






一、Hadoop的介绍与准备
1.Hadoop是什么?
简单来说,Hadoop是一个分布式应用程序,主要由HDFS、YARN和MapReduce组成。
-
HDFS (Hadoop Distributed File System): 一个分布式文件系统,负责存储海量数据。
-
YARN (Yet Another Resource Negotiator): 一个资源管理系统,负责管理和调度集群中的计算资源。
-
MapReduce: 一个分布式计算框架,用于处理和分析HDFS上的数据。
1.2.Hadoop的应用场景
Hadoop可以解决以下两个主要问题:
-
海量数据存储: 当本地存储空间不足时,HDFS可以分布式存储海量数据,并提供高可靠性和可扩展性。
-
海量数据分析: 使用MapReduce框架,可以高效地分析HDFS上的数据,并进行各种复杂的计算。
1.3学习Hadoop的目标
通过学习Hadoop,我们将能够:
-
部署Hadoop集群。
-
使用HDFS进行海量数据的存储。
-
使用MapReduce框架开发程序来分析HDFS上的数据。
-
使用Hive和Hbase等基于Hadoop的数据库。
2.环境准备
为了学习Hadoop,我们需要准备一台运行Linux系统的虚拟机。建议使用CentOS 7,因为它在企业和社区中都非常流行。
2.1 Linux基本使用
在学习Hadoop之前,我们需要熟悉Linux的基本操作,包括:
-
进程管理:查看、查找、杀死进程。
-
文件管理:创建、查看、修改、移动、删除文件和文件夹。
-
命令行界面:使用shell命令与操作系统交互。
2.2 准备一台Centos7虚拟机
Cento7系统ISO镜像文件(CentOS-7-x86_64-Minimal-2009.iso)已上传到我的资源。按照以下图片说明,一步一步操作即可。(注:此操作的目的是准备一个Centos7系统,用来安装Hadoop。因为绝大多数的企业,都是将Hadoop运行在linux上,而在众多的开源的linux发行版中,red hat(红帽子)的Centos又是最为流行的)
2.2.1 安装VMware
安装社区版(VMware-player-15.5.7-17171714.exe),这是免费版的。
2.2.2 基于VMware安装Centos7
(1)首先我们打开VMware,点击创建新虚拟机。
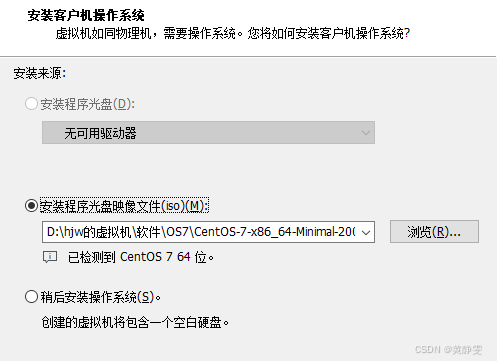
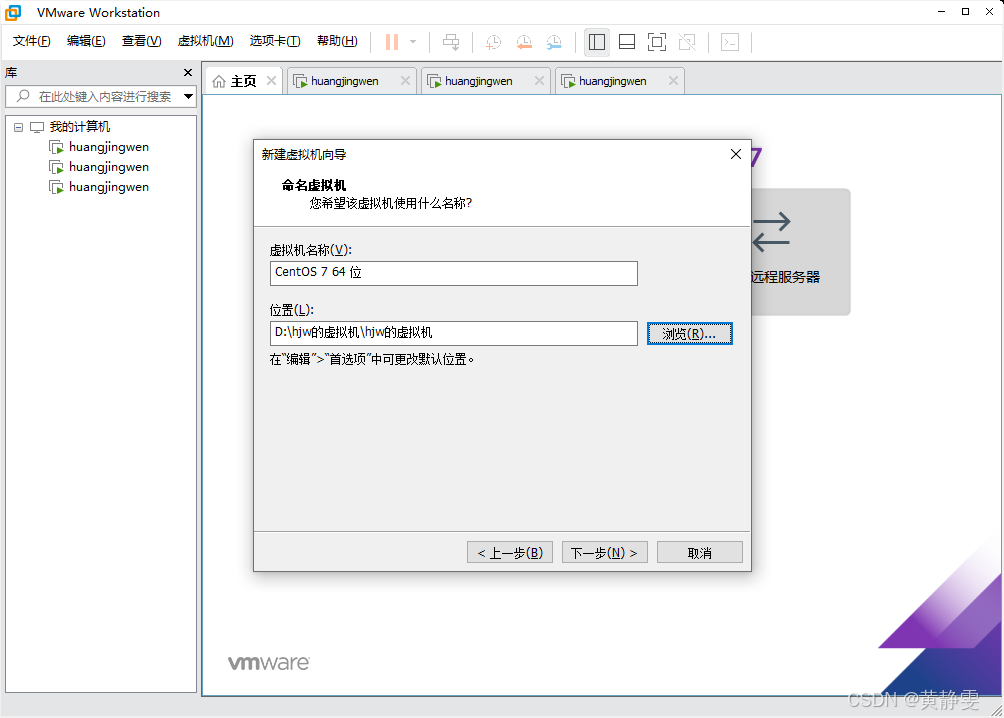
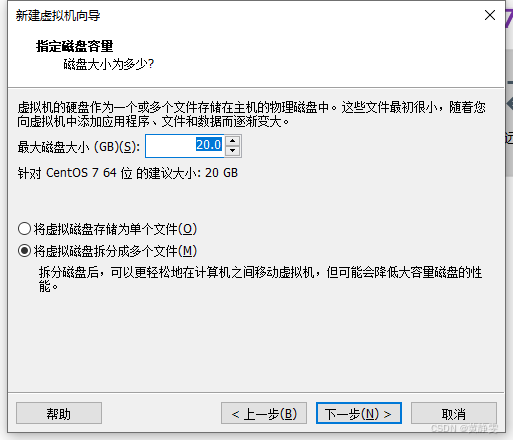
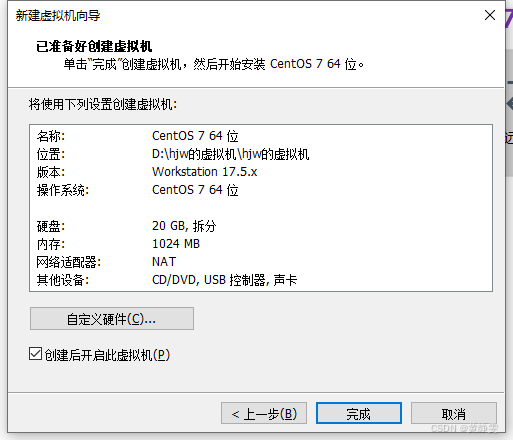
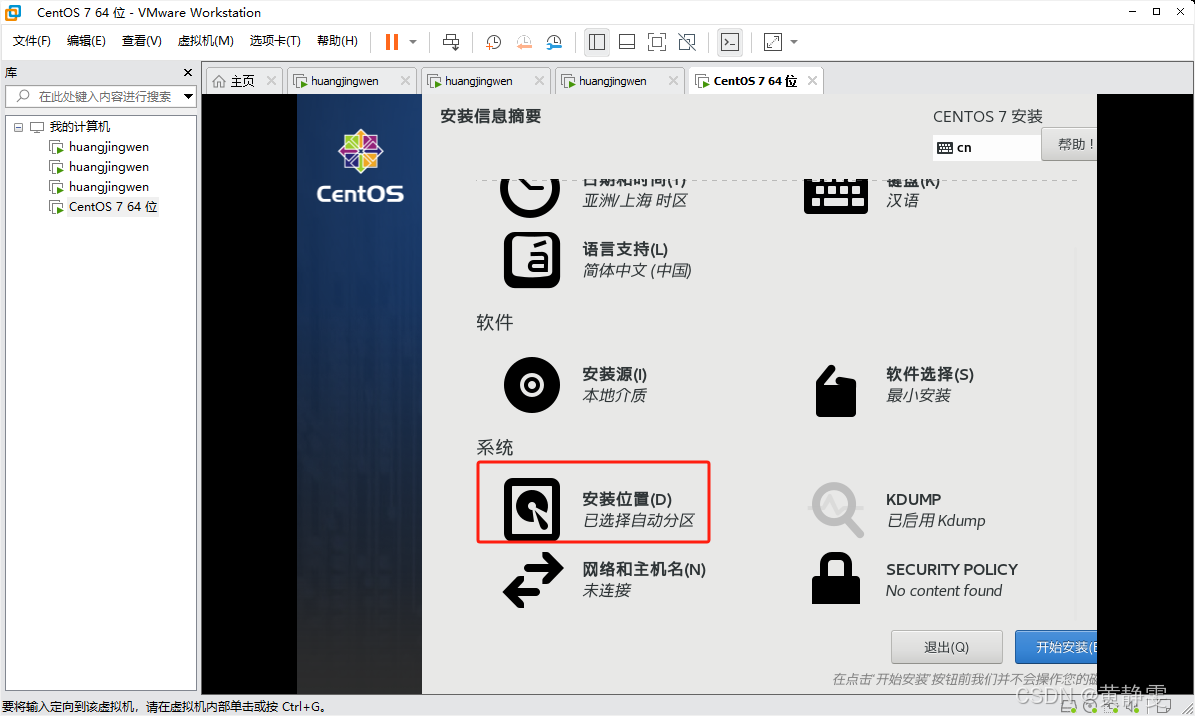
在弹出的对话框中选择要安装的磁盘
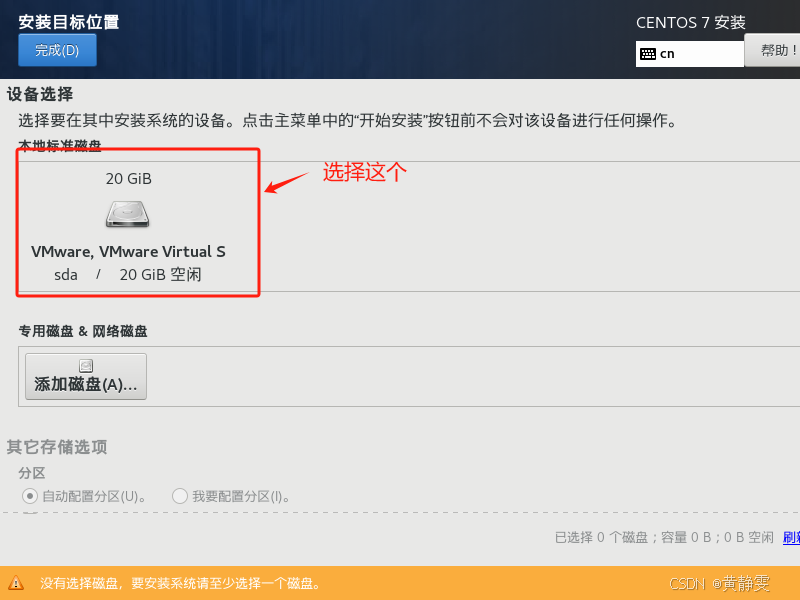
点击完成
注:上图主要是选择磁盘,不选择是无法进行往下安装的
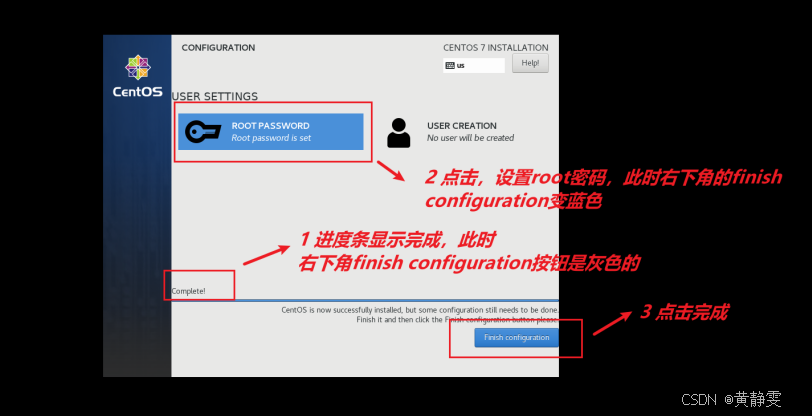

