






哈希表
一.概念
//误入大佬堆的我瑟瑟发抖,让我先尽力追赶一下吧(苦笑.jpg)
1.哈希表基本原理
误区:哈希表和我们常说的 Map(键值映射)不是一个东西,Map 是一个 Java 接口,仅仅声明了若干个方法,并没有给出方法的具体实现,HashMap 是 Map 的一个实现类,而 Map 本身并不是一个具体的数据结构类。
哈希表的底层实现就是一个数组(我们不妨称之为 table)。它先把这个 key 通过一个哈希函数(我们不妨称之为 hash)转化成数组里面的索引,然后增删查改操作和数组基本相同,所以key 的值不可能出现重复,而 value 的值可以随意。
哈希函数:1.因为增删改查都会用到,所以性能很关键2.相同的key对应的输出相同,保证正确性
把非整数类型的 key 转化成整数索引:
方法一:调用 key 的 hashCode() 方法(如果不重写这个方法,那么它的默认返回值可以认为是该对象的内存地址)全局唯一
问题:
int hash(K key) {
int h = key.hashCode();
// 保证非负数
h = h & 0x7fffffff;
// 映射到 table 数组的合法索引
return h % table.length;
}哈希冲突:两个不同的 key 通过哈希函数得到了相同的索引,因为 hash 函数相当于是把一个无穷大的空间映射到了一个有限的索引空间,所以必然会有不同的 key 映射到同一个索引上。
解决方法:线性探查法的思路是,一个 key 发现算出来的 index 值已经被别的 key 占了,那么它就去 index + 1 的位置看看,如果还是被占了,就继续往后找,直到找到一个空的位置为止。
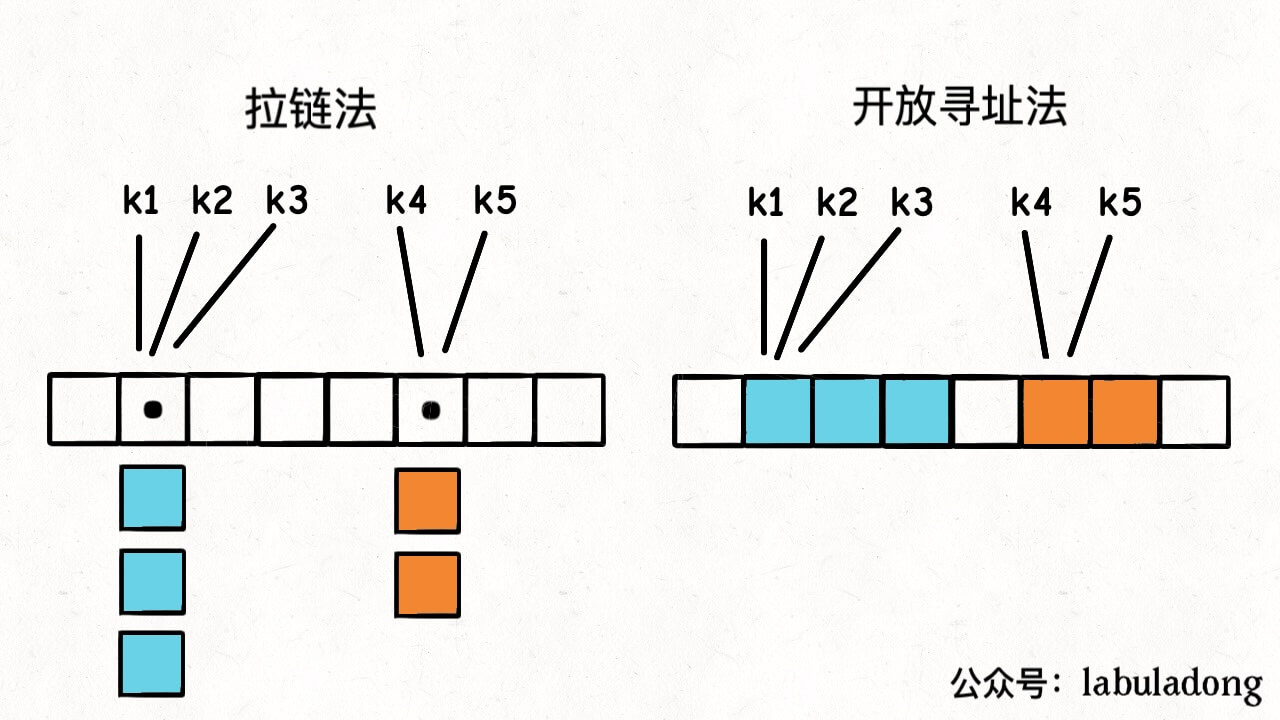
二者都会导致性能下降,所以要尽量避免出现哈希冲突,即避免哈希表装太满
负载因子是一个哈希表装满的程度的度量,一般来说,负载因子越大,说明哈希表里面的 key-value 对越多,哈希冲突的概率就越大。
负载因子的计算公式也很简单,就是 size / table.length。其中 size 是哈希表里面的 key-value 对的数量,table.length 是哈希表底层数组的容量。
Java 的 HashMap不设置的话默认是 0.75当哈希表内元素达到负载因子时,哈希表会扩容
hash 函数,它计算出的值依赖 table.length。也就是说,哈希表自动扩容后,同一个 key 的哈希值可能变化,即这个 key-value 对儿存储在 table 的索引也变了,所以遍历结果的顺序就和之前不一样的,所以不能依赖哈希表的遍历顺序
只有那些不可变类型,才能作为哈希表的 key,这一点很重要。如 Java 中的 String, Integer 等类型,一旦创建了这些对象,你就只能读取它的值,而不能再修改它的值了。
把可变类型作为key, 这样写并不会产生语法错误,但是一旦可变类型发生改变,hashcode会随之改变,存入哈希表的 key-value 就意外丢失了。
String 类型的 hashCode 方法也需要遍历所有字符,但是由于它的不可变性,这个值只要算出来一次,就可以缓存下来,不用每次都重新计算,所以平均时间复杂度 依然是 O(1)。
只有哈希函数的复杂度是 O(1),且合理解决哈希冲突的问题,才能保证增删查改的复杂度是 O(1)。
2.用拉链法实现哈希表
public class MyChainingHashMap<K,V> {
//用内置的LinkedList类,不用next指针,泛式可以让函数可使用的类型更加广泛
private static class KVNode<K,V>{
K key;
V value;
KVNode(K key, V value) {
this.key = key;
this.value = value;
}
}
//此处使用数组可以降低时间复杂度,每个数组元素是一个链表,链表中每个节点是 KVNode 存储键值对
private LinkedList<KVNode<K,V>>[] table;
private int size;//存入的键值对个数
private static final int INIT_CAP = 4;//底层数组的初始容量
public MyChainingHashMap(int initCapacity){
size = 0;
//初始化哈希表
table = (LinkedList<KVNode<K,V>>[]) new LinkedList[initCapacity];
for(int i = 0;i<table.length;i++){
table[i] = new LinkedList<>();
}
}
public MyChainingHashMap() {
this(INIT_CAP);
}
//添加键值对,若key已存在,则将值修改为val
public void put(K key,V val){
if(key == null){
throw new IllegalArgumentException("key is null");
}
LinkedList<KVNode<K,V>>list = table[hash(key)];
//若存在key,则修改对应的val值
for(KVNode<K,V>node:list){
if(node.key.equals(key)){
