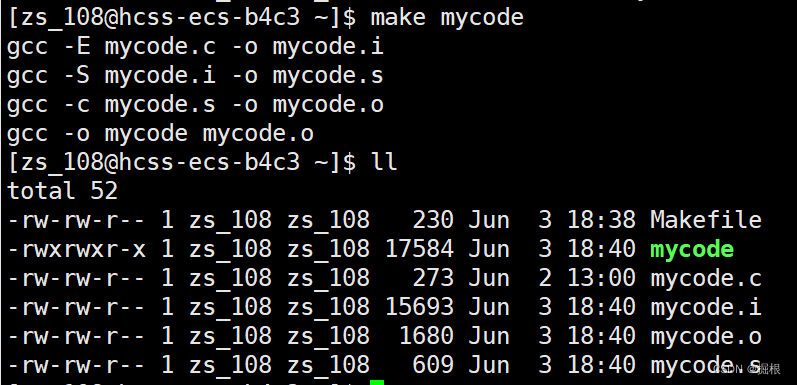
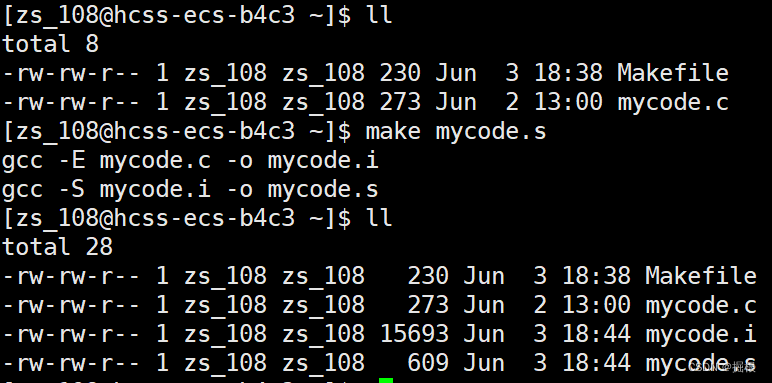
新的问题又来了,我们看下面
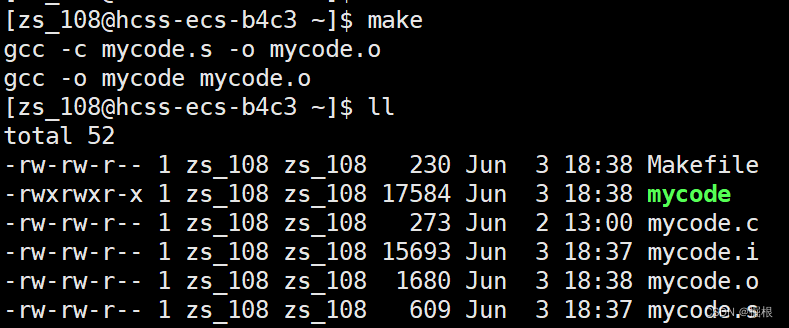
我们可以使用make clean,那么是不是意味着我们可以使用make mycode ,make mycode.o,make mycode.i , make mycode .s?我们验证一下
事实证明确实如此
我们接着看啊,我们直接把clean放到前面
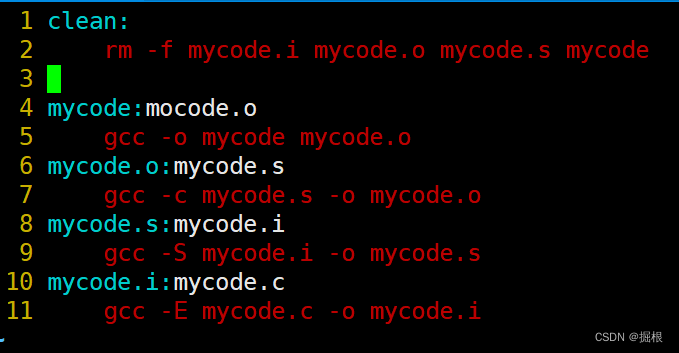
我们此时再执行make指令会有什么反应?

我靠,怎么变删除了!!!
所以make会自顶向下查找第一个依赖关系,并执行该依赖关系的依赖方法
所以我们不要把清理工作放在最前面
2.4.为什么我们只可以make一次 ,后面make多次就不行?怎么做到的?
我们看看下面这个情况

我们make使用一次之后就不让我编译了
为了方便,我们把Makefile全改回来简单版本

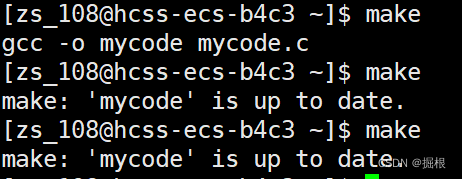
只让我们make一次
我们将代码修改,再make一下,发现又可以了,再make又不行了
为什么不让我们编译了?