这样我们就 准备好了一台Centos7虚拟机了。
在接下来的博客中,我将详细介绍如何安装和配置Hadoop集群,以及如何使用HDFS和MapReduce进行数据存储和分析。
二、Hadoop 伪分布式部署的基础准备全攻略
在大数据处理领域,Hadoop 无疑是一款非常重要的框架。本文将详细介绍 Hadoop 伪分布式部署前在 Centos7 系统中的各项准备工作,包括设置静态 IP、关闭防火墙、设置主机名、主机名与 IP 的映射以及安装 JDK1.8 等内容,为后续 Hadoop 伪分布式部署奠定坚实基础。
(一)、Hadoop 的三种安装方式
(1)独立(本地)运行模式
直接解压 Hadoop 安装包到指定路径,无需运行守护进程,常用于开发和测试场景。在后续介绍 MapReduce 时,会详细讲解在 Windows 系统中如何配置该模式的本地开发环境。
(2)伪分布式运行模式
在单一节点上部署 Hadoop,需要启动所有相关进程,适用于学习、开发和测试场景,是本文重点关注的部署模式。
(3)完全分布式模式
在多个节点上部署 Hadoop,通常至少需要 3 个节点,常用于生产环境和测试环境,但部署难度相对较高。
(二)、Hadoop 伪分布式安装前的准备工作
(1)在 Centos7 中设置静态 IP
- 目的
Centos7 默认通过 DHCP 协议获取 IP,每次开机虚拟机 IP 可能变动,这对集群环境极为不利,设置静态 IP 可避免此问题。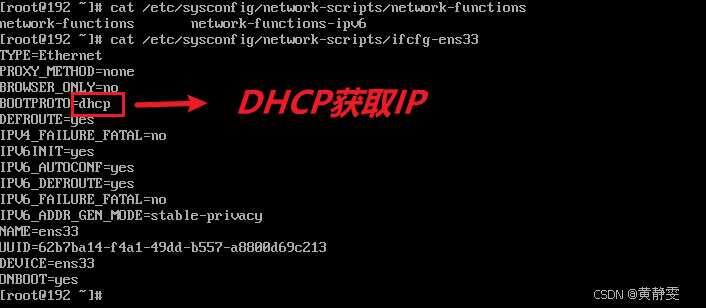
- 设置方法
编辑/etc/sysconfig/network-scripts/ifcfg-ens33文件,将BOOTPROTO=dhcp改为BOOTPROTO=static,并设置IPADDR(与电脑 VMnet8 在同一网段,如192.168.159.128)、NETMASK(与 VMnet8 一致,如255.255.255.0)、GATEWAY(默认xxx.xxx.xxx.2,网段与 VMnet8 相同)和DNS1(如8.8.8.8)。设置完成后重启网卡,通过ping外网地址验证是否成功访问外网。
vi /etc/sysconfig/network-scripts/ifcfg-ens33

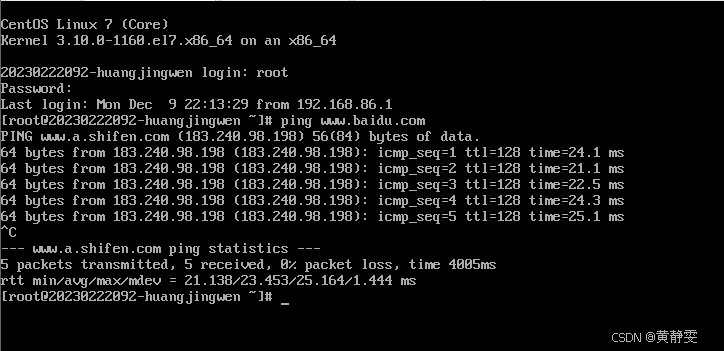
改完后我们要重启网卡,并验证是否可以访问外网:
systemctl restart network
ping www.baidu.com
windows怎么看网卡VMnet8的IP、子网掩码呢?
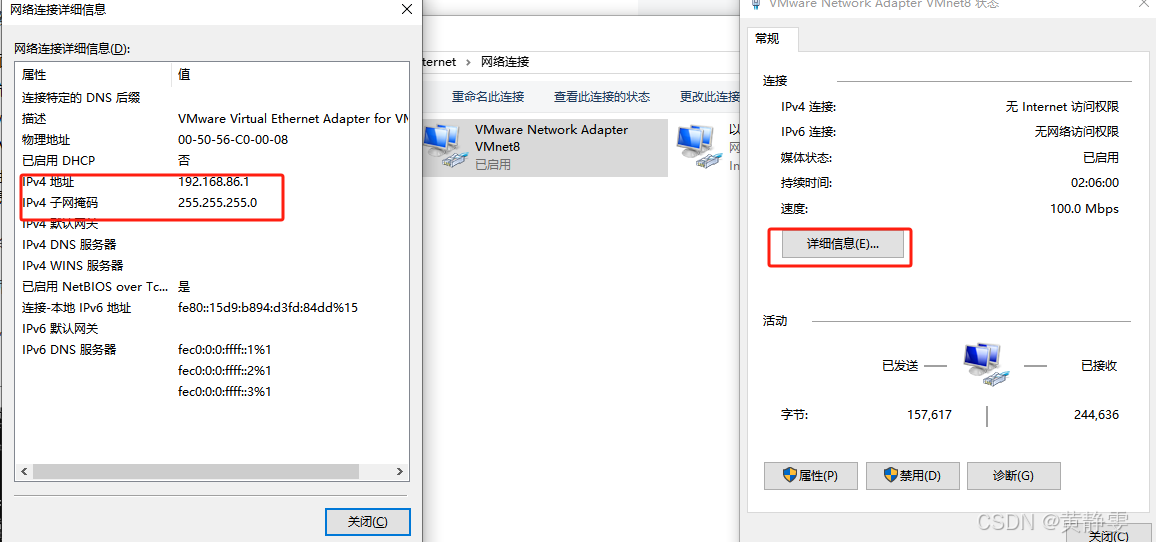
在 Windows 系统中查看网卡 VMnet8 的 IP 地址和子网掩码,可按如下步骤操作:
方式一:通过网络连接状态查看
- 打开 “控制面板”,选择 “网络和共享中心”。
- 在左侧导航栏中,点击 “更改适配器设置”。
- 找到 “VMware Network Adapter VMnet8” 网卡,右键点击并选择 “状态”。
