







概念:
-
当有一堆任务要处理,但由于资源有限,这些事情没法同时处理。这就需要确定某种规则来决定处理这些任务的顺序
三个层次:
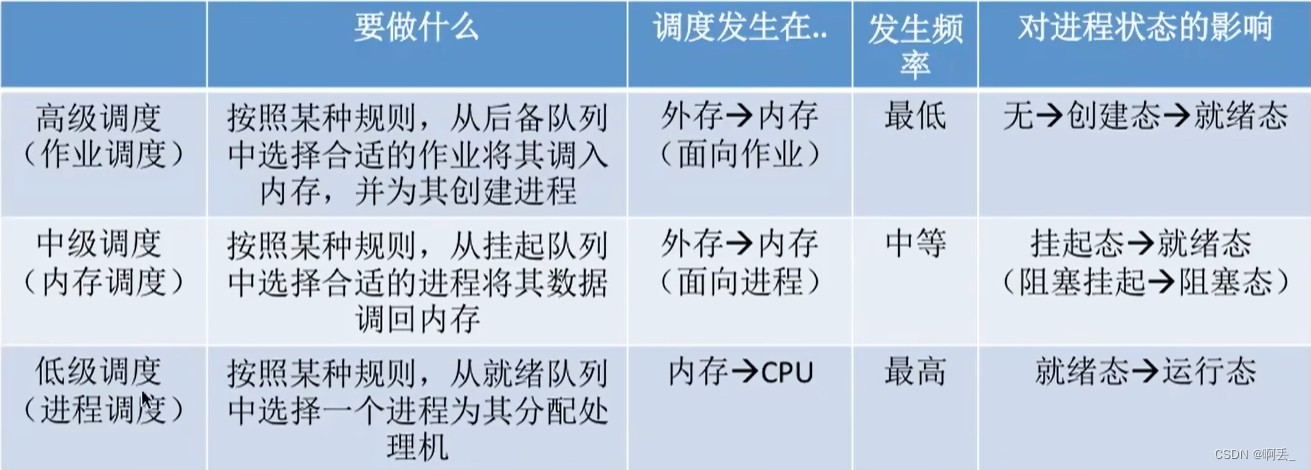
高级调度(作业调度):
-
按一定的原则从外存的作业后备队列中挑选一个作业调入内存,并创建进程。每个作业只调入一次,调出一次。作业调入时会建立PCB,调出时才撤销PCB
低级调度(进程调度):
-
按照某种策略从就绪队列中选取一个进程,将处理机分配给它
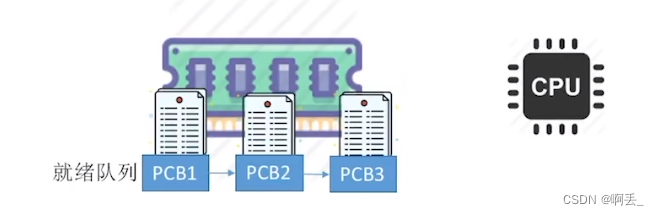
![]() 编辑
编辑

