



一,利用蒙特卡洛法计算模拟
首先,这个题目我们可以看成在365天中抽取n天,其中至少有m对相同。
对于最一般的方法,就是把上面这句话直接转变成代码形式,在[1~365]中抽取n个数据(可以相同),然后检验这n个数据中有几个相同。我们可以利用较大基数的计算模拟的试验成功频率来近似概率。
很不幸的是,作者并未明白其所说的m对同一天过生日的同学是指:
1.字面意义的有m对同学过生日,将生日重复的同学分别两两取对,即:若有3个人在1月1日过生日,4个人在1月3日过生日,则m为C(2,3)+C(2,4)。(作者也考虑过是否可能是不重复的配对,但是考虑到可能存在3个人同一天生日,剩下一个人好孤独,就没有写这种情况)
2.有m组的同学同一天过生日,即有m个日期,在此日期过生日的人数>=2
3.有m个人生日所对应的日期,在此日期不止一个人过生日,即m为至少有几个人不是单独过生日的。eg:有10个人(n),其中有6个人是单独过生日的,4个人是有人和他们一天生日的,m为4.
所以,本处分情况编写了三种程序,但是更遗憾的是所有运行实验均在数据n较小时贴近题目所给答案,而在n较大时远离答案,所以希望读者可以指出可能存在的错误所在。
实际上,这三种方式的主函数结构都是相同的,不过有些小的差异罢了。
一.字面意义的有m对同学过生日
import random
import math
def pailie2(a):
if a==1 or a==2:
return 1
elif a>2:
fenzi=math.factorial(a)
fenmu=2*math.factorial(a-2)
return fenzi/fenmu
def same(a):
a=sorted(a)
wad=0
duishu=[]
b=[]
for i in a:
if i not in b:
b.append(i) #b中现在为a中所有的元素
for i in range(len(b)):
a.remove(b[i]) #a中现在为a中所有重复过的元素(但这些元素可能仍旧存在重复)
b.clear() #清空b
for i in range(len(a)):
if a[i] not in b:
b.append(a[i]) #b中现在为a中所有重复过的元素(但这些元素已经不再存在重复)
for i in range(len(b)):
zhongzhi1=1
for j in range(len(a)):
if a[j]==b[i]:
zhongzhi1+=1
duishu.append(zhongzhi1)
for i in duishu:
s=pailie2(i)
wad+=s
return wad
n=int(input())
m=int(input())
year=[]
birthday=[]
V=10000
res=0
for i in range(V):
for i in range(1,366):
year.append(i)
birthday=random.choices(year,k=n)
birthday.sort()
sum=same(birthday)
if sum>=m:
res+=1
print(res/V)
上面的是逻辑上最直白的一个结构,同时没有使用高级函数,但是也用到了math函数库的factorial(),以减少for循环的使用,当然如果使用for循环的话,factorial()函数也可以写为
a=1
n=int(input())
for i in range(n):
a=a*(i+1)
print(a)
下面我们来看第一个def的函数pailie2,作者写完后才发现其实就是写了comd。
def pailie2(a):
if a==1 or a==2:
return 1
elif a>2:
fenzi=math.factorial(a)
fenmu=2*math.factorial(a-2)
return fenzi/fenmu
这其实就是数学上排列组合的C(m,n)【在n个数据中抽取可重复的m个数据的组合】的代码形式。fenzi就是n!,fenmu就是m!*(n-m)!