- 在弹出的 “VMware Network Adapter VMnet8 状态” 窗口中,点击 “详细信息” 按钮。
- 在 “网络连接详细信息” 中,可查看 “IPv4 地址” 即为 VMnet8 的 IP 地址,“子网掩码” 也会显示相应信息。
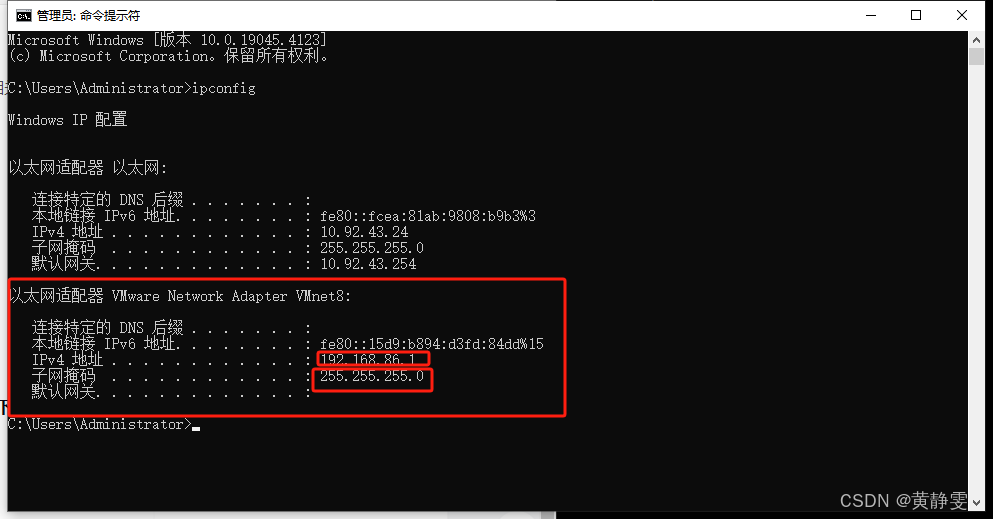
方式二:通过命令行查看(以管理员身份运行命令提示符)
打开命令提示符后,输入命令ipconfig。
在显示的信息中,找到 “以太网适配器 VMware Network Adapter VMnet8” 相关部分。“IPv4 地址” 就是 VMnet8 的 IP 地址。“子网掩码” 也会明确列出。
方式三:通过 VMware Workstation 软件查看(如果安装了该软件)
打开 VMware Workstation 软件。
点击菜单栏中的 “编辑”,选择 “虚拟网络编辑器”。
在弹出的 “虚拟网络编辑器” 窗口中,选择 “VMnet8”。
右侧 “子网 IP” 显示的就是 VMnet8 的 IP 地址。
“子网掩码” 也会一同显示。
注意:改完IP后,可以用MobaXterm_Personal_9.0.exe远程连接操作。接下来我会借助 MobaXterm 工具操作。
![]()
(2)关闭防火墙
1.防火墙原理与默认状态
防火墙是控制流量进出的程序,Centos7 默认开机自启。在集群部署中,节点间进程通信频繁,为方便起见通常关闭防火墙。不过在伪分布式环境下,因仅涉及一个节点,不关闭也可正常工作。操2.作步骤查看防火墙状态:使用systemctl status firewalld命令查看防火墙状态,若显示active (running)则表示防火墙正在运行。
systemctl status firewalld

3.关闭防火墙:执行systemctl stop firewalld命令停止防火墙。
systemctl stop firewalld
4.查看防火墙是否开机自启:通过systemctl is-enabled firewalld命令查看,若显示enabled表示开机自启,disabled表示不开机自启。

5.禁止防火墙开机自启:执行systemctl disable firewalld命令可禁止防火墙开机自启。
(3)设置主机名
给机器命名,类似于人的姓名,方便后续识别和管理。使用hostnamectl set-hostname <主机名>命令进行设置,设置完成后可通过hostname命令查看当前主机名。

然后重启就可以了。
(4)设置主机名和 IP 的映射
在计算机网络中,通过编辑/etc/hosts文件,添加主机名与 IP 的映射记录,如192.168.86.199 hjw-01,以便程序通过主机名进行通信时能正确解析 IP 地址。在集群环境中,需添加所有节点的主机名与 IP 映射。
vi
/etc/hosts

追加一个IP和主机名的映射,集群情况下,还要别的节点,那么也要把别的节点的主机名和IP映射添加进来说明:在不加这个映射的情况下,ping当前机器的主机名,也能成功 。
(5)在 Centos7 中安装 jdk1.8
文件上传
