






 本文提出了一种新的无监督跨模态检索方法,通过CLIP编码视觉特征,利用模态特定自编码器学习哈希表示,并构建语义互补的关联矩阵。实验结果显示,这种方法在大规模多模态数据集上优于现有方法,实现了高效的图像文本检索。
本文提出了一种新的无监督跨模态检索方法,通过CLIP编码视觉特征,利用模态特定自编码器学习哈希表示,并构建语义互补的关联矩阵。实验结果显示,这种方法在大规模多模态数据集上优于现有方法,实现了高效的图像文本检索。
摘要
随着多模态数据的激增,人们不再满足于单一的数据检索模式来获取信息。深度哈希检索算法以其存储效率高、查询速度快等优点受到广泛关注。目前,现有的无监督哈希方法普遍存在两方面的局限性:(1)现有方法不能充分捕获不同模态数据中潜在的语义相关性和共存信息,导致缺乏有效的特征和哈希编码表示来弥合多模态数据中的异构和语义差距。(2)现有的无监督方法通常构造相似矩阵来指导哈希码学习,存在不准确的相似度问题,导致检索性能次优。为了解决这些问题,我们提出了一种新的基于clip的融合模态重构哈希算法,用于大规模无监督跨模态检索。首先,我们使用CLIP对视觉模态的跨模态特征进行编码,并使用模态特定的自编码器学习哈希码的公共表示空间。其次,我们提出了一种有效的融合方法来构建一个语义互补的关联矩阵,该矩阵可以最大限度地提高不同模态实例的潜在语义相关性。此外,为了保持所学习的哈希码中所有相似对的内在语义相似性,设计了基于语义互补的相似性重构目标函数,学习高质量的哈希码表示。在四个多模态基准数据集(WIKI、MIRFLICKR、NUS-WIDE和MS COCO)上进行了充分的实验,与几种具有代表性的无监督跨模态哈希方法相比,所提出的方法获得了最先进的图像文本检索性能。
介绍
随着多媒体数据的快速增长,单一的数据检索方式已经不能满足信息需求。跨模态检索是利用一种模态的数据作为查询来检索另一种模态的相关数据,如用户可以通过文本检索图像、音频和视频等,已受到研究者的广泛关注。由于不同模态数据之间存在异质性差距和语义差距,如何量化不同模态数据之间的相似度是跨模态检索的主要障碍。早期的一些方法使用人工标签来度量不同模态数据之间的相似性,但由于巨大的人工成本和噪声问题,这些方法并不适用于实际场景。
跨模态检索存在高维数据存储和检索速度慢的问题,哈希技术以其相对低的存储要求和快速的检索速度受到了广泛的关注。基于哈希的跨模态检索方法旨在通过将高维数据映射为二进制代码来保留高维数据之间的语义关系。由于模态异质性无法直接比较不同模态实例之间的相似性,跨模态哈希方法将原始数据映射到统一的二值哈希空间中,利用汉明距离量化各种模态实例之间的相关性。