






爬取糗事百科段子:
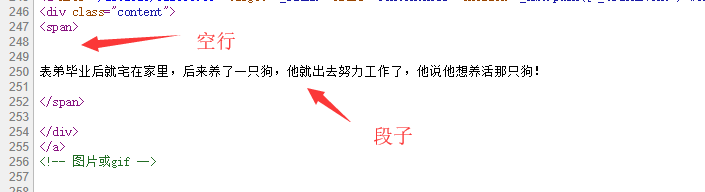
段子在 <div class="content"> 里面的 <span> 标签里面
不过这里有个坑,div 标签跟 span 标签 之间有很多空行
普通 .*? 是匹配不了的,需要使用模式修饰符 S
S 的意思 让 .(点) 匹配,包括换行符
我们来爬文字的段子
先看看他的 url 有什么规律,
https://www.qiushibaike.com/text/page/1/
第一页就是 1 ,第 2 页就是 2
代码跟之前几乎一样,只是正则不同,应该不需要怎么介绍了
代码:
import urllib.request import re import time headers = ( "User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36" ) opener = urllib.request.build_opener() opener.addheaders = [headers] urllib.request.install_opener(opener) # 安装为全局 for i in range(1,5): this_url = "https://www.qiushibaike.com/text/page/"+str(i)+"/" data = urllib.request.urlopen(this_url).read().decode("utf-8","ignore") path = '<div class="content">.*?<span>(.*?)</span>.*?</div>' resut = re.compile(path,re.S).findall(data) for j in resut: print(j) time.sleep(0.5)
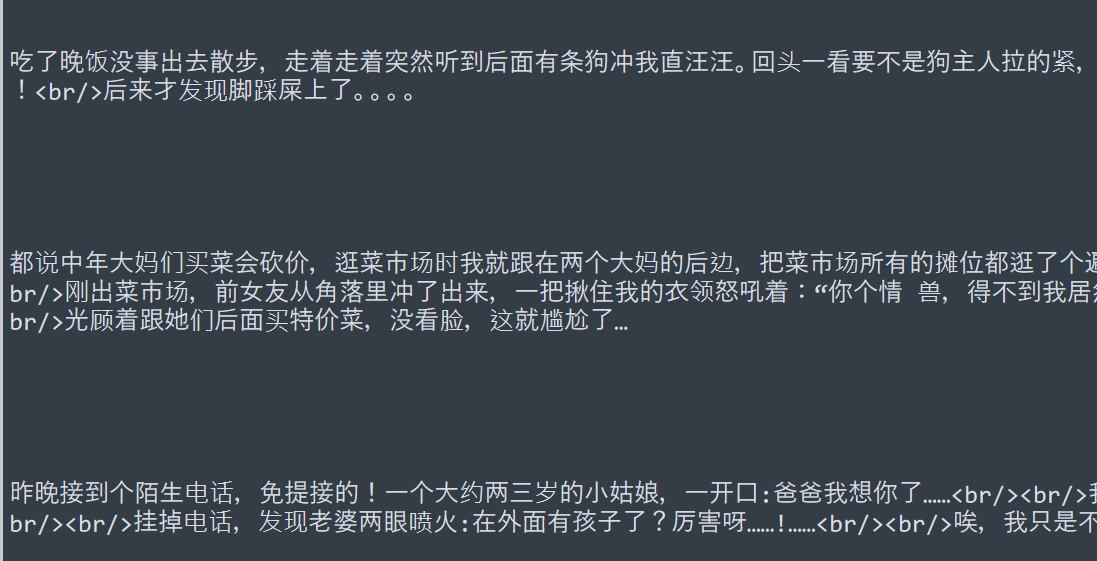
运行效果就这样
如果怕请求出错的话,
可以使用 try except 方法来捕获异常
















 231
231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