node.value = val;
return;
}
}
//若不存在key,则插入
list.add(new KVNode<>(key,val));
size++;
//如果超过负载因子,进行扩容
if(size >= table.length * 0.75){
resize(table.length*2);
}
}
//删除键值对
public void remove(K key){
if(key == null){
throw new IllegalArgumentException("key is null");
}
LinkedList<KVNode<K,V>>list = table[hash(key)];
for(KVNode<K,V>node:list){
if(node.key.equals(key)){
list.remove(node);
size--;
//缩容
if(size <= table.length/8){
resize(table.length/4);
}
return;
}
}
}
//查找
public V get(K key){
if(key == null){
throw new IllegalArgumentException("key is null");
}
LinkedList<KVNode<K,V>>list = table[hash(key)];
for(KVNode<K,V>node:list){
if(node.key.equals(key)){
return node.value;
}
}return null;
}
//返回所有key
public List<K> keys(){
List<K> keys = new LinkedList<>();
for (LinkedList<KVNode<K,V>>list:table){
for (KVNode<K,V>node:list){
keys.add(node.key);
}
}return keys;
}
//工具函数
private int hash(K key){
return (key.hashCode()&0x7fffffff) % table.length;
}
public int size(){
return size;
}
private void resize(int newCap){
//构造一个更大容量的HashMap
MyChainingHashMap<K,V> newMap = new MyChainingHashMap<>(newCap);
for(LinkedList<KVNode<K,V>>list:table){
for (KVNode<K,V>node:list){
newMap.put(node.key,node.value);
}
}
this.table = newMap.table;
}
//测试代码
public static void main(String[] args) {
MyChainingHashMap<Integer, Integer> map = new MyChainingHashMap<>();
map.put(1, 1);
map.put(2, 2);
map.put(3, 3);
System.out.println(map.get(1)); // 1fashixianhaxibiao
System.out.println(map.get(2)); // 2
map.put(1, 100);
System.out.println(map.get(1)); // 100
map.remove(2);
System.out.println(map.get(2)); // null
System.out.println(map.keys()); // [1, 3](顺序可能不同)
}
}
注意:不同的key可能由于哈希冲突而映射到同一个链表位置。然而,这并不意味着这些key在链表中是“相同的”或“重复的”,它们只是共享了相同的哈希值。在链表遍历的过程中仍然可以找到对应的key
3.用线性探查法实现哈希表
难点:如果直接将对应的key值变为null,则会使增加查找时的遍历出现问题,但同时也有一部分没有出现哈希冲突而没有往后放置的数值,所以如果全部往前移也会无法匹配。
正确的做法是,只把在 hash(key) = 0 出现哈希冲突的元素往前挪,其他元素要不动,这样才能保证线性探查的正确性。
public class MyLinearProbingHashMap1<K,V> {
private static class KVNode<K,V>{
K key;
V val;
KVNode(K key, V val) {
this.key = key;
this.val = val;
}
}
//存储键值对的数组
private KVNode<K,V>[] table;
//HashMap中的键值对个数
private int size;
private static final int INIT_CAP = 4;
public MyLinearProbingHashMap1(int initCapacity){
size = 0;
table =(KVNode<K, V>[]) new KVNode[initCapacity];
}
/*调用同一个类中的另一个构造函数,并传递给它 `INIT_CAP`作为参数,
