






大家好,今天我将与大家分享一个使用Java编写的过滤非英文字符的实用示例。这个示例可以帮助你在处理文本数据时,轻松地提取出英文字符。我们将通过两个不同的代码示例来讲解这个问题,并对比分析它们的优缺点。
首先,让我们看看代码示例1:
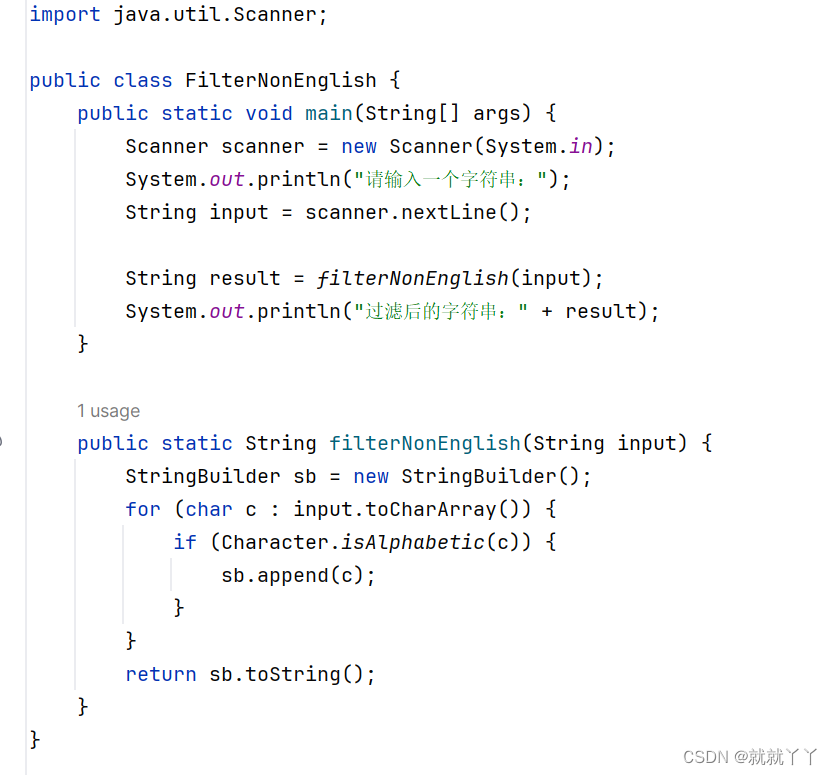
这个示例使用了Java的Scanner类来获取用户输入的字符串。接着,我们调用filterNonEnglish函数,该函数通过遍历输入字符串的每个字符,使用Character.isAlphabetic()方法判断字符是否为英文字母。如果是,则将字符添加到StringBuilder对象中。最后,将StringBuilder对象转换为字符串并返回。
接下来,我们看看代码示例2:

代码示例2与示例1的区别在于,我们不再使用函数,而是在循环中直接判断每个字符是否为英文字母,并将符合条件的字符添加到StringBuilder对象中。最后将StringBuilder对象转换为字符串并输出。
现在,让我们分析这两个示例的优缺点:
示例1的优点:
- 使用了函数,代码结构更清晰;
- 通过
Character.isAlphabetic()方法判断字符是否为英文字母,准确性较高。
示例1的缺点:
- 函数调用会增加栈空间的开销;
- 遍历字符串时,使用
Character.isAlphabetic()方法判断字符,运行速度较慢。
示例2的优点:
- 直接在循环中判断字符,减少函数调用的开销;
- 利用
StringBuilder对象动态构建结果字符串,避免多次字符串拼接操作。
示例2的缺点:
- 代码逻辑较为紧凑,不易阅读;
综合以上分析,我们可以根据实际需求和性能要求选择合适的示例。无论选择哪个示例,都要确保Java环境已安装,以便正确编译和运行代码。
这两个示例都实现了过滤非英文字符的功能,可以帮助你在处理文本数据时,轻松地提取出英文字符。希望这个示例能帮助你解决问题,如果你有任何疑问或需要进一步讨论,请随时留言。祝你编程愉快!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