借助 MobaXterm 工具,先通过 SSH 远程登录到虚拟机,再利用其 SFTP 功能将jdk-8u221-linux-x64.tar.gz文件上传到/usr/local路径。
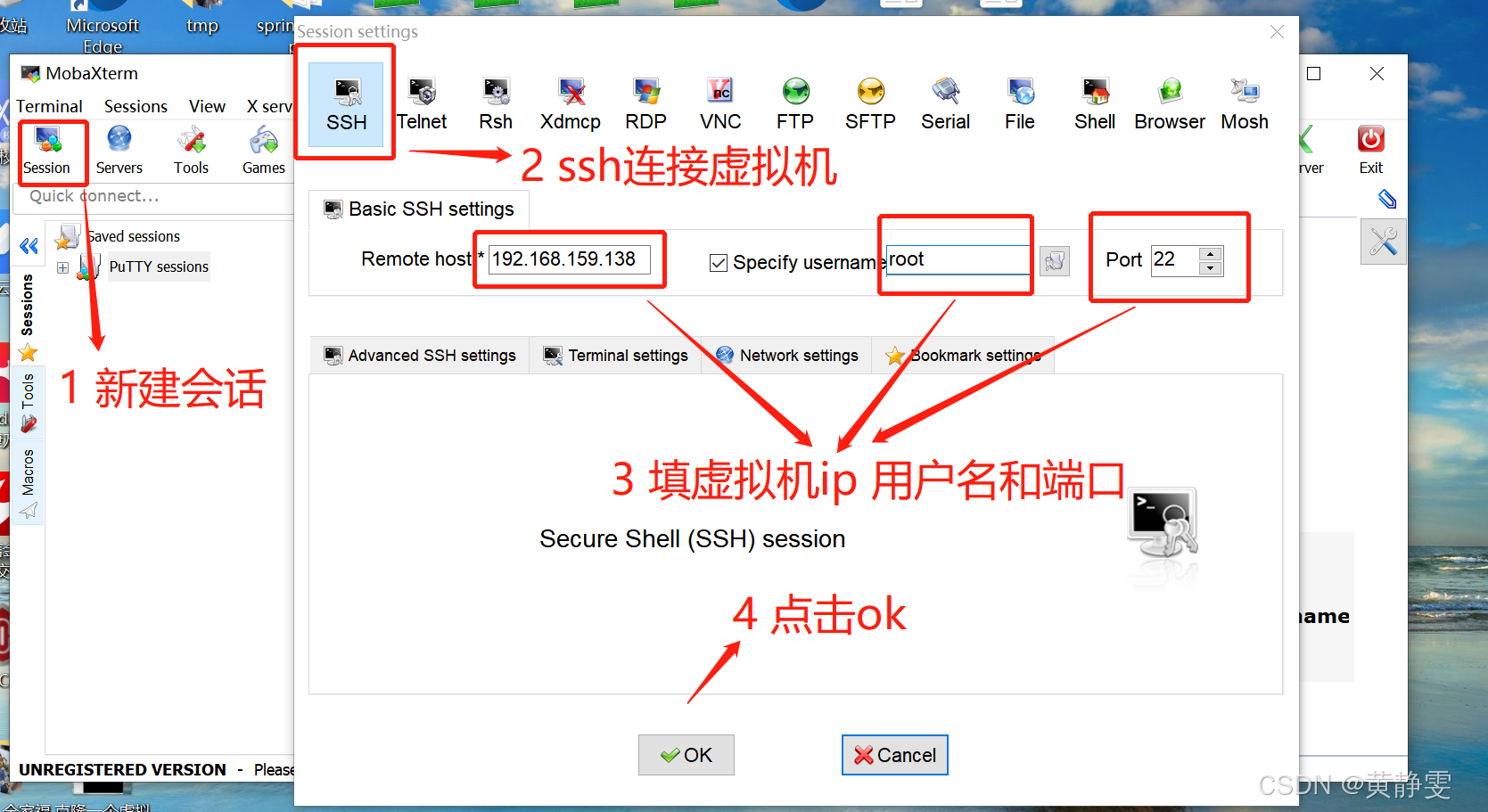
安装过程
解压 JDK:在/usr/local路径下执行tar -xzvf jdk-8u221-linux-x64.tar.gz命令解压文件。
tar -xzvf jdk-8u221-linux-x64.tar.gz
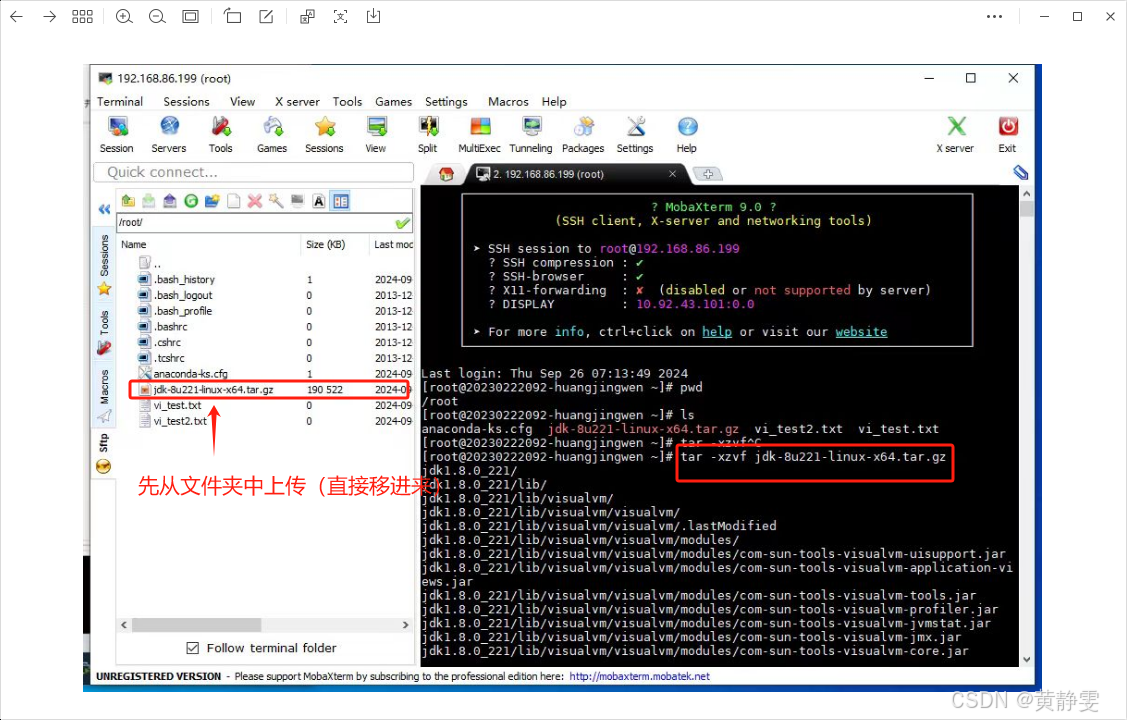
解压完后,我们需要 复制到 /usr/local 路径下
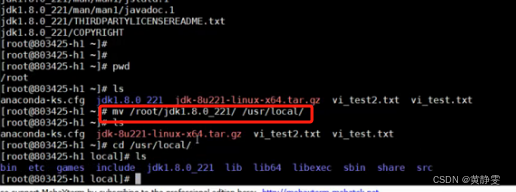
然后我们看一下
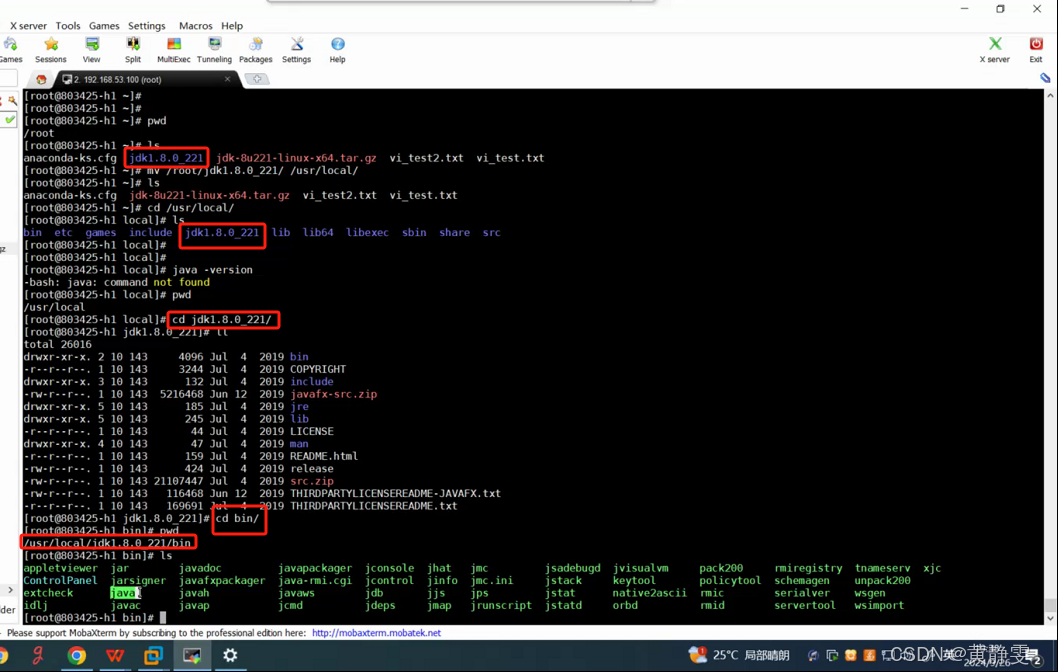
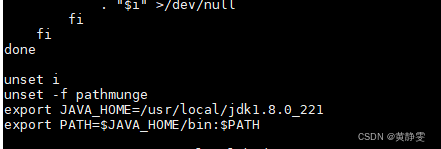
配置环境变量:在/etc/profile文件末尾追加export JAVA_HOME=/usr/local/jdk1.8.0_221和export PATH=$JAVA_HOME/bin:$PATH,然后执行source /etc/profile使配置生效。
vi
/etc/profile
配置环境变量:
export JAVA_HOME=/usr/local/jdk1.8.0_221
export PATH=$JAVA_HOME/bin:$PATH
使配置生效:
source /etc/profile
验证安装:执行java -version命令,若显示 Java 版本信息则表明 JDK 安装成功。
java -version

通过完成上述准备工作,我们已经为 Hadoop 伪分布式部署搭建好了基本环境。这些步骤虽然繁琐,但每一步都至关重要,是后续成功部署 Hadoop 并进行大数据处理的基础。
三、Hadoop 伪分布式部署实战
在大数据处理领域,Hadoop 无疑是一颗璀璨的明星。它的分布式计算能力让处理海量数据变得高效且可行。咱们就来深入学习 Hadoop 伪分布式部署,这可是掌握 Hadoop 技术的重要一步哦。
1、SSH 免密登录配置
(一)远程登录方式
在机器之间进行远程控制时,SSH 是常用的安全通信协议。比如,在机器 1 上远程控制机器 2,需要在机器 1 安装 SSH 客户端,机器 2 安装 SSH 服务端,它们之间通过 SSH 协议通信。在 Linux 系统中,SSH 命令就是 SSH 客户端程序,sshd 进程则是 SSH 服务端。我们可以通过用户名和密码的方式进行远程登录,像执行ssh user1@192.168.159.100命令,但要注意输入的密码得是对应账号的密码哦。
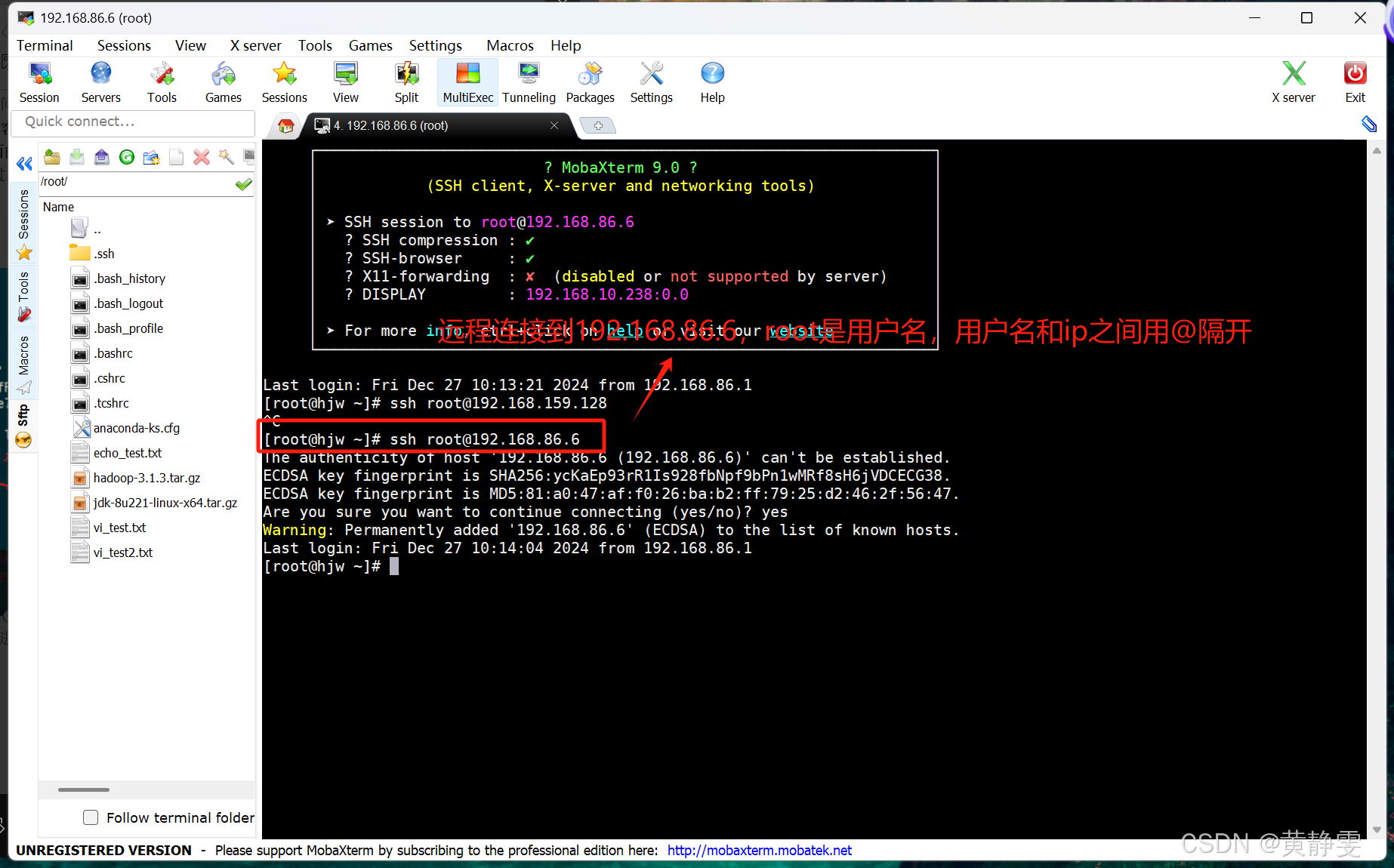
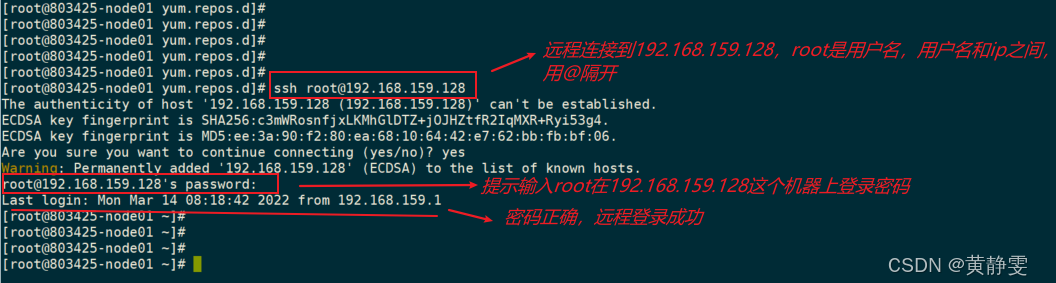
注意:当执行ssh user1@192.168.159.100命令进行远程登录,这时应该输入的是root账号的密码吗?为什么?
- 不一定是 root 账号的密码
