







本文
TextIn:文档解析强引擎
TextIn的产品丰富多样,涵盖大模型加速器、基础识别、文档处理等多个维度,无论你是在处理合同、票据,还是进行图像优化、格式转换,亦或是探索前沿 AI 应用,都能在其中找到契合需求的利器。
在质量方面,TextIn 更是表现出色,100页长文档解析最快仅需1.5秒,运行稳定率可达99.99%。
其中【通用文档解析】和【智能文档抽取】更是TextIn的重点产品,那么下面我们就展示下TextIn强大的产品能力!
通用文档解析
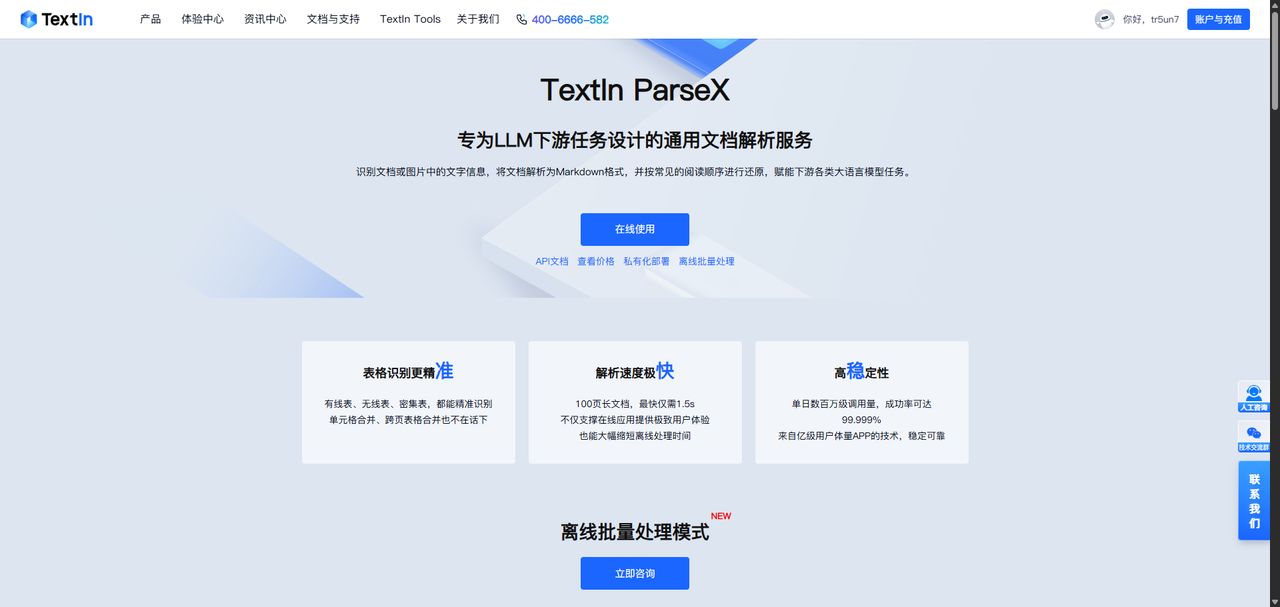
【通用文档解析】能识别文档或图片中的文字信息,将各类复杂文档解析为 Markdown、表格、公式、图片等多种类型 ,像常见的金融报告、国家标准、论文、招投标文件、合同等,都能轻松应对,无论是多栏文本,还是带有图表、公式的复杂排版,都不在话下。尤其表格识别能力超强,有线表、无线表、密集表,甚至单元格合并、跨页表格合并等情况,都能精准识别 ,防止数据丢失或变形。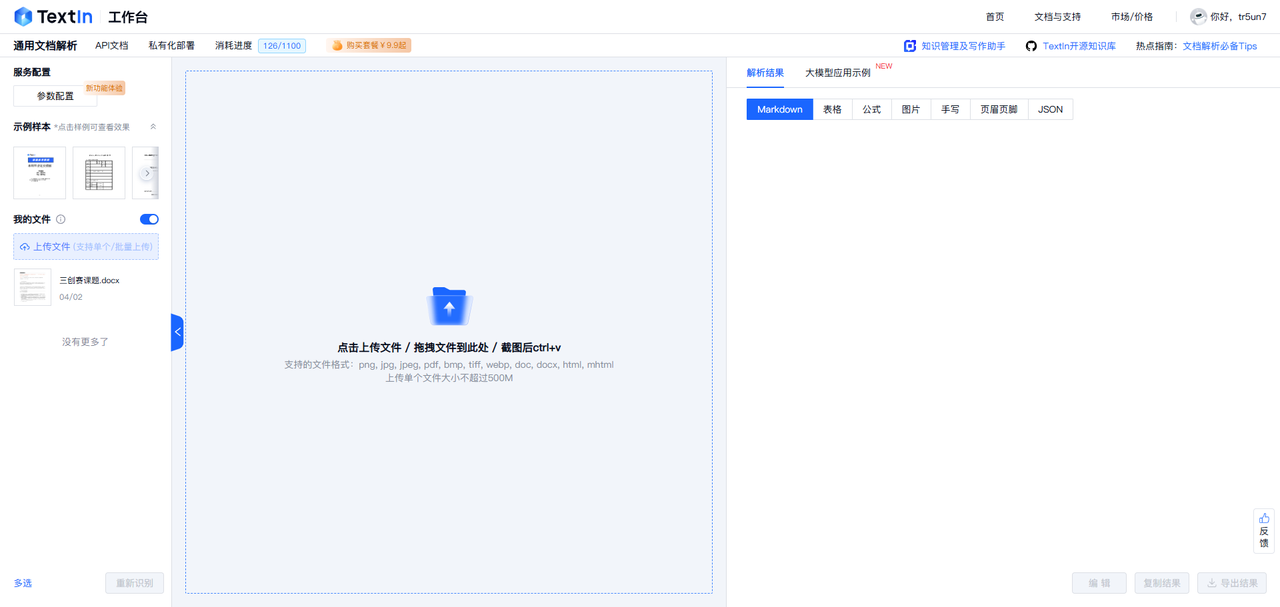
将需要解析的文件拖入到中间的区域,右侧即可得到解析后的表格、公式、图片、手写、页眉页脚等元素,并支持导出为JSON、Markdown等多种格式。 这么多类型,需要在这个文档解析的兄弟已经泪目了:怎么不早点知道这个东西啊,功能这么逆天的吗?简单强势的文件转换分析
这个解析速度还是非常快的,这个文件总共20页,他一秒不到就分析好了呈现在右边,并且我们可以实时变换这个解析结果的
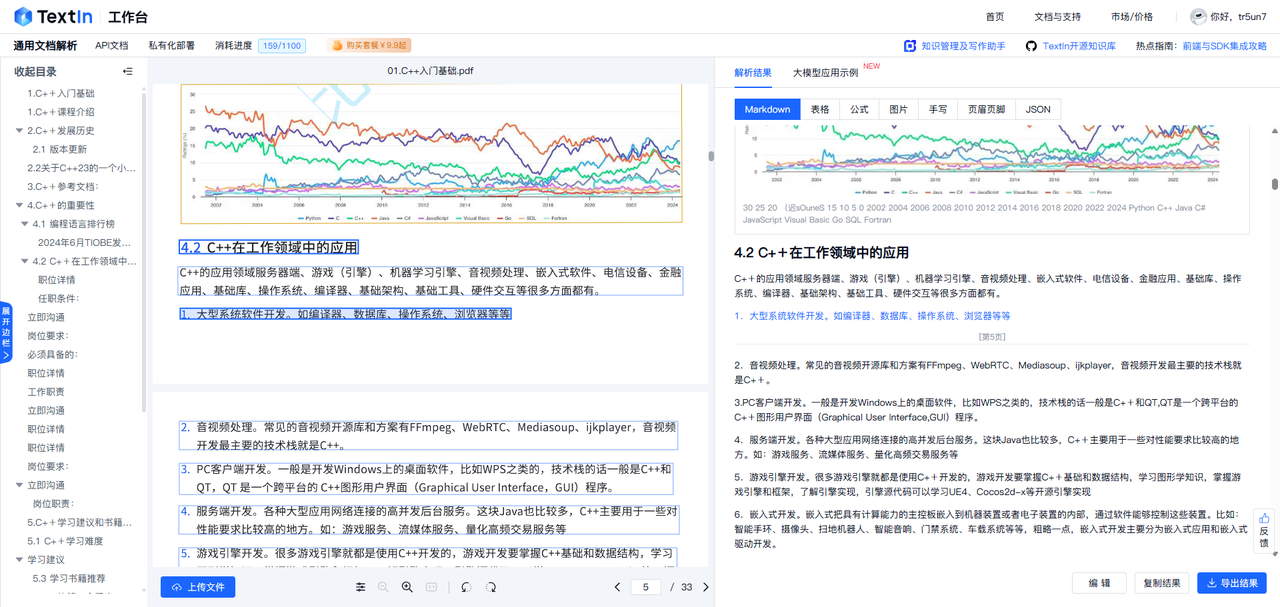
支持多种格式之间的转换操作
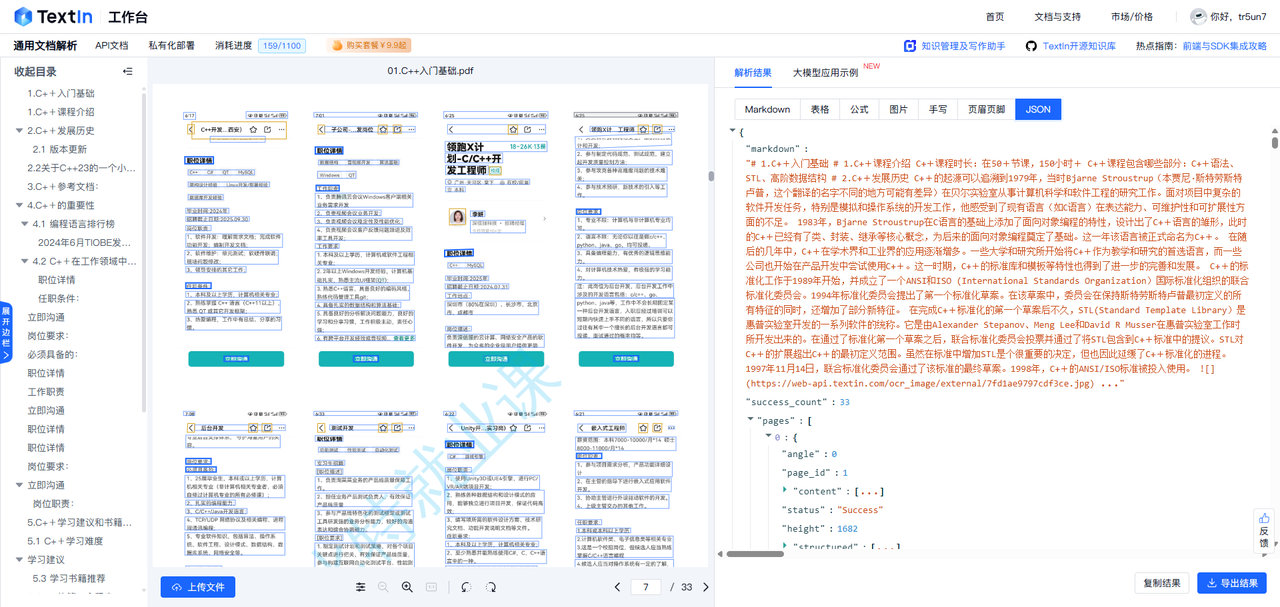
解析速度堪称一绝,处理 100 页长文档,最快仅需 1.5 秒 !无论是在线实时处理,给用户带来极致的快速响应体验,还是离线批量处理大量文档,都能大大缩短时间成本。就算单日数百万级的调用量,也能稳定运行,成功率极高。
另外,面对复杂的表格如财务报表,无论是行列结构、数据内容,还是单元格合并等特殊情况,都能精准识别。像图中报表里的各项资产数据、项目名称等,都能准确提取;我测试下来几乎不会出现数据错位、内容遗漏等问题,为后续数据分析和处理提供坚实可靠的数据基础。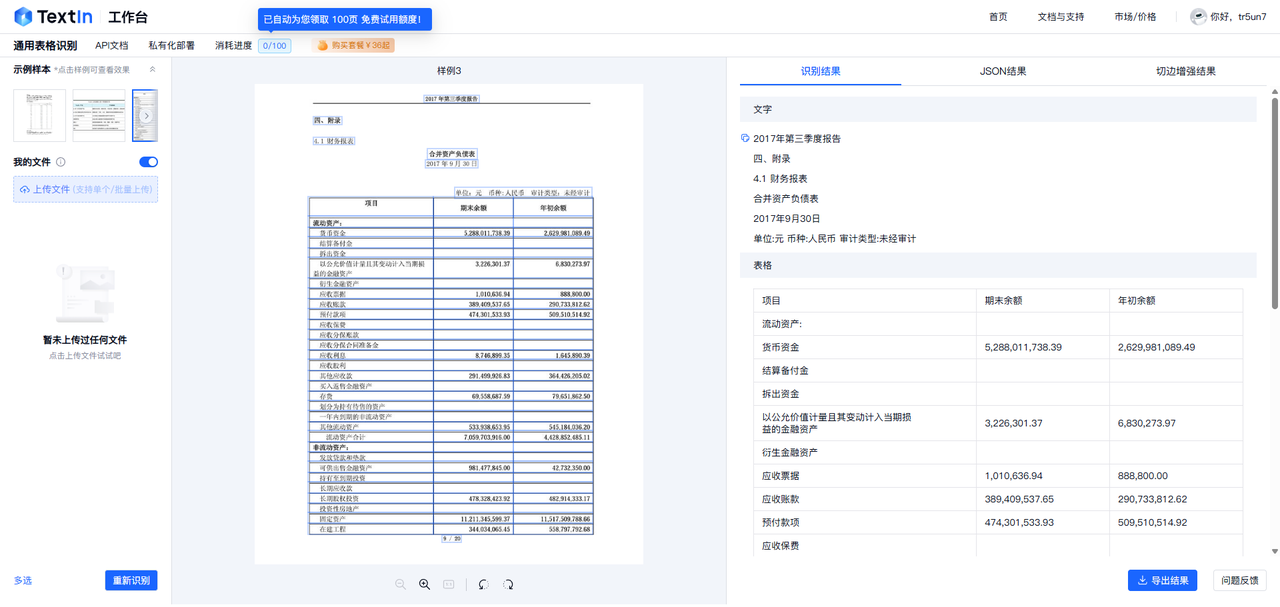
处理表格的效率极高,无需漫长等待。即使是多张复杂表格批量处理,也能在短时间内完成识别,大大节省时间成本。以往人工录入表格数据可能需要花费数小时,使用这个功能,几分钟甚至几十秒就能搞定,工作节奏瞬间加快。
不仅适用于财务报表,对各类行业的表格,如销售数据报表、生产进度表、人员信息表等都能完美适配。不管表格格式是简单还是复杂,都能游刃有余地进行识别处理,满足多样化的工作场景需求。