因为源文件没有更新的话,没有必要,提高编译效率
那它是怎么做到的?
- 先有源文件,再有可执行程序——源文件一定比可执行文件先进行修改
- 如果我们更改了源文件,历史上曾经还有可执行,那么源文件的最近修改时间,一定比可执行程序要新!
一般而言,源文件的最近修改时间会不会和可执行程序最近修改时间是不会一样的,除非我们去修改了设置
基于上面两个常识,我们就能知道为什么了
我们只需比较可执行程序的最近修改时间和源文件最近修改时间,
- 如果可执行程序的修改时间比源文件的修改时间新,那么说明源文件是旧的,不需要重新编译;
- 如果可执行程序的修改时间比源文件的修改时间旧,那么说明源文件是新的,需要重新编译;
我们来验证一下上面的猜想
我们先补充一下知识
linux有一条指令stat,专门用来查看文件的生成时间
对于文件有3个时间(简称Acm)
- Access(进入):最近被访问时间
- Modify(改变):最近文件内容被修改时间
- Change(更改): 最近文件属性被修改时间
文件=文件内容+文件属性
在linux中,我们把文件内容改了,文件属性也改了(大小)
我们很容易知道Access更改的频率是非常高的,但是文件是存在在外部磁盘里,当用户一多,更改频率太大容易影响性能,所以Access不会每次都更改
我们去修改一下mycode.c
我们发现 全变了
我们发现上面的Change改变了

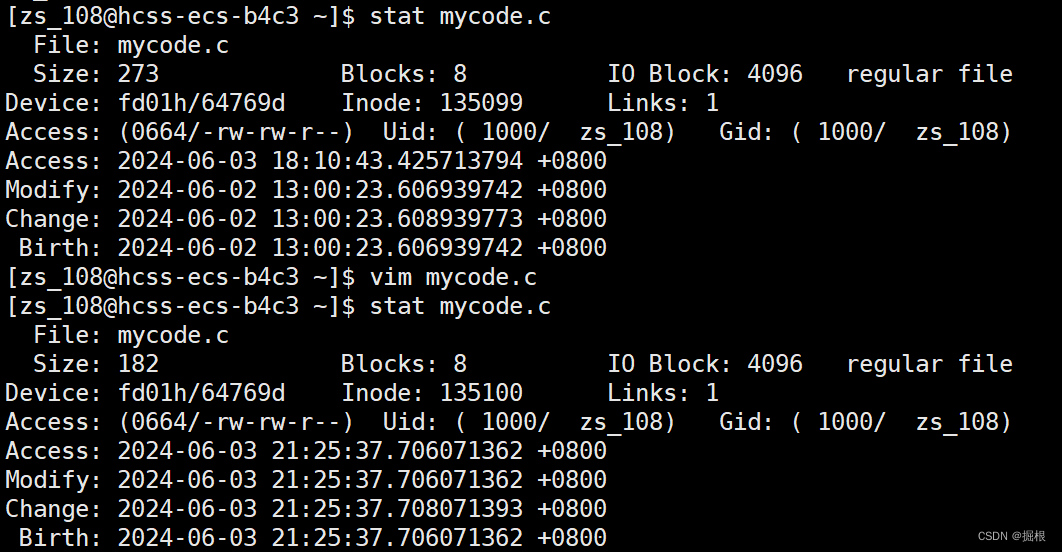
我们回头去验证
我们怎么判断可执行程序和源文件的新旧啊?
