







目录
题目一——860. 柠檬水找零 - 力扣(LeetCode)
题目二——2208. 将数组和减半的最少操作次数 - 力扣(LeetCode)
题目五——300. 最长递增子序列 - 力扣(LeetCode)
题目六——334. 递增的三元子序列 - 力扣(LeetCode)
题目七——674. 最长连续递增序列 - 力扣(LeetCode)
题目八——121. 买卖股票的最佳时机 - 力扣(LeetCode)
题目九——122. 买卖股票的最佳时机 II - 力扣(LeetCode)
题目十——1005. K 次取反后最大化的数组和 - 力扣(LeetCode)
题目十一——2418. 按身高排序 - 力扣(LeetCode)
题目十二—— 870. 优势洗牌 - 力扣(LeetCode)
题目十三—— 409. 最长回文串 - 力扣(LeetCode)
题目十四——942. 增减字符串匹配 - 力扣(LeetCode)
题目十五——455. 分发饼干 - 力扣(LeetCode)
题目十六——553. 最优除法 - 力扣(LeetCode)
题目十七——45. 跳跃游戏 II - 力扣(LeetCode)
题目十八—— 55. 跳跃游戏 - 力扣(LeetCode)
题目二十—— 738. 单调递增的数字 - 力扣(LeetCode)
题目二十一—— 991. 坏了的计算器 - 力扣(LeetCode)
题目二十二——56. 合并区间 - 力扣(LeetCode)
题目二十三——435. 无重叠区间 - 力扣(LeetCode)
题目二十四——452. 用最少数量的箭引爆气球 - 力扣(LeetCode)
题目二十五——397. 整数替换 - 力扣(LeetCode)
题目二十六——354. 俄罗斯套娃信封问题 - 力扣(LeetCode)
题目二十七——1262. 可被三整除的最大和 - 力扣(LeetCode)
题目二十八——1054. 距离相等的条形码 - 力扣(LeetCode)
题目二十九——767. 重构字符串 - 力扣(LeetCode)
贪心算法
说实话啊,这个贪心算法其实比那些什么回溯啊,二分啊,滑动窗口难学,那些都使用三四道题目就能吃透里面的精髓,但是贪心算法不一样。贪心算法的策略非常多,多到我们刷了二三十道题目了,遇到新的题目还是,没啥太多思路。
什么是贪心算法?
贪心算法(Greedy Alogorithm)又叫登山算法,它的根本思想是逐步到达山顶,即逐步获得最优解,是解决最优化问题时的一种简单但是适用范围有限的策略。
贪心算法没有固定的框架,算法设计的关键是贪婪策略的选择。贪心策略要无后向性,也就是说某状态以后的过程不会影响以前的状态,至于当前状态有关。
贪心算法是对某些求解最优解问题的最简单、最迅速的技术。某些问题的最优解可以通过一系列的最优的选择即贪心选择来达到。但局部最优并不总能获得整体最优解,但通常能获得近似最优解。
在每一步贪心选择中,只考虑当前对自己最有利的选择,而不去考虑在后面看来这种选择是否合理。
贪心算法(greedy algorithm)是一种常见的解决优化问题的算法,其基本思想是在问题的每个决策阶段,都选择当前看起来最优的选择,即贪心地做出局部最优的决策,以期获得全局最优解。贪心算法简洁且高效,在许多实际问题中有着广泛的应用。
贪心算法和动态规划都常用于解决优化问题。它们之间存在一些相似之处,比如都依赖最优子结构性质,但工作原理不同。
- 动态规划会根据之前阶段的所有决策来考虑当前决策,并使用过去子问题的解来构建当前子问题的解。
- 贪心算法不会考虑过去的决策,而是一路向前地进行贪心选择,不断缩小问题范围,直至问题被解决。
我们这里举3个例子来理解贪心算法。
- 问题一. 找零问题
比如说你用50块钱去买了一个4块钱的东西,而卖家有面值为20,10,5,1的钱若干张,那商家要怎么找钱才能使得找的钱的张数最少呢?