![]() 编辑
编辑
不能进行进程调度与切换的情况:
-
在处理中断的过程中。中断处理过程复杂,与硬件密切相关,很难做到在中断处理过程中进行进程切换
-
进程在操作系统内核临界区中
-
在原子操作过程中(原语)。原子操作不可中断,要一气呵成(如之前讲过的修改PCB中进程状态标志,并把PCB放到相应队列)
临界资源:一个时间段内只允许一个进程使用的资源。各进程需要互斥地访问临界资源内核程序临界区:一般是用来访问某种内核数据结构的,比如进程的就绪队列(由各就绪进程的PCB组成)
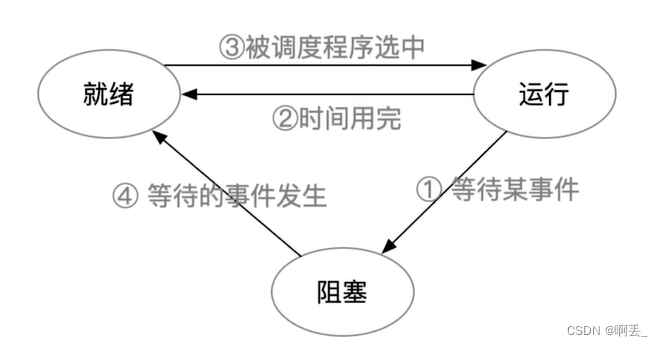
调度方式:
-
非剥夺调度方式(非抢占方式):即,只允许进程主动放弃处理机。在运行过程中即便有更紧迫的任务到达,当前进程依然会继续使用处理机,直到进程终止或主动要求进入阻塞态。【实现简单,系统开销小但是无法及时处理紧急任务,适合于早期的批处理系统】
-
剥夺调度方式(抢占方式):当一个进程正在处理机上执行时,如果有一个更重要或更紧迫的进程需要使用处理机,则立即暂停正在执行的过程,将处理机分配给更重要紧迫的那个进程【可以优先处理更紧急的进程,也可以让各进程按时间片轮流执行的功能(通过时钟中断)适合于分时操作系统、实现操作系统】
进程切换:
-
主要完成了对原来运行进程各种数据的保存
-
对新的进程各种数据的恢复(如:程序计数器、程序状态字、各种数据寄存器等处理机现场信息,这些信息一般保存在进程控制块)
中级调度(内存调度):
-
按照某种策略决定将哪个处于挂起状态的进程重新调入内存
挂起态:
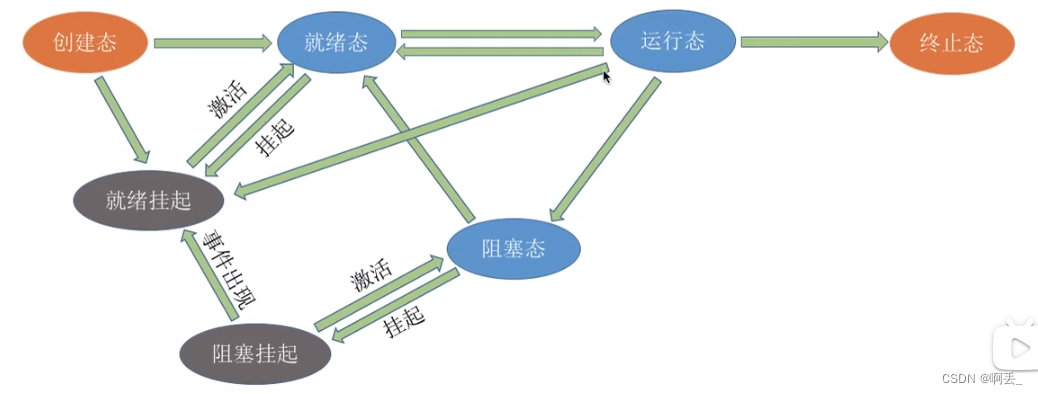
![]() 编辑
编辑
七状态模型
“挂起”和“阻塞”的区别:
两种状态都是暂时不能获得CPU的服务,但挂起态时将进程映像调到外存去了,而阻塞态下进程映像还在内存中。有的操作系统会把就绪挂起、阻塞挂起分为两个挂起队列,甚至会根据阻塞原因不同再把阻塞挂起进程进一步细分为多个队列
![]() 编辑
编辑
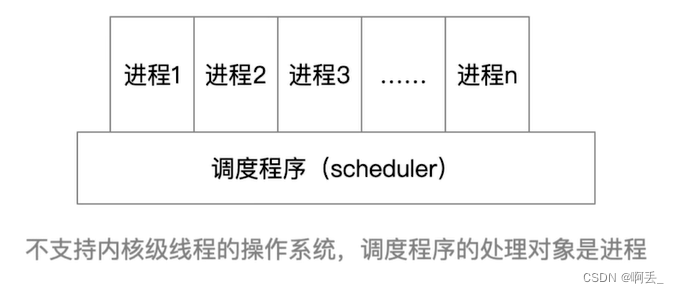
调度程序:
![]() 编辑
编辑
![]() 编辑
编辑
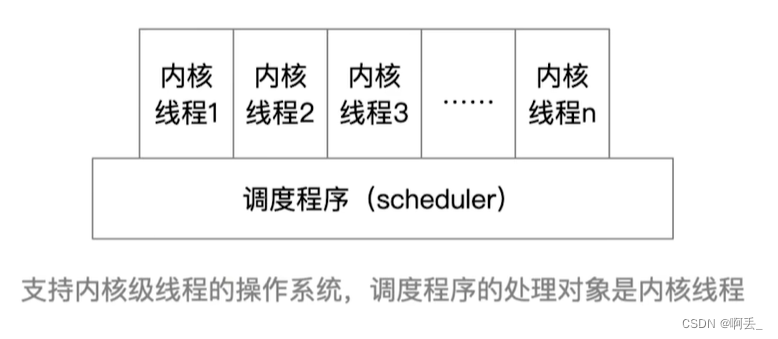
![]() 编辑
编辑
闲逛进程:
-
调度程序永远的备胎,没有其他就绪进程时,运行闲逛进程
特性:
-
优先级最低
-
可能是0地址指令,占一个完整的指令周期(指令周期末尾例行检查中断)
-
能耗低
调度算法的评价指标:
CPU利用率:指CPU“忙碌”的时间占总时间的比例