我们一般比较Modify
其实最简单的方法就是把它们各自的时间转换为时间戳进行对比
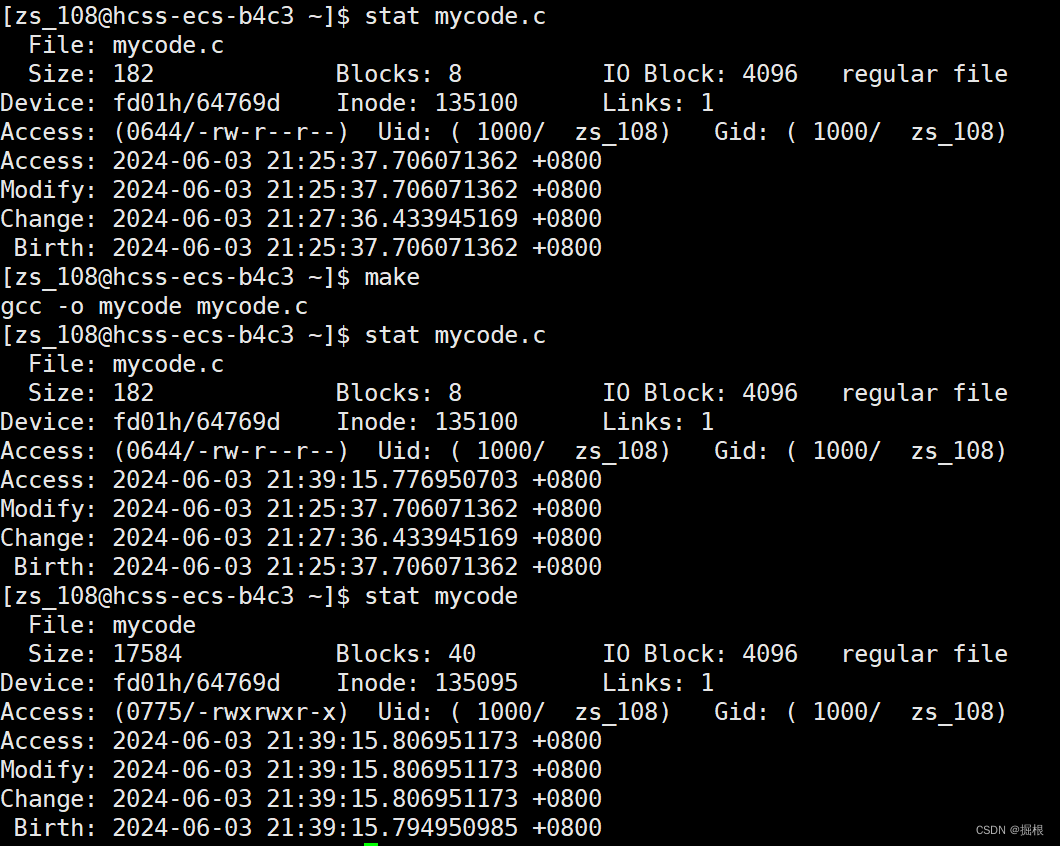
mycode.c的Access更改的原因是因为gcc编译时读取了mycode.c
我们比较可执行程序和源文件的Modify时间,显然可执行程序的更新

这里不让我们make了
我们直接创建一个新的mycode.c
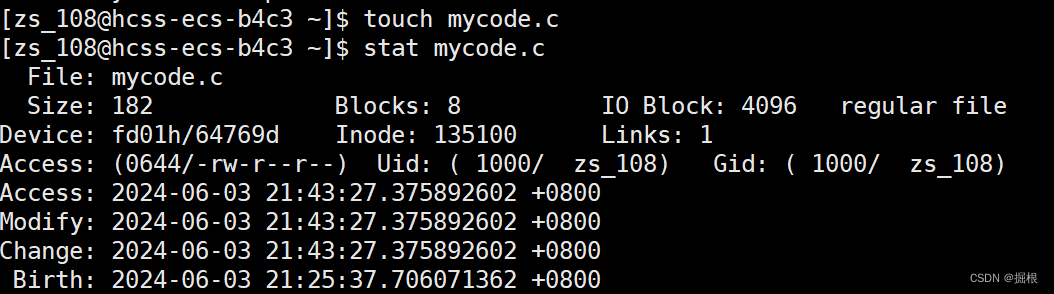
时间全更新了
这个新的mycode.c会覆盖旧的mycode.c

这个时候啊,源文件的Modify时间比可执行程序的新,肯定可以执行make

我们看看可执行程序的Modify时间和源文件的
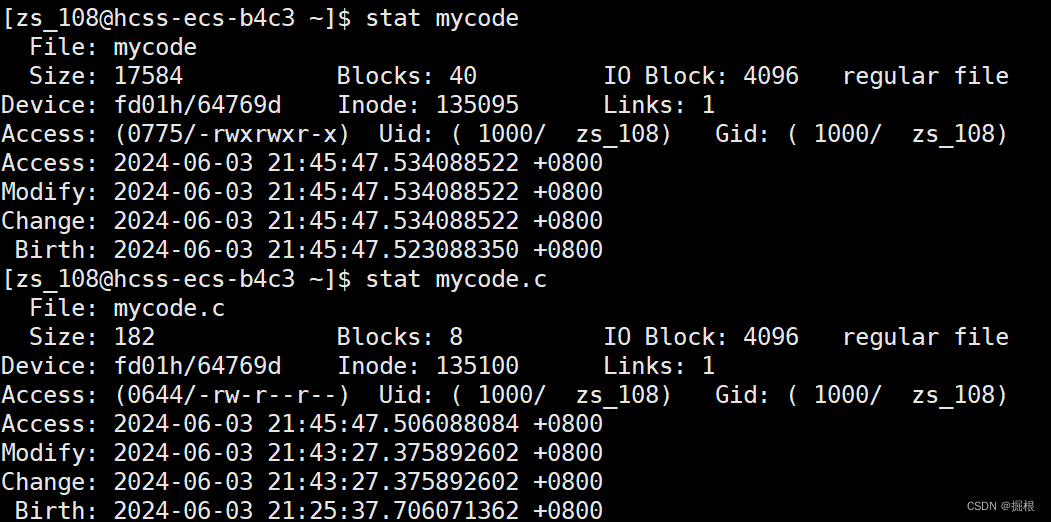
可执行程序的时间更新啊
不能执行make

依次类推
我们得出结论:make会根据源文件和目标文件的新旧,判断是否需要重新执行依赖关系!它不一定总是执行的
今天我就是想对应的依赖关系被执行呢?