我们就是要找回46,我们是一张一张的找,那我们可以使用贪心策略,每一次都选当前看起来最优秀的,第一张找20,第二张找20,下一张只能找5,下一张只能是1。
- 题目二 . 最小路径和
这个其实我们在动态规划里面讲过的,就是我们每一步只能往下或者往右边走,然后我们的起点是左上角,终点是右下角。方格里面的是走过这格需要的步数,问我们从左上角走到右下角的最少步数是多少?
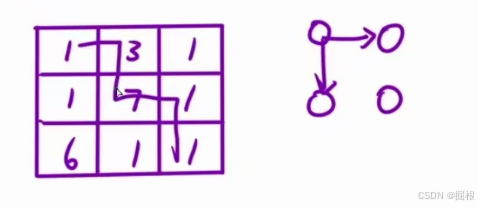
我们完全可以在每一步的时候,比较下面和右边那个格子里面的数值的大小,在符合条件的情况,哪个小就选哪个。
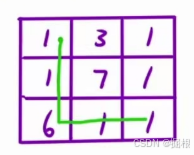
有人可能说,应该是先沿着右边走,再往下走才是最优解啊。但是我们这个先不讲解,后面再说,我们现在先把贪心策略搞清楚即可。
- 题目三 . 背包问题
这个其实是动态规划的内容,但是还是适用于贪心
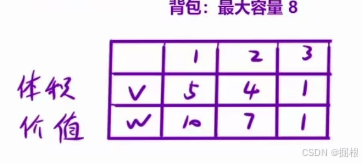
每件物品有无数件,问这个背包所能装下物品的最大价值是多少?
其实这题的贪心策略有三种
- 我们只考虑体积:每次选择都选择体积最小的,那就是选了8件物品3
- 我们只考虑价值:每次选择都选择价值最高的,那就是选择了1件物品1,3件物品3
- 我们一起考虑体积和价值,我们采用价值/体积的方式来选择物品:每次选择都选择价值/体积最大的,那就是选择1个物品1和3个物品3.
但是这3种都不是正确答案。正确答案应该是选择两个物品二。
贪心策略的提出
我们仔细看上面那三题,我们就会发现,这3题的贪心策略都是根据题目或者经验来得出。这就说明我们学习贪心是没有啥套路可言,完完全全都是根据问题具体分析。
贪心策略的正确性证明
我们在上面的例子里面也看到了,贪心策略不一定是最优解。所以正确的贪心策略需要我们自己去证明一番。
常见的证明方法:都是我们在数字里面见过的证明方法
贪心算法最难的部分不在于问题的求解,而在于是正确性的证明。我们常用的证明方法有「数学归纳法」和「交换论证法」。
数学归纳法:先计算出边界情况(例如 n=1)的最优解,然后再证明对于每个 n,Fn+1 都可以由 Fn 推导出。
交换论证法:从最优解出发,在保证全局最优不变的前提下,如果交换方案中任意两个元素 / 相邻的两个元素后,答案不会变得更好,则可以推定目前的解是最优解。
判断一个问题是否通过贪心算法求解,是需要进行严格的数学证明的。但是在日常写题或者算法面试中,不太会要求大家去证明贪心算法的正确性。
所以,当我们想要判断一个问题是否通过贪心算法求解时,我们可以:
- 凭直觉:如果感觉这道题可以通过「贪心算法」去做,就尝试找到局部最优解,再推导出全局最优解。
- 举反例:尝试一下,举出反例。也就是说找出一个局部最优解推不出全局最优解的例子,或者找出一个替换当前子问题的最优解,可以得到更优解的例子。如果举不出反例,大概率这道题是可以通过贪心算法求解的。
接下来我来验证一下:
- 找零问题
比如说你用50块钱去买了一个4块钱的东西,而卖家有面值为20,10,5,1的钱若干张,那商家要怎么找钱才能使得找的钱的张数最少呢?
我们先证明一个性质:假设最优解里面 20块钱用了A张,10块钱用了B张,5块钱用了C张,1块钱用了D张,我们这个B,C,D三个数是有取值范围的。
首先说这个B
- B>2:这绝对不是最优解,这个情况我为啥不用20来呢?
- B=2:这绝对不是最优解,这个情况我为啥不用一张20来呢?
- B<2:这个时候就可以了
所以B<2,即B<=1。
再说这个C
- C>2:这绝对不是最优解,这个情况我为啥不用10来呢?
