






摘要:
解决问题:
大多数跨模态哈希方法通常采用等长编码方案来表示多模态数据,实现跨模态相似性搜索。但是,这种方案的局限性比较严格,因为它牺牲了现实中多模态数据的灵活表示,不能总是保证最优的检索性能。为了解决这一挑战,本文将重点放在对具有不同散列长度的异构数据进行编码上。
在 MTFH:AMatrix Tri-Factorization Hashing Framework for Efficient Cross-Modal Retrieval 这篇论文中充分证明了在进行单模态检索时,不同模态的最佳检索的哈希码长度并不相同。因此将不同模态进行分离,学习不同长度的哈希码,在进行检索时进行转换是可行的一个方向。
模型框架:
在第一阶段,TASPH设计了一种新的离散非对称策略来学习具有不同长度的模态特定哈希码,从而实现异构数据的灵活表示。同时,TASPH利用两个语义转换矩阵来建立不同哈希码之间的语义相关性。与大多数采用松弛解的现有方法不同,TASPH不需要任何松弛就能满足离散约束。第二阶段,学习到的语义变换矩阵。
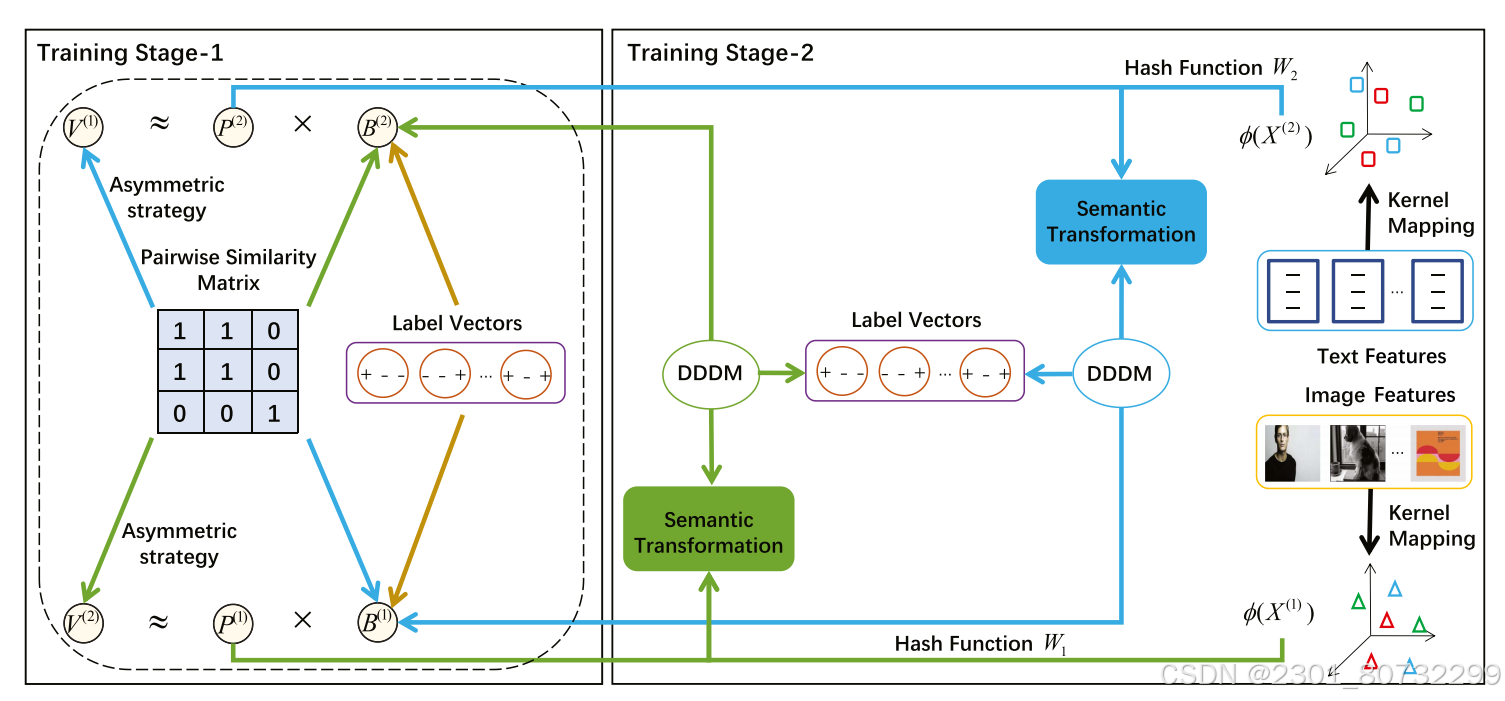
(一阶段:通过S保持Vi与Bi之间的相似性,通过转换矩阵P使两个不同模态之间的B通过一个共同的V建立起联系,B同时保持标签的监督信息。二阶段:通过投影使两个模态的B进行相似保持来学习位数投影矩阵。)
模型搭建
在第一阶段:
模型的损失主要包括三个 相似保持损失 标签重构损失 语义一致损失
相似保持损失:上篇文章有详细推导http://t.csdnimg.cn/osEwr
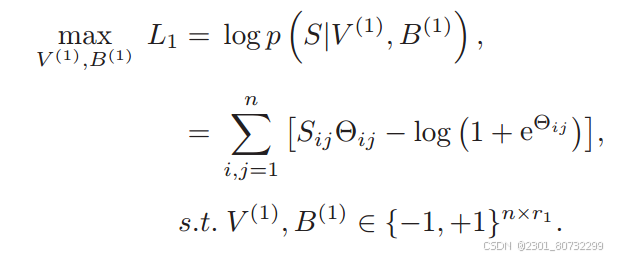
采用非对称化引入V使B保持相似间的关系,V与B强关联
标签重构损失:
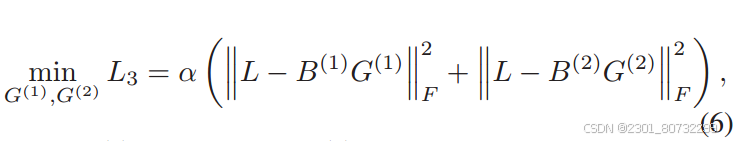
常规的将标签的信息引入
语义一致损失:
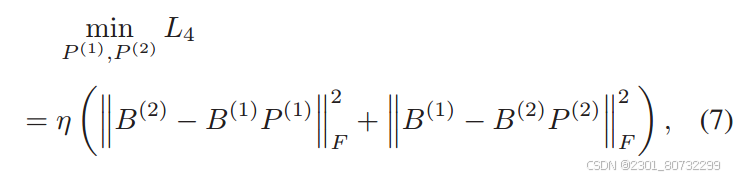
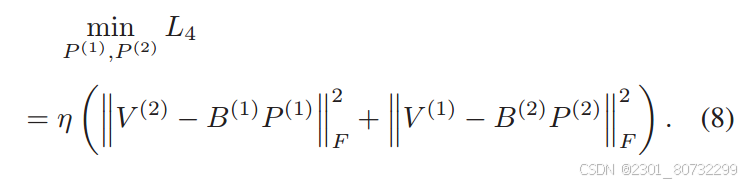
不同模态之间由于对应的是同一个实例,因此经过转换位数之后不同模态之间应该保持着语义的一致,从这角度个人觉得公式(6)应该比(7)更合理,文章使用的是(7)因为B与V强相关,但两者那个效果好还得看具体实验。