那么就引入了新的语法
我们打开Makefile
改成下面这样子

这样子就能总是执行mycode的依赖关系啦
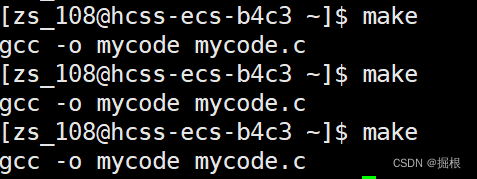
但是我们一般不会把这个语法用在这里
我们常常把这个语法用到清理工作,因为清理工作需要总是被执行
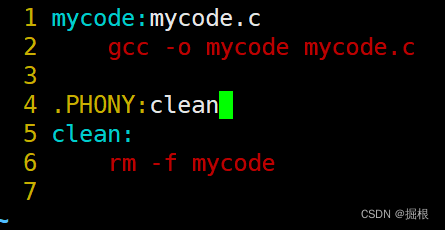
这样子清理工作就能多次被执行了
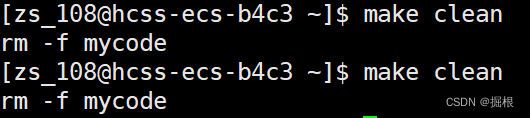
2.5.特殊符号
我们在上面的Makefile文件里面写的是
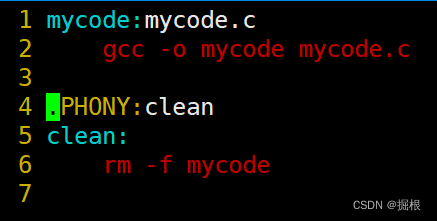
我们可以将其修改成下面这样子

- $@代表依赖关系的目标文件,冒号的左侧
- $^代表冒号的右侧
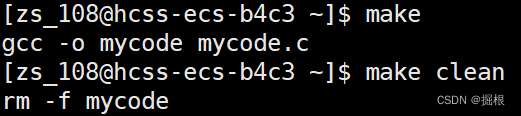
也能正常运转,我们发现使用make就会回显,我们不想回显,怎么做呢?