- 当执行
ssh user1@192.168.159.100命令时,是尝试以user1这个用户账号登录到 IP 地址为192.168.159.100的远程主机。 - 应该输入的是
user1账号对应的密码,而不是 root 账号的密码。因为ssh命令中明确指定了要登录的用户是user1,远程服务器会验证user1这个用户的身份,而不是 root 用户的身份。
- 当执行
- 验证过程示例
- 假设远程服务器运行的是 Linux 系统。当输入
ssh user1@192.168.159.100并回车后,服务器会收到连接请求,并检查是否有user1这个用户。 - 如果有
user1这个用户,服务器会要求输入user1用户的密码(前提是服务器配置为通过密码验证)。只有输入正确的user1用户密码,才能成功登录到远程服务器上以user1用户的身份进行操作。 - 如果服务器配置为使用公钥认证等其他认证方式,可能会要求提供与
user1用户对应的私钥等认证信息,而不是密码。
- 假设远程服务器运行的是 Linux 系统。当输入
- 安全和权限考虑
- 从安全角度讲,不允许随意使用 root 账号进行远程登录是一种良好的安全策略。因为 root 账号拥有最高权限,一旦 root 账号的密码泄露,整个系统的安全将受到严重威胁。
- 许多服务器会禁止 root 账号通过 SSH 直接登录,只允许普通用户登录后,再通过
sudo等命令提升权限来执行需要 root 权限的操作。这样可以增加系统的安全性,对用户的操作进行审计和控制。
(二)免密登录配置步骤
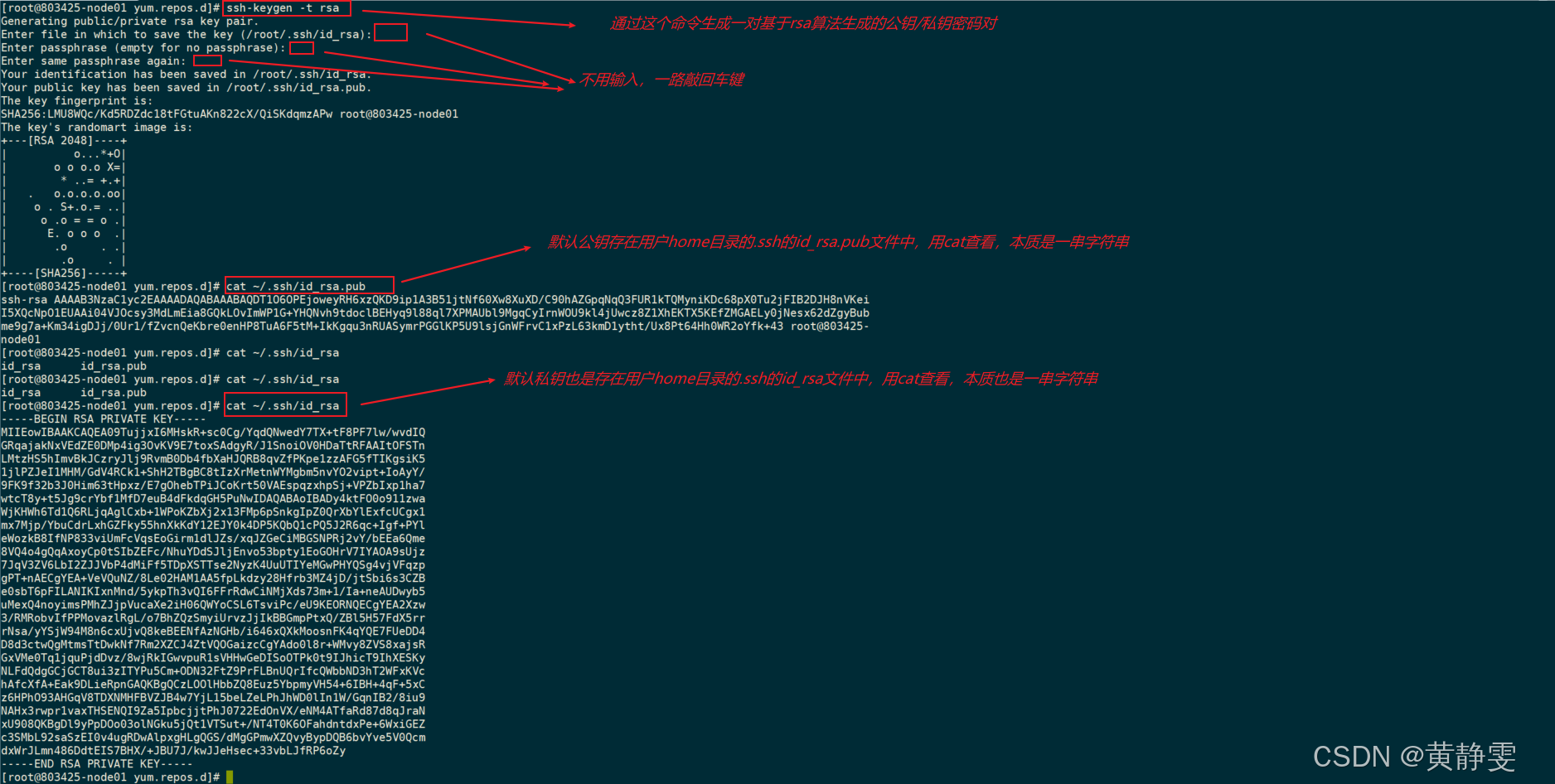
1.生成公钥 / 私钥密码对:使用特定命令生成,这是实现免密登录的基础。
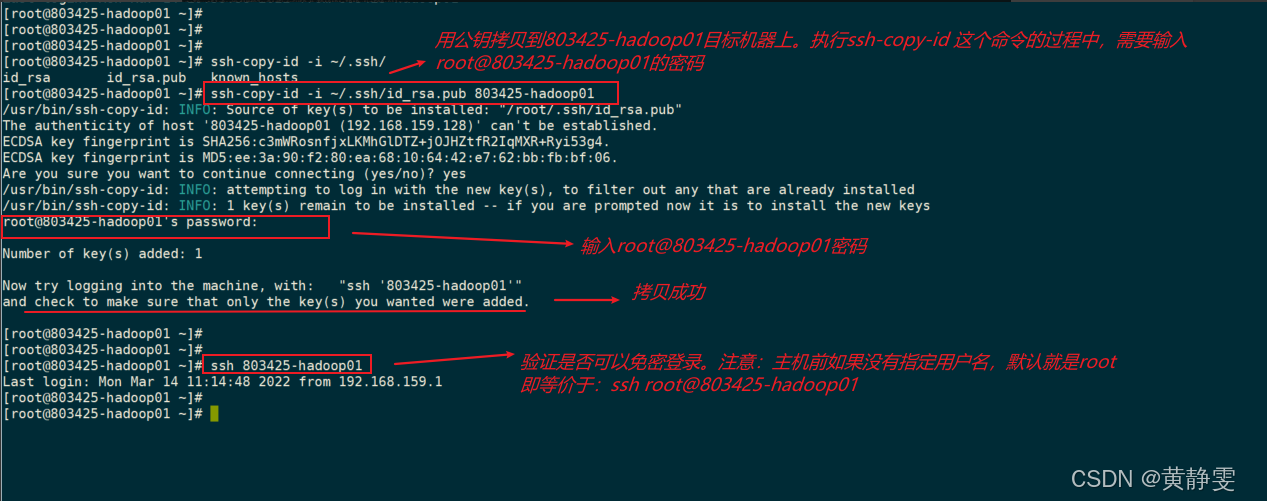
2.将公钥发送到目标机器:例如执行ssh-copy-id -i ~/.ssh/id_rsa.pub 目标机器用户名@目标机器IP命令,过程中需要输入目标机器的密码。
3.验证免密登录:输入ssh 目标机器IP,若无需密码直接登录,则表示免密登录配置成功。
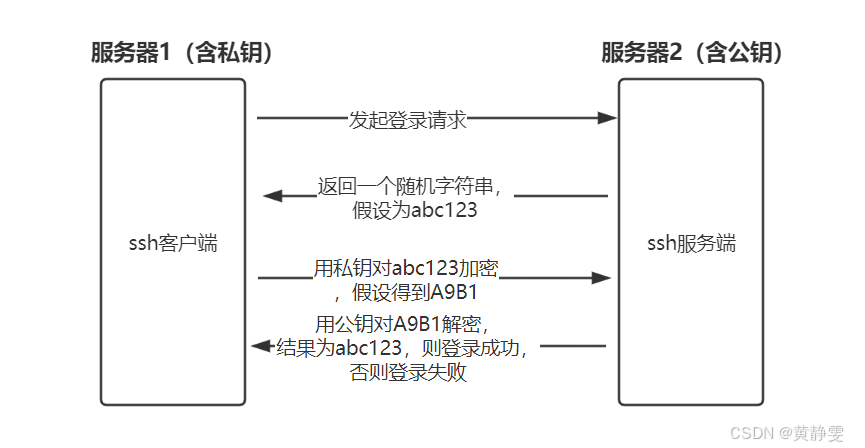
(三)免密登录工作原理
SSH 免密登录的原理很有趣。当发起登录请求时,服务器会返回一个随机字符串,客户端用私钥对该字符串加密后发送给服务端,服务端再用公钥解密。如果解密结果与之前的随机字符串一致,登录就成功啦,否则登录失败。
2、Hadoop 伪分布式安装
(一)上传解压
首先,把 hadoop - 3.1.3.tar.gz 压缩包上传到 Centos7 虚拟机,可以上传到自己指定的路径,比如/usr/local,然后解压这个压缩包。
(二)配置环境变量
1.添加HADOOP_HOME环境变量,其值为解压后的 hadoop 文件夹的绝对路径。
2.将 hadoop 的bin和sbin文件夹的绝对路径添加到PATH环境变量中,这样就能在任何位置方便地执行 hadoop 相关命令了。
(三)修改 Hadoop 的配置文件