识别后的表格结果能方便快捷地导出,可直接用于其他办公软件进行进一步编辑、分析。无缝衔接后续工作环节,减少了繁琐的数据转换和整理步骤,极大提升整体工作效率。
智能文档抽取
【智能文档抽取】强在它可以精准抽取文档中的任意字段,无论是整份文档的版面信息提取,还是自定义抽取几个重要的字段信息,它都可以满足。
我们这里传了一个三创赛的文档,他立马就分层将对应的信息解析出来了
能像 “信息猎手” 一样,精准捕捉文档里的关键信息。像图中对项目报告,能准确揪出标题、作品名称、赛道等关键内容,不会遗漏重要细节,避免人工查找的疏漏,为后续分析、整理和利用文档信息筑牢根基 。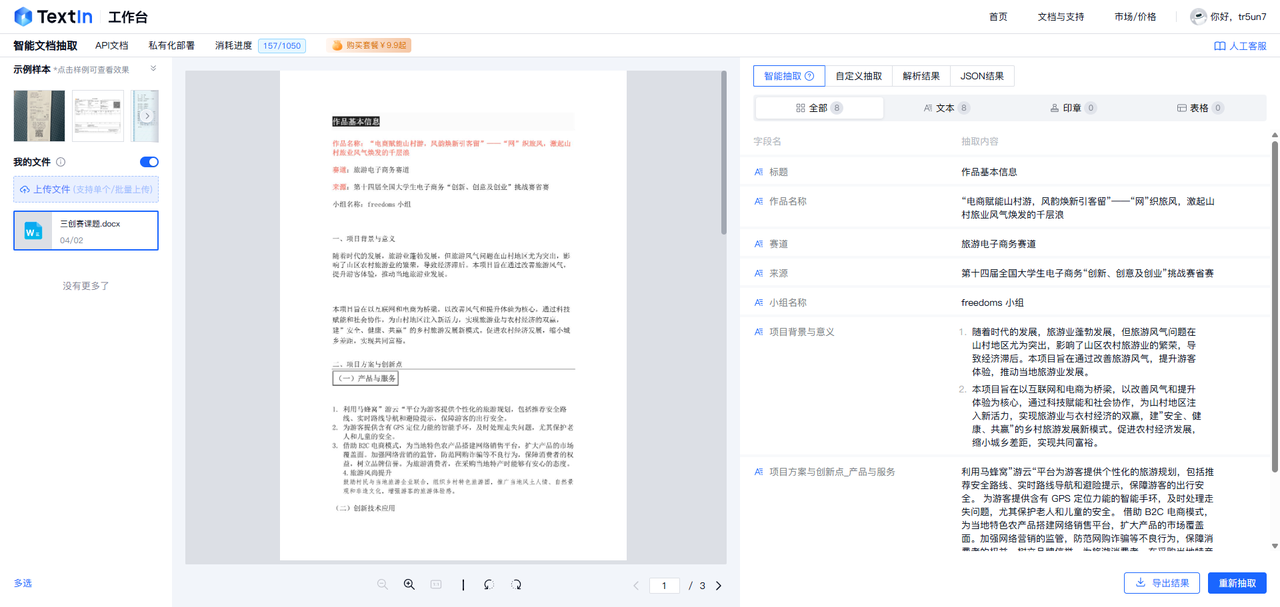
依托于垂直领域的语义模型,用户可以自定义抽取所需字段信息;输入需要抽取的字段名,系统可以完成版面分析、语义理解,抽取出所需要的字段内容,对于非常规表格,还能自动还原出表格信息,简直太方便了。
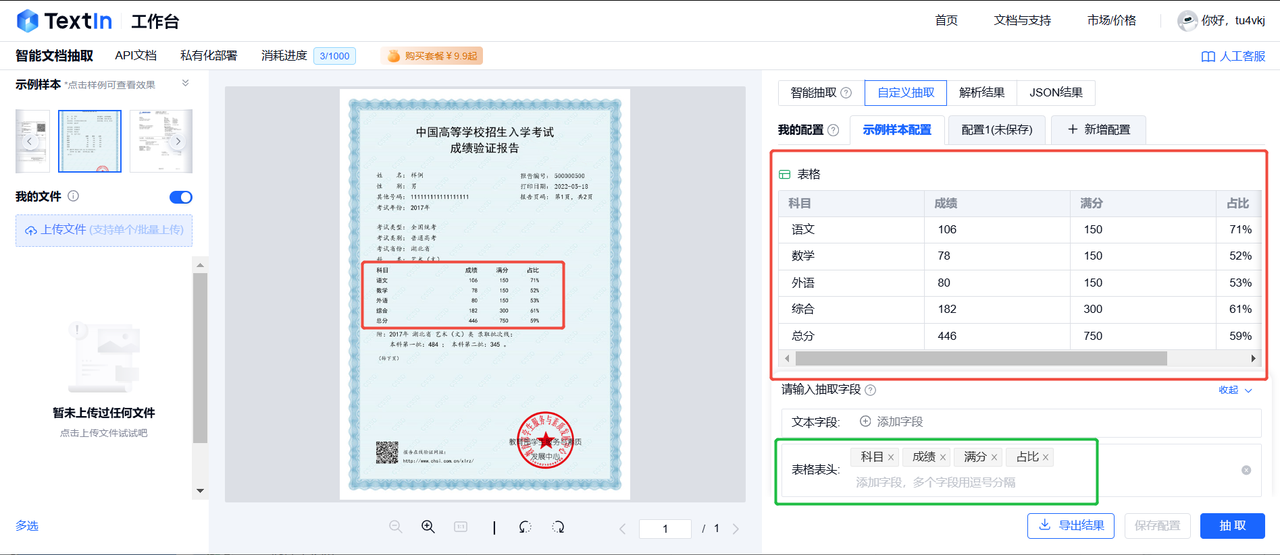
适用于各式各样的文档类型,不管是项目报告、合同文书,还是商业策划等,都能灵活应对,轻松抽取不同文档结构和格式下的关键要素,满足多样化业务场景需求。抽取结果可直接用于数据录入、信息统计、报告撰写等工作环节,无缝衔接后续流程,为业务推进提供有力支持 。
如何利用coze和TextIn搭建一个属于你自己的agent
我们先打开扣子-AI 智能体开发平台进行登录操作
进入到主页之后按照步骤进行创建智能体:工作空间 -> 项目开发 -> 创建 -> 创建智能体 -> 创建 -> 输入项目名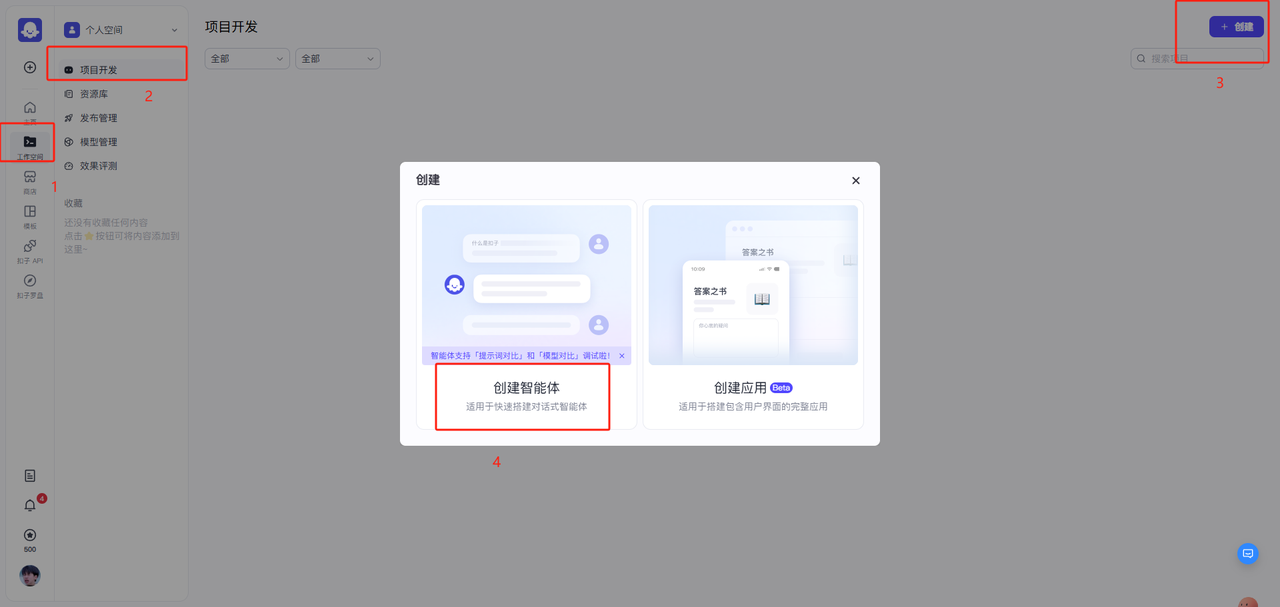
对智能体进行一个设定的操作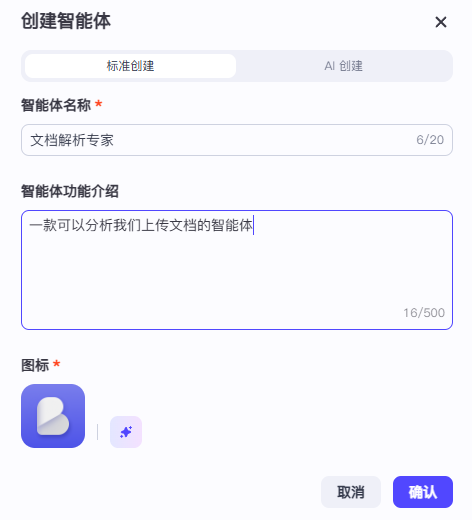
然后点击创建稍等一会儿就可以进入到智能体配置的主界面了,主界面分三块区域,左边的区域是人设与回复逻辑,中间的区域是对这个智能体的各项设置,右边的区域就是预览与调试,可以看到我们的智能体的表现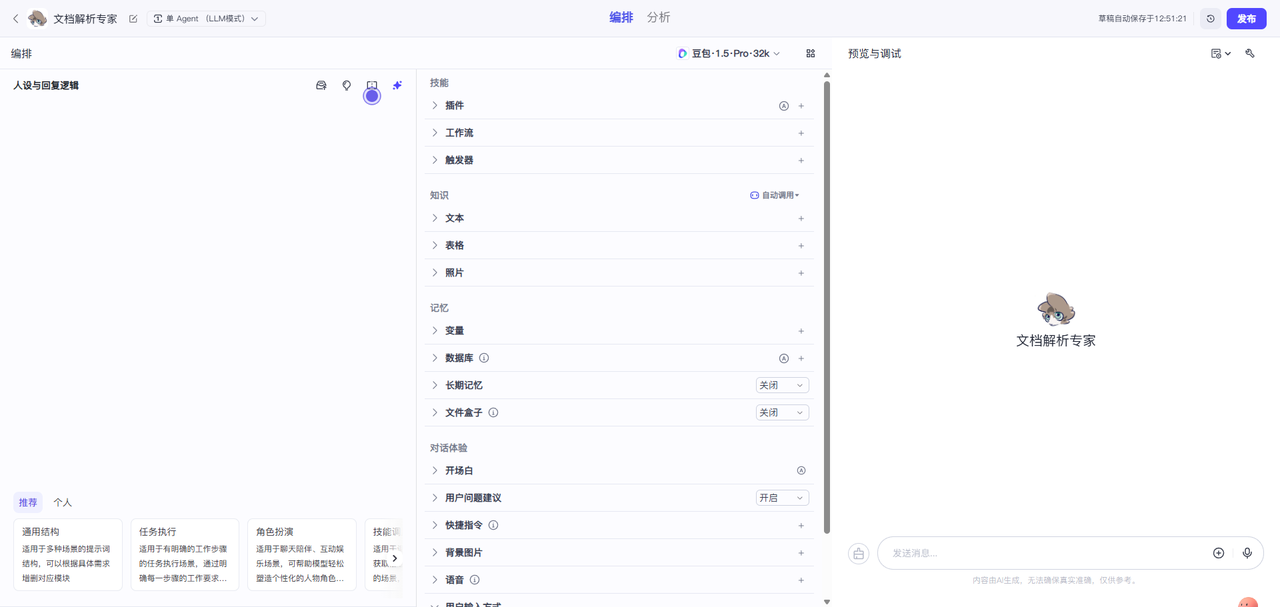
我们在中间区域找到这个工作流,点击右边的加号进行工作流的创建操作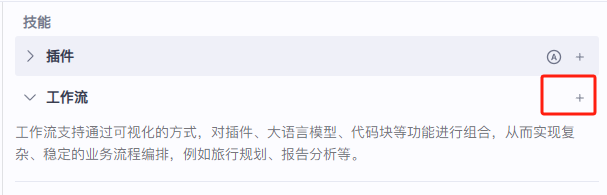
依次点击创建工作流,然后进行工作流名称和工作流描述的设置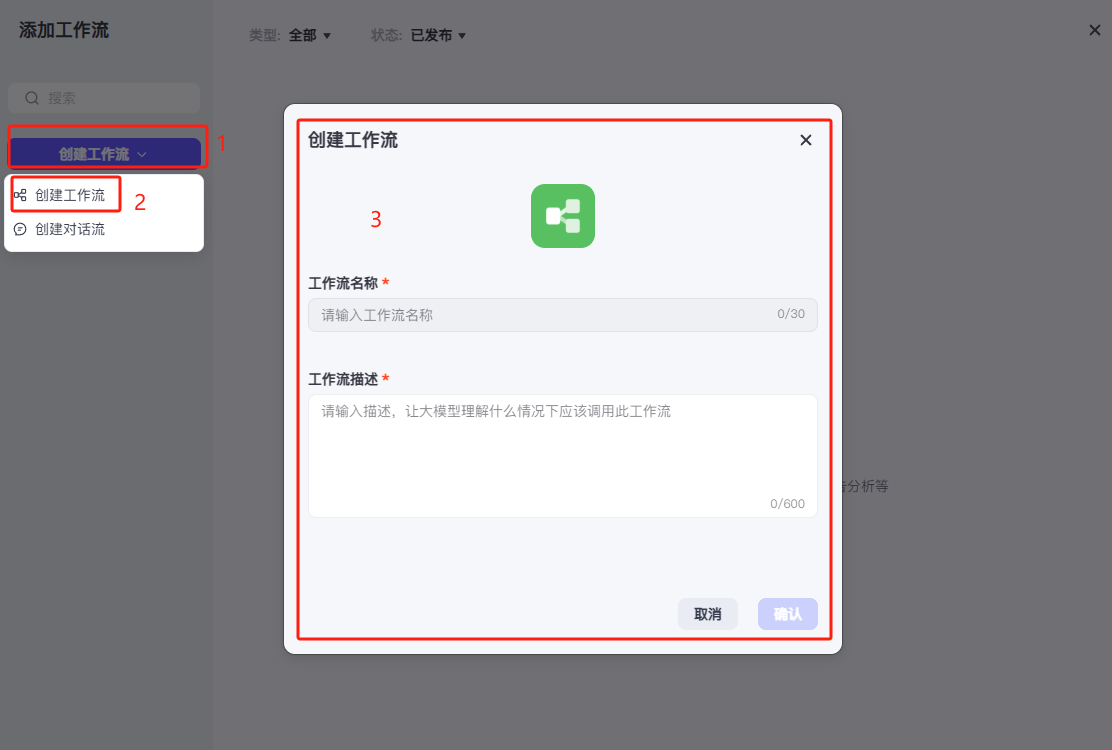
进入到工作流主界面他会有小tips的,教你怎么搭建工作流的
这里我们可以看到有开始和结束的两个节点,那么我们现在的工作就是在中间位置进行节点的搭建操作
点击这里的加号,点击插件
