






医疗保险欺诈是一种对医保基金造成严重损害的行为,它不仅侵害了公平正义的医疗保障体系,也直接影响到人民群众的切身利益。为了保卫人民群众的“看病钱”和“救命钱”,各级医保部门采取了严厉的措施打击欺诈行为。
在技术层面,运用数据分析方法,尤其是线性回归模型,对医疗保险欺诈进行预测和分析,已成为一种有效的监管手段。线性回归能够通过分析历史数据,识别出可能导致欺诈行为发生的因素,并建立欺诈风险预测模型。通过模型的预警,医保部门可以及时发现异常行为,采取措施预防欺诈事件的发生。
具体来说,线性回归分析的过程包括数据收集、特征选择、模型训练和验证等步骤。在数据收集阶段,需要收集包括患者就医行为、历史欺诈案件记录、医疗保险结算数据等大量信息。在特征选择阶段,要从这些数据中筛选出与医疗保险欺诈相关联的特征,例如患者年龄、性别、就医频率、药品消费习惯等。随后,利用这些特征来训练线性回归模型,模型通过学习历史数据,能够找出欺诈的规律和模式。最后,通过验证数据集来测试模型的预测准确性,并对模型进行调整优化。
此外,对于医疗机构内外勾结欺诈骗保的行为,除了运用技术手段进行预测和分析外,还需要从制度上建立和强化长效监管机制。这包括但不限于完善内部控制、强化外部审计、加大违规处罚力度、提高违规成本等。同时,还要加强对医疗机构、医务人员的教育培训,提高他们的职业道德和法律意识,从源头上减少欺诈行为的发生。
通过上述措施,可以有效地预测和分析医疗保险欺诈行为,保护医保基金的安全,确保人民群众能够享受到实实在在的医疗保障。
根据以上的功能需求情况,整体的功能模块包括有前台vue项目模块,后台Django项目模块和爬虫模块。前台vue的页面主要页面包括注册与登录页面,数据可视化展示页面,爬虫模块主要用来爬取网站的相关数据信息,利用离线数仓技术,构建高效、可扩展的数据存储和管理架构。用图表、热力图、词云等形式直观地展示校园信息分析结果,帮助用户快速理解信息态势。通过使用hadoop进行数据的存储,后台用来提供前台所用的json数据以及给出推荐的相关的用户行为可视化分析和用户行为信息。
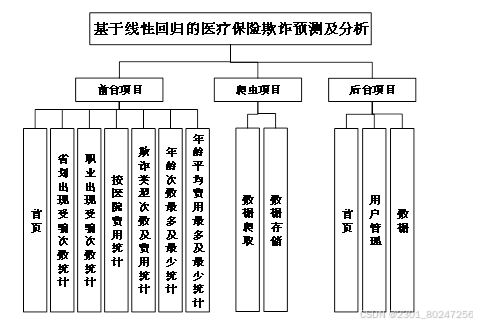
图4.2系统功能模块图
省分出现受骗次数统计:收集各省的医疗保险欺诈案例数据,对数据进行预处理,提取与欺诈发生次数相关的特征,利用线性回归模型对这些特征与欺诈发生次数之间的关系进行建模,通过训练和验证数据集来确定模型的参数。如图5-2所示。
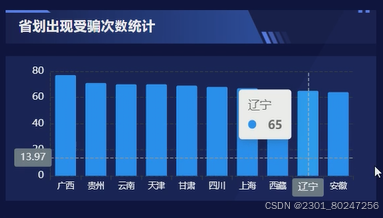
图5.2 省分出现受骗次数统计


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









