






哈希表
作用:把一个复杂的数据结构映射到比较小的区间0到n,比如把0到10^9的数映射到0到10^5内
离散化可以看做是一个极其特殊的哈希方式
这就会产生冲突,就是某些数映射成同一个数,为了处理冲突有两种方法,拉链法和开放寻址法,当然开放寻址法靠运气咯
哈希算法是一个期望算法,在算法题里面一般只会添加一个数和查找一个数,一般不会有删除操作,如果有删除操作,一般不会真的删除某个点,可以开一个bool数组在删除的点上做个标记
1.存储结构
两种方法都可以用
①拉链法
顾名思义,开一个一维数组来存储所有的哈希值,一般数组长度取成质数,要离2的整数次幂较远,这样冲突的情况较少(emm 目前我也不知道为啥,有兴趣可以搜一下)
处理冲突:每个x映射到几就在哪个槽下面拉个数,如果映射到同一个数,就继续在下面拉一条链子
每个链的长度很短在一般情况下时间复杂度可以看作O(1)
例题
维护一个集合,支持如下几种操作:
1.I x,插入一个整数 x
2.Q x,询问整数 x是否在集合中出现过;
现在要进行 N次操作,对于每个询问操作输出对应的结果。
输入格式:
第一行包含整数 N,表示操作数量。
接下来 N行,每行包含一个操作指令,操作指令为 I x,Q x 中的一种。
输出格式:
对于每个询问指令 Q x,输出一个询问结果,如果 x在集合中出现过,则输出 Yes,否则输出 No。
每个结果占一行。
数据范围
1≤N≤10^5
−10^9≤x≤10^9
输入样例:
5
I 1
I 2
I 3
Q 2
Q 5
输出样例:
Yes
No
代码如下
#include<iostream>
#include<cstring>
using namespace std;
const int N = 100003; // 是大于一万的第一个质数
int e[N], ne[N], h[N], idx;
/*e[N]存储的是每个节点上的值, ne[N]存储的是每个节点的指向下一个节点的指针,
h[k]存储的是哈希表k中链表的头指针,就是那个槽的位置指向第一个节点的指针,头指针,
idx是用到第几个数了*/
void insert(int x)
{
int k = abs(x % N); // x的映射方式
// int k = (x % N + N) % N; x的另一种映射方式,x % N可能是个负数+N再模N就正的了
e[idx] = x; // 将这个数记下来
ne[idx] = h[k]; // 这个节点的指向原来链子的头
h[k] = idx ++; // 那槽的头指针指向这个点
}
bool find(int x)
{
int k = abs(x % N); // 映射
for(int i = h[k]; i != -1; i = ne[i]) // 根据链表查找
if (e[i] == x) return true;
return false;
}
int main()
{
cin.tie(0);
cout.tie(0);
ios::sync_with_stdio(false);//关流,提高效率
int n;
cin >> n;
memset(h, -1, sizeof h); // 将数组里的数全变成-1,跟链表一样,代表空的,头文件是cstring
while(n --)
{
string op;
int x;
cin >> op >> x;
if (op == "I") insert(x);
else
{
if (find(x)) puts("Yes");
else puts("No");
}
}
return 0;
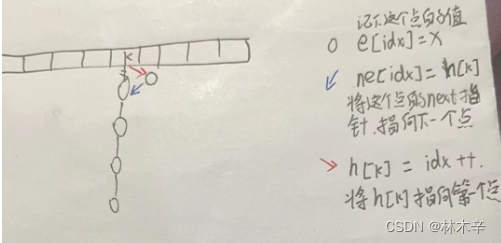
}如何理解h[k]:
一个一维数组本来都是空的,然后第一个数x映射出了一个k,这个k就是这个x在数组中所在的槽的下标位置,然后在这个槽下拉个链子,有个节点,这个节点的值就是x,h[k]就是头指针,就好像k这个槽指向第一个节点,当我们取这个点就是i = h[k], 值就是e[i]
插入操作:
②开放寻址法
只开了一维数组,没有开列表,一般开到题目范围的两到三倍,冲突概率较低