Hadoop 的配置文件大多是 xml 格式,用标签来组织内容,用于数据存储和交换。这些配置文件都在$HADOOP_HOME/etc/hadoop路径下。
1.修改 hadoop - env.sh 配置文件:启动 Hadoop 相关进程时会执行这个文件获取JAVA_HOME、HADOOP_HOME等信息,若不一致需手动修改,也可添加source /etc/profile命令。
vi 进去改
vi
/etc/profile
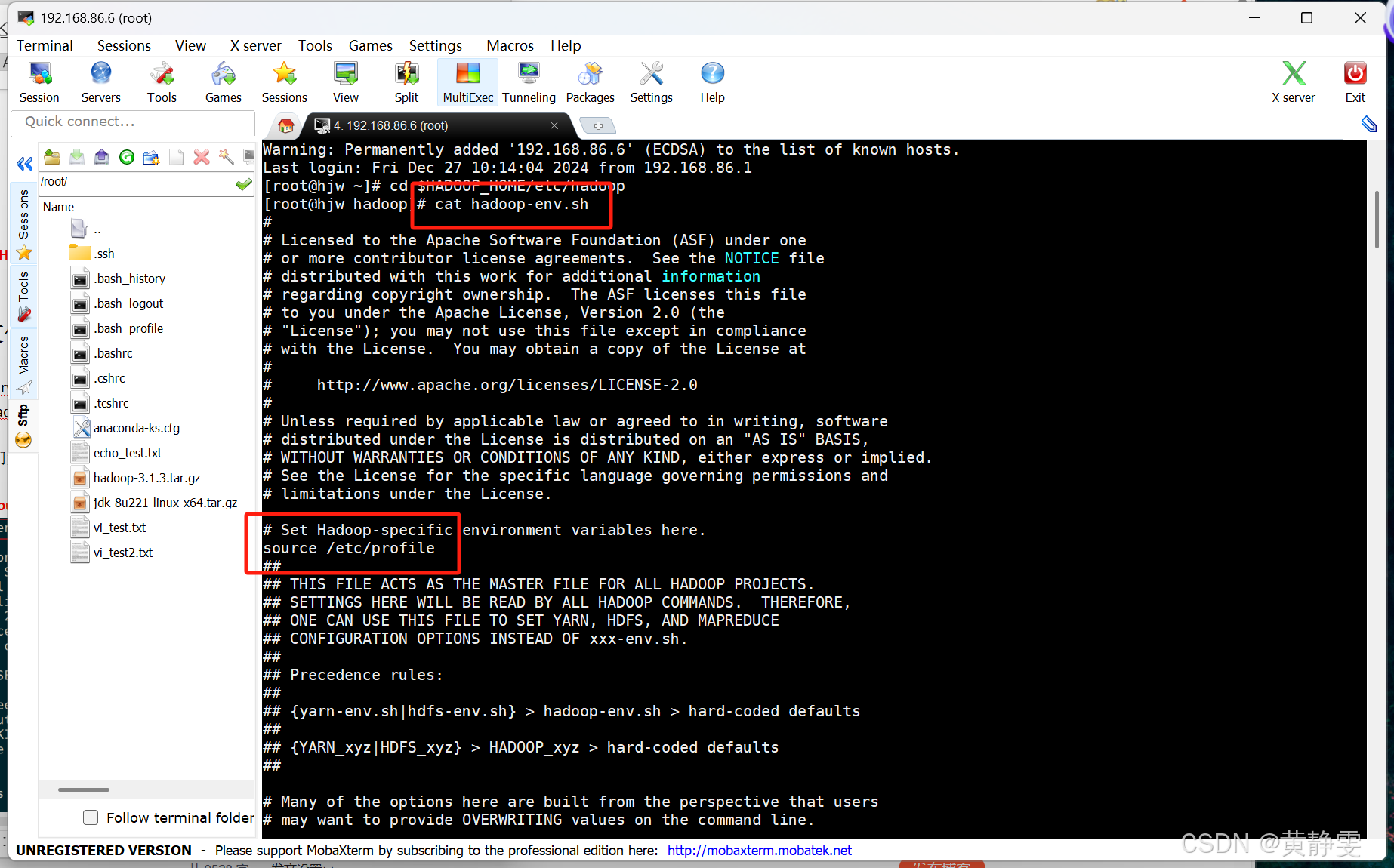
2.修改 core - site.xml 配置文件:这是核心配置文件,主要设置fs.defaultFS(默认文件系统,如hdfs://你的主机名)和hadoop.tmp.dir(Hadoop 临时文件目录,DataNode 默认数据存放位置)。
在最后加
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://你的主机名</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-3.1.3/data</value>
</property>
</configuration>
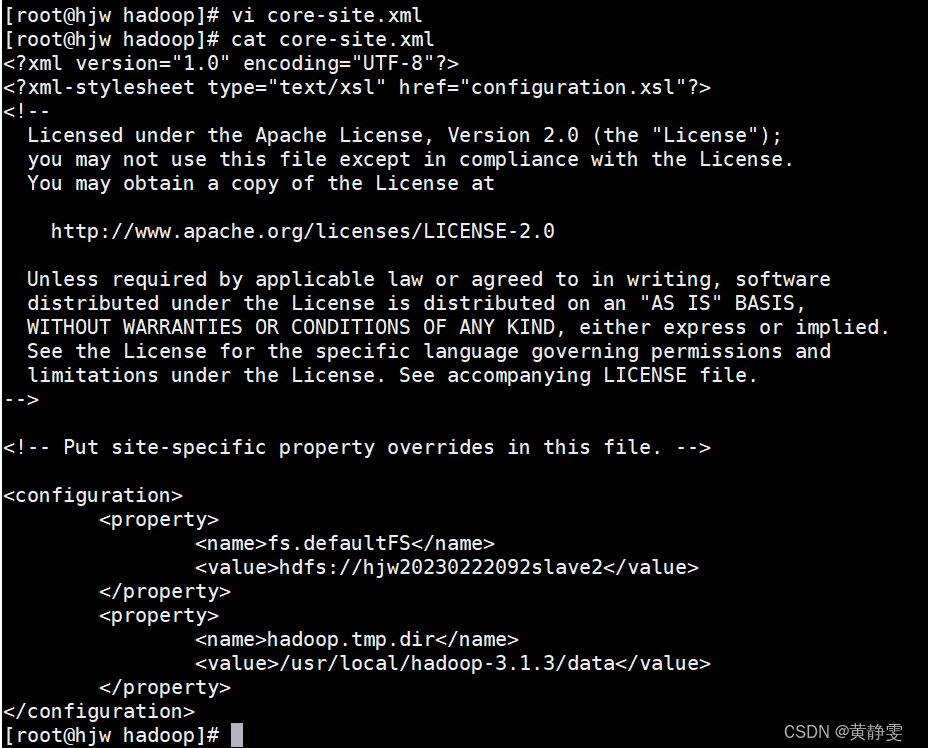
3.修改 yarn - site.xml 配置文件:用于配置 YARN 组件,设置ResourceManager运行的节点,以及开启 mapreduce 的 shuffle 阶段相关服务。
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>主机名</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4.5</value>
</property>
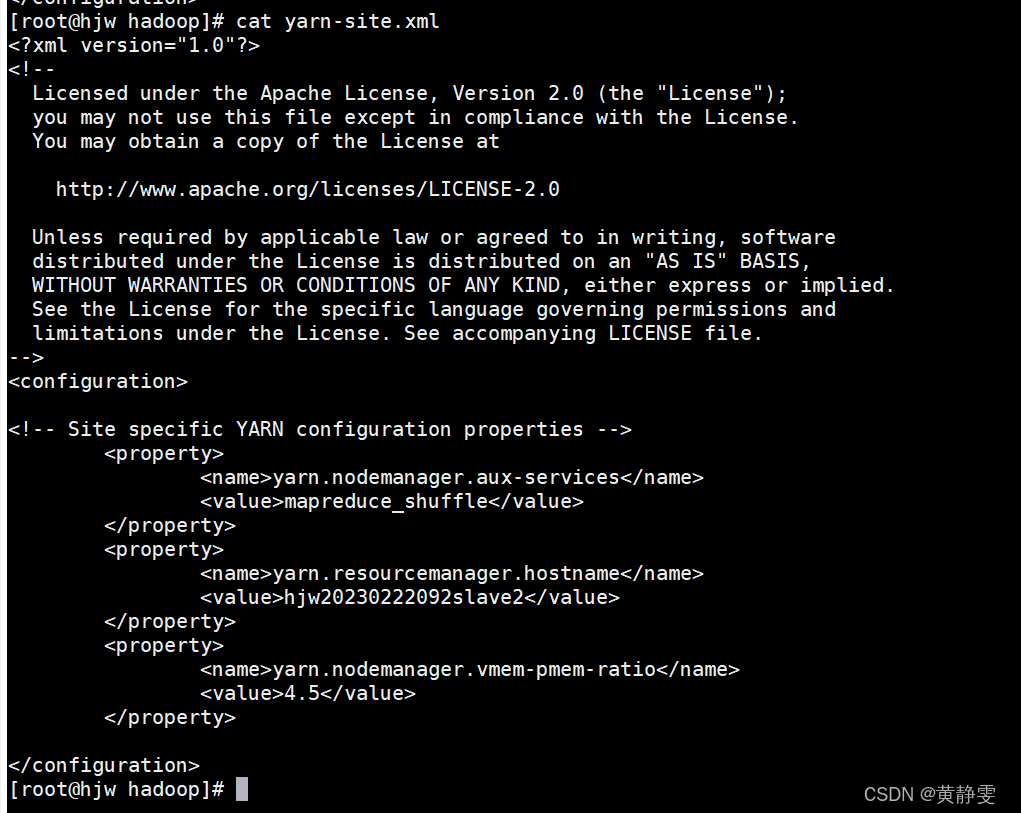
4.修改 mapred - site.xml 配置文件:主要设置 MapReduce 程序运行的位置,默认是local本地运行,修改为在 YARN 集群上运行,才能实现多节点分布式计算。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>
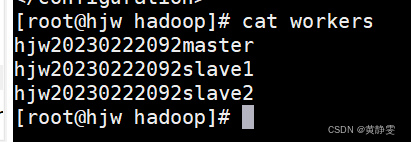
5.修改 workers 配置文件:控制 HDFS 从进程和 YARN 从进程运行的节点,每行写一个节点名,修改后启动 Hadoop 集群,指定节点上就会运行相应从进程。
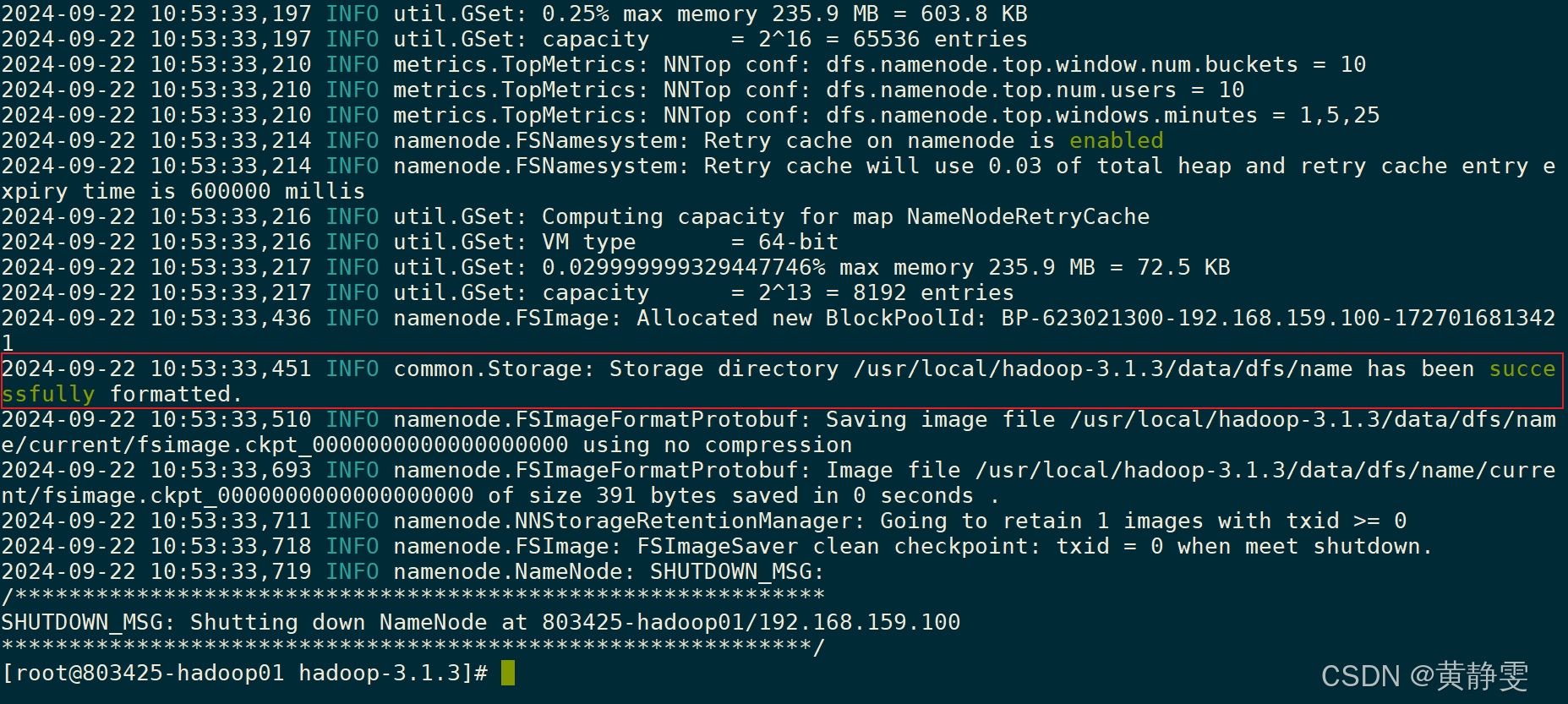
(四)格式化 NameNode
修改完配置文件后,要进行 NameNode 格式化操作,执行hdfs namenode - format命令,成功后会看到特定提示。注意正常情况下只格式化一次,多次格式化会使 HDFS 无法使用。格式化的目的是为首次运行 HDFS 做准备,会在hadoop.tmp.dir指定目录下生成一些文件和目录。
注意: 正常情况下,只需要格式化一次,多次格式化,会导致HDFS无法使用!