- C=2:这绝对不是最优解,这个情况我为啥不用一张10来呢?
- C<2:这个时候就可以了
所以C<2,即C<=1。
再说这个D
- C>5:这绝对不是最优解,这个情况我为啥不用5来呢?
- C=5:这绝对不是最优解,这个情况我为啥不用一张5来呢?
- C<5:这个时候就可以了
所以C<5,即C<=4。
总的来说,就是在最优解里面,B<=1,C<=1,D<=5
当BCD都取最大值的时候,只能取19块钱
接下来我们的贪心解和最优解是一致的即可。
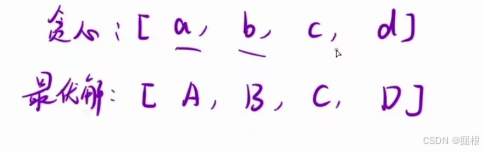
我们的贪心策略就是每次都选择面额最大的,也就是说a>=A。但是我们仔细思考一下,当BCD都取最大值的时候,只能取19块钱,这就说明了a>A这个情况是不能存在的。所以a==A。
同理我们能证明b==B,c==C ,d==D。
那就说明我们的贪心策略是相当正确的。
就这么简单的一个问题,证明这么长,说明遇到不会的贪心题,很正常,放轻松,把心态放平。
- 前期学习的时候,我们把重点放到贪心的策略上,把这个策略当成经验吸收。
- 我们需要学习如何去证明一个贪心策略的证明
贪心问题的解决流程
贪心问题的解决流程大体可分为以下三步。
- 问题分析:梳理与理解问题特性,包括状态定义、优化目标和约束条件等。这一步在回溯和动态规划中都有涉及。
- 确定贪心策略:确定如何在每一步中做出贪心选择。这个策略能够在每一步减小问题的规模,并最终解决整个问题。
- 正确性证明:通常需要证明问题具有贪心选择性质和最优子结构。这个步骤可能需要用到数学证明,例如归纳法或反证法等。
确定贪心策略是求解问题的核心步骤,但实施起来可能并不容易,主要有以下原因。
- 不同问题的贪心策略的差异较大。对于许多问题来说,贪心策略比较浅显,我们通过一些大概的思考与尝试就能得出。而对于一些复杂问题,贪心策略可能非常隐蔽,这种情况就非常考验个人的解题经验与算法能力了。
- 某些贪心策略具有较强的迷惑性。当我们满怀信心设计好贪心策略,写出解题代码并提交运行,很可能发现部分测试样例无法通过。这是因为设计的贪心策略只是“部分正确”的,上文介绍的零钱兑换就是一个典型案例。
为了保证正确性,我们应该对贪心策略进行严谨的数学证明,通常需要用到反证法或数学归纳法。
然而,正确性证明也很可能不是一件易事。如若没有头绪,我们通常会选择面向测试用例进行代码调试,一步步修改与验证贪心策略。
题目一——860. 柠檬水找零 - 力扣(LeetCode)


注意:一开始你手头没有任何零钱。
由于顾客只可能给你三个面值的钞票,而且我们一开始没有任何钞票,因此我们拥有的钞票面值只可能是 5 美元,10 美元和 20 美元三种。基于此,我们可以进行如下的分类讨论。
- 5 美元,由于柠檬水的价格也为 5 美元,因此我们直接收下即可。
- 10 美元,我们需要找回 5 美元,如果没有 5 美元面值的钞票,则无法正确找零。
- 20 美元,我们需要找回 15 美元,此时有两种组合方式,一种是一张 10 美元和 5 美元的钞票,一种是 3 张 5 美元的钞票,如果两种组合方式都没有,则无法正确找零。当可以正确找零时,两种找零的方式中我们更倾向于第一种,即如果存在 5 美元和 10 美元,我们就按第一种方式找零,否则按第二种方式找零,因为需要使用 5 美元的找零场景会比需要使用 10 美元的找零场景多,我们需要尽可能保留 5 美元的钞票。
基于此,我们维护两个变量 five 和 ten 表示当前手中拥有的 5 美元和 10 美元钞票的张数,从前往后遍历数组分类讨论即可。
class Solution {
public:
bool lemonadeChange(vector<int>& bills) {
int five = 0, ten = 0;
for(auto&bill:bills)
{
if(bill==5)
{
five++;
}
else if(bill==10)
{
if(five>0)
{
five--;
ten++;//这是你收下的钱
}
else
{
return false;
}
}
else
{
if(ten>0&&five>0)
{
five--;
ten--;
}
else if(five>=3)
