






一、项目背景和目的
这段代码是一个基于 Flask 框架的简单问答系统。它使用了 TensorFlow 库中的 TensorFlow Hub 和 TensorFlow Text 来加载预训练的多语言通用句子编码器(Universal Sentence Encoder),利用该编码器将输入文本嵌入到一个多维空间中,并通过计算余弦相似度来寻找最相似的问题并返回相应的答案。
问答系统的背景是基于自然语言处理(NLP)和人工智能(AI)技术的发展。这些技术使得计算机能够理解和生成人类语言,从而实现与用户的互动。提供一个用户界面或API,用户可以输入问题,系统将返回与问题语义最相似的预定义答案。这种系统可以用于网站的智能客服、自动化问答平台等场景。
二、数据:
数据来源:代码文本数据由自己手动生成

数据预处理:
def load_qa_pairs(filename):
qa_pairs = []
with open(filename, 'r', encoding='utf-8') as file:
for line in file:
if line.strip(): # 确保不是空行
parts = re.split(r'::', line.strip(), maxsplit=1)
if len(parts) == 2:
question, answer = parts
qa_pairs.append((question.strip(), answer.strip()))
else:
print(f"Warning: Invalid line format: {line.strip()}")
return qa_pairs
- 加载问题与答案数据:通过load_qa_pairs(filename)函数从文件中加载问题与答案数据。在读取每一行数据时,使用re.split()方法根据特定的分隔符::将问题和答案分开,并去除首尾空格。
- 使用BERT模型进行文本嵌入:get_bert_embeddings(texts)函数使用BERT模型进行文本嵌入。在这里,使用了Google提供的Universal Sentence Encoder多语言模型,该模型能够将文本转换为高维度的向量表示,捕捉文本语义的丰富信息。
- 计算相似度:在respond()函数中,首先使用BERT模型将用户提出的问题转换为嵌入向量,然后计算用户问题与预先计算的问题嵌入向量之间的相似度。这里使用了余弦相似度作为相似度度量的方法。
- 阈值设定:在判断用户问题与预先设定问题之间的相似度时,设定了一个阈值 -0.5。如果最相似的问题与用户问题之间的相似度低于该阈值,系统会返回该问题对应的答案;否则,系统会返回一个默认的不明白问题的提示
标注:
在以上代码中,并没有直接使用任何标注工具。代码主要涉及到文本处理、嵌入模型的使用、相似度计算以及基于阈值的简单问答系统的实现,没有涉及到标注工具的直接应用。标注工具通常用于数据标注、模型训练等任务,而这段代码主要是针对预先准备好的问题与答案数据进行处理和响应。
三、框架
(1)1.采用框架:
Flask: 用于构建Web应用程序的轻量级Python框架。
TensorFlow: 用于机器学习和深度学习任务的开源框架,这里具体使用了TensorFlow Hub中的Universal Sentence Encoder(USE)模型来处理文本嵌入。
(2)为什么选择:
选择Flask框架的原因可能是因为它的轻量级和灵活性,适合快速开发小型的Web应用和API。与其他框架相比,Flask具有较低的学习曲线和灵活的扩展性,使得它成为许多开发者喜爱的选择之一。
(3)尝试其他框架:
Keras:Keras是一个高级神经网络API,它可以以各种后端(包括TensorFlow和Theano)作为支持。Keras提供了简洁的API和丰富的内置模型,使得快速构建和训练神经网络变得容易。
PyTorch:PyTorch是另一个流行的深度学习框架,被广泛用于研究和开发领域。PyTorch提供了动态图机制和易于使用的API,使得模型定义和训练变得简单。
(4)有什么突出优点