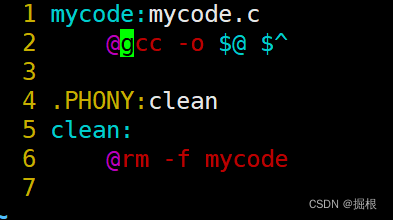
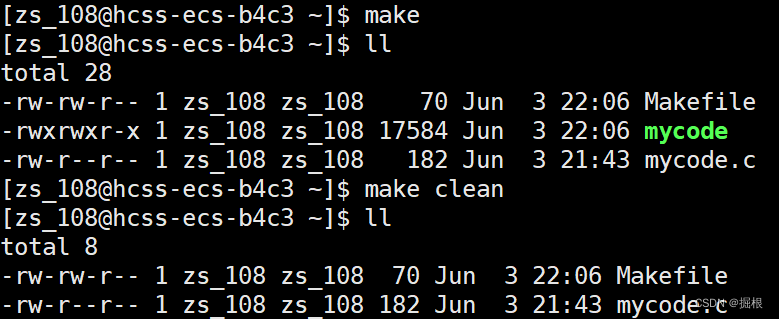
这样子即可
3.Linux第一个项目——进度条
制作进度条,我们需要一些储备知识
3.1.回车换行
我们对回车换行可能有的误解
真正的回车换行应该是下面这样子的
- 回车(Carriage Return):在打字机时代,回车指的是将打字机的打印头(称为"carrier")移回到行首的操作。在计算机时代,回车通常表示将光标移动到当前行的开头,而不会换到下一行。在ASCII字符集中,回车通常用"\r"表示。
- 换行(Line Feed)::换行是指将光标移动到下一行的操作,使得文本在纵向上向下移动一个行高。在ASCII字符集中,换行通常用"\n"表示。
- 在Unix和类Unix系统(如Linux和macOS)中:通常使用换行字符(“\n”)来表示换行。
- 在Windows系统中:,通常使用回车和换行的组合来表示换行,即"\r\n"。
3.2.缓冲区
缓冲区(Buffer)是计算机内存中的一块特定区域,用于临时存储数据。它在许多计算机系统和应用程序中发挥着重要作用,通常用于临时存储输入数据、输出数据或在内存和其他设备之间进行数据传输。
输入缓冲区:用于暂时存储从输入设备(如键盘、鼠标、网络接口等)接收到的数据,直到程序能够处理它们。输入缓冲区使得程序可以按需处理输入,而不必担心输入数据的速度与程序处理速度不匹配的问题。输出缓冲区:用于暂时存储将要发送到输出设备(如显示器、打印机、网络接口等)的数据,直到设备准备好接收它们。输出缓冲区可以提高数据传输的效率,因为程序不必等待设备就绪就可以继续执行。
3.2.1.缓冲区何时被清理
拿C语言举个例子:
在C语言中,标准库函数printf()用于将格式化的数据打印到标准输出流(通常是终端)。但是,printf()函数并不会立即将数据显示到终端上。相反,它会将数据写入到输出缓冲区中。输出缓冲区是一个临时存储区域,用于存放printf()函数打印的数据,直到满足一定条件时才将其刷新(即将数据发送到终端并显示出来)。
这些条件包括:
- 遇到换行符 \n:当printf()函数遇到换行符时,输出缓冲区会被自动刷新,将缓冲区中的数据输出到终端并显示出来。
- 缓冲区满:当输出缓冲区满了,它也会被自动刷新。
- 调用fflush()函数:显式调用fflush(stdout)函数可以强制刷新输出缓冲区,将其中的数据输出到终端。
- 程序结束:当程序正常终止时,所有的缓冲区都会被刷新。
3.2.2.验证缓冲区存在
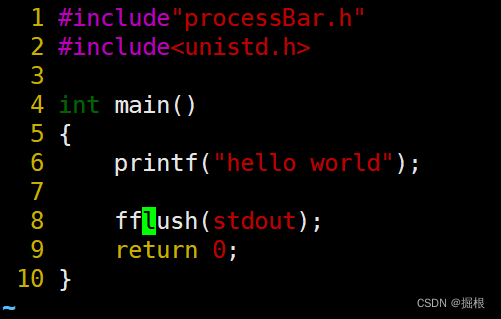
我们先写出基本的代码结构
processBar.h
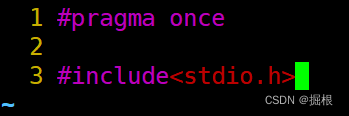
processBar.c我们暂时不写
main.c
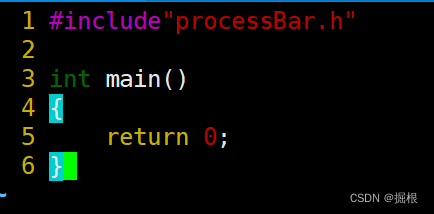
我们新建一个makefile,写成下面这个
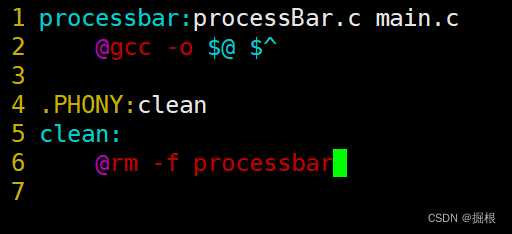
我们为什么只写两个源文件,不写头文件呢?