处理冲突:跟上厕所差不多, 比如求出来个h[x] = k,如果k有人就去下一个坑位
添加:比如求出来个h[x] = k,如果k有人就去下一个坑位
查找:从第k个坑开始找,如果有人,是x就找到了,如果有人不是x就去下一个坑位,如果没人,x就不存在
删除:按查找找x,找到x就给它打个标记,就相当于删除了
例题
跟上面那个一样的例题
代码如下
#include<iostream>
#include<cstring>
using namespace std;
const int N = 200003, null = 0x3f3f3f3f; // 规定空指针为null,一个很大的值,可以当作无穷大
int h[N];
// 如果在hash里,返回x的位置,如果不在返回应该存储的位置
int find(int x)
{
int k = (x % N + N) % N;
while(h[k] != null && h[k] != x)
{
k ++;
if(k == N) k = 0;
/* 数组走到头了,从头找,就假如x映射k是100,那就从100开始往后找,假如k==N了 说明从k到数组末尾都有人并且都不是
x,那k从0开始继续找,如果找到x就找到了,如果没有找到那一定会找到一个没有人的点,那这个点就是x应该存储的点
,当然如果数组满了,那就额,死循环了,不过开的时候坑就比人多*/
}
return k;
}
int main()
{
cin.tie(0);
cout.tie(0);
ios::sync_with_stdio(false);
int n;
cin >> n;
memset(h, 0x3f, sizeof h);
// int是4个字节,每个字节就是3f,所以数组中每个元素被初始化成了0x3f3f3f3f,也就是空指针
while(n -- )
{
string op;
int x;
cin >> op >> x;
int k = find(x); // k就是x存储的位置或者应该存储的位置
if (op == "I") h[k] = x; // hash表里没有x那k的含义就是应该存储的位置,让其值等于x
else
{
if (h[k] == null) puts("No"); // 如果找出来结果是个空的位置,那就是表里没有x
else puts("Yes");
}
}
return 0;
}关于memset:https://blog.csdn.net/lyj2014211626/article/details/65481630
2.字符串哈希方式
(字符串前缀哈希法)
基本思路:
1.首先预处理所有前缀的哈希值,规定h[0] = 0; h[i] = h[i - 1] * p + str[i];
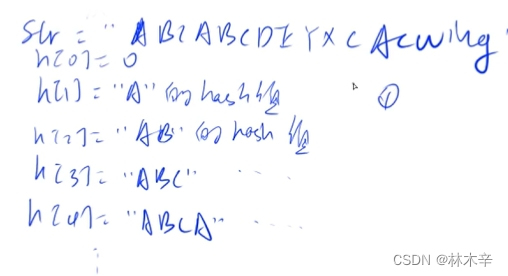
2.把字符串看成p进制的数 如“ABCD”,第一位数上的数是a以此类推,比如我们可以将a映射成1,b映射成2,可以看成(1 2 3 4)p

3.因为到后面数的位数很长,可以将p进制的数转化成十进制的数,模上一个数Q
【注】:
1.一般不能把字母映射成0; 假如A映射成0,那AA也是0,那就冲突了
2.这种方法假设Rp足够好,不存在冲突; 经验值一般 p = 131 或 13331 Q = 2 ^ 64; 99%情况下不会冲突(前面是有冲突但是有方法可以处理冲突,这种方法是假定我们人品够好,没有冲突,emmm要相信前辈们的经验)
优点:
可以利用求得的前缀hash,用一个公式求得所有子段(某个区间内的字符串)的hash值
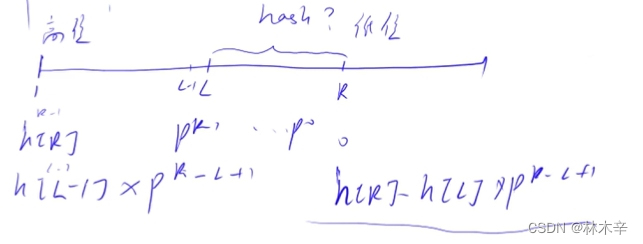
我们通过预处理知道了h[R]和 h[L - 1]的哈希值,让h[L - 1] * p^(R - L + 1),也就是往左挪R - L + 1位,错位相减嘛, 就像ABCDE 与 ABC 的前三个字符值是一样,只差两位,乘上P的二次方把 ABC 变为 ABC00,再用 ABCDE - ABC00 得到 DE 的哈希值。 这样不就得到了区间L到R的哈希值了嘛。 聪明的小朋友已经想到了,不是要模上Q(2的64次方)吗,其实我们可以用unsigned long long 来存储所有的h,它会溢出,这样就等价于取模了,详细的溢出在最下面。