即在调用无参构造函数时用默认的容量 `INIT_CAP` 来初始化 `table` 数组*/
public MyLinearProbingHashMap1(){
this(INIT_CAP);
}
//增/改
public void put(K key,V val){
if(key == null){
throw new IllegalArgumentException("key is null");
}
if(size >= table.length * 0.75){
resize(table.length * 2);
}
int index = getKeyIndex(key);
//key已存在,修改对应的val
if(table[index] != null){
table[index].val = val;
return;
}
//key不存在,在空位插入
table[index] = new KVNode<>(key,val);
size++;
}
//删
public void remove(K key){
if(key == null){
throw new IllegalArgumentException("key is null");
}
if(size <= table.length / 8){
resize(table.length/4);
}
int index = getKeyIndex(key);
if(table[index] == null){
return;
}
//开始remove
table[index] = null;
size--;
//保持元素连续性,进行rehash
index = (index + 1) % table.length;
for(;table[index] != null;index = (index+1)%table.length){
KVNode<K,V>entry = table[index];
table[index] = null;
//这里减1,因为put里面会加1
size--;
put(entry.key, entry.val);
}
}
//查
public V get(K key){
if(key == null){
throw new IllegalArgumentException("key is null");
}
int index = getKeyIndex(key);
if(table[index] == null){
return null;
}
return table[index].val;
}
//返回所有key
public List<K> keys(){
LinkedList<K> keys = new LinkedList<>();
for(KVNode<K,V> entry:table){
if(entry != null){
keys.addLast(entry.key);
}
}
return keys;
}
//工具函数
public int size(){
return size;
}
private int hash(K key){
return (key.hashCode() & 0x7fffffff) % table.length;
}
private void resize(int newCap){
MyLinearProbingHashMap1<K,V>newMap = new MyLinearProbingHashMap1<>(newCap);
for (KVNode<K,V> entry:table){
if(entry != null){
newMap.put(entry.key, entry.val);
}
}
this.table = newMap.table;
}
// 对 key 进行线性探查,返回一个索引
// 如果 key 不存在,返回的就是下一个为 null 的索引,可用于插入
private int getKeyIndex(K key){
int index;
for(index = hash(key);table[index]!=null;index = (index+1)%table.length){
if(table[index].key.equals(key)){
return index;
}
}
return index;
}
//测试代码
public static void main(String[] args) {
MyLinearProbingHashMap1<Integer, Integer> map = new MyLinearProbingHashMap1<>();
map.put(1, 1);
map.put(2, 2);
map.put(10, 10);
map.put(20, 20);
map.put(30, 30);
map.put(3, 3);
System.out.println(map.get(1)); // 1
System.out.println(map.get(2)); // 2
System.out.println(map.get(20)); // 20
map.put(1, 100);
System.out.println(map.get(1)); // 100
map.remove(20);
System.out.println(map.get(20)); // null
System.out.println(map.get(30)); // 30