特别是,有两种主要类型的跨模态哈希方法:用于成对多媒体数据的无监督跨模态哈希检索和用于标记多模态数据的监督方法。无监督方法仅使用原始文本图像对的原始邻域结构来最大化它们在统一哈希空间中的相关性。在监督方法中,它们可以进一步利用语义标签,使语义相关的多模态数据生成高质量的哈希码,大大缓解了模态差距。与无监督方法相比,有监督方法往往具有更好的检索性能,但对于大规模数据标注需要人工标注和昂贵的人工成本,并且在实践中,许多数据标注也是有噪声的。无监督的场景在现实中是相对未被探索和至关重要的。因此,一些工作旨在提高无监督条件下跨模态哈希的检索性能。
得益于深度神经网络强大的深度非线性特征提取能力,用于大规模信息检索的深度无监督跨模态哈希研究日益受到关注。深度无监督跨模态哈希方法,它试图消除训练过程中对大量标记数据的需求,并取得了显著的改进。现有的深度无监督跨模态哈希方法通常采用深度神经网络从图像和文本中提取深度特征,构建相似矩阵来指导二进制码学习,取得了很大的性能提升,在现实场景中是可行的。
虽然这些方法取得了一些突破,但仍然存在特征学习不足、相似度不准确等问题。考虑到单一相似度度量难以完全表示数据之间的相似关系,图像模态通常比文本模态包含更丰富的语义信息,并且可以相互补充。因此,提出一种更好的构造相似矩阵的方法来实现语义互补是至关重要的。此外,大多数无监督跨模态哈希方法的一个不可否认的缺点是它们无法充分捕获不同模态数据的协同和跨模态信息,从而导致相似性度量不准确的问题。图1说明了现有的无监督跨模态哈希方法的局限性,这进一步导致无法为哈希码学习提供有效的指导。
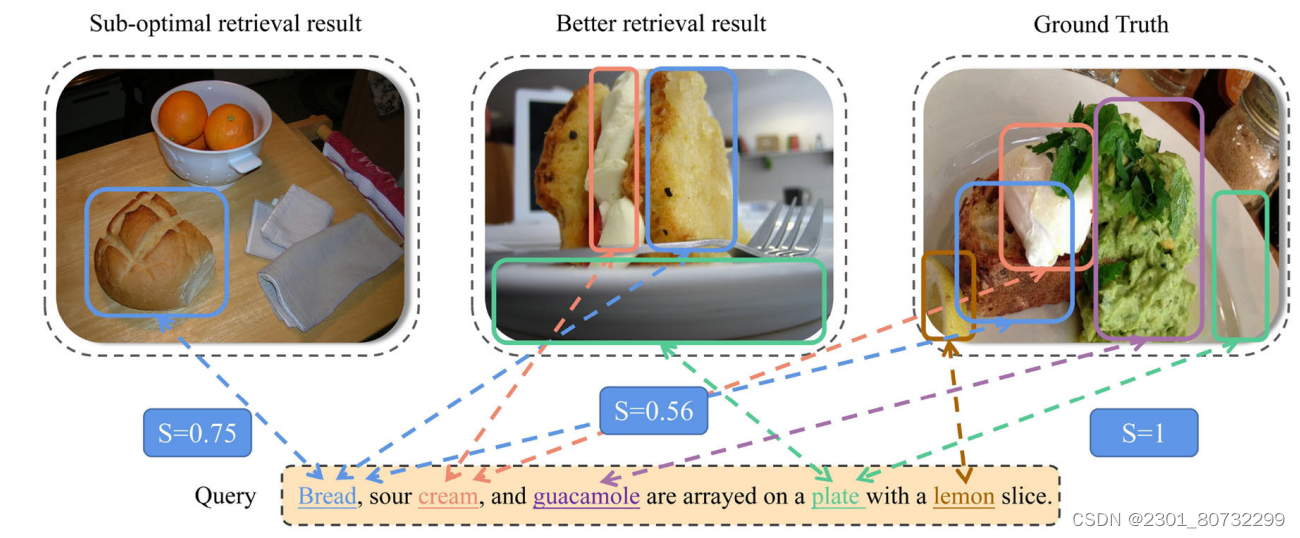
(图1:现有的无监督跨模态哈希方法没有充分编码不同模态数据的共现信息来度量它们的相似度,导致检索结果不够理想。例如,右边是下面文字描述的图片,中间的图片比左边包含更多的共现信息,但是中间的图像-文本相似度评分(S)比左边低)
为了解决这些问题,我们提出了一种新的基于clip的融合模态重构哈希(CFRH)用于大规模无监督跨模态检索。所提出方法的框架下图所示,它是一个端到端深度神经网络架构,可以同时学习特征表示和哈希码。一方面,为了学习不同模态数据的跨模态特征,我们使用视觉语言预训练模型CLIP提取特征。另一方面,我们设计了一个自编码器重构模块,使生成的哈希码尽可能保留潜在的语义信息。
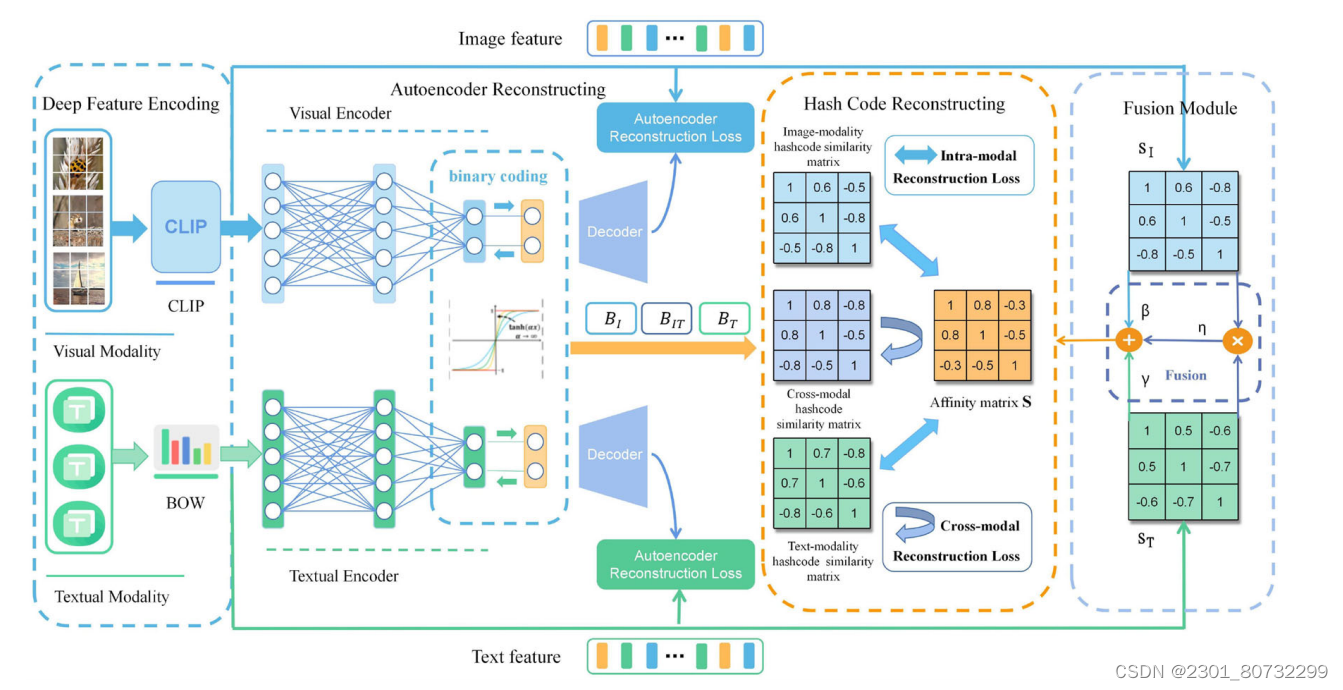
此外,我们提出了一个相似度融合模块来连接每个模态的互补相似度信息,以学习一致的哈希表示。最后,哈希码重构模块通过多个损失函数和最大逼近优化来优化哈希码学习,降低模型不稳定性。这些贡献总结如下:
1. 提出了一种基于CLIP的大规模无监督跨模态检索融合模态重构哈希(CFRH)方法,该方法利用视觉语言预训练模型CLIP对原始数据特征进行编码,构建语义互补的亲和矩阵,从而更好地融合不同模态的内在语义信息。
2. 为了学习不同模态的高质量哈希码表示,我们设计了一个模态特定的自编码器模块,它可以用更短的二进制码长度学习更高质量的哈希码。此外,我们还详细阐述了包含模态内和跨模态重构损失的哈希码重构模块,该模块可以有效地合并来自各种模态实例的相似互补信息并重构哈希码,从而为哈希码学习提供有效的指导。
3. 为了证明所提出方法的有效性,在四个广泛使用的基准数据集(Wiki, NUS-WIDE, MIRFLICKR25K和MS COCO)上,充分的实验验证了CFRH与几种具有代表性的先进无监督跨模态哈希方法相比的优越性
相关工作
在这一部分中,我们将简要回顾相关的跨模态哈希工作,然后介绍视觉语言预训练的相关工作。
跨模态哈希检索
跨模态哈希检索的主要挑战是弥合模态差异和学习哈希函数以将多模态数据映射到统一的汉明空间。现有的跨模态哈希方法可以大致分为两类:用于标记多模态实例的监督方法和用于成对多媒体数据的无监督跨模态哈希检索方法。
监督深度跨模态哈希方法试图挖掘语义相关性,并利用标签信息从不同的模态实例中生成公共哈希码。RDMH提出了一种新的离散矩阵分解方案和自编码器策略来学习哈希函数,可以保留更多有价值的信息,使哈希函数学习更加强大。Wang等人提出的ACMR提出使用生成式对抗网络来弥合不同模式之间的异构差距,从而可以生成更一致的哈希码。Gu等人提出的AGAH采用基于对抗的多标签注意分量来增强特征编码模块,并采用新颖的三重约束和余弦量化函数来保持汉明空间相似性。Zhang等人提出的WATCH提出了一种新的基于光滑矩阵分解和标签松弛的两阶段离散跨媒体哈希方法,该方法通过一种新的标签松弛策略自适应控制边距,从而减少量化误差。Bai等人提出的DADH采用对抗的方式对特征进行编码,引入了一种新的加权三联体损失,可以充分利用多标签的语义信息。基于注意力的自约束哈希网络(Attention-based self- constraint哈希network, SCAHN)提出了一种位可扩展的跨模态哈希方法,该方法将早期和晚期标签约束纳入哈希编码学习和哈希表示中。然而,这些有监督的方法使用昂贵的手工标注标签信息来学习哈希编码,并且由于大量的手工标注,在实际场景中获取标签信息有时是昂贵的、嘈杂的和难以实现的。
