







1.dataloder 介绍
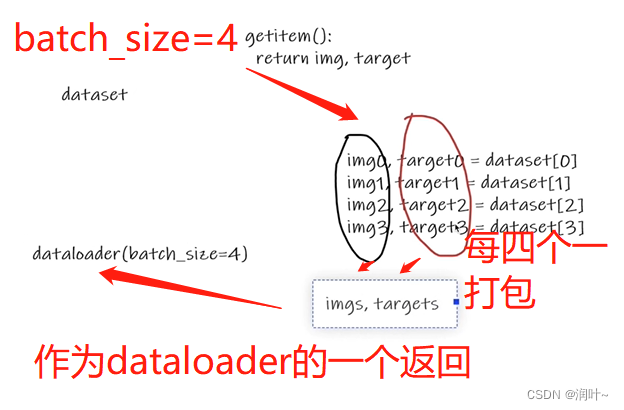
数据加载器,把数据加载到神经网络中,每次从dataset中取数据,每次取多少,怎么取,由dataloder中的参数决定。
pytorch官方文档:https://pytorch.org/docs/stable/index.html
(1)dataloader参数介绍
-
dataset (Dataset) – dataset from which to load the data.---数据集位置和信息
-
batch_size (int, optional) – how many samples per batch to load (default:
1). -
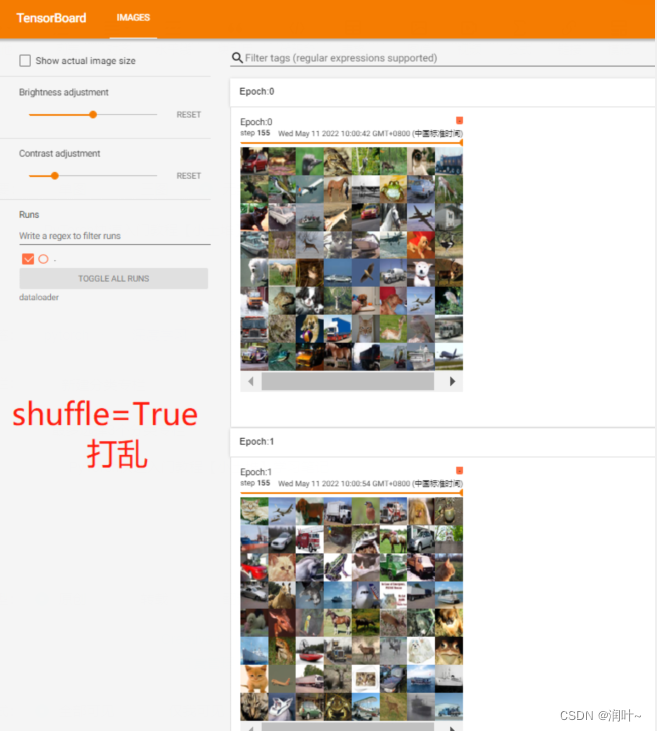
shuffle (bool, optional) – set to
Trueto have the data reshuffled at every epoch (default:False).---为true重新整理数据,false不重新整理,默认false -
sampler (Sampler or Iterable, optional) – defines the strategy to draw samples from the dataset. Can be any
Iterablewith__len__implemented. If specified,shufflemust not be specified. -
batch_sampler (Sampler or Iterable, optional) – like
sampler, but returns a batch of indices at a time. Mutually exclusive withbatch_size,shuffle,sampler, anddrop_last. -
num_workers (int, optional) – how many subprocesses to use for data loading.
0means that the data will be loaded in the main process. (default:0)---加载数据采用多进程还是单进程,默认0代表采用主进程加载 -
collate_fn (callable, optional) – merges a list of samples to form a mini-batch of Tensor(s). Used when using batched loading from a map-style dataset.
-
pin_memory (bool, optional) – If
True, the data loader will copy Tensors into CUDA pinned memory before returning them. If your data elements are a custom type, or yourcollate_fnreturns a batch that is a custom type, see the example below. -