}
}
还有一种方法,就是通过一个特殊值作为占位符来标记被删元素,这样就可以避免数据搬移,同时保证元素连续。但如果不对特殊值进行处理,可能会使算法陷入死循环
public class MyLinearProbingHashMap2 <K,V>{
private static class KVNode<K,V>{
K key;
V val;
KVNode(K key, V val) {
this.key = key;
this.val = val;
}
}
//被删除的 KVNode 的占位符
private final KVNode<K,V>dummy = new KVNode<>(null,null);
//存储键值对的数组
private KVNode<K,V>[] table;
//HashMap中的键值对个数
private int size;
private static final int INIT_CAP = 4;
public MyLinearProbingHashMap2(int capacity){
size = 0;
table =(KVNode<K, V>[]) new KVNode[capacity];
}
public MyLinearProbingHashMap2(){
this(INIT_CAP);
}
//增/改
public void put(K key,V val){
if(key == null){
throw new IllegalArgumentException("key is null");
}
if(size >= table.length * 0.75){
resize(table.length * 2);
}
int index = getKeyIndex(key);
//key已存在,修改对应的val
if(index != -1){
table[index].val = val;
return;
}
//key不存在
KVNode<K,V>x= new KVNode<>(key,val);
index= hash(key);
while(table[index] != null && table[index] != dummy){
index=(index+1)%table.length;
}
table[index] = x;
size++;
}
//删
public void remove(K key){
if(key == null){
throw new IllegalArgumentException("key is null");
}
if(size < table.length/8){
resize(table.length/2);
}
int index = getKeyIndex(key);
if(index == -1){
return;
}
table[index] = dummy;
size--;
}
//查
public V get(K key){
if(key == null){
throw new IllegalArgumentException("key is null");
}
int index = getKeyIndex(key);
if(index == -1){
return null;
}
return table[index].val;
}
public List<K>keys(){
LinkedList<K> keys = new LinkedList<>();
for(KVNode<K,V>entry:table){
if(entry != null){
keys.addLast(entry.key);
}
}return keys;
}
//工具函数
public int size(){
return size;
}
private int hash(K key){
return (key.hashCode() & 0x7fffffff) % table.length;
}
private int getKeyIndex(K key){
int step = 0;
for(int i = hash(key);table[i] !=null;i = (i+1)%table.length){
KVNode<K,V>entry = table[i];
if(entry == dummy){
continue;
}
if(entry.key.equals(key)){
return i;
}
step++;
//防止死循环
if(step == table.length){
//这里可以触发一次 resize,把标记为删除的占位符清理掉
resize(table.length);
return -1;
}
}
return -1;
}
private void resize(int cap){
MyLinearProbingHashMap2<K,V>newMap = new MyLinearProbingHashMap2<>(cap);
for(KVNode<K,V>entry:table){
if(entry != null&&entry !=dummy){
newMap.put(entry.key, entry.val);
}
}this.table = newMap.table;
}
public static void main(String[] args) {