无监督深度跨模态哈希方法消除了训练过程中对监督信息的依赖。无监督方法仅考虑多模态数据之间的两两关系,通常涉及词级和区域级局部嵌入之间的各种跨模态深度神经网络,以聚合跨模态相似性并学习跨模态语义对齐。Su等人提出了深度联合语义重构哈希(Deep JointSemantics Reconstructing hash, DJSRH),通过构造联合语义亲和矩阵来统一不同模态数据的邻域关系,引入了一种重构跨模态哈希矩阵的新方法。Zhang等人提出的HNH从局部和非局部两个角度考虑多模态实例之间的相似关系,构建了一个更全面的相似矩阵。Yang等人提出的DSAH设计了一个语义对齐的损失函数来对齐不同模态实例的共现信息。AGCH由Zhang等人提出,利用图卷积神经网络聚合模态实例之间的相似度信息,进一步挖掘不同模态数据之间的语义相关性。Yu等人提出的DGCPN通过整合数据与其邻居之间的信息来保持图邻居的一致性,使用三种不同形式的数据相似度来调节组合的相似度保留损失,并设计了一种优化策略来减少哈希码训练过程中的量化损失。深度无监督对比哈希(Deep Unsupervised contrast Hashing, DUCH)[36]由Mikriukov等人提出,是最早将对比学习应用于无监督哈希学习的作品之一。在学习过程中引入了一种新的多目标损失函数,将对比损失和对抗损失结合起来,可以更好地表达跨模态数据之间的相似关系,实现多模态实例表示的一致性。
这些方法虽然取得了一定的突破,但在训练过程中没有充分捕捉到原始文本图像对的潜在语义信息,导致构建的相似矩阵效率低下且冗余。此外,来自不同模态的相似信息是互补的,但这些方法不能充分融合各种模态特征之间的语义相关性,并产生相应的哈希码来弥补模态差距。
视觉语言预训练
在过去几年中,基于Transformer的自监督文本预训练方法在大量自然语言处理任务中取得了先进的性能。通过利用无卷积自注意机制作为一种新的架构,Transformer还扩展到了用于视觉识别的视觉Transformer(ViT)。基于Transformer架构的大量视觉语言预训练(VLP)方法已被提出,用于构建多模态对应关系,并学习视觉语言语义对齐,以便在下游的视觉语言任务(如多模态检索)中进行微调。
VLP模型的架构大致可以分为单流和双流,其中文本和视觉特征被链接在一起并馈送到单个Transformer块中,该Transformer使用注意机制实现视觉语言对齐,如图2a所示;双流架构,文本和视觉特征不链接在一起,而是独立发送到两个不同的Transformer块,使用跨模态注意机制实现多模态融合,如图2b所示。
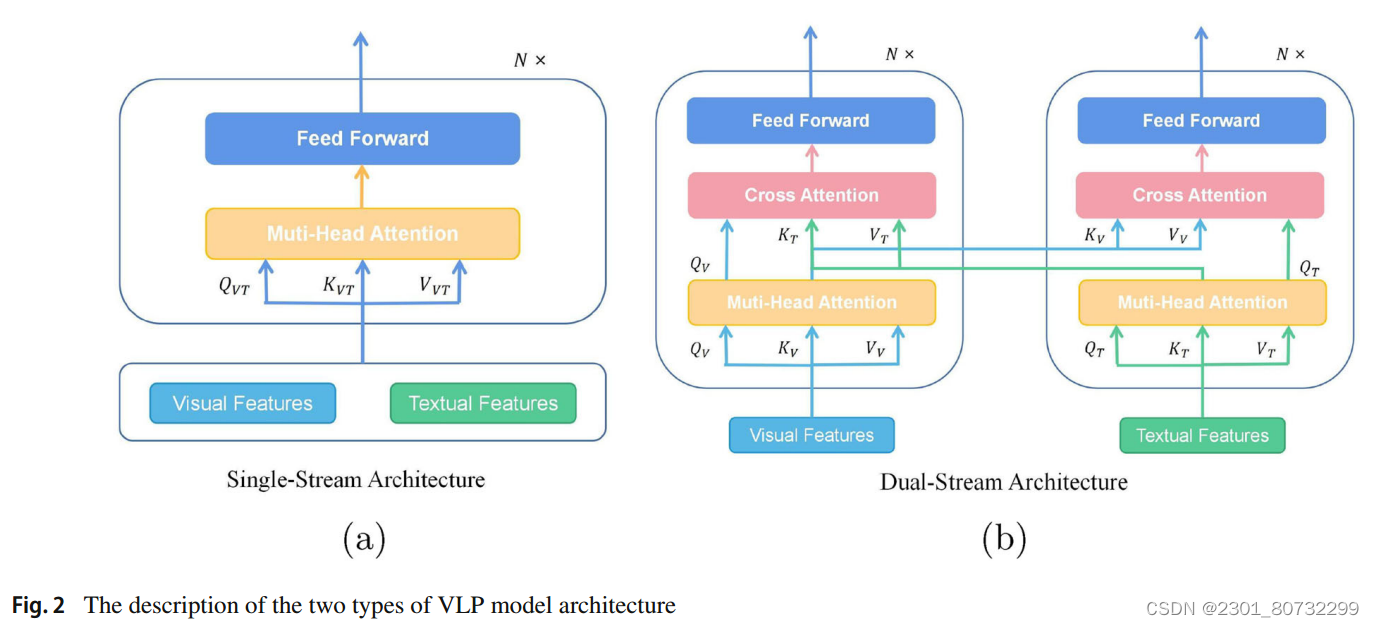