进入到插件页面,在左侧的搜索框中进行一个输入操作:通用文档解析专业版
找到我们需要的那一款文档解析的插件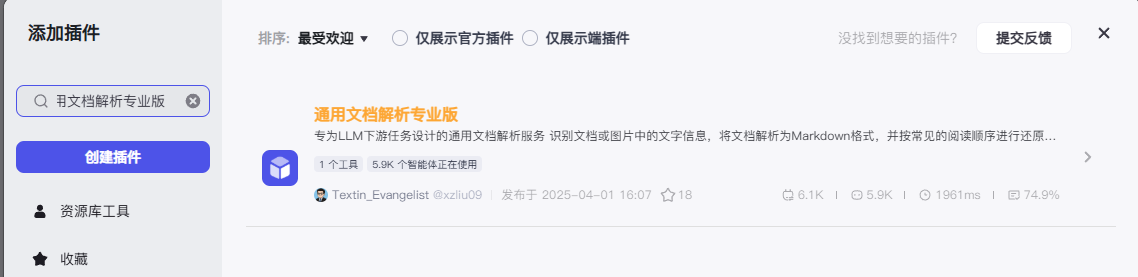
点击添加Parsex
这里科普下:Parsex专为LLM下游任务设计的通用文档解析服务 识别文档或图片中的文字信息,将文档解析为Markdown格式,并按常见的阅读顺序进行还原,赋能下游各类大语言模型任务。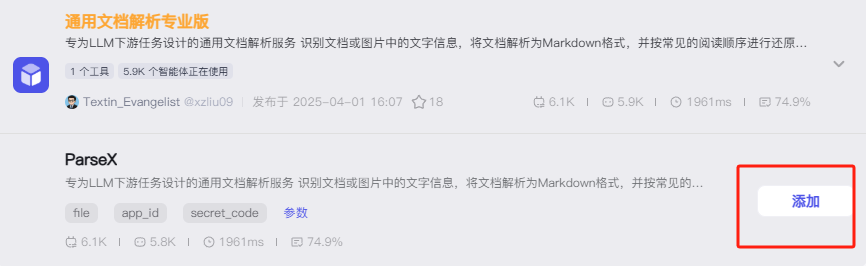
我们也可以理解为在这个扣子中进行api的调用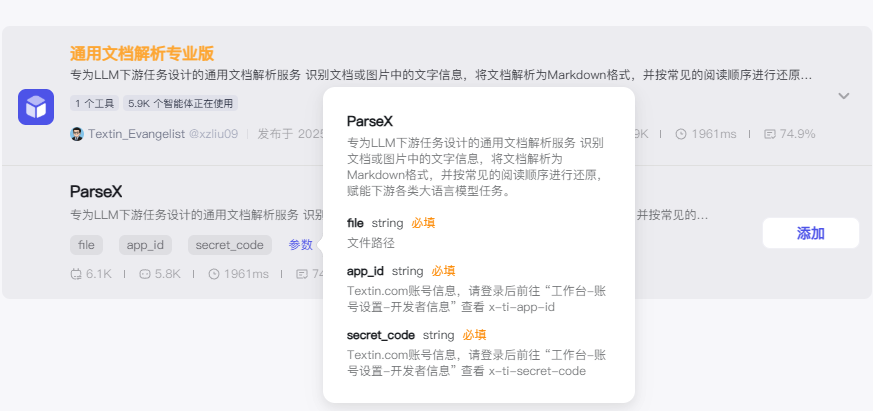
我们这里需要知道我们这个工作流是干什么的,我们这里是对我们上传的文档进行解析操作
所以我们需要将开始的这个节点输入的变量变成一个文件类型的,就是接受的是一个文件,然后通过后续的节点对这个文件进行操作
那么这里我们就能看到我们节点列表中多了Parsex这个节点了
点击这个开始,然后我们在右边就会出现一个弹窗,我们就能对这个接受的变量进行设置,只要我们输入了对应的类型的数据,那么我们这个工作流就能进行运行操作
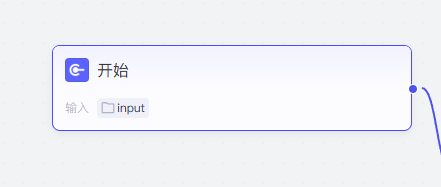
我们将这个设置为File->Default就行了,变量名的话可以自定义,这里我们用的就是默认的inputs就行了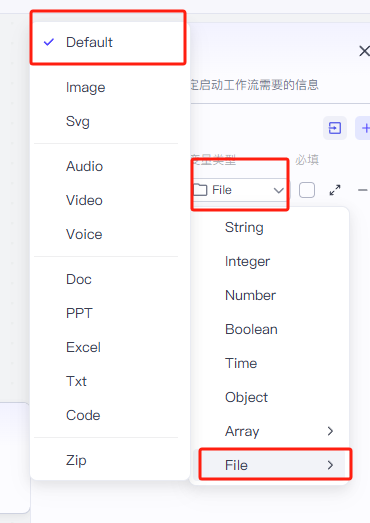
接下来我们进行Parsex这个节点的设置,如果 不能正确的进行配置的话,我们是不能正常调用这个工作流的,就会使用到一半出现卡住报错的情况的,为了避免这种情况,下面的部分一定要认证且看仔细了
点击Parsex这个节点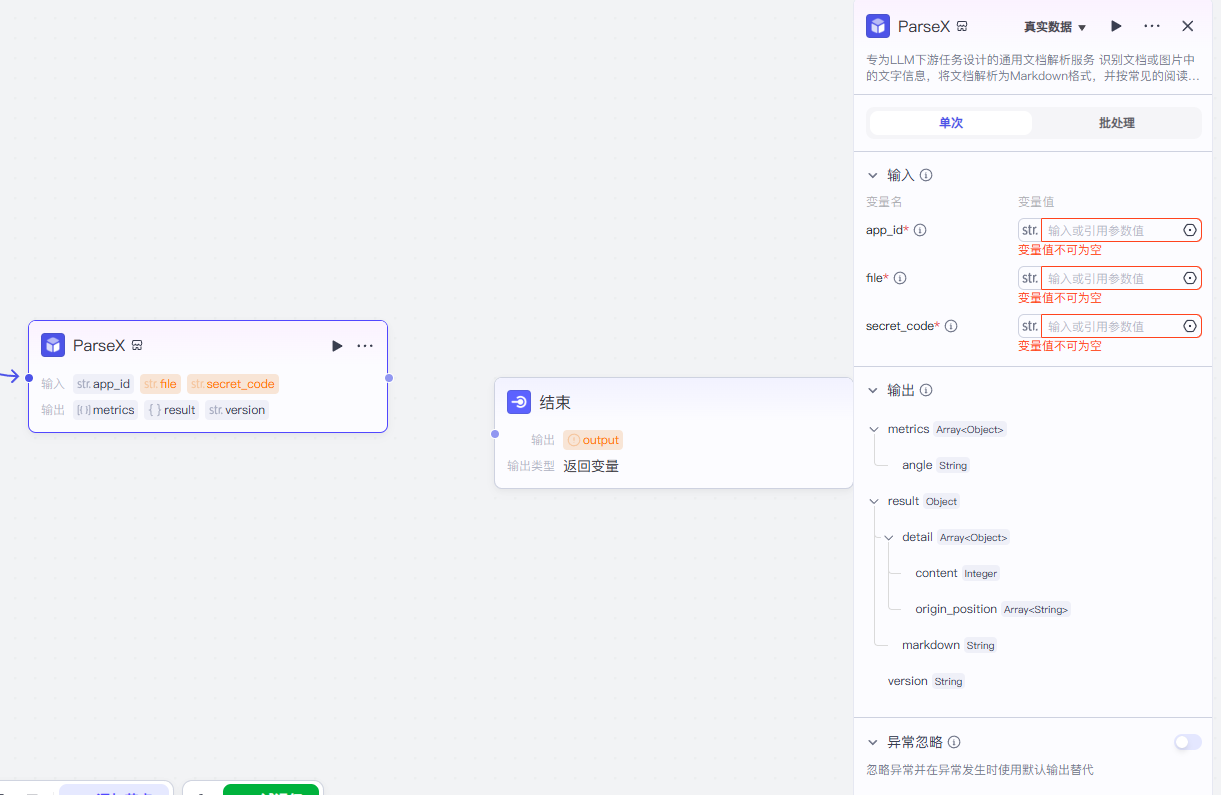
可以看到右边我们是需要填写app_id、file、secret_code这三个信息
我们的这个file的话我们直接设置为我们的开始,就是我们上面的设置的第一个节点,设置好了我们就可以接受到第一个节点的文件了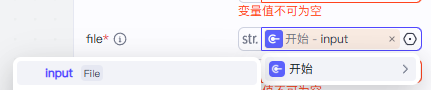
app_id和secret_code这个的话我们点击TextIn个人主页
我们可以在主页的右下角看到对应的信息的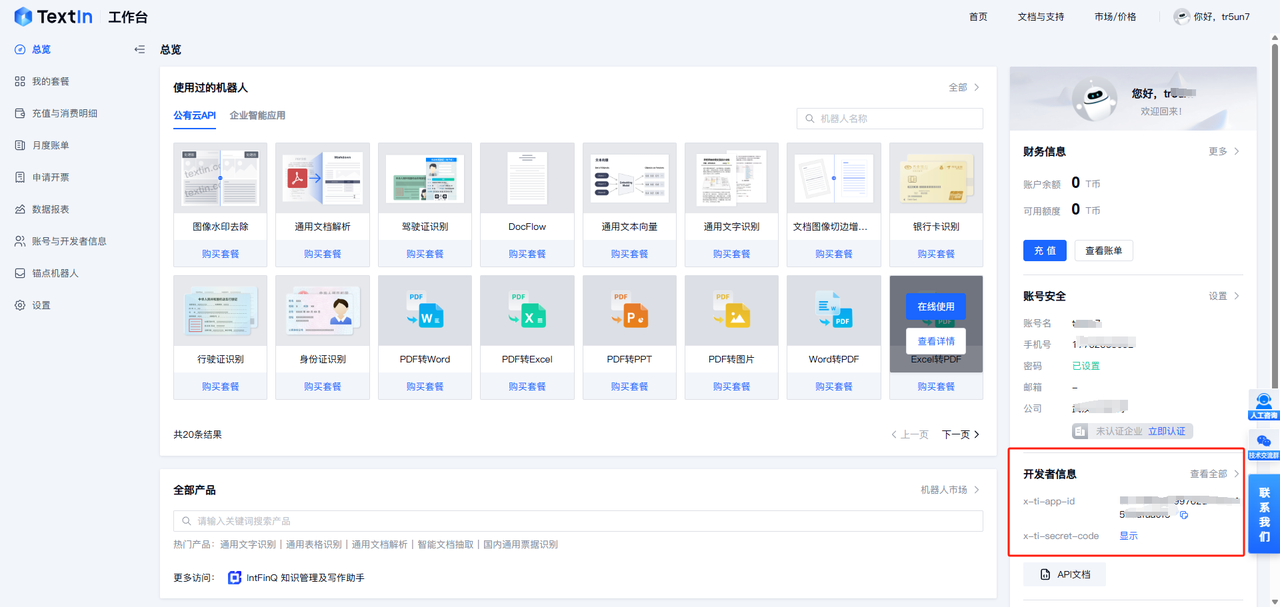
将信息复制到我们扣子的工作流那里就行了
现在我们的第一个节点就是获取我们的文件的,第二个节点Parsex就是对文件进行处理的操作的,我们还需要一个节点对处理后的文档进行一个分析操作的,就是将文件的信息输送给ai大模型,那么就能梳理出一个更耐看的文件了。
点击Parsex这个节点后面加号,点击大模型,那么我们就添加了一个大模型的ai节点了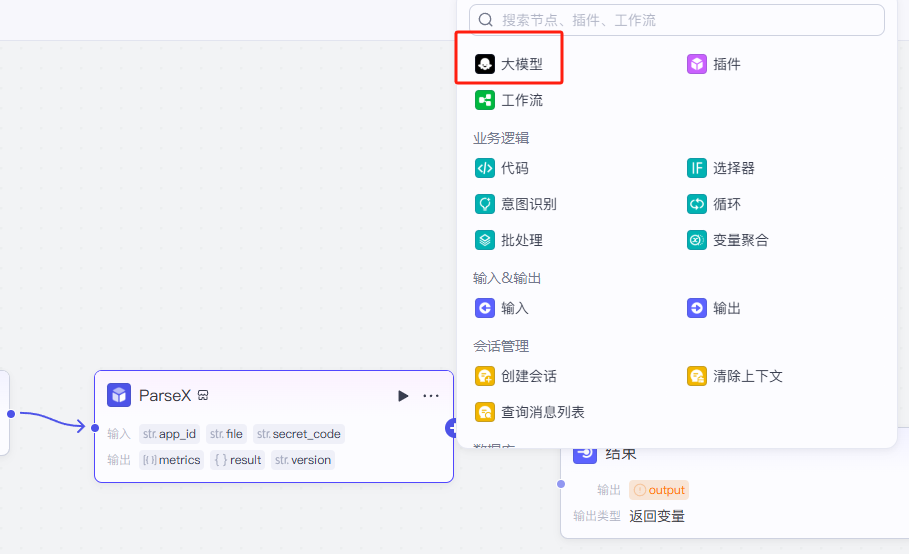