{
five-=3;
}
else
{
return false;
}
}
}
return true;
}
};
题目二——2208. 将数组和减半的最少操作次数 - 力扣(LeetCode)


基于贪心的思想,我们可以将数组和减半的操作次数最小化的策略精炼为:在每一步操作中,都应当选择当前数组中的最大值进行减半。这一策略的有效性可以通过以下逻辑得以证明:
假设存在一种能使操作次数达到最小的策略(我们称之为最优策略),在其执行的某一步中,并未选择对最大值x进行操作,而是选择了对另一个值y进行操作。此时,我们可以根据后续对x的处理情况分为两类:
-
在后续步骤中,从未对
x进行过操作:在此情形下,我们可以将原本应用于y的所有操作,全部替换为对x的操作。由于x是数组中的较大值,这样的替换不仅不会增加操作次数,反而可能通过更快地接近目标值(即数组和的一半),来优化整体效率(尽管在本证明中,我们主要关注操作次数的非增加性)。 -
在后续的某一步中,对
x进行了操作:面对这种情况,我们可以简单地交换这两步操作的顺序。由于x原本就是较大的值,因此先减半x会比先减半y更快地减少总和。这样的交换同样不会增加总的操作次数。
综上所述,为了最小化操作次数,我们应当在每一步中都选择当前数组中的最大值进行减半操作。
实现这一策略的具体步骤如下:
- 首先,我们将数组中的所有元素都放入一个浮点数优先队列(通常也被称为最大堆)中。
- 使用变量
sum来记录数组的初始总和。 - 定义一个变量
sum_halved(初始化为0),用于跟踪我们已减少的总和。 - 当
sum_halved小于sum的一半时,我们重复执行以下操作:- 从优先队列中取出当前的最大元素
x。 - 更新
sum_halved,使其增加x的一半(即sum_halved += x / 2)。注意,这里的加法操作实际上是在累积我们已减少的总和,而非直接减少sum。 - 将
x的一半(x / 2)重新放入优先队列中,以备后续可能的操作。
- 从优先队列中取出当前的最大元素
- 最后,返回我们执行上述步骤的次数,即为所求的最小操作次数。
通过上述策略,我们能够确保每一步操作都尽可能有效地减少数组的总和,从而以最小的操作次数达到将数组和减半的目标。
class Solution {
public:
int halveArray(vector<int>& nums) {
// 创建一个大根堆(优先队列,最大堆),用于存储数组元素
priority_queue<double> heap;
double sum = 0.0;
// 遍历数组nums,将元素转换为double类型加入堆中,并计算总和
for (int x : nums) {
heap.push(static_cast<double>(x)); // 将整数x转换为double类型后推入堆中
sum += x; // 累加数组元素的值
}
sum /= 2.0; // 计算总和的一半,作为目标值
int count = 0; // 记录操作的次数
// 依次取出堆顶元素(当前最大值),将其减半,直到剩余总和不再大于目标值的一半
while (sum > 0) {
double t = heap.top() / 2.0; // 取出堆顶元素并减半
heap.pop(); // 弹出堆顶元素
sum -= t; // 从剩余总和中减去减半后的值
count++; // 操作次数加一
// 将减半后的值重新推入堆中,因为题目可能允许元素重复(尽管未明确说明)
heap.push(t);
// 注意:原代码中的"比特就业课"是无关内容,已移除
}
// 当剩余总和不再大于目标值的一半时,返回操作次数
return count;
}
};
题目三——179. 最大数 - 力扣(LeetCode)

要想组成最大的整数,一种直观的想法是把数值大的数放在高位。于是我们可以比较输入数组的每个元素的最高位,最高位相同的时候比较次高位,以此类推,完成排序,然后把它们拼接起来。这种排序方式对于输入数组 没有相同数字开头 的时候是有效的,例如 [45,56,81,76,123]。
下面考虑输入数组 有相同数字开头 的情况,例如 [4,42] 和 [4,45]。