作用:
它有个让kmp望而却步的作用,很多时候,很复杂的思路用kmp来做,可以用非常简单的字符串哈希来做
例题:
给定一个长度为 n的字符串,再给定 m个询问,每个询问包含四个整l1,r1,l2,r2请你判断 [l1,r1] 和 [l2,r2]这两个区间所包含的字符串子串是否完全相同。
字符串中只包含大小写英文字母和数字。
输入格式:
第一行包含整数 n和 m,表示字符串长度和询问次数。
第二行包含一个长度为 n的字符串,字符串中只包含大小写英文字母和数字。
接下来 m行,每行包含四个整数 l1,r1,l2,r2,表示一次询问所涉及的两个区间。
注意,字符串的位置从1开始编号。
输出格式:
对于每个询问输出一个结果,如果两个字符串子串完全相同则输出 Yes,否则输出 No。
每个结果占一行。
数据范围
1 ≤ n,m ≤ 10^5
输入样例:
8 3
aabbaabb
1 3 5 7
1 3 6 8
1 2 1 2
输出样例:
Yes
No
Yes
代码:
#include<iostream>
using namespace std;
typedef unsigned long long ULL; // 用这个定义h数组,可以免去取模
const int N = 100010, P = 131; // 13331
int n, m;
string str; // 存储字符数组
ULL h[N], p[N]; // h[N] 存储预处理的哈希值,h[i]是前i个字符的hash值 p[k] 意思是p ^ k;
ULL get(int l, int r)
{
return h[r] - h[l - 1] * p[r - l + 1]; // 求区间内字符串的哈希值
}
int main()
{
cin.tie(0);
cout.tie(0);
ios::sync_with_stdio(false);
cin >> n >> m;
cin >> str ;
p[0] = 1;
// h[0] 直接就是 0了,可以不用再写了
for (int i = 1; i <= n; i ++ )
{
p[i] = p[i - 1] * P; // 类似于 2 ^ 6 = 2 ^ 5 * 2
h[i] = h[i - 1] * P + str[i - 1]; /* 映射方式一般为该字母的ASCLL码,p进制看不懂的看十进制,1234,h[1]是1,h[2]是1*10+2就是12
这里是str[i - 1]是因为string str这个是从零开始输入的,记得i要减一,当然可以写成char str[N] 然后再 cin >> str + 1;这样这里可以直接写成str[i] */
}
while (m -- )
{
int l1, r1, l2, r2;
cin >> l1 >> r1 >> l2 >> r2;
if (get(l1, r1) == get(l2, r2)) puts("Yes");
else puts("No");
}
return 0;
}问题点:
unsigned long long 的溢出:
unsigned long long是一种无符号的长整型数据类型,通常用于存储较大的非负整数。溢出指的是当一个变量的值大于它所能表示的最大值时发生的情况。对于unsigned long long,它的最大值取决于编译器和平台,但通常是2^64 - 1。
溢出可能发生在对该类型的变量进行算术运算时,例如加法、减法、乘法等。当结果超出了unsigned long long类型所能表示的范围时,就会发生溢出。
例如,在unsigned long long类型的最大值为2^64 - 1时,如果你尝试将其加1,结果会回到0,这就是溢出的一种常见情况。
所以让其自然溢出,也就是说本身就模上了2^64,也就是模上了Q















 2577
2577











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