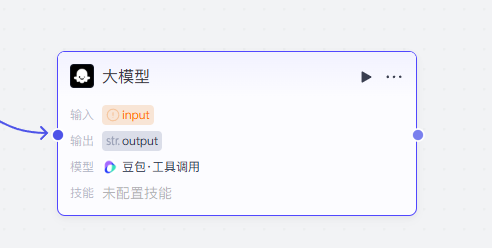
点击大模型这个节点,我们先进行模型的设置操作,模型的话我们就选择deepseek R1的模型就行了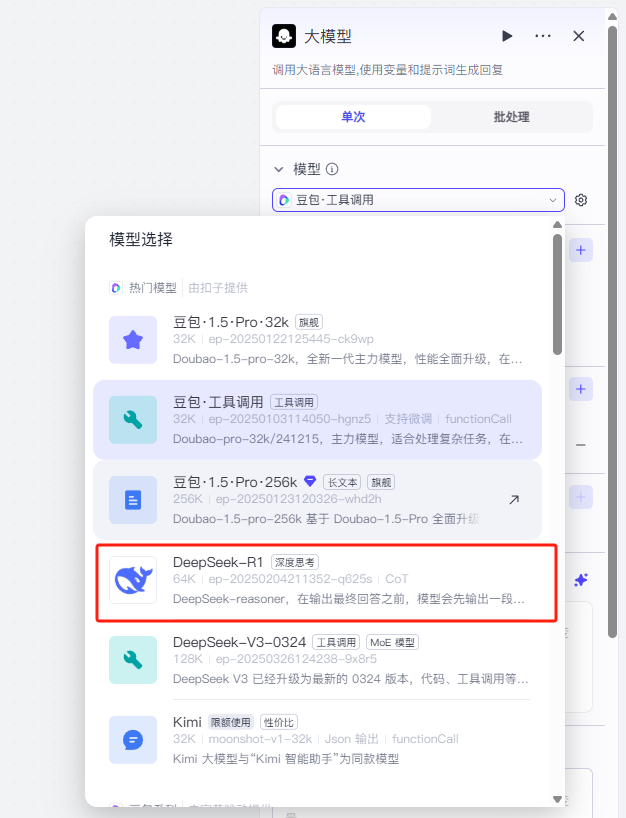
这里我们的输入就是上个节点Parsex输出的md文件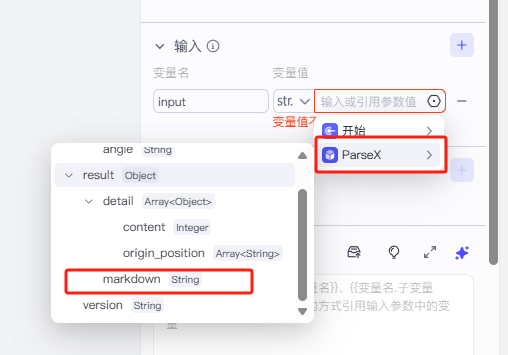
我们在这个系统提示词这里输入:请从输入{{input}}中提取内容,然后进行总结。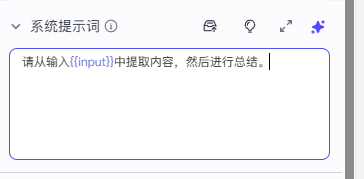
那么我们这个大模型的节点就设置好了,然后最后我们设置下结束的节点了,前提是需要将我们大模型这个节点和结束的这个节点链接上,我们拖动大模型这个节点到结束这个节点,然后就可以通过箭头进行链接了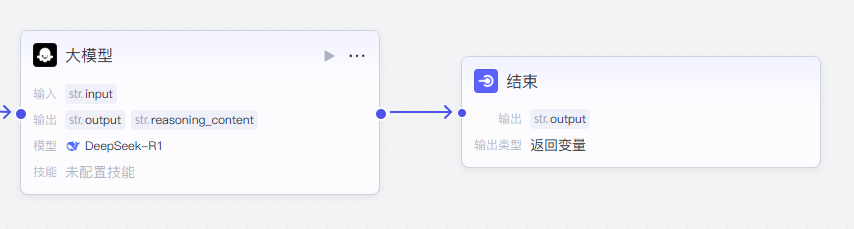
点击结束这个节点,我们将这个输入的变量值设置为大模型中的output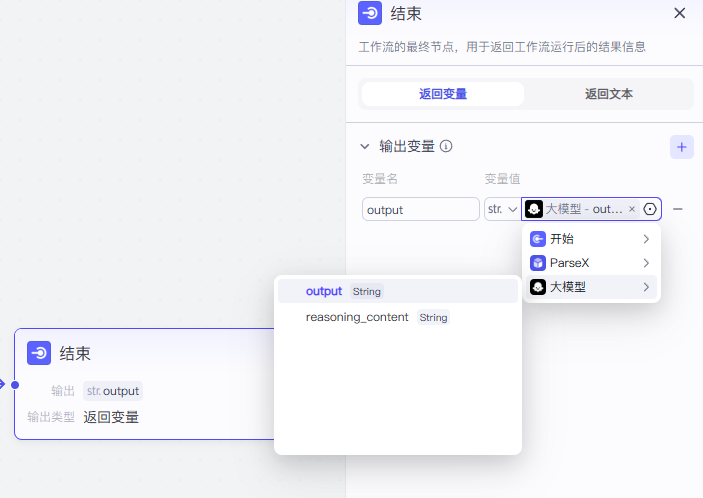
那么到这里我们就简单的创建了一个文件处理的工作流了,我们可以简单的测试下是否能正常的进行运行
点击下方的试运行,然后输入文件到右边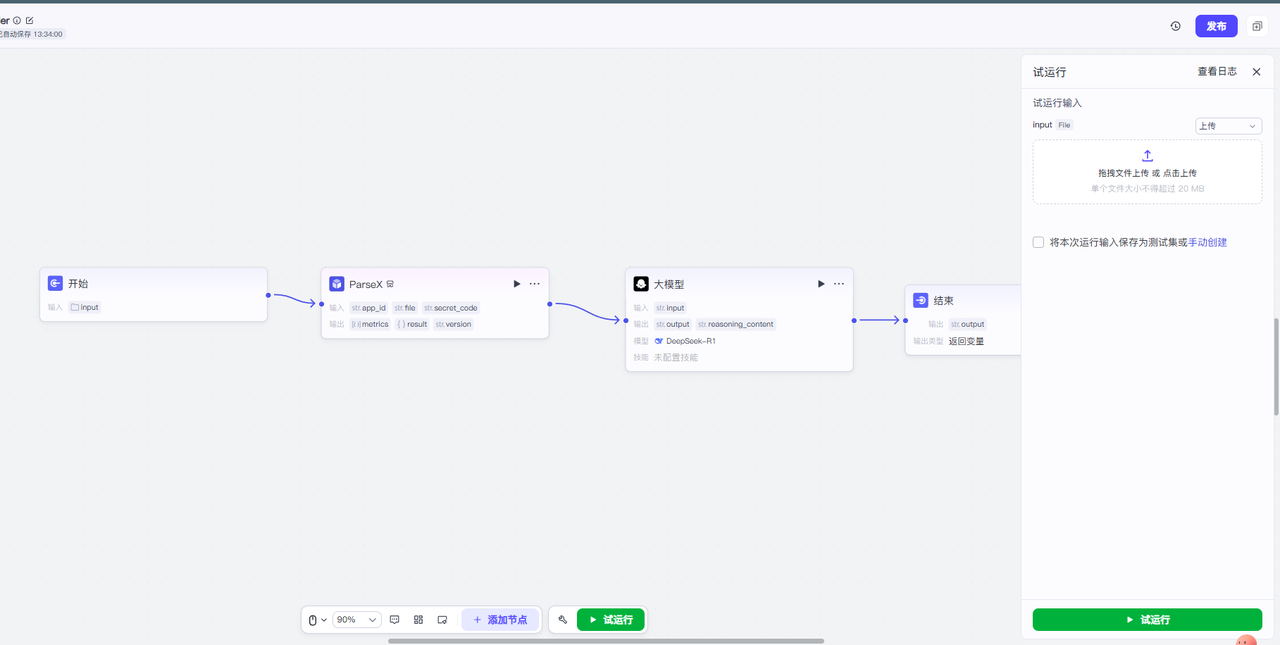
可以识别的文件格式还是蛮多的,我们这个工作流就是将信息转换为md文件更加耐看
我们这里选择了一个pdf进行处理操作,将文件放到输入框后我们直接点击下方的试运行
可以发现我们的ParseX这个节点调用的时间才1s钟,这个速度快的有点逆天了谁实话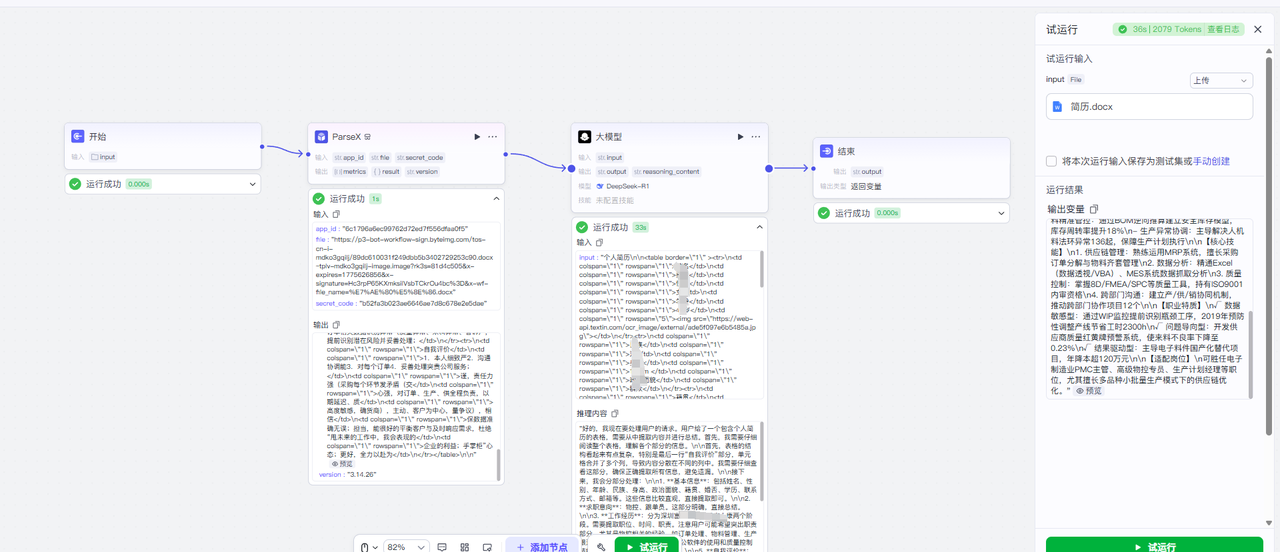
这里我们对输出进行预览,直接点击预览就行了
可以看到分析的结果十分详细,并且很有层次感
测试完毕,体验感觉直接拉满了,我们直接点击右上角的发布就行了
那么这里就能看到我我们刚刚创建的工作流了
然后这里我们就可以在右侧的预览区域进行进一步的测试操作了,我们依旧上传的是一个简历,让他具体分析这个简历了,可以看到确实调用了我们这个工作流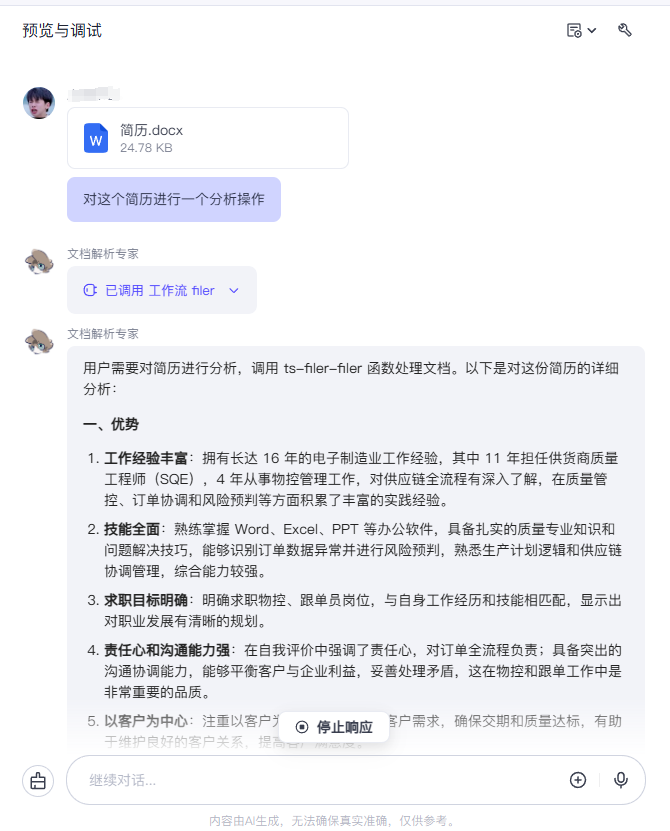
如何利用TextIn和影刀RPA实现商业化去水印操作
视频展示
下面就是我们使用TextIn中的去水印api接口调用和影刀rpa进行合并的视频效果展示,批量化进行水印图片的去处操作
机器学习
电商图片水印处理的困境
电商平台上,商家需要频繁更新商品图片,以保持竞争力和新鲜感。但从素材获取渠道收集来的图片,往往带有各种水印,可能来自图片提供商、原作者或其他相关方。对于大型电商企业而言,商品数量庞大,图片数以万计,如果采用人工手动一张张去除水印,不仅耗费大量人力和时间,还极易出现疏漏。