Flask框架优点:
-
轻量级和灵活: Flask是一个轻量级的Web框架,它的设计简单而灵活,易于学习和使用。它并不强制使用特定的项目结构或库,开发人员可以根据项目需求选择合适的扩展。
-
简单而强大的路由系统: Flask的路由系统非常直观,通过装饰器可以很容易地定义URL和相应的处理函数。这使得开发RESTful API或者普通的Web应用变得简单和直观。
-
丰富的扩展库: Flask拥有丰富的扩展库,可以方便地集成各种功能,例如数据库访问、表单验证、身份验证等。这些扩展使得开发者可以快速构建功能完善的Web应用。
-
社区支持和生态系统: Flask拥有一个活跃的社区和丰富的生态系统,可以在社区中找到大量的教程、文档和开源项目。这些资源能够帮助开发者快速解决问题和学习新技能。
-
适用于小型和中型项目: 由于其灵活性和轻量级特性,Flask非常适合于小型和中型项目的快速开发和迭代。对于简单的Web服务或者原型开发,Flask是一个非常合适的选择。
TensorFlow框架优点:
-
强大的数值计算能力: TensorFlow是一个功能强大的数值计算框架,特别适合于机器学习和深度学习任务。它提供了高效的数值运算和张量操作,能够处理大规模的数据和复杂的模型。
-
灵活的架构: TensorFlow的设计理念允许开发者构建和训练各种类型的机器学习模型,包括神经网络、决策树、聚类算法等。其灵活的架构使得可以实现复杂的模型组合和定制化需求。
-
跨平台支持: TensorFlow支持多种硬件平台和操作系统,包括CPU、GPU甚至TPU(Tensor Processing Unit)。这使得开发者可以利用不同的硬件资源加速训练和推断过程。
-
丰富的工具和生态系统: TensorFlow拥有丰富的工具和库,如TensorBoard用于可视化、TensorFlow Serving用于模型部署、TensorFlow Hub用于共享模型等。这些工具和库使得整个机器学习工作流更加高效和便捷。
-
广泛的应用场景: TensorFlow被广泛应用于许多领域,包括自然语言处理、计算机视觉、推荐系统等。它在学术界和工业界都有大量应用案例,是一个被广泛认可和使用的深度学习框架。
总体来说,Flask适用于Web开发中的后端服务和API构建,而TensorFlow则适用于需要处理大规模数据和复杂计算的机器学习和深度学习任务。
四、调节超参数
1.文本嵌入
def get_bert_embeddings(texts):
embed = hub.load("https://tfhub.dev/google/universal-sentence-encoder-multilingual-large/3")
embeddings = embed(texts)
return embeddings
- 模型URL:
https://tfhub.dev/google/universal-sentence-encoder-multilingual-large/3: 通常较大型的多语言模型提供更好的准确性,但也需要更多的计算资源。- 可以选择不同的USE模型,如基本版、单语言版或小型版,以在计算资源和性能之间找到平衡。
影响:
- 精度: 更高级的模型通常能提供更精确的文本嵌入。
- 性能: 大型模型会增加内存和计算时间需求。
2. 相似性阈值
if similarities[closest_index].numpy() < -0.5: # Adjust the threshold as needed
return qa_pairs[closest_index][1]
else:
return "抱歉,我不明白你的问题。"
- 阈值设置:
- 当前阈值设为
-0.5,这是一个经验值,可以根据实际情况进行调整。
- 当前阈值设为
- 匹配率:
- 较低阈值(例如
-0.3): 系统更容易返回答案,但可能会增加错误匹配的概率。 - 较高阈值(例如
-0.7): 系统会更严格,只在高相似度时返回答案,减少错误匹配,但可能会有更多未匹配的情况。
- 较低阈值(例如
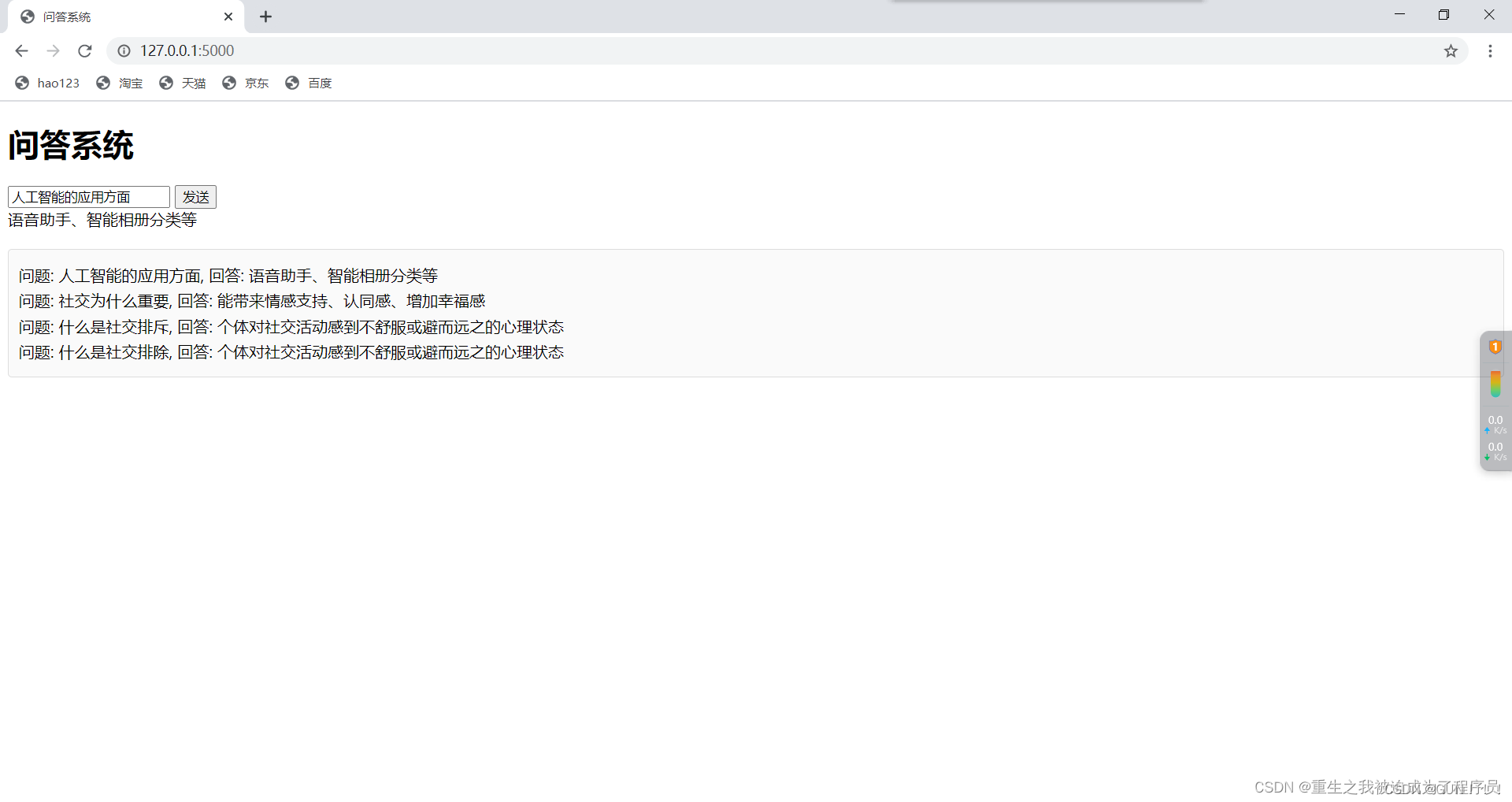