MyLinearProbingHashMap2<Integer, Integer> map = new MyLinearProbingHashMap2<>();
map.put(1, 1);
map.put(2, 2);
map.put(10, 10);
map.put(20, 20);
map.put(30, 30);
map.put(3, 3);
System.out.println(map.get(1)); // 1
System.out.println(map.get(2)); // 2
System.out.println(map.get(20)); // 20
map.put(1, 100);
System.out.println(map.get(1)); // 100
map.remove(20);
System.out.println(map.get(20)); // null
System.out.println(map.get(30)); // 30
}
}
在Java中,当我们想使用哈希法来解决问题时,通常会选择以下几种数据结构:
-
HashSet
:
-
HashSet是一个不允许出现重复元素的集合。它基于哈希表实现,因此插入和查找操作的平均时间复杂度都是O(1)。 -
适用于需要快速判断一个元素是否存在于集合中的场景。
-
-
HashMap
:
-
HashMap是一个存储键值对的数据结构。键是唯一的,而值可以重复。 -
它也基于哈希表实现,因此可以通过键快速地查找、插入和删除键值对。
-
适用于需要根据键快速获取、更新或删除值的场景。
-
-
LinkedHashMap
:
-
LinkedHashMap是HashMap的一个子类,它维护了一个双向链表来记录插入顺序或访问顺序。 -
除了具有
HashMap的查找、插入和删除的高效性能外,还可以按照插入顺序或访问顺序遍历键值对。 -
适用于需要保留元素插入顺序或访问顺序的场景。
-
-
Hashtable
:
-
Hashtable是一个古老的、同步的键值对存储结构,类似于HashMap。 -
由于它是同步的,所以在多线程环境下是线程安全的,但性能上通常不如
HashMap。 -
在现代的Java开发中,
Hashtable的使用已经较少,更多地被HashMap和ConcurrentHashMap所替代。
-
-
ConcurrentHashMap
:
-
ConcurrentHashMap是一个线程安全的哈希表实现,它支持高并发场景下的插入、查找和删除操作。 -
它通过分段锁(在Java 8及以后的版本中通过CAS和同步控制块实现)来减少锁的竞争,从而提高性能。
-
适用于需要在并发环境下高效地进行键值对操作的场景。
-
在选择哈希表数据结构时,应根据具体的应用场景和需求来权衡。例如,如果不需要保留插入顺序或访问顺序,并且不需要同步,那么HashMap通常是最佳选择;如果需要在并发环境下操作键值对,则ConcurrentHashMap更为合适。
总结一下,当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法。
但是哈希法也是牺牲了空间换取了时间,因为我们要使用额外的数组,set或者是map来存放数据,才能实现快速的查找。
1.有效的字母异位词
class Solution {
public boolean isAnagram(String s, String t) {
//字母数量不同,直接返回
if(s.length() != t.length()){
return false;
}
//将小写字母出现次数创建为一个数组
//字符是由ASCII码表示的,如果直接用charAt(i)就不是偏移量,会超出索引范围
int[] record = new int[26];
for(int i = 0; i<s.length();i++){
//将出现次数加一
record[s.charAt(i)-'a']++;
}
for(int i = 0;i<t.length();i++){
//将对应字母的出现次数减一
record[t.charAt(i)-'a']--;
}
//对每个字母出现次数进行排查
for(int count:record){
if(count != 0){
return false;
}
}
return true;
}
}要注意,使用数组来做哈希的题目,是因为题目都限制了数值的大小。
而如果没有限制数值的大小,就无法使用数组来做哈希表了。
2.两个数组的交集
直接使用set 不仅占用空间比数组大,而且速度要比数组慢,set把数值映射到key上都要做hash计算的。
class Solution {
public int[] intersection(int[] nums1, int[] nums2) {
if(nums1 == null||nums1.length == 0||nums2 == null||nums2.length == 0){
return new int[0];
}
Set<Integer> set1 = new HashSet<>();
Set<Integer> resSet = new HashSet<>();
//先遍历第一个数组
for(int i:nums1){
//如果换成数组的话添加会受到数组长度限制,且不去重,所以用set1
set1.add(i);
}
//再遍历第二个数组,将相同的内容存放进去