- 对于 [4,42],比较 442>424,需要把 4 放在前面;
- 对于 [4,45],比较 445<454,需要把 45 放在前面。
因此我们需要比较两个数不同的拼接顺序的结果,进而决定它们在结果中的排列顺序。
贪⼼策略:
按照题⽬的要求,重新定义⼀个新的排序规则,然后排序即可。
排序规则:
- a. 「A拼接B」⼤于「B拼接A」,那么A在前,B在后;
- b. 「A拼接B」等于「B拼接A」,那么AB的顺序⽆所谓;
- c. 「A拼接B」⼩于「B拼接A」,那么B在前,A在后;
由于需要拼接以后才能决定两个数在结果中的先后顺序,N 个数就有 N! 种拼接的可能,我们是不是需要先得到 N 个数的全排列以后,再选出最大的呢?答案是没有必要。上述排序规则满足传递性,两个元素比较就可以确定它们在排序以后的相对位置关系。
class Solution
{
public:
// 定义一个公共成员函数largestNumber,接受一个整数向量nums作为参数,返回一个字符串
string largestNumber(vector<int>& nums)
{
// 优化:把所有的数转化成字符串,以便后续进行字符串拼接和比较
vector<string> strs;
// 遍历nums中的每个整数x,将其转换为字符串并添加到strs向量中
for(int x : nums) strs.push_back(to_string(x));
// 对字符串向量strs进行排序
// 排序的依据是两个字符串拼接后的结果大小,即s1 + s2与s2 + s1的比较
// 如果s1 + s2大于s2 + s1,则s1应该排在s2前面,以保证拼接出的数字最大
sort(strs.begin(), strs.end(), [](const string& s1, const string& s2)
{
return s1 + s2 > s2 + s1;
});
// 提取排序后的结果,将所有字符串拼接成一个最终的字符串ret
string ret;
for(auto& s : strs) ret += s;
// 如果拼接后的字符串以'0'开头(例如,输入为[0, 0]),则直接返回"0"
// 因为任何以0开头的数字都不是最大的数字表示形式
if(ret[0] == '0') return "0";
// 返回拼接后的字符串,即可能的最大数字字符串
return ret;
}
};
题目四——376. 摆动序列 - 力扣(LeetCode)


当然可以,我会尝试用更通俗易懂的语言来解释如何确定一个整数序列中“摆动序列”的最大长度。
首先,我们要明白什么是“摆动序列”。一个摆动序列指的是从序列的第一个元素开始,交替地出现峰值(比相邻元素大)和谷值(比相邻元素小),但序列的开始和结束也可以是峰值或谷值,只要它们满足与其相邻元素的比较关系。
现在,想象一下你正在走一个上下起伏的山路。你想要记录你走过的最高点和最低点的数量(但不需要连续),以此来估计你走了多远(或者说,这个山路有多曲折)。这就是我们要做的:在整数序列中找到峰值和谷值的数量。
但是,有一个细节需要注意:如果连续几个数字都是相同的,那么它们之间就没有峰值也没有谷值。比如,在序列[1, 1, 1]中,就没有摆动。
现在,让我们把这个想法转换成简单的步骤:
-
初始化:设置两个变量,一个用来记录当前的“趋势”(上升还是下降),另一个用来记录摆动序列的长度。趋势可以简单地用
-1(下降)、0(无趋势,即相同数字连续出现)、1(上升)来表示。开始时,我们可以比较序列的前两个数字来确定初始趋势。 -
遍历序列:从序列的第三个数字开始(因为前两个数字已经用来确定初始趋势了),逐个检查每个数字。
-
检查趋势变化:对于每个数字,检查它与前一个数字的差值。如果差值与当前趋势相反(比如,当前趋势是上升,但新数字比前一个数字小,即出现了下降趋势),则说明我们找到了一个新的峰值或谷值。此时,增加摆动序列的长度,并更新趋势。
-
忽略相同数字:如果新数字与前一个数字相同,那么不改变趋势,也不增加摆动序列的长度。
-
返回结果:遍历完整个序列后,返回摆动序列的长度。
这个过程就像是在走山路时,每当你上坡或下坡时,就停下来数一下你已经走过了多少个坡(不管是上坡还是下坡,都算一个)。如果你走在平地上(即数字相同),就继续走,不数。