这个是因为头文件在makefile的同一目录里,我们的main.c包含了这个头文件,make会自动寻找头文件

没有任何问题
我们基于这个结构来验证一下缓冲区的问题
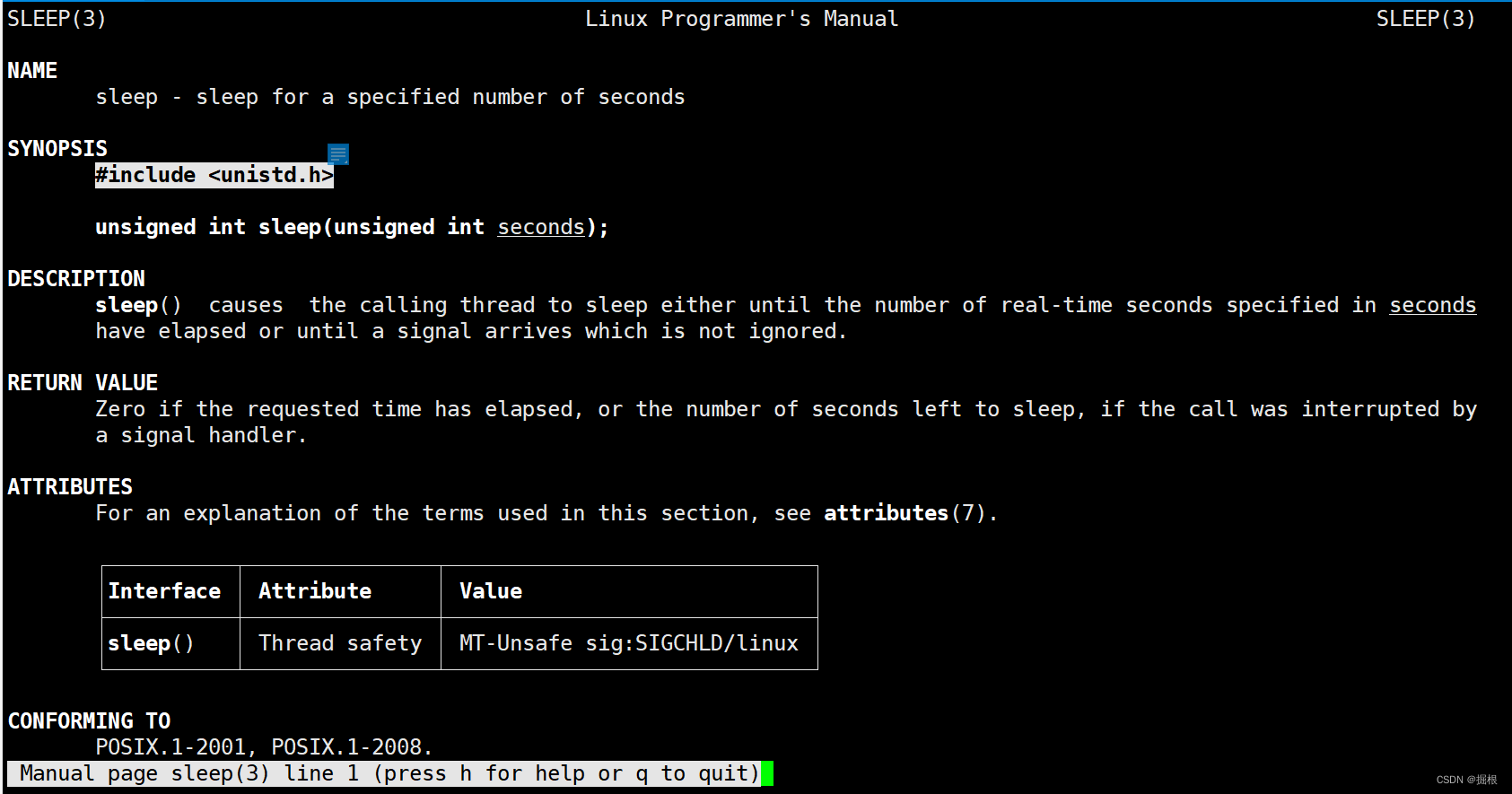
我们可以查找sleep函数
我们编译运行上面那个代码
发现hello world直接出来了,没有等待3ms
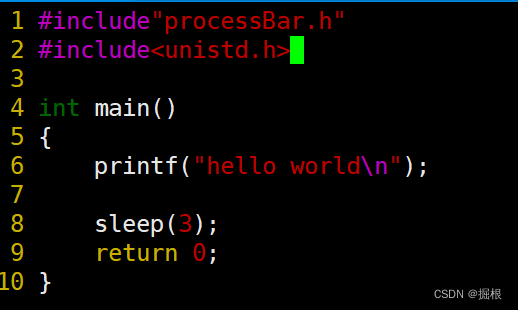
我们更新一下代码
helloworld居然没有先出来出来
在等待的这段时间里,helloworld是在输出缓冲区里
后出来的helloworld



我们再更新 一下代码
fflush函数可以去man3号手册查
直接输出了

3.3.代码
有了以上的知识储备,咱们就可以尝试编写一下简单的倒计时程序了,思路如下:
- 首先新建一个
time.c文件,然后再用我们之前讲的makefile工具来实现time.c文件的自动构建:
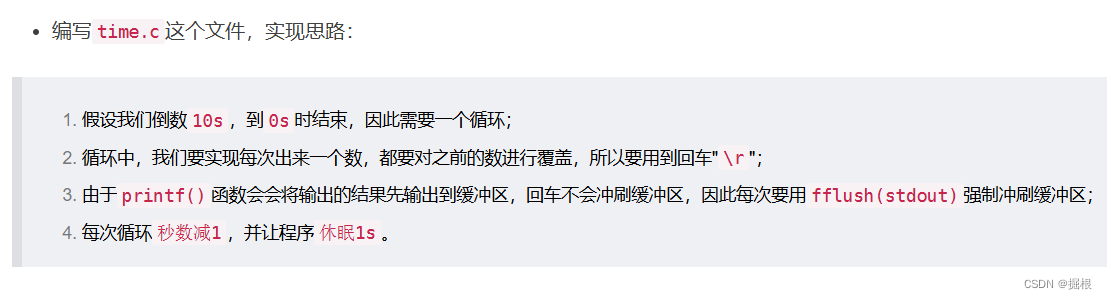
#include <stdio.h>
#include <unistd.h>
int main()
{
int cnt = 10;
while(cnt >= 0)
{
// 打印的时候每次覆盖上一次出现的数字
printf("倒计时:%2d\r",cnt);
// 强制冲刷缓冲区
fflush(stdout);
--cnt;
sleep(1);
}
printf("\n");
return 0;
}
用make命令进行编译:
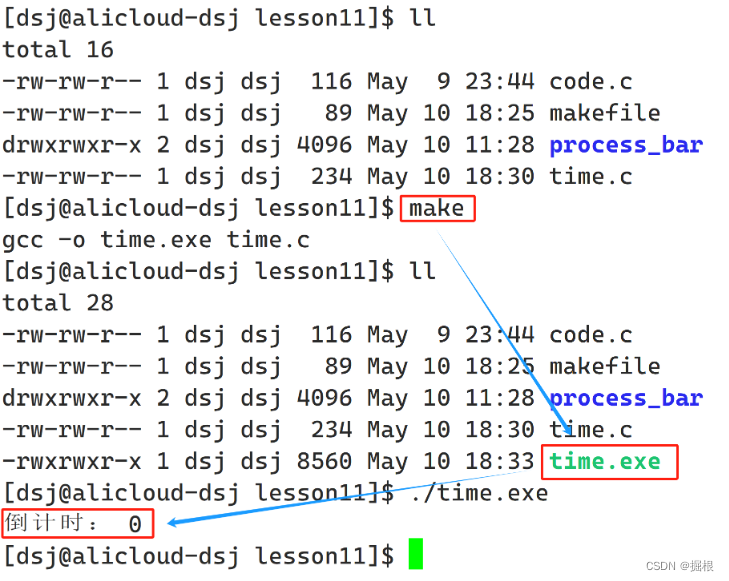
- 这里有个小拓展,如果我们要覆盖上次的数字是4位,这次是三次(比如1000到999),可以用
%4d这个输出形式来解决,也可以用下面这种方法:
#include <stdio.h>
#include <unistd.h>
int main()
{
int cnt = 1000;
int tmp = cnt;
int num = 0;
while (tmp)
{
++num;
tmp /= 10;
}
while(cnt >= 0)
{
// 主要就是这里的变化,用最大数字的位数来做占位符
printf("倒计时:%*d\r",num, cnt);
fflush(stdout);
--cnt;
sleep(1);
}
printf("\n");
return 0;
}
总共有三个部分:
1. 我们要实现的进度条用#来进行加载;
2. 后面要有数据来表示现在加载的进度是多少(百分数);
3. 最后用一个动态旋转的类⚪来表示程序还在继续加载。
1. 动态加载的过程
动态加和之前的倒计时差不多,每次都要覆盖上次出现的#,具体思路如下:
1. 定义一个字符类型数组char *str,用memset()函数进行初始化(‘\0’);2. 循环100次,每次循环都在数组中加一个#,并打印str('\r’进行覆盖);
3. 强制冲刷缓冲区;
2. 进度加载
我们可以用每次循环的次数来当作是当前加载的进度,当然还要进行覆盖,具体思路如下:
1. 每次循环都以当前的循环次数作为加载进度;2. 每次覆盖上一次的进度;
3. 强制冲刷缓冲区。
4. 程序休眠(可以用usleep()函数,单位是微秒)
3. 动态旋转
定义一个数组,并初始化为-\\/-,覆盖的方法和之前类似,就不详细说了。
#include "process_bar.h"
#include <memory.h>
#include <unistd.h>
#define style '#'
#define round "-\\/-"
void test()
{
int i = 0;
char str[100];
memset(str,'\0',sizeof(str));
while (i <= 100)
{
str[i] = style;
printf("[%-100s][%d%%][%c]\r",str,i,round[i % 4]);
fflush(stdout);
++i;
usleep(10000);
}
printf("\n");
}
3.4.第二版本
我们正常用进度条肯定不是单独使用的,会结合其他的场景,例如下载界面,登陆界面。
对于要下载的文件,肯定有文件大小,下载的时候网络也有它的带宽,所以在下载的时候,每次下载的大小都是一个带宽,我们可以先写一个下载的函数:
void download()
{
double bandwidth = 1024 * 1024 * 1.0;
double filesize = 1024 * 1024 * 10.0;
double cur = 0.0;
while (cur <= filesize)
{
// 调用进度条函数
test(filesize, cur);
// 每次增加带宽
cur += bandwidth;
usleep(20000);
}
printf("\n");
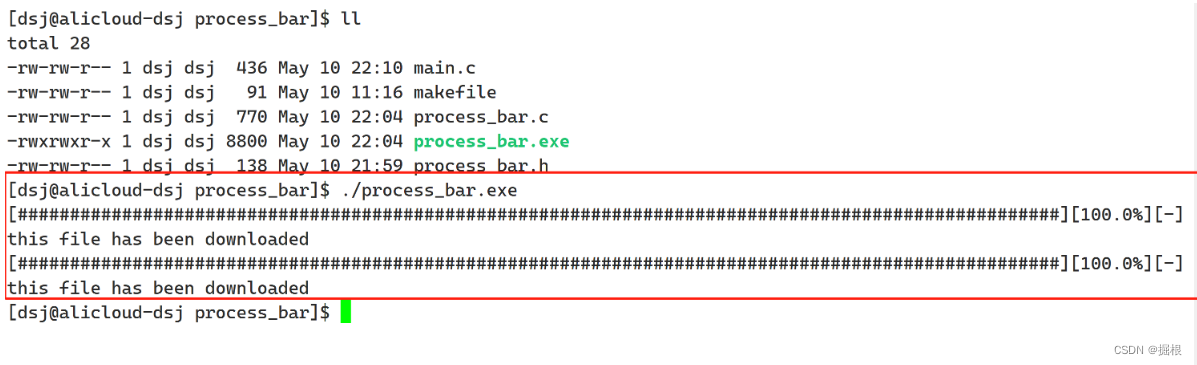
printf("this file has been downloaded\n");
}
void test(double total, double current)
{
char str[101];
memset(str,'\0',sizeof(str));
int i = 0;
// 这次的比率
double rate = (current * 100) / total;
// 循环次数