for(int i:nums2){
//数组不能快速查询,所以此处用set1
if(set1.contains(i)){
resSet.add(i);
}
}
//将HashSet转成数组
int[] result = new int[resSet.size()];
int j = 0;
for(int i:resSet){
result[j++] = i;
}
return result;
}
}3.快乐数
「快乐数」定义为:对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和,然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。如果 可以变为 1,那么这个数就是快乐数。
无限循环的话sum会重复出现,而此时要判断sum是否出现在集合中,所以此处需要哈希法
class Solution {
public boolean isHappy(int n) {
Set<Integer> record = new HashSet<>();
//如果陷入无限循环那就能在record中找到n,则退出循环
while(n!=1 && !record.contains(n)){
//把对应n放入record中,从而进行查询
record.add(n);
n = getMaxNumber(n);
}
//可能的返回有两种情况,进行判断
return n == 1;
}
private int getMaxNumber(int n){
int res = 0;
while(n>0){
int temp = n%10;
res += temp*temp;
n = n/10;
}
return res;
}
}4.两数之和
方法一:
class Solution {
public int[] twoSum(int[] nums, int target) {
int[] res = new int[2];
//排除异常情况
if(nums == null||nums.length == 0){
return res;
}
Map<Integer,Integer> map = new HashMap<>();
for(int i = 0;i<nums.length;i++){
//因为最后是要求索引,所以将索引作为key,而把实际的值作为value
int temp = target - nums[i];
if(map.containsKey(temp)){
res[0] = i;
res[1] = map.get(temp);
break;
}
//刚开始肯定凑不够,所以得往里填数据
map.put(nums[i],i);
}
return res;
}
}方法二:
class Solution {
public int[] twoSum(int[] nums, int target) {
int m=0,n=0,k;
int[]res = new int[2];
int[]tmp1 = new int[nums.length];
//备份数组
System.arraycopy(nums,0,tmp1,0,nums.length);
//排序
Arrays.sort(nums);
//双指针
for(int i=0,j=nums.length-1;i<j;){
if(nums[i]+nums[j]<target)
i++;
else if(nums[i]+nums[j]>target)
j--;
else if(nums[i]+nums[j]==target){
m=i;
n=j;
break;
}
}
//找到nums[m]在tmp1数组中的下标
for(k=0;k<nums.length;k++){
if(tmp1[k] == nums[m]){
res[0] = k;
break;
}
}
//找到nums[n]在tmp1数组中的下标
for(int i = 0;i<nums.length;i++){
//防重复
if(tmp1[i]==nums[n]&&i!=k){
res[1] = i;
break;
}
}
return res;
}
}
该方法实际上是借用了二分查找的思想,将数组按大小排序后首尾相加,再根据相加后的结果比大小,通过比大小来往前或往后,再由于要求原本数组的索引,所以要拷贝一份数组
5.四数相加Ⅰ
class Solution {
public int fourSumCount(int[] nums1, int[] nums2, int[] nums3, int[] nums4) {
int res = 0;
Map<Integer,Integer>map = new HashMap<>();
for(int i:nums1){
for(int j:nums2){
//该方法实际上是先从map中取出sum对应的次数,再加一放入map中
int sum = i+j;
//此处sum的值更加重要,要算出它出现的次数,所以将sum作为key存放
map.put(sum,map.getOrDefault(sum,0)+1);
}
}
for(int i:nums3){
for(int j:nums4){
//直接查询map中是否有nums3和nums4中的数相加后的相反数的次数
res+=map.getOrDefault(-i-j,0);
}
}return res;
}
}6.赎金信