利用TextIn和魔法指令3.0两步实现去除水印操作
我们这里是利用到了两个魔法指令来实现水印去除的,思想就是选中一个文件夹,将这个文件夹中的带水印的图片进行去处水印并且将这个去处水印的结果存储在我们电脑的本地,下面就详细进行教程,如何利用影刀rpa最新的魔法指令3.0实现这么一个去水印小工具。
首先我们打开影刀rpa创建一个pc自动化应用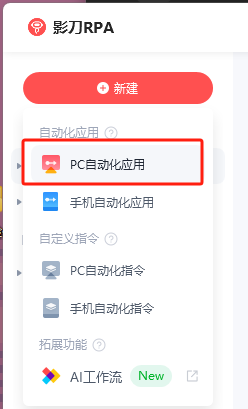
进入到主页面中我们选择左侧栏中的魔法指令,拖拽到我们中间区域,我们这里的第一个魔法指令是弹出一个弹窗来获取我们本地文件夹的地址,这个文件夹就是我们一开始说的存储水印图片的文件夹,我们手动选择本地的文件夹,这个命令就会将这个文件夹的地址进行保存到变量中去,我们是直接对影刀ai说:弹窗,获取文件夹的路径
一句废话不用说,影刀就get到我们想要的效果了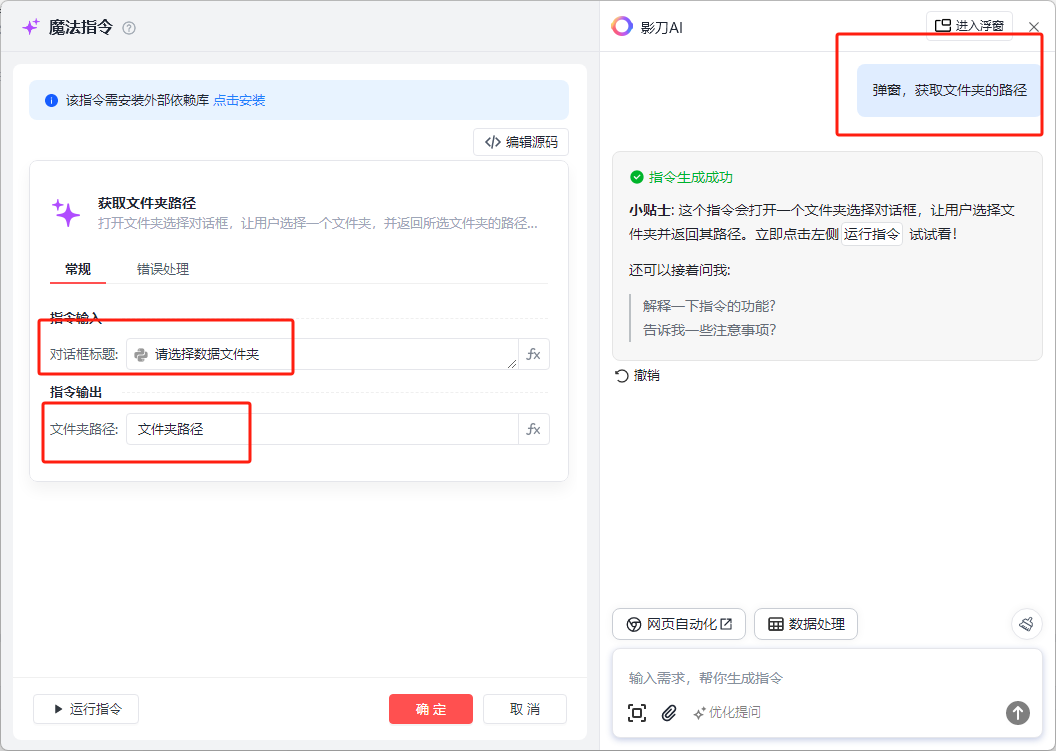
我们这里的文件夹路径存储在:文件夹路径 这个变量里面
我们这里进行测试,我们在这个效果后面加一个打印日志的效果,将这个变量打印出来看看结果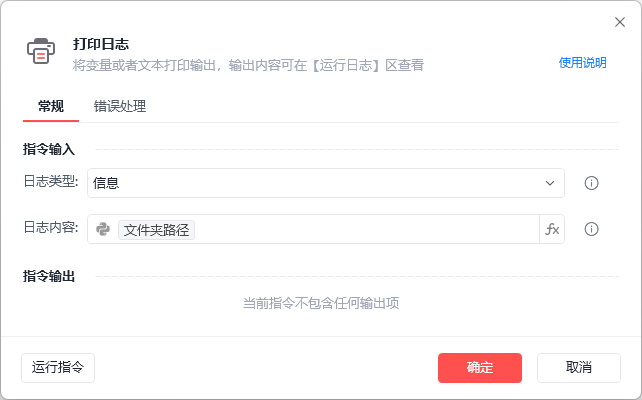
选择这个文件夹:笔试强训48天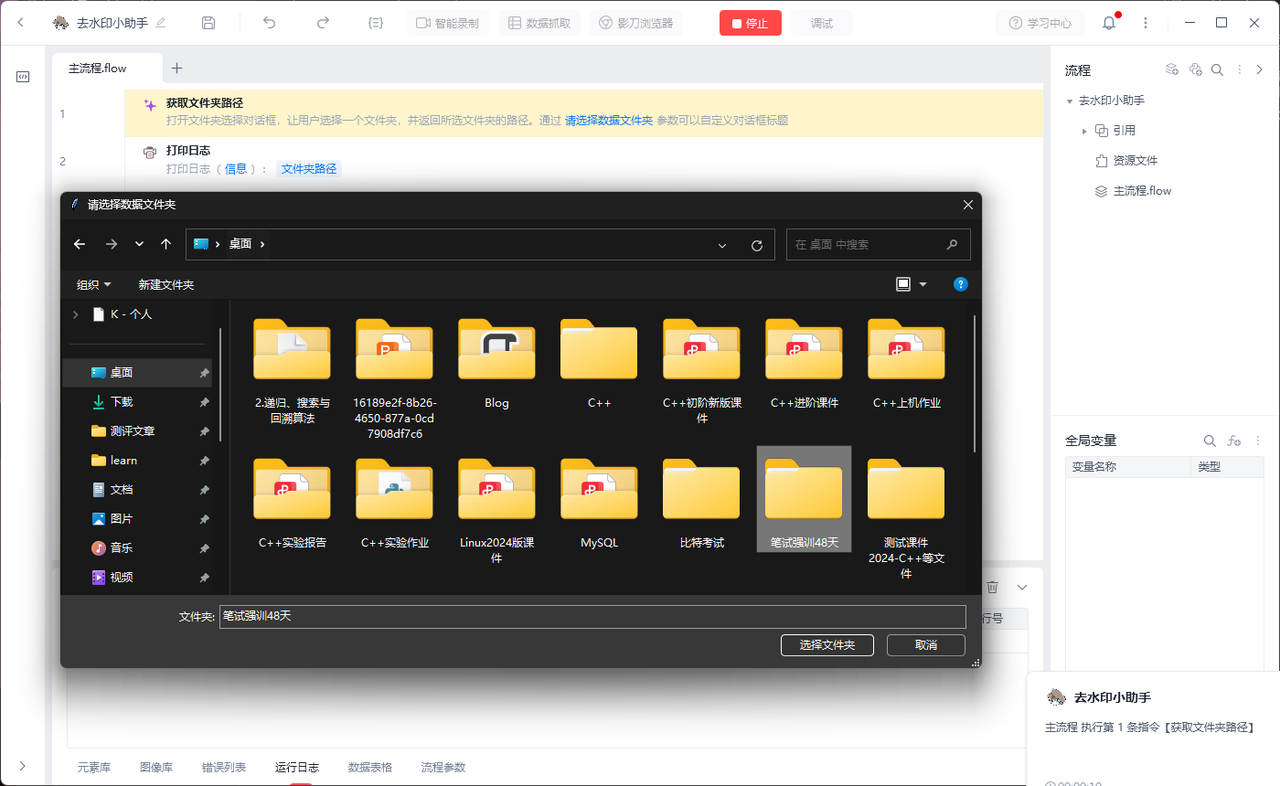
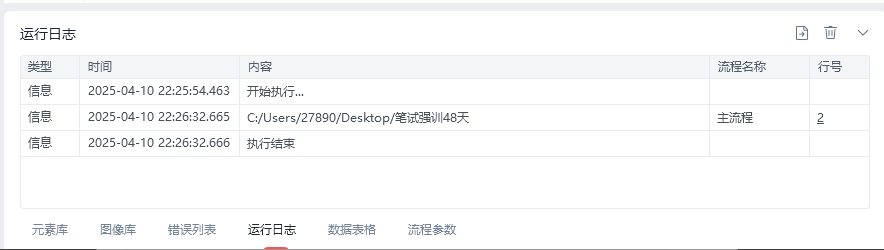
执行完成之后我们可以看见打印的日志,就是变量中的文件夹地址:C:/Users/27890/Desktop/笔试强训48天
那么接下来我们就进行第二条指令的创建,依旧是魔法指令,直接跟他说具体的要求:
我利用打开选择文件夹对话框这个指令选中了一个需要去水印的文件夹,里面存储的都是需要去除水印的图片,请你去除水印并且存储在我们指定的文件夹里面,下面是去除水印调用的api代码,密钥和账号都在里面了:
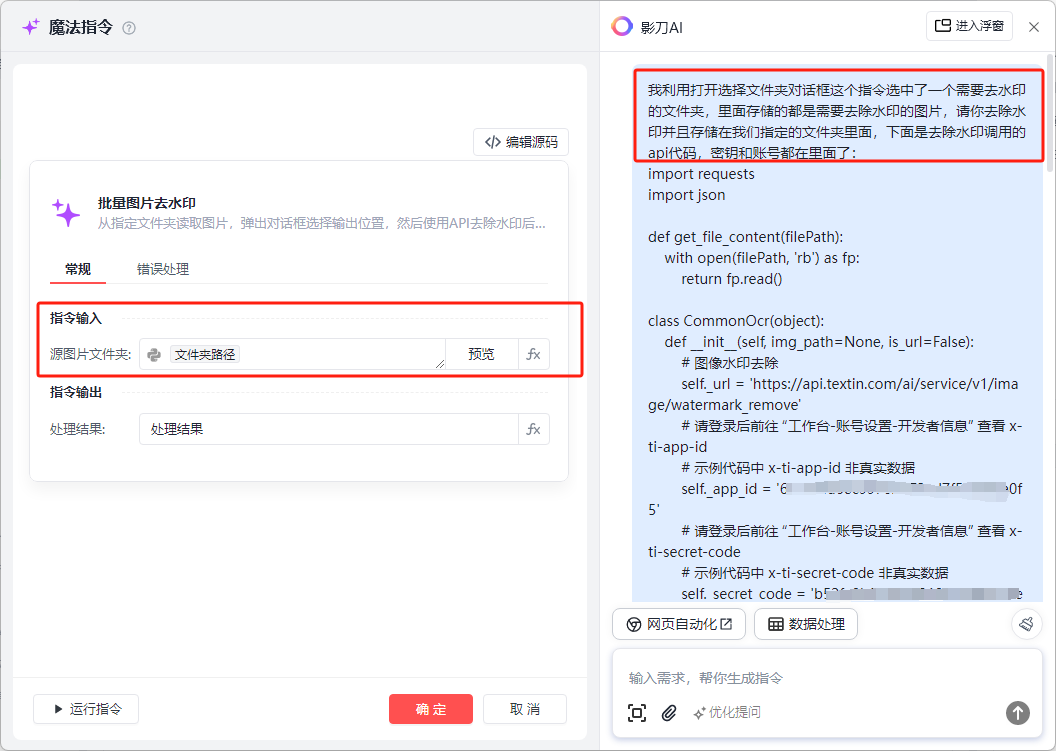
但是我发现他的处理结果不能存储到本地的文件夹,于是我让他在本次的基础上进行改变:
就是我想在去除完水印之后会进行一个弹窗,让我选择一个文件夹存储最后去除水印的结果
并且我们生成的指令是可以进行撤销的,防止我们对本次生成的效果不满意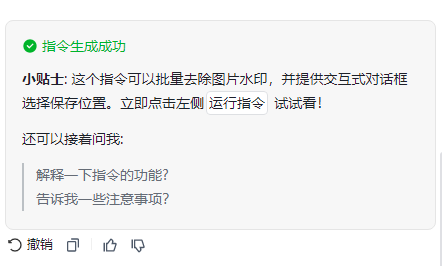
从上一步获取的文件夹地址获取我们需要去除水印的图片,然后再弹出一个弹窗,就是我们选择去除水印存储结果的文件夹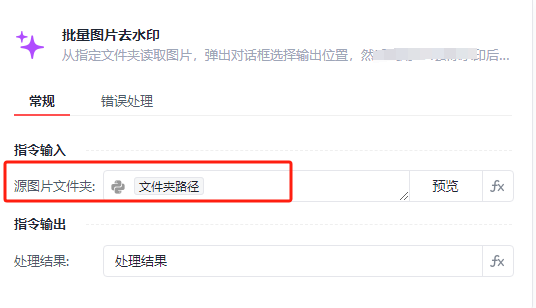
那么到这里我们就使用两步实现了我们的去处水印的操作,并且是批量化的去处水印,将需要去除水印的图片集体放在本地的文件夹中就行了, 之前的话一张一张的去处水印真的很麻烦,并且很耗费时间,在在这里的话我们利用rpa的魔法命令直接点一下就将我们这么多的图片进行去水印操作