五、前端的实现过程
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>问答系统</title>
<style>
/* 原有的 CSS 样式 */
.history {
margin-top: 20px;
padding: 10px;
border: 1px solid #ddd;
border-radius: 4px;
background-color: #fafafa;
max-height: 200px;
overflow-y: auto;
}
.history p {
margin: 5px 0;
}
</style>
</head>
<body>
<div class="container">
<h1>问答系统</h1>
<div class="input-group">
<input type="text" id="question-input" placeholder="请输入您的问题">
<button οnclick="getResponse()">发送</button>
</div>
<div class="response" id="response-output"></div>
<div class="history" id="history-output"></div>
</div>
<script>
async function getResponse() {
const question = document.getElementById('question-input').value;
const responseOutput = document.getElementById('response-output');
const historyOutput = document.getElementById('history-output');
const response = await fetch('/get_response', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({ question: question })
});
const data = await response.json();
responseOutput.textContent = data.response;
// 更新问答记录
const historyEntry = document.createElement('p');
historyEntry.textContent = `问题: ${question}, 回答: ${data.response}`;
historyOutput.prepend(historyEntry);
}
</script>
</body>
</html>
六、 研究方向
- TF-IDF (Term Frequency-Inverse Document Frequency)优点:
- 简单而且高效。
- 可解释性强,能够理解每个词对于文本的重要性。
- 适用于小规模数据集。
- 缺点:
- 不考虑词与词之间的语义关系。
- 无法捕捉文本的语境信息。
- 对于稀有词或停用词的处理不够优秀。
Word2Vec:
- 优点:
- 能够捕捉词语之间的语义关系。
- 可以在大规模文本数据上训练。
- 可以得到词向量表示,适合进行文本相似度计算。
- 缺点:
- 需要大量数据进行训练。
- 对于生僻词或专有名词可能表现不佳。
- 无法处理词语的多义性。
Doc2Vec:(一种用于文档嵌入的技术,是Word2vec的扩展,用于处理)
- 优点:
- 可以学习文档级别的语义表示。
- 在训练数据不充足时表现较好。
- 能够处理上下文信息,适合文本分类和相似度计算。
- 缺点:
- 训练时间较长,需要大规模文本数据。
- 参数调优相对复杂。
- 对于长文档可能表现不佳。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