公式:利用率=忙碌时间/总时间
例:某计算机只支持单道程序,某个作业刚开始需要在CPU上运行5秒,再用打印机打印输出5秒,之后再执行5秒,才能结束。在此过程中,CPU利用率、打印机利用率分别是多少?答:
编辑
编辑
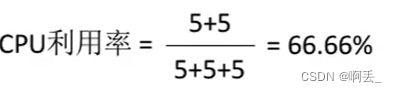
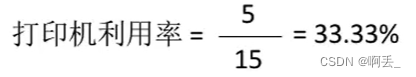
系统吞吐量:单位时间内完成作业的数量
公式:系统吞吐量=总共完成了多少道作业/总共花了多少时间
例:某计算机系统处理完10道作业,总共花费100秒,则系统吞吐量为?
答:10/100=0.1道/秒
周转时间:
-
是指从作业提交给系统开始,到作业完成为止的这段时间间隔
-
它包括四个部分:作业在外存后备队列上的能带作业调度(高级调度)的时间、进程在就绪队列上等待进程调度(低级调度)的时间、进程在CPU上执行的时间、进程等待I/O操作完成的时间。后三项在一个作业的整个过程中,可能发生多次。
公式:
作业周转时间=作业完成时间-作业提交时间
平均周转时间=各作业周转时间之和/作业数
带权周转时间=作业周转时间/作业实际运行时间=(作业完成时间-作业提交时间)/作业实际运行的时间
等待时间:指进程/作业处于等待处理机时间之和,等待时间越长,用户满意度越低
![]() 编辑
编辑
-
对于进程来说,等待时间就是指进程建立后等待被服务的时间之和,在等待I/O完成的期间其实进程也是在被服务的,所以不计入等待时间。
-
一个作业总共需要被CPU服务多久,被I/O设备服务多久一般是确定不变的,因此调度算法其实只会影响进程/作业的等待时间。当然,与前面指标类似,也有“平均等待时间”来评价整体性能
响应时间:指从用户提交请求到首次响应所用的时间
调度算法:
先来服务(FCFS):【非抢占式算法】
算法思想:主要从“公平”的角度考虑(类似于我们生活中排队买东西的例子)
算法规则:按照作业/进程到达的先后顺序进行服务
用于作业/进程调度:
作业调度:考虑的是哪个作业先到达后到达后备队列
进程调度:考虑的时哪个进程先到达就绪队列
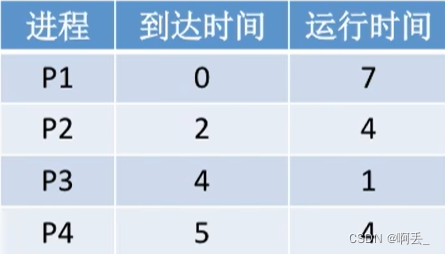
例:各进程到达就绪队列的时间、需要运行时间如下表所示。使用先来先服务调度算法,计算各进程的等待时间、平均等待时间、周转时间、平均周转时间、带权周转时间、平均带权周转时间。
答:
调度顺序为:p1->p2->p3->p4
周转时间=完成时间-到达时间
带权周转时间=周转时间/运行时间
等待时间=周转时间-运行时间