下面是第一步的代码:
# 使用此指令前,请确保安装必要的Python库,例如使用以下命令安装:
# pip install tkinter (通常已预装在Python中)
import tkinter as tk
from tkinter import filedialog
from typing import *
try:
from xbot.app.logging import trace as print
except:
from xbot import print
def get_folder_path(title="选择文件夹"):
"""
title: 获取文件夹路径
description: 打开文件夹选择对话框,让用户选择一个文件夹,并返回所选文件夹的路径。通过%title%参数可以自定义对话框标题。
inputs:
- title (str): 对话框标题,eg: "请选择数据文件夹"
outputs:
- folder_path (str): 文件夹路径,eg: "C:/Users/Documents"
"""
# 创建隐藏的根窗口
root = tk.Tk()
root.withdraw()
# 打开文件夹选择对话框
folder_path = filedialog.askdirectory(title=title)
# 销毁隐藏的根窗口
root.destroy()
return folder_path
下面是第二步的代码:
# 使用此指令前,请确保安装必要的Python库,例如使用以下命令安装:
# pip install requests pillow tkinter
import os
import json
import base64
import requests
from PIL import Image
from io import BytesIO
import tkinter as tk
from tkinter import filedialog
from typing import *
try:
from xbot.app.logging import trace as print
except:
from xbot import print
def remove_watermark_from_folder(input_folder):
"""
title: 批量图片去水印
description: 从指定文件夹读取图片,弹出对话框选择输出位置,然后使用API去除水印后保存到选择的文件夹。
inputs:
- input_folder (folder): 源图片文件夹,eg: "C:/Images"
outputs:
- result_message (str): 处理结果,eg: "成功处理10张图片"
"""
# 检查输入有效性
if not os.path.exists(input_folder):
return "输入文件夹不存在"
# 创建tkinter根窗口(但不显示)
root = tk.Tk()
root.withdraw()
# 弹出文件夹选择对话框
output_folder = filedialog.askdirectory(title="选择保存去水印图片的文件夹")
# 如果用户取消选择,则退出
if not output_folder:
return "用户取消了操作"
# 确保输出文件夹存在
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 获取所有图片文件
image_extensions = ['.jpg', '.jpeg', '.png', '.bmp']
image_files = []
for file in os.listdir(input_folder):
file_ext = os.path.splitext(file)[1].lower()
if file_ext in image_extensions:
image_files.append(file)
if not image_files:
return "没有找到图片文件"
# 处理每张图片
processed_count = 0
failed_count = 0
for idx, file in enumerate(image_files):
try:
print(f"正在处理 {idx+1}/{len(image_files)}: {file}")
input_path = os.path.join(input_folder, file)
output_path = os.path.join(output_folder, file)
# 调用API去除水印
response = _remove_watermark(input_path)
response_json = json.loads(response)
if 'result' in response_json and 'image' in response_json['result']:
# 解码Base64图像数据
img_data = base64.b64decode(response_json['result']['image'])
# 保存图像
with open(output_path, 'wb') as f:
f.write(img_data)
processed_count += 1
else:
print(f"处理失败: {file}, 原因: {response}")
