






一、环境配置
下载Maven软件
apache-maven-3.9.6
二、在f盘下新建文件夹maven
在maven下将软件包解压,并新建文件夹repo文件夹
在E:\maven\apache-maven-3.9.6\conf目录下打开settings.xml文件
ctrl+f搜索mirrors
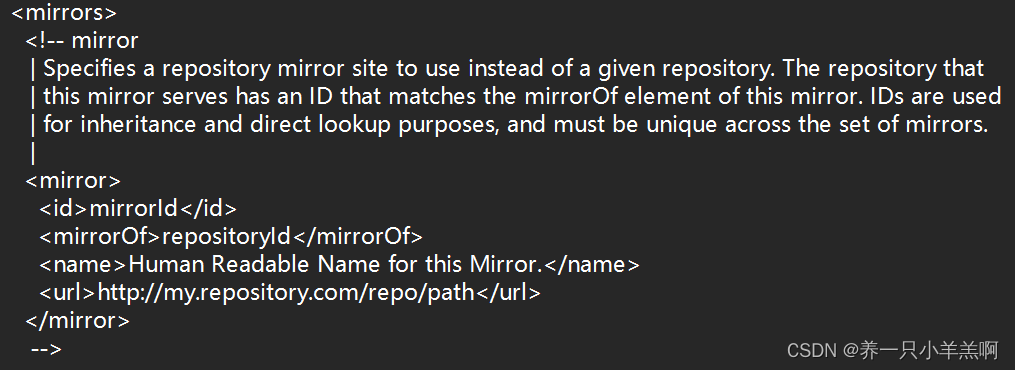
找到此段,并在<mirrors></mirrors>标签中添加
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror><mirror>
<id>nexus-163</id>
<mirrorOf>*</mirrorOf>
<name>Nexus 163</name>
<url>http://mirrors.163.com/maven/repository/maven-public/</url>
</mirror><mirror>
<id>nexus-tencentyun</id>
<mirrorOf>*</mirrorOf>
<name>Nexus tencentyun</name>
<url>http://mirrors.cloud.tencent.com/nexus/repository/maven-public/</url>
</mirror> 并将如下置换到末尾
<mirror>
<id>maven-default-http-blocker</id>
<mirrorOf>external:http:*</mirrorOf>
<name>Pseudo repository to mirror external repositories initially using HTTP.</name>
<url>http://0.0.0.0/</url>
<blocked>true</blocked>
</mirror>
CTRL+f搜索localRepository
找到<localRepository>/path/to/local/repo</localRepository>
在其后面添加<localRepository></localRepository>一对标签,并将repo文件的路径粘贴到此

二、idea配置
1.在d盘下新建hadoop文件夹以保存idea后期的文件
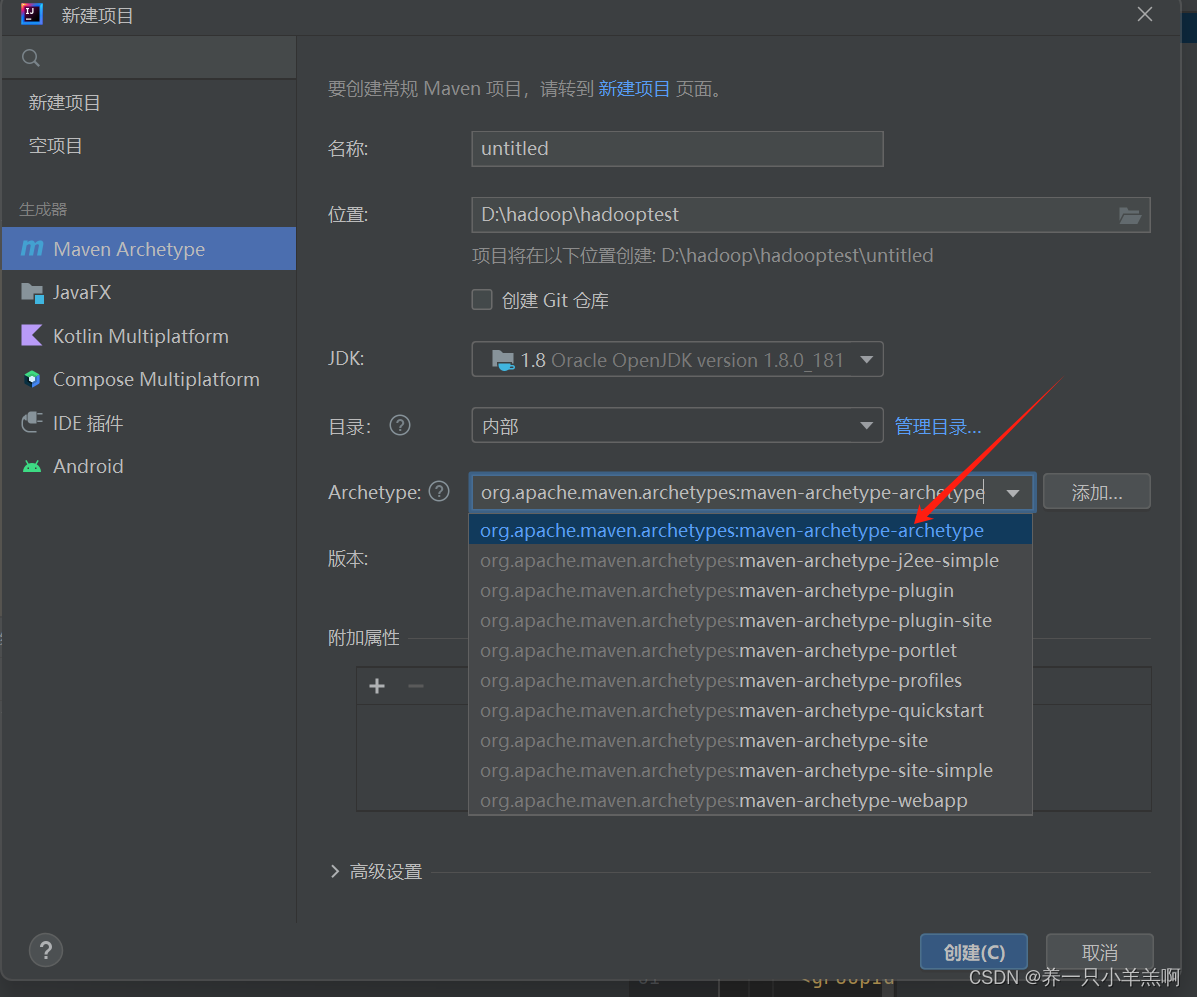
2.打开idea新建项目Maven
名称为HadoopTest
Archetype选则第一个
3.创建完成后,在src中依次创建如下文件