1.查看hadoop.tmp.dir指定目录新增内容
1.首先需要确定hadoop.tmp.dir的配置路径。在 Hadoop 的配置文件(通常是core - site.xml)中可以找到这个配置项的值。假设hadoop.tmp.dir配置为/tmp/hadoop - tmp。
2.当执行 NameNode 格式化操作后,在这个目录下会新增一些和 HDFS 元数据相关的目录和文件。例如,会有dfs/name目录,这个目录是用来存储 NameNode 的元数据信息的,包括文件系统的命名空间(如文件和目录的层次结构、文件的块列表等)。里面可能包含current目录,在current目录中有VERSION文件,这个文件记录了 HDFS 的版本信息、集群 ID 等元数据。还可能有fsimage文件和edits文件,fsimage是文件系统的镜像文件,记录了文件系统的元数据的持久化状态,edits文件记录了对文件系统的所有更改操作。
tips:
2.解决因二次 NameNode 格式化导致 HDFS 无法启动的问题(测试环境下)
2.1.原因分析:
当第二次执行 NameNode 格式化操作时,会重新初始化 HDFS 的元数据,原来存储在hadoop.tmp.dir目录下的旧元数据被新的元数据覆盖。这可能导致 DataNode 和 NameNode 之间的元数据不一致,从而使得 HDFS 无法正常启动。
2.2.解决方法:
2.2.1 首先,停止所有 Hadoop 相关服务,包括 NameNode、DataNode 等。可以使用命令stop - all.sh(假设在 Hadoop 安装目录下的sbin目录执行,并且配置了相关环境变量)。
stop-all.sh
2.2.2 然后,删除 DataNode 上存储数据块的目录。这个目录通常也在hadoop.tmp.dir配置的目录下(如果 DataNode 的数据存储目录和 NameNode 的临时目录配置相同),或者在dfs.data.dir配置的目录下。删除这些目录下的所有内容,这一步是为了清除旧的数据块信息,使得 DataNode 和新格式化后的 NameNode 元数据重新同步。
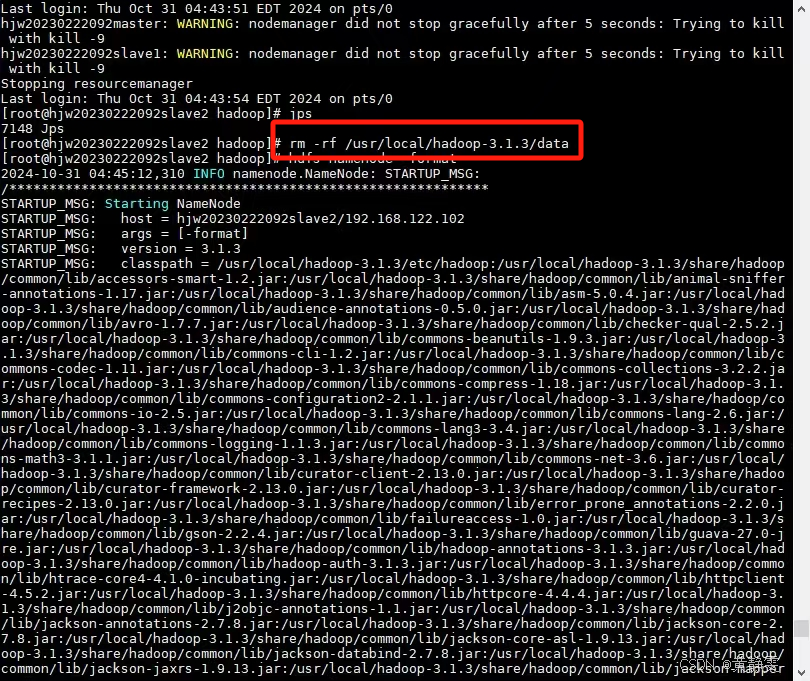
然后再格式化一次
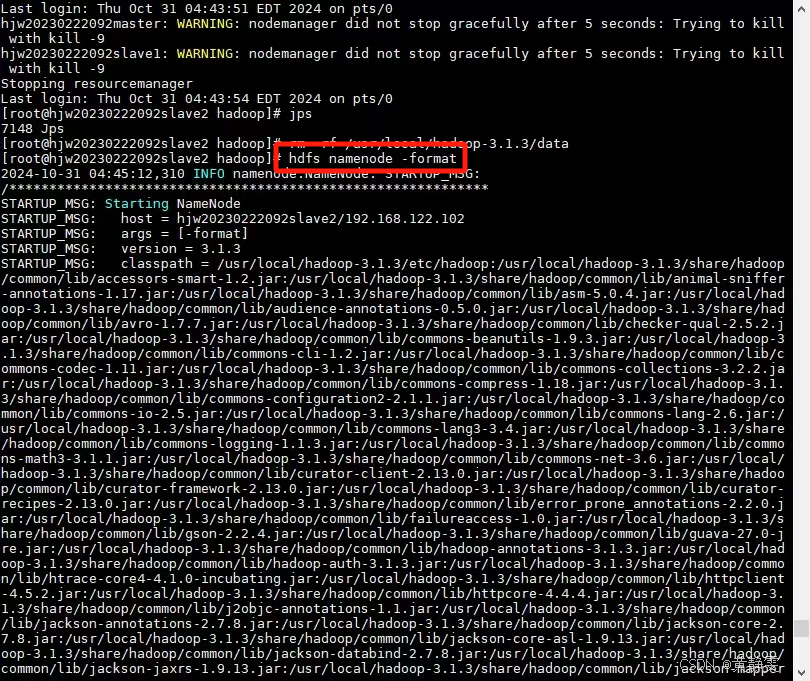
2.2.3 最后,重新启动 Hadoop 服务,使用start-all.sh命令。这样可以让 NameNode 重新分配数据块给 DataNode,重新构建 HDFS 的文件系统。
start-all.sh
3.删除hadoop.tmp.dir指定目录的后果
3.1 如果删除hadoop.tmp.dir指定的目录,会导致 HDFS 无法正常工作。因为这个目录存储了 HDFS 的关键元数据和数据块信息(如果 DataNode 的数据存储目录和它相同)。
3.2 对于 NameNode 来说,丢失了存储在dfs/name目录下的元数据文件(如fsimage和edits文件),会导致无法恢复文件系统的命名空间信息,无法知道文件和目录的层次结构以及文件块的分配情况。
3.3 对于 DataNode 来说,如果数据块存储目录也在hadoop.tmp.dir指定的目录下,那么所有的数据块信息都会丢失。当尝试重新启动 HDFS 时,会出现无法找到元数据和数据块的错误,需要重新格式化 NameNode 并且重新构建整个 HDFS 文件系统才能恢复使用。不过这样会导致之前存储在 HDFS 中的所有数据丢失。
(五)Hadoop 的启动和停止
- 启动 Hadoop(HDFS 和 YARN):使用
start-all.sh命令,启动过程中看到相关进程的启动提示,初步判断启动成功。
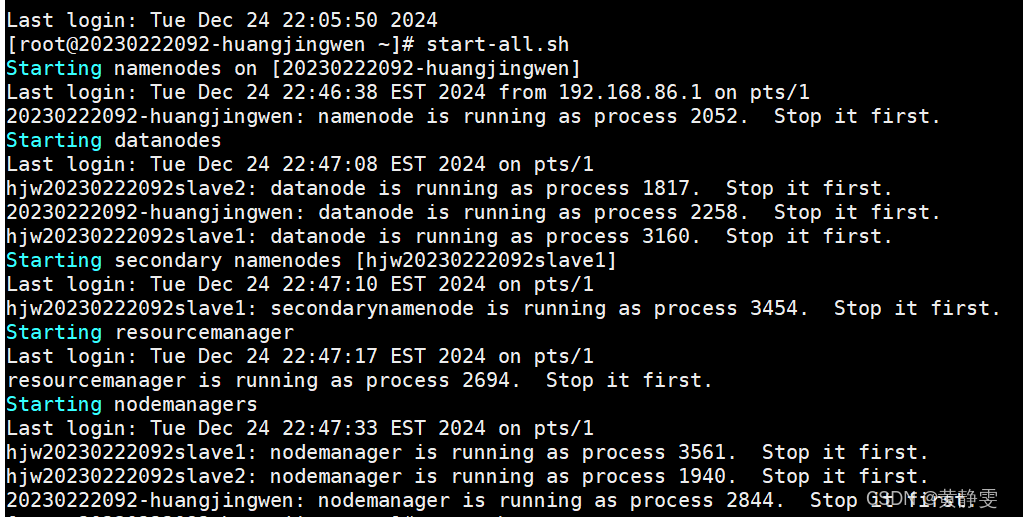
- 停止 Hadoop(HDFS 和 YARN):使用
stop-all.sh命令。
(六)验证是否部署成功
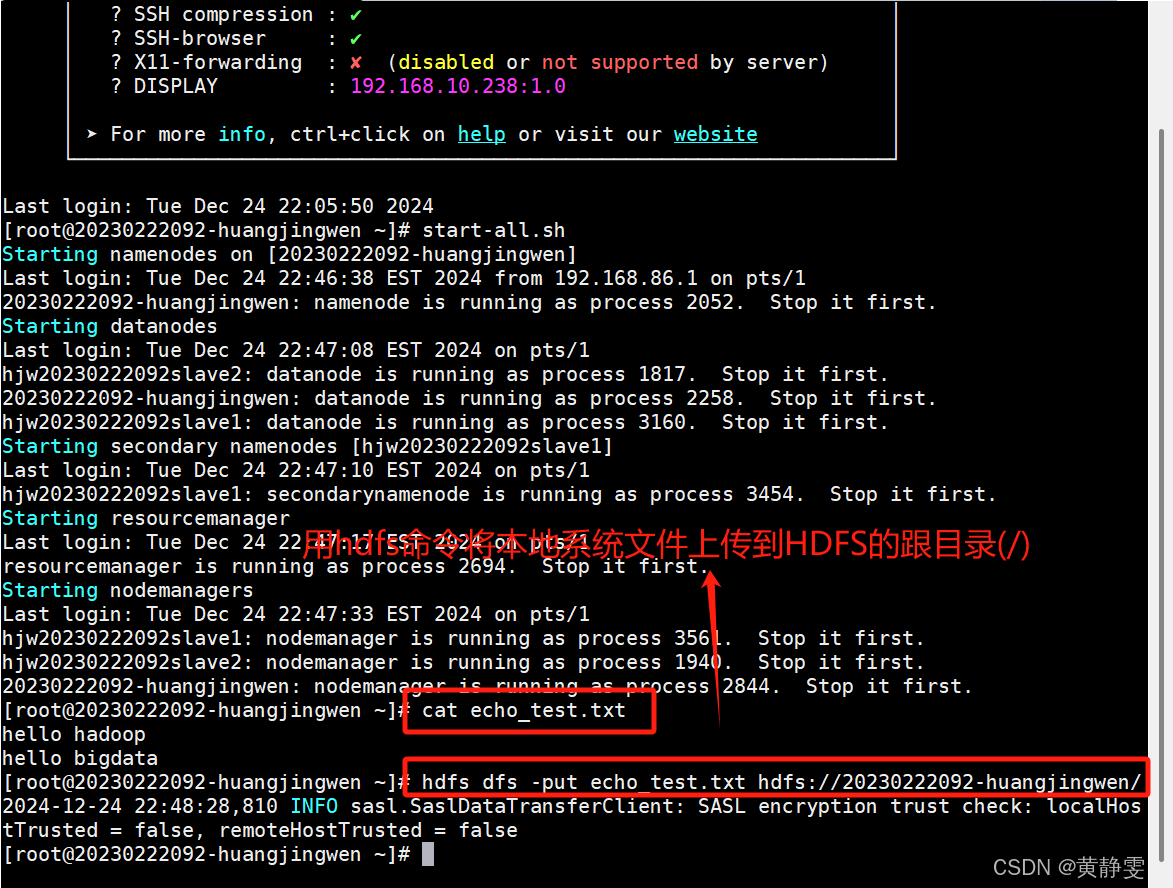
1.查看 Hadoop 守护进程是否运行:通过特定命令查看,如果少了部分进程,说明部署失败,需要具体分析原因。
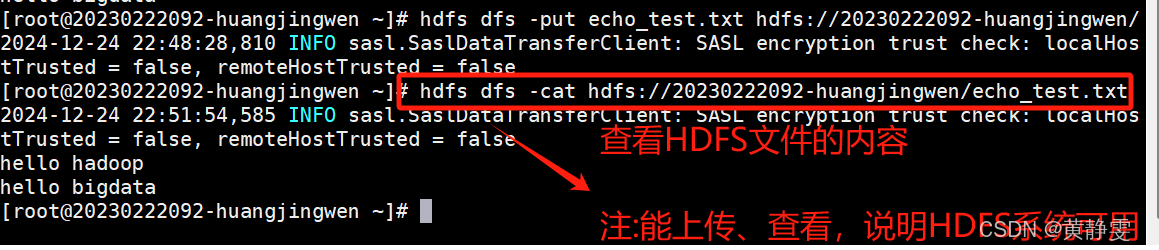
2.验证 HDFS 是否可用:用hdfs dfs -put命令上传本地文件到 HDFS,再用hdfs dfs -cat命令查看文件内容,能上传和查看说明 HDFS 可用。
思考:怎么查看Hadoop相关进程是否在运行??