在单流架构中,图像和文本标签被连接并馈送到Transformer中,单流模型执行隐式的模态内和多模态融合。VL-BERT提出了一个可预训练的通用视觉语言表示模型,该模型使用简单但功能强大的Transformer作为主干,并使用大规模的概念说明数据集和纯文本语料库进行预训练。UNITER提出了掩码的语言/区域建模的条件掩码方法和基于最优传输的新的单词-区域对齐任务。双流模型使用两个独立的编码器分别学习视觉和语言的高级表示。ViLBERT将流行的BERT架构扩展为双流多模态模型,该模型可以处理两个独立流中的文本和视觉输入,并通过公共注意力转换层跨模态进行交互。CLIP(对比语言图像预训练)使用对比学习方法来简化跨模态交互,并在各种视觉和语言相关任务中显示出令人印象深刻的表现。事实上,以CLIP为代表的VLP模型正在深刻地重塑跨模态域,并且在大规模多模态数据上预训练的VLP模型可以产生优越性能的假设已经得到越来越多的认可。因此,所提出的模型为CLIP在无监督跨模态哈希检索领域的应用提供了一个深入的见解。
CLIP4CMR (CLIP For supervised Cross-Modal Retrieval)首次提出了一种以预训练的CLIP为骨干网络应用于监督跨模态检索的新模型。CLIP4Hashing提出了一种无监督深度跨模态视频文本哈希方法,该方法设计了动态加权策略和最小-最大哈希层来提高检索性能。受这些工作的启发,我们将视觉语言预训练模型CLIP应用于无监督跨模态哈希检索任务,将视觉语言模型中的知识转移到无监督多模态图像-文本检索任务中。
在本文中并未采用两种之中的任何一种方法,而是采用了CLIP的编码器作为了特征提取器,利用了CLIP良好的特征提起能力和泛化能力。
模型构建
本文中的模型构建一共分为,特征提取模块(此模块图像采用Clip文本采用BOW),特征编码模块(将两个模态之间的特征通过参数网络编码成连续的哈希特征,在通过双曲函数进行二值化),相似度构建模块(本文为无监跨模态,采用两个模态提取之后的特征进行两个独立模态的相似度构造,再将两个模态的相似度进行高维混合得到Sc(Sc合成原理可看Joint-modal Distribution-based Similarity Hashing for Large-scale Unsupervised Deep Cross-modal Retrieval)这篇论文,再将三个相似度进行融合成S,此时S中包含多种信息),哈希重构模块(再次模块采用前面构造好的相似矩阵来指导哈希吗的学习,通过对各模态损失的优化从而使两个模态对其和使前面的特征编码模块得到优化 ,使其可以很好的从特征生成哈希码)
总结
本文主要是尝试了采用CLIP作为特征提取器是否会对模型性能有所提升,其他例如相似度构造,以及损失优化等等皆为常用方法。

















 1016
1016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