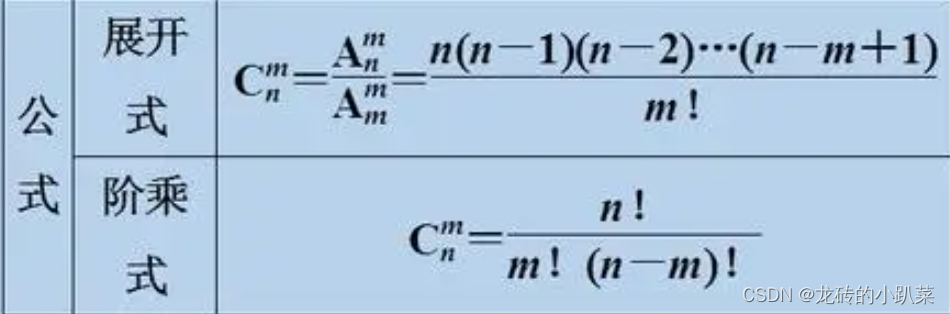
接下来第二个函数same函数中,通过较为复杂的多次for循环,第一次for循环的嵌套,我们得到了a中所有的元素列表b(无重复),随后通过for循环的remove,我们将a中所有的元素全都删除一遍,得到了所有重复的元素(重复个数均减一,因为我们的remove把未重复的元素直接删除,重复的元素删除了一个),随后我们把得到的新的a列表再经过一步和第一个for循环相同的循环,得到了a中所有重复过的元素列表,一个新的列表b(旧的列表b已经被clear了)。
现在通过第四个for循环(一级),将新a(a中所有重复过的元素,仍可能有重复)中所有元素的个数通过与b相比较而得到,但是不要忘记我们上一步把a的重复元素个数全部减了一,所以现在的zhongzhi1要从1开始累加。
这样我们就得到了原a中所有重复元素分别重复了几次,并讲这些个数塞入一个列表中,得到了列表duishu(对数)。
def same(a):
a=sorted(a)
wad=0
duishu=[]
b=[]
for i in a:
if i not in b:
b.append(i) #b中现在为a中所有的元素
for i in range(len(b)):
a.remove(b[i]) #a中现在为a中所有重复过的元素(但这些元素可能仍旧存在重复)
b.clear() #清空b
for i in range(len(a)):
if i not in b:
b.append(a[i]) #b中现在为a中所有重复过的元素(但这些元素已经不再存在重复)
for i in range(len(b)):
zhongzhi1=1
for j in range(len(a)):
if a[j]==b[i]:
zhongzhi1+=1
duishu.append(zhongzhi1)
for i in duishu:
s=pailie2(i)
wad+=s
return wad
下面就是主函数部分,我们的运算逻辑实际上是在365天中取出n天,所以先用for循环定义出一个列表year为[1~365]
随后我们用random.choices(year,k=n)从year中取出n个值,将他们组成一个新的列表birthday
随后加入我们刚才编写好的same函数。
我们这里的计算模拟次数设置为10000次,计算量还是比较小的,当然误差也会适当偏大,读者如果有更好的条件可以将V适当放大。
n=int(input())
m=int(input())
year=[]
birthday=[]
V=10000
res=0
for i in range(V):
for i in range(1,366):
year.append(i)
birthday=random.choices(year,k=n)
birthday.sort()
sum=same(birthday)
if sum>=m:
res+=1
print(res/V)
二.有m组的同学同一天过生日,即有m个日期,在此日期过生日的人数>=2。
这里最后的b为a中所有重复元素的列表(b的元素无重复),len(b)也就是有m组同学生日相同。
import random
def same(a):
a=sorted(a)
b=[]
for i in a:
if i not in b:
b.append(i)
for i in range(len(b)):
a.remove(b[i])
b.clear()
for i in range(len(a)):
if i not in b:
b.append(a[i])
return len(b)
n=int(input())
m=int(input())
year=[]
birthday=[]
V=10000
res=0
for i in range(V):
for i in range(1,366):
year.append(i)
birthday=random.choices(year,k=n)
birthday.sort()
sum=same(birthday)
if sum>=m:
res+=1
ans=res/V
print(format(ans,'.2f'))
三.有m个人生日所对应的日期,在此日期不止一个人过生日
这个类型的函数是这三种情况中最简单的了,我们只需要获得a中有几个不同元素,即列表b(a中所有不重复元素)的长度,然后len(a)-len(b)即为重复元素的总个数,也就是m。
import random
def same(a):
a=sorted(a)
b=[]
for i in a:
if i not in b:
b.append(i)
return len(a)-len(b)
n=int(input())
m=int(input())
year=[]
birthday=[]
V=10000
res=0
for i in range(V):
for i in range(1,366):
year.append(i)
birthday=random.choices(year,k=n)
birthday.sort()
sum=same(birthday)
if sum>=m:
res+=1
ans=res/V
print(format(ans,'.2f'))
二,直接计算
或许从题目来看,规定了存在有m对人生日相同,即n>=2m,那么一共有365**n种情况,其中符合m对人生日相同的条件时,可以将n分为2m和n-2m两部分,其中2m部分又可以存在重叠,但是n-2m部分不可重叠,所以可以视为一对为一个日期,
从comb(365,n-2m+1):所有m对人的生日均相同(重叠)
comb(365,n-m-k+1):有k对重叠
到comb(365,n-m):无重叠
所以只需要用for循环累加上面的m个数据后再考虑m的变化即可得到符合情况的个数。

















 1008
1008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