c++的暴力解法中如果先循环ransomNote的话在第三个案例中删除第一个字符后,第二个字符会变为第一个字符,而j已经自增为1,不会再遍历到原先的第二个字符,而如果先循环magazine,那么既不影响逻辑,同时也能重新再循环ransomNote
class Solution {
public boolean canConstruct(String ransomNote, String magazine) {
if(ransomNote.length()>magazine.length()){
return false;
}
int[] record = new int[26];
for(char c:magazine.toCharArray()){
//toCharArray()将字符串转换为字符数组
record[c-'a']++;
//单纯c会是ASCII码,超出索引范围,需要算偏移值
}
for(char c:ransomNote.toCharArray()){
record[c -'a']--;
}
for(int i:record){
if(i<0){
return false;
}
}return true;
}
}7.三数之和
class Solution {
public List<List<Integer>> threeSum(int[] nums) {
List<List<Integer>> result =new ArrayList<>();
//排序方便去重
Arrays.sort(nums);
//a=nums[i],b=nums[left],c=nums[right]
for(int i = 0;i<nums.length;i++){
if(nums[i]>0){
return result;
}
//去重,如果是[-1,-1,2],判断nums[i]和nums[i+1]的话就跳过去了,而比前面的话能避免这种情况
if(i>0&&nums[i]==nums[i-1]){
continue;
}
int left = i+1;
int right=nums.length-1;
while(left<right){
int sum = nums[i]+nums[left]+nums[right];
if(sum>0)
right--;
else if(sum<0)
left++;
else{
result.add(Arrays.asList(nums[i],nums[left],nums[right]));
//避免出现[0,0,0]这种情况直接跳过没有一个,所以先有一个数组再查重
while(right>left&&nums[right]==nums[right-1]) right--;
while(right>left&&nums[left]==nums[left+1]) left++;
//去重相当于减两次,如果不重复就进下一组
right--;
left++;
}
}
}return result;
}
}8.四数之和
class Solution {
public List<List<Integer>> fourSum(int[] nums, int target) {
List<List<Integer>>result = new ArrayList<>();
Arrays.sort(nums);
for(int i =0;i<nums.length;i++){
//例如target=-10,数组为[-4,-3,-2,-1],不光要考虑大于target,还要在正数范围内
if(nums[i]>0&&nums[i]>target){
return result;
}
if(i>0&&nums[i]==nums[i-1]){
continue;
}
for(int j=i+1;j<nums.length;j++){
if(j>i+1&&nums[j]==nums[j-1]){
continue;
}
int left = j+1;
int right = nums.length-1;
while(right>left){
long sum =(long) nums[i]+nums[j]+nums[left]+nums[right];
if(sum>target){
right--;
}else if(sum<target){
left++;
}else{
result.add(Arrays.asList(nums[i],nums[j],nums[left],nums[right]));
while(right>left&&nums[right]==nums[right-1])right--;
while(right>left&&nums[left]==nums[left+1])left++;
left++;
right--;
}
}
}
}return result;
}
}本题其实和三数之和是类似的,都是通过双指针方法,left和right是不变的,只是在三数之和的基础上再加一个j=i+1,去重也类似于i,从而延伸到n数之和
总结:哈希表的题目主要分为数组,set和map
数组的题目适用于大小已知,map的题目适用于大小未知,只需要key,map的题目适用于要求索引下标,进行key和value的映射。















 219
219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