failed_count += 1
except Exception as e:
print(f"处理错误: {file}, 错误: {str(e)}")
failed_count += 1
result = f"处理完成: 成功{processed_count}张,失败{failed_count}张"
return result
def _remove_watermark(img_path):
"""API调用函数,用于去除单个图片的水印"""
url = 'https://api.textin.com/ai/service/v1/image/watermark_remove'
app_id = 'xxxxxxxxxxxxxxxxxxxxxxxx'
secret_code = 'xxxxxxxxxxxxxxxxxxxx'
headers = {
'x-ti-app-id': app_id,
'x-ti-secret-code': secret_code,
'Content-Type': 'application/octet-stream'
}
with open(img_path, 'rb') as fp:
image_data = fp.read()
try:
response = requests.post(url, data=image_data, headers=headers)
return response.text
except Exception as e:
return json.dumps({"error": str(e)})
在我们影刀rpa中你如果需要修改代码的话是可以进行修改的,修改成我们的需求代码
总结与未来展望
在实际应用场景中,TextIn 凭借广泛的适用性,展现出巨大价值。与 coze 携手,能为用户定制个性化应用解决方案,满足多样化需求;和影刀 RPA 协同,积极探索商业化路径,挖掘业务潜藏的新价值,为企业发展注入新动力。
产品布局更是可圈可点,大模型加速器、基础识别、文档处理等多维度功能紧密配合,形成精密强大的智能科技矩阵。无论是合同票据处理的专业领域,还是图像优化、格式转换等多元场景,乃至前沿 AI 应用的创新探索,都能高效应对。
未来期望:期待 TextIn 持续深化与 coze、影刀 RPA 等的合作,进一步拓展技术融合的广度与深度。在技术创新上,不断攻克难题,提升对复杂任务的处理能力。应用层面,积极开拓新领域,让智能科技惠及更多行业。同时,不断优化用户体验,以更加便捷、高效、智能的服务,成为企业数字化转型和个人工作生活的得力助手,引领智能应用迈向新高度。
需明确,本文仅为个人观点,并非广告。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