4.以下配置添加到hdfs文件中
此为权限设置,不关闭则无法使用API对hdfs进行操作
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>注意:第一次配置时,需要下载相应的插件
三、基于JavaAPI操作HDFS
1.创建main方法
1.导包
import java.io.IOException;
2.main方法
public static void main(String[] args) throws IOException {
}2.创建配置参数对象
注意包名:
1.导包
import org.apache.hadoop.conf.Configuration;
2.创建对象
Configuration conf = new Configuration();3.指定hdfs的地址
信息与core-site.xml文件内的hdfs地址一致
conf.set("fs.defaultFS", "hdfs://master:8020");4.创建hdfs文件系统的对象--带配置项---Filesystem类
使用静态get方法获取稳健系统对象(带配置对象)
1.导包
import org.apache.hadoop.fs.FileSystem;
2.使用静态get方法获取稳健系统对象(带配置对象)
FileSystem fs = FileSystem.get(conf);进行客户端身份验证(可以省略)
System.setProperty("HADOOP_USER_NAME","root");Path常用操作
Path path = new Path("文件的路径");
---path src:源文件的路径
---path dst:目标路径
系统文件地址使用'\\'字符隔开 '\n' '\t'
上传文件
fs.copyFromLocalFile(src,dst);
创建文件
fs.mkdirs(path);
下载文件
fs.copyToLocalFile(src,dst);
删除文件
fs.delete(src,true);
更改文件名
fs.rename(src,dst);四、Mapreduce 编程模型
1.核心思想:
“分而治之”(Map—映射,Reduce—归约)。MapReduce就是 “任务的分解和结果的汇总”。
2.MapReduce处理过程
在Hadoop中,每个MapReduce任务都被初始化为一个Job,Job将数据划分
为多个数据块,每个数据块对应一个计算任务(Task),并自动调用计算节点来处理相应的数据块。
每个Job又可以分为两种阶段:map阶段和reduce阶段。
这两个阶段分别用两个函数表示,即map方法和reduce方法。
map方法接收一个<key, value>形式的输入,然后同样产生一个<key, value>形式的中间输出,reduce方法接收一个如<key, (list of values)>形式的输入,然后对这个value集合进行处理,每个reduce产生0或1个输出,reduce的输出也是<key, value>形式的。
将map的输出作为输入传给reducer的过程就是shuffle。而shuffle是mapReduce的核心,主要工作是从Map结束阶段到Reduce阶段,可以分为Map端的Shuffle和Reduce端的Shuffle。
创建map类:1
1.创建对应的Mapper
public class SalMap {}2.继承Mapper类
import org.apache.hadoop.mapreduce.Mapper;
public class SalMap extends Mapper{
}3.使用泛型规定对应输入和输出的数据类型
Mapper 处理的输入键类型,输入值类型 ,输出键类型,输出值类型 。
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class SalMap extends Mapper<LongWritable, Text, IntWritable,IntWritable> {
}4.重写map方法
import java.io.IOException;
public class SalMap extends Mapper<LongWritable, Text, IntWritable,IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, IntWritable, IntWritable>.Context context) throws IOException, InterruptedException {
}
}创建reduce:
1.创建对应的Reducer类
public class Reduce {
}2.继承Reducer类
import org.apache.hadoop.mapreduce.Reducer;
public class Reduce extends Reducer {
}3.使用泛型规定对应输入和输出的数据类型
import org.apache.hadoop.io.IntWritable;
public class Reduce extends Reducer <IntWritable,IntWritable,IntWritable,IntWritable>{
}4.重写reduce方法
public class Reduce extends Reducer <IntWritable,IntWritable,IntWritable,IntWritable>{
@Override
protected void reduce(IntWritable key, Iterable<IntWritable> values, Reducer<IntWritable, IntWritable, IntWritable, IntWritable>.Context context) throws IOException, InterruptedException {
}
}创建job:
1.创建对应的job类
public class job {
}
2.书写main方法
public class SalJob {
public static void main(String[] args) {
}
}3.使用泛型规定对应输入和输出的数据类型
public class SalJob {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
}
}Map中常用的方法:
//转换字符串并切分
String[] arr = value.toString().split(" ");














 352
352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









