






DataLoader 是 PyTorch 中用于加载数据的工具,它能够方便地对数据进行批量加载、洗牌和并行处理等操作。通常情况下,我们会将数据集通过 Dataset 对象传入 DataLoader 中,然后在模型训练过程中使用 DataLoader 来迭代加载数据。
DataLoader 时,可以通过设置一系列参数来控制数据加载的方式,常用的参数包括:
dataset:要加载的数据集,通常是一个 Dataset 对象。
batch_size:每个批次中的样本数量。
shuffle:是否在每个 epoch 之后对数据进行洗牌,默认为 False。
num_workers:用于数据加载的子进程数目,可以加速数据加载过程。
drop_last:如果数据集大小不能被批量大小整除,是否丢弃最后一批数据,默认为 False。
pin_memory:是否将数据加载到 CUDA 的固定内存中,对于 GPU 加速训练有帮助。
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
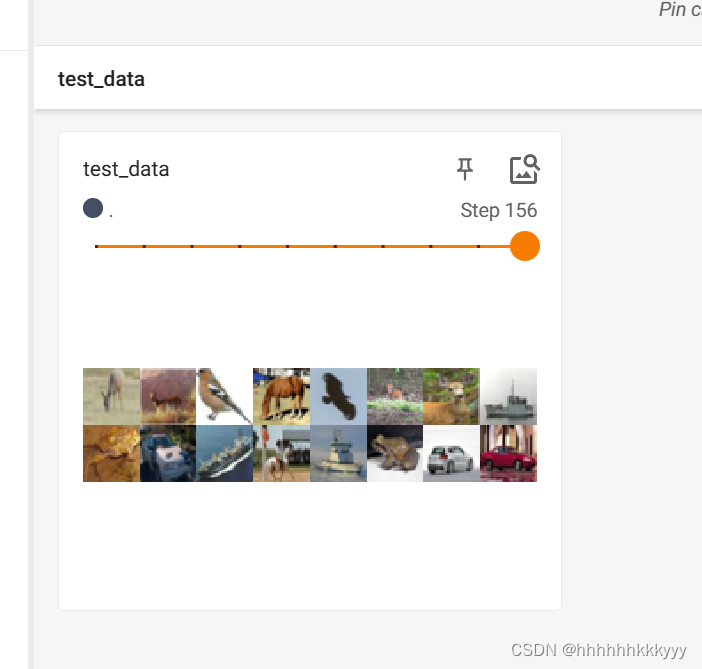
test_data = torchvision.datasets.CIFAR10(root='./dataset',train=False,transform = torchvision.transforms.ToTensor())#测试数据集
test_loader = DataLoader(dataset = test_data,batch_size = 64,shuffle=True,num_workers=0,drop_last=False)
#drop_last=Ture时,因为此时batch_size = 64不能整除最后一个不完整的batch,因此会被舍去
#drop_last=False时,则会进行保留
#shuffle Ture随机重排 False按照原序列
img, target=test_data[0]
print(img.shape)#torch.Size([3, 32, 32]) 3 个通道(红、绿、蓝),32,32表示高度和宽度
print(target)
step = 0
writer = SummaryWriter('dataloader')
for data in test_loader:
imgs,targets = data
# print(imgs.shape)
# print(targets)
writer.add_images('test_data',imgs,step)
step = step+1
writer.close()















 2176
2176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