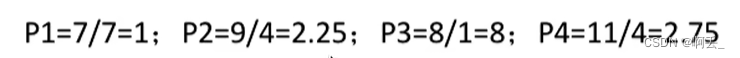

优点:公平、算法实现简单
缺点:排在长作业和(进程)后面的短作业需要等待很长的时间,带权周转时间很大,对短作业来说用户体验不好。即,FCFS算法对长作业有利,对短作业不利(如排队买奶茶)
短作业优先(SJF):
算法思想:追求最少的平均等待时间,最少的平均周转时间、最少的平均带权周转时间
算法规则:最短的作业/进程优先得到服务(所谓”最短“,是指要求服务时间最短)
用于作业/进程调度:可用于作业调度,也可用于进程调度。用于进程调度时称为”短进程优先(SPF)算法“
是否可抢占:SJF和SPF时非抢占式的算法。但也有抢占式版本——最短剩余时间优先算法(SRTN)
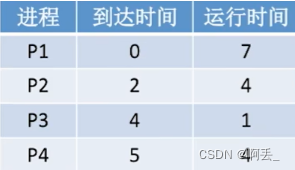
例题:各进程到达就绪队列的时间、需要运行时间如下表所示。使用非抢占式的短作业优先调度算法,计算各进程的等待时间、平均等待时间、周转时间、平均周转时间、带权周转时间、平均带权周转时间。
答:
短作业/进程优先调度算法:每次调度时选择当前已到达且运行时间最短的作业/进程
调度顺序:p1->p3->p2->p4
周转时间:
带权周转时间:
等待时间:

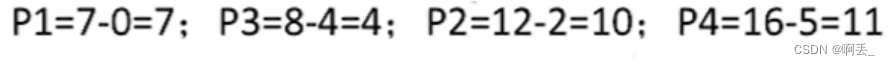
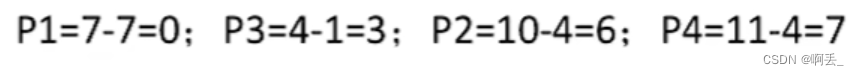

高响应比优先(HRRN):
算法思想:要综合考虑作业/进程的等待时间和要求服务的时间
算法规则:在每次调度时先计算各个作业/进程的响应比,选择响应比最高的作业/进程为其服务
-
公式:响应比=(等待时间+要求服务时间)/要求服务时间
用于作业/进程调度:既可用于作业调度,也可用于进程调度
是否可抢占:非抢占式的算法
-
因此只有当前运行的作业/进程主动放弃处理机时,才需要调度,才需要计算响应比
例题:各进程到达就绪队列的时间、需要运行时间如下表所示。使用非抢占式的短作业优先调度算法,计算各进程的等待时间、平均等待时间、周转时间、平均周转时间、带权周转时间、平均带权周转时间。
答:
0时刻:只有P1到达就绪队列,P1上处理机
7时刻(P1主动放弃CPU):就绪队列中有P2(响应比=(5+4)/4=2.25)、P3((3+1)/1=4) 、P4((2+4)/4=1.5)
8时刻(P3完成):P2(2.5)、P4(1.75)
12时刻(P2完成):就绪队列中只剩下P4