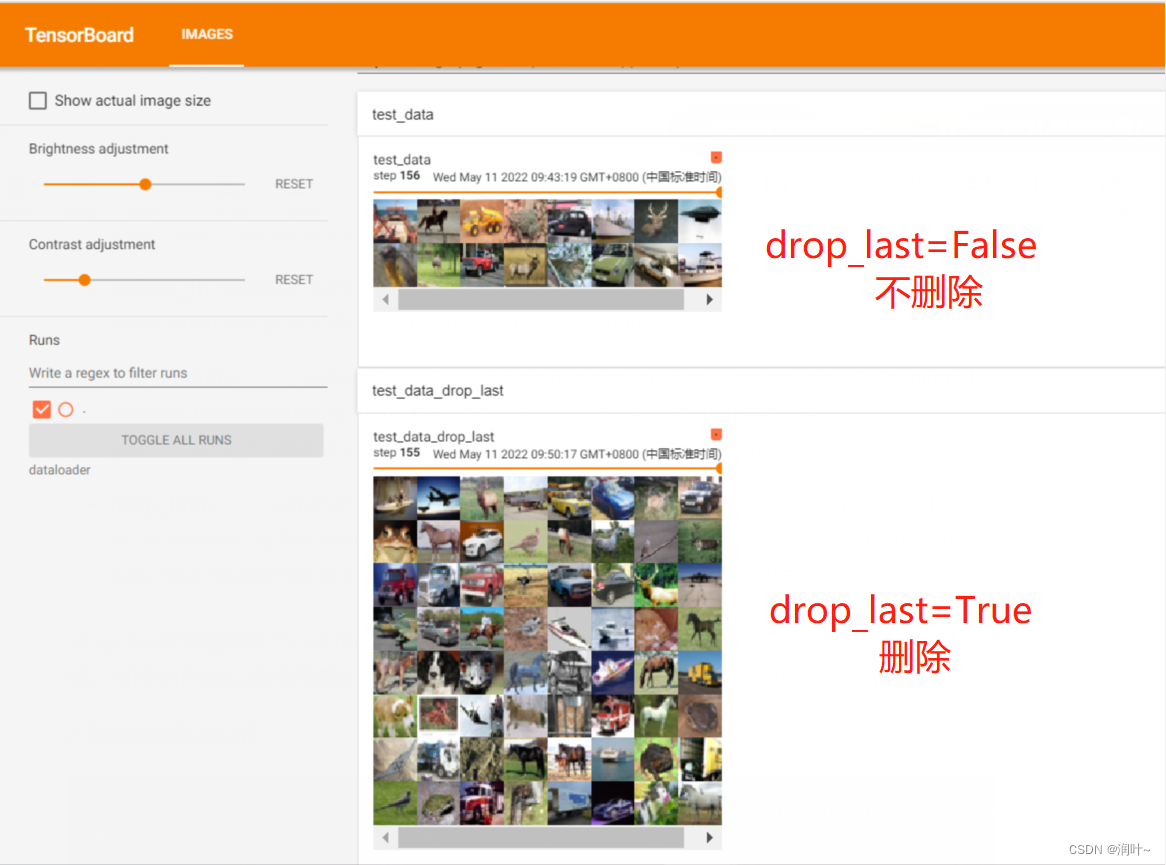
drop_last (bool, optional) – set to
Trueto drop the last incomplete batch, if the dataset size is not divisible by the batch size. IfFalseand the size of dataset is not divisible by the batch size, then the last batch will be smaller. (default:False)--true,删除最后未整除的,
drop_last如果数据集大小不能被批处理大小整除,则设置为True可删除最后一个未完成的批处理。 如果为False且数据集的大小不能被批处理大小整除,则最后一批将更小。 (默认值:False)
(2)查看返回值


注:如果tensorboard里面图片显示不出来或者显示不全,建议删掉log文件夹重新运行
2.代码实现
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
#准备的测试数据集
test_data=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
# test_loader=DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=False)
# test_loader=DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=True)
test_loader=DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=True)
#batch_size=4 每次从test_data中随机抓取4个数据
#测试数据集中第一张图片及target
img,target=test_data[0]
print(img.shape)
print(target)
writer=SummaryWriter("dataloader")
for epoch in range(2):
step=0
for data in test_loader:
imgs,targets=data
# print(imgs.shape)
# print(targets)
#writer.add_images("test_data",imgs,step)# drop_last=False 最后保留
#writer.add_images("test_data_drop_last", imgs, step) #drop_last=true 最后不保留
writer.add_images("Epoch:{}".format(epoch), imgs, step)
step=step+1
writer.close()3.运行结果















 5960
5960











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