总损失函数:
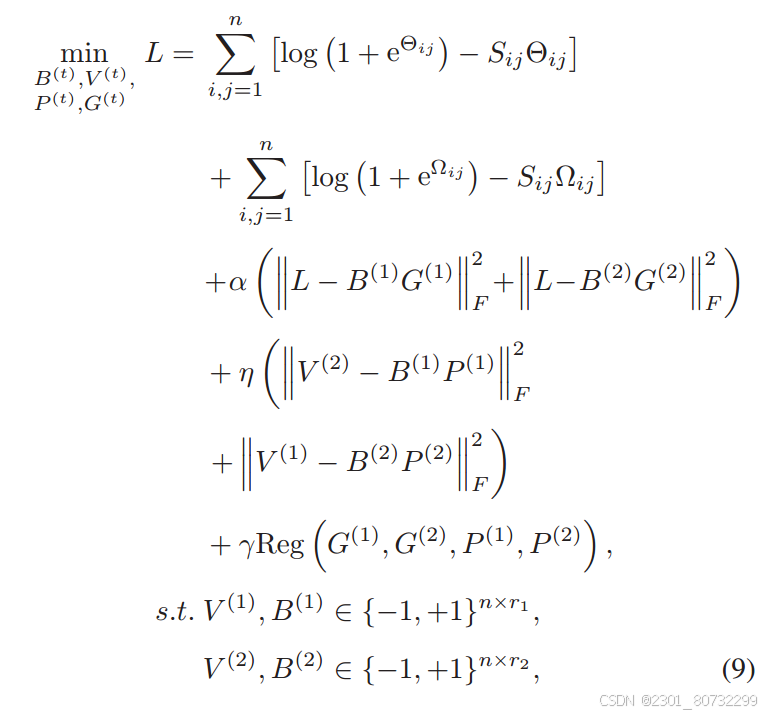
在第二阶段:
通过一阶段学习到的B来学习不同长度之间的转换矩阵。同时实例之间任然是需要保持着实例之间的相似性。
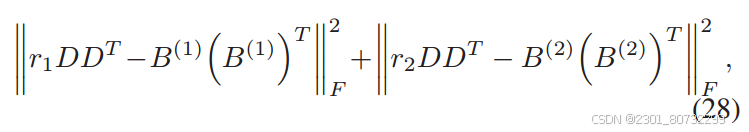
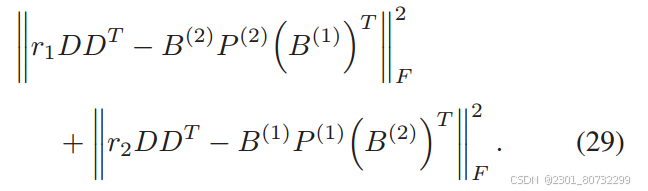
此时B是由模态实例数据生成,则可以转化为:
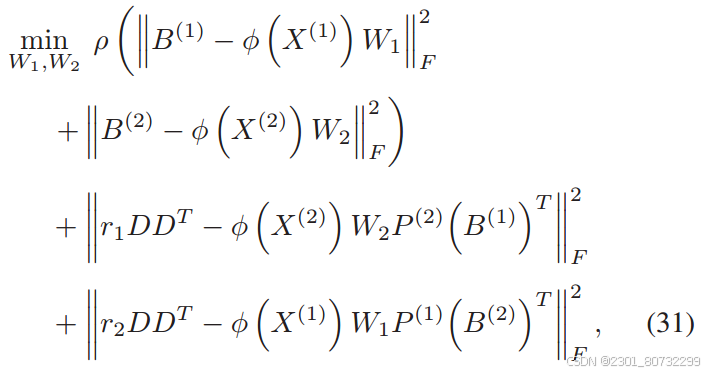
理解:
在这篇文章中,主要的创新点是考虑到不同模态的异质性采用不同长度的哈希码来进行检索从而提出了此框架,相似保持与标签重建在跨模态检索中使用比较常见,其中使用 采用语义一致性的来保证不同模态之间的关系和哈希函数的学习过程中对B的转换可以提供一个不错的思路。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