优点:
- 综合考虑了等待时间和运行时间(要求服务时间)
- 等待时间相同时,要求服务时间短的优先(SJF的优点)
- 要求服务时间相同时,等待时间长的优先(FCFS的优点)
- 对于长作业来说,随着等待时间越来越久,其响应比也会越来越大,从而避免了长作业饥饿的问题
时间片轮转调度算法(RR):
算法思想:公平的、轮流地为各个进程服务,让每个进程在一定时间间隔内都可以得到响应
算法规则:按照各进程到达就绪队列的顺序,轮流让各个进程执行一个时间片(如100s).若进程未在一个时间片内执行完,则剥夺处理机,将进程重新放到就绪队列队尾重新排队
用于作业/进程调度:用于进程调度(只有作业放入内存建立了相应的进程后,才能被分配处理机时间片)
是否可抢占?若进程未能在时间片内运行完,将被强行剥夺处理机使用权,因此时间片轮转调度算法属于抢占式算法。由时钟装置发出时钟中断来通知CPU时间片已到
例题:
当时间片为2时:
当时间片为5时:






注:
- 如果时间片太大,则会退化为先来先服务调度算法,并且会增大进程响应时间,所以时间片不能太大 。
- 如果时间片太小,则进程切换会过于频繁,系统会花大量的时间来处理进程切换,从而导致实际用于进程执行的时间比例减少。
优点:
-
公平、响应快适用于分时系统
缺点:
-
由于高频率的进程切换,因此有一定的开销;不区分任务的紧急程度
是否会导致饥饿:不会导致饥饿
优先级调度算法
算法思想:随着计算机的发展,特别是实时操作系统的出现,越来越多的应用场景需要根据任务的紧急程度来决定处理顺序
算法规则:每个作业/进程有各自的优先级,调度时选择优先级最高的作业/进程
用于作业/进程调度:既可用于作业调度,也可用于进程调度。甚至,还会用于在之后会学习的I/O调度中
是否可抢占:抢占式和非抢占式的都有。
例题:(非抢占式)且优先数越大,优先级越高
抢占式
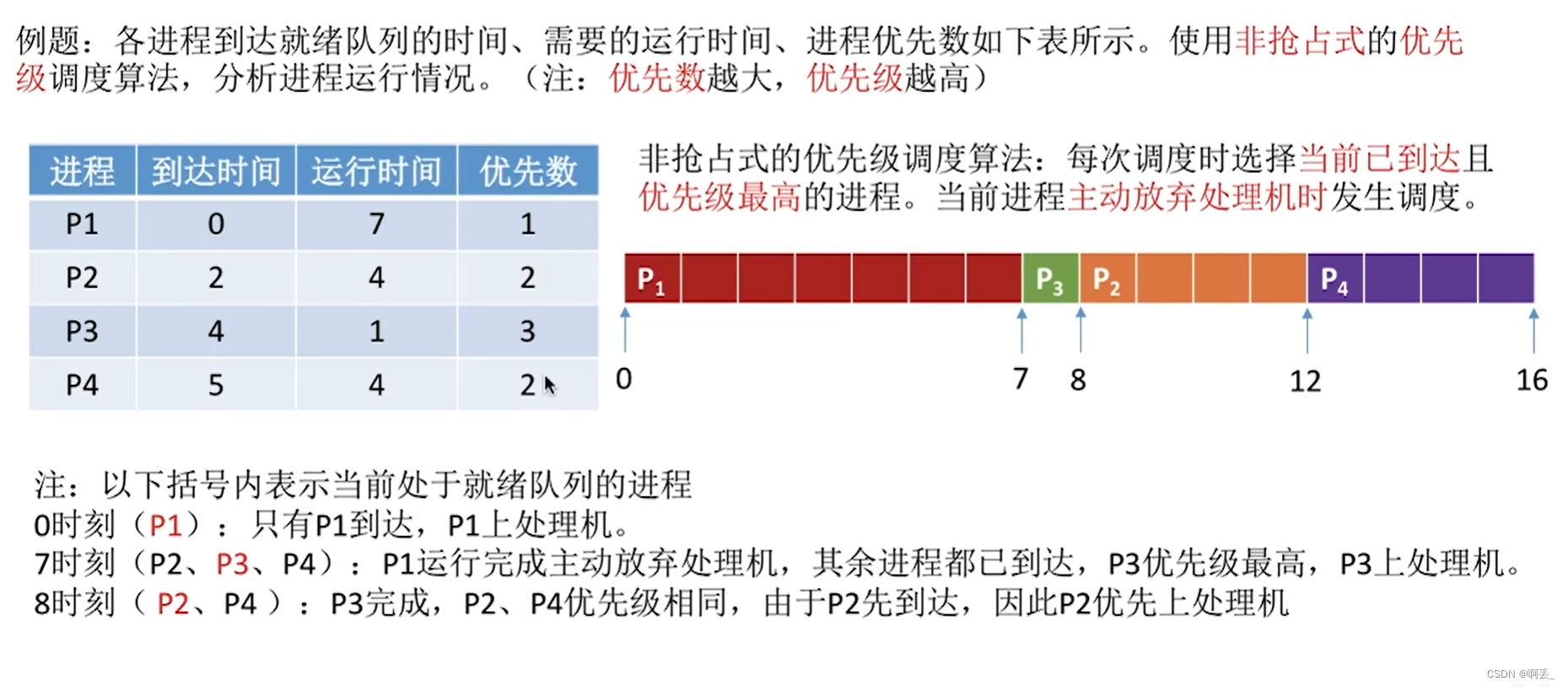