int loop_count = (int)rate;
while (i <= loop_count)
{
str[i++] = style;
}
printf("[%-100s][%.1lf%%][%c]\r",str,rate,round[loop_count % 4]);
fflush(stdout);
}
// 头文件 process_bar.h
#include <stdio.h>
typedef void(*callback_t)(double, double);// 函数指针(回调函数)
void test(double total, double current);
// 函数实现文件 process_bar.c
#include "process_bar.h"
#include <memory.h>
#include <unistd.h>
#define style '#'
#define round "-\\/-"
void test(double total, double current)
{
char str[101];
memset(str,'\0',sizeof(str));
int i = 0;
double rate = (current * 100) / total;
int loop_count = (int)rate;
while (i <= loop_count)
{
str[i++] = style;
}
printf("[%-100s][%.1lf%%][%c]\r",str,rate,round[loop_count % 4]);
fflush(stdout);
}
// main.c 主函数和 download 函数
#include "process_bar.h"
#include <unistd.h>
double bandwidth = 1024 * 1024 * 1.0;
void download(double filesize, callback_t cb)
{
double cur = 0.0;
while (cur <= filesize)
{
cb(filesize, cur);
cur += bandwidth;
usleep(20000);
}
printf("\n");
printf("this file has been downloaded\n");
}
int main()
{
download(1024*1024*100.0,test);
download(1024*1024*20.0,test);
return 0;
}















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