在求解摆动序列的最大长度问题时,所采用的贪心策略核心在于:尽可能多地捕捉序列中的峰值和谷值,同时忽略那些不构成新摆动的“过渡元素”。这种策略之所以被称为贪心,是因为在每一步选择中,我们都局部最优地(即贪心地)决定是否将当前元素计入摆动序列的长度中,而无需考虑全局所有可能的选择。
class Solution
{
public:
int wiggleMaxLength(vector<int>& nums)
{
int n = nums.size(); // 获取数组的长度
if(n < 2) return n; // 如果数组长度小于2,则直接返回数组长度(因为长度为1的数组自身就是一个长度为1的摆动序列,或空数组长度为0)
int ret = 0, left = 0; // 初始化摆动序列长度为0,left变量用于存储前一个元素与当前元素的差值(代表前一个趋势)
// 遍历数组,从第一个元素到倒数第二个元素(因为我们需要比较当前元素和下一个元素)
for(int i = 0; i < n - 1; i++)
{
int right = nums[i + 1] - nums[i]; // 计算当前元素与下一个元素的差值,代表当前趋势
if(right == 0) continue; // 如果当前趋势为0(即水平,没有上升或下降),则跳过此次循环,因为不构成摆动
// 如果当前趋势与前一个趋势符号相反(即一个为正,一个为负),或者前一个趋势为0(即刚开始遍历或之前遇到了水平段),
// 则说明找到了一个新的波峰或波谷,因此摆动序列长度加1
if(right * left <= 0) ret++;
left = right; // 更新前一个趋势为当前趋势,以便进行下一次比较
}
return ret + 1; // 返回摆动序列的最大长度(注意最开始的时候本应该算2个的,但是我们只算了一个,所以我们应该加回去)
}
};
题目五——300. 最长递增子序列 - 力扣(LeetCode)

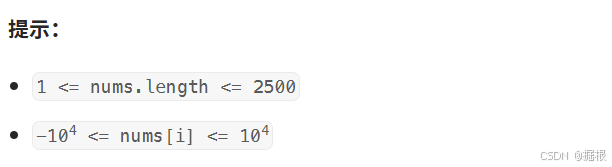
考虑一个简单的贪心,如果我们要使上升子序列尽可能的长,则我们需要让序列上升得尽可能慢,因此我们希望每次在上升子序列最后加上的那个数尽可能的小。
基于上面的贪心思路,我们维护一个数组 d[i] ,表示长度为 i 的最长上升子序列的末尾元素的最小值,用 len 记录目前最长上升子序列的长度,起始时 len 为 1,d[1]=nums[0]。
同时我们可以注意到 d[i] 是关于 i 单调递增的。因为如果 d[j]≥d[i] 且 j<i,我们考虑从长度为 i 的最长上升子序列的末尾删除 i−j 个元素,那么这个序列长度变为 j ,且第 j 个元素 x(末尾元素)必然小于 d[i],也就小于 d[j]。那么我们就找到了一个长度为 j 的最长上升子序列,并且末尾元素比 d[j] 小,从而产生了矛盾。因此数组 d 的单调性得证。
我们依次遍历数组 nums 中的每个元素,并更新数组 d 和 len 的值。如果 nums[i]>d[len] 则更新 len=len+1,否则在 d[1…len]中找满足 d[i−1]<nums[j]<d[i] 的下标 i,并更新 d[i]=nums[j]。
根据 d 数组的单调性,我们可以使用二分查找寻找下标 i,优化时间复杂度。
最后整个算法流程为:
- 设当前已求出的最长上升子序列的长度为 len(初始时为 1),从前往后遍历数组 nums,在遍历到 nums[i] 时:
- 如果 nums[i]>d[len] ,则直接加入到 d 数组末尾,并更新 len=len+1;
- 否则,在 d 数组中二分查找,找到第一个比 nums[i] 小的数 d[k] ,并更新 d[k+1]=nums[i]。
以输入序列 [0,8,4,12,2] 为例:
- 第一步插入 0,d=[0];
- 第二步插入 8,d=[0,8];
- 第三步插入 4,d=[0,4];
- 第四步插入
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