补充:就绪队列其实不止一个 ,可以按照不同优先级来组织。 另外,也可以把优先级高的进程排在更靠近队头的位置。根据优先级是否可以动态改变,可将优先级分为静态优先级和动态优先级两种
静态优先级:创建进程时确定,之后一直都不变
动态优先级:创建进程时有一个初始值,之后会根据i情况动态地调整优先级
优点:用优先级区分紧急程度、重要程度,适用于实时操作系统。可灵活的调整对各种作业/进程的偏好程度
缺点:若源源不断地有高优先级进程到来,则可能导致饥饿
是否会发生饥饿:会
多级反馈队列调度算法:
算法思想:对其他调度地这种权衡
算法规则:
-
设置多级就绪队列,各级队列优先级从高到低,时间片从小到大
-
若用完时间片段进程还未结束,则进程进入下一级队列队尾。如果此时已经是在最下级的队列队尾。如果此时已经是在最下级的队列,则重新放回该队队列队尾
-
只有第k级队列为空时,才会为k+1级队头的进程分配时间片
用于作业/调度进程:用于进程调度

通常有如上所示对应的三个级别的队列和时间片
是否可抢占?抢占式算法。在k级队列的进程运行过程中,若更上级的队列中进入了一个新进程,则由于新进程处于优先级更高的队列中,因此新进程会抢占处理机。原来运行的进程放回k级队列的队尾
例题:

优点:
-
对各类进程相对公平(FCFS的优点)
-
每个新到达的进程都可以很快得到响应(RR的优点)
-
短进程只用较少的时间就可以完成(SPF的优点)
-
不必实现估计进程的运行时间(避免啊用户造假)
-
可灵活地调整对各类进程的偏好程度,比如CPU密集型进程、I/O密集型进程















 1289
1289











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