如果进程都在,接下来要验证HDFS和YARN是否可以正常使用,两者都可用,则Hadoop部署成功
HDFS可正常使用:
3.验证 YARN 是否可用:执行hadoop jar hadoop-mapreduce-examples-3.1.3.jar wordcount命令提交 MapReduce 任务统计单词数量,任务成功运行且结果正确,说明 YARN 可以正常运行 MapReduce。
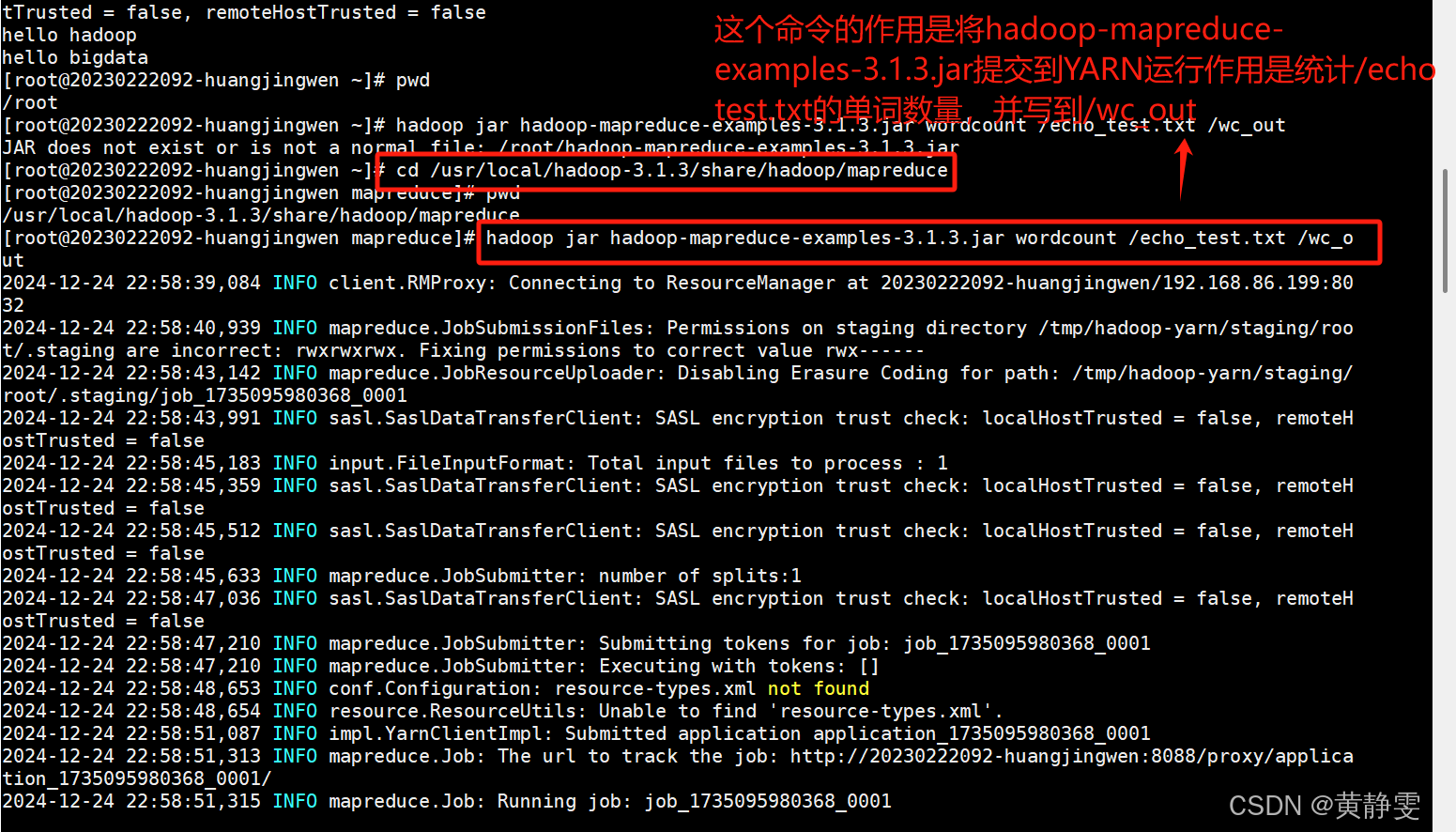
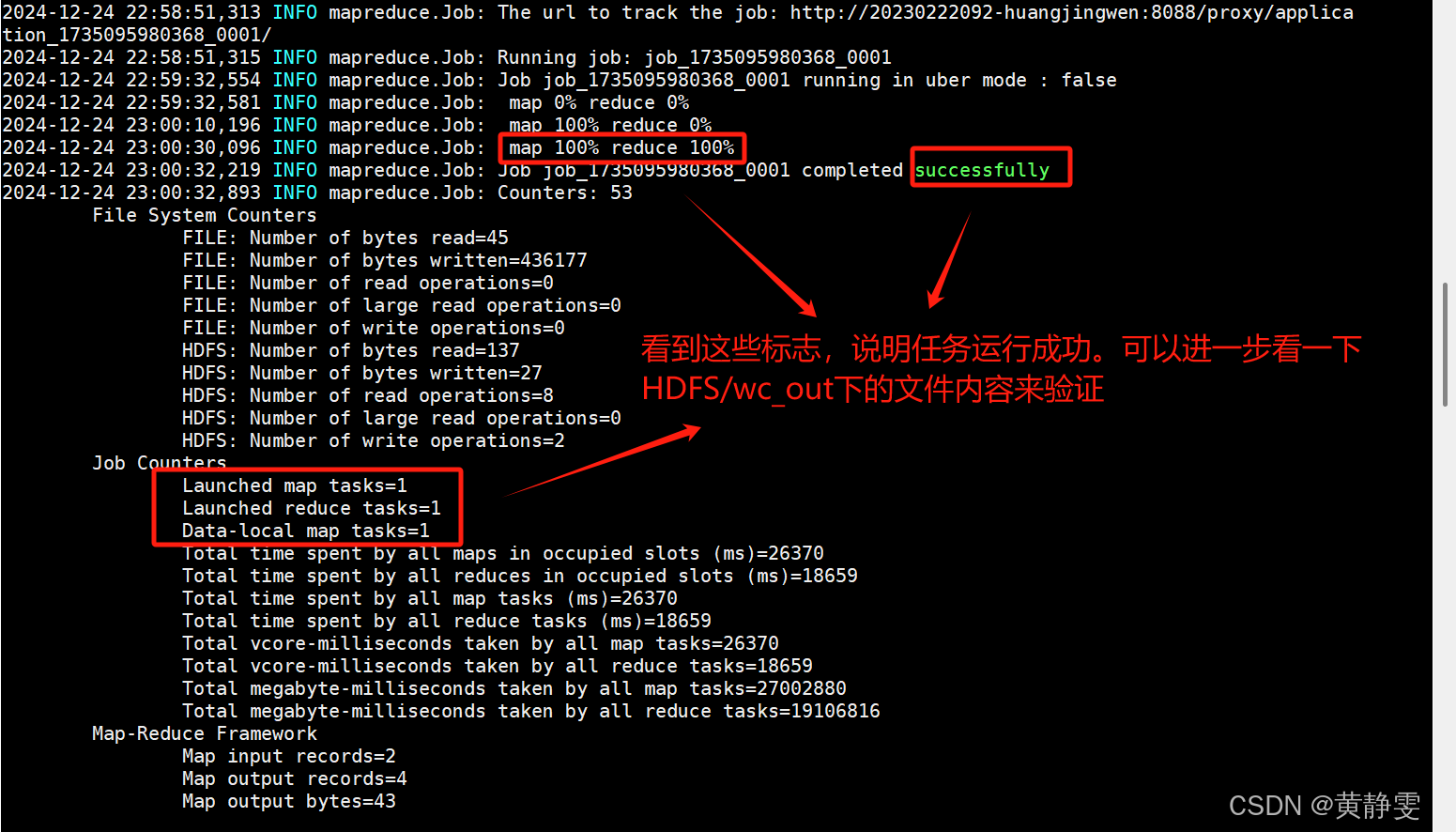
 (七)常见问题解决
(七)常见问题解决
1.启动报错:如果启动时报错ERROR: Attempting to operate on hdfs namenode as root等类似错误,解决办法是添加环境变量,如export HDFS_NAMENODE_USER=root等。
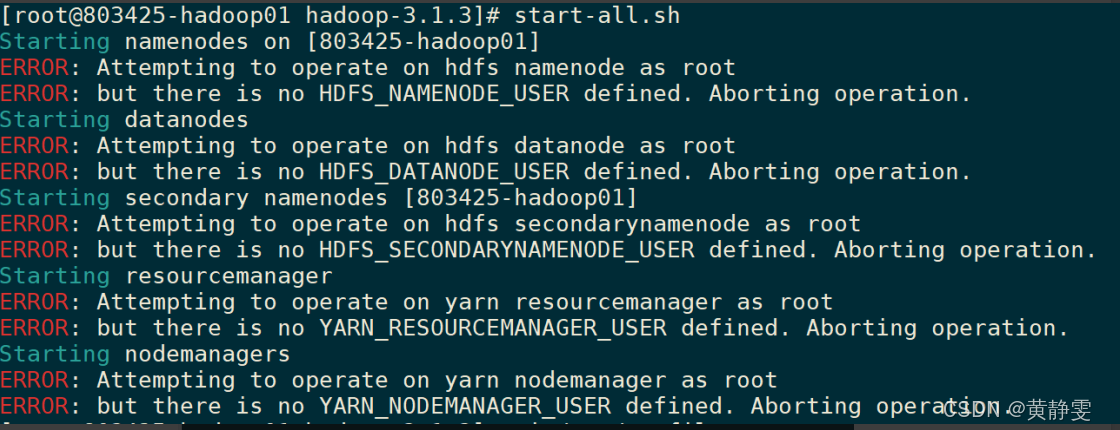
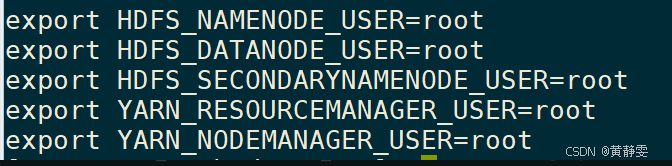
解决:添加环境变量,内容如下:
2.运行 MapReduce 的 wordcount 例子报错:如果错误信息是Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster,就在mapred - site.xml添加相关属性。
解决:在mapred-site.xml添加以下属性:
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
3.运行 MapReduce 的 wordcount 例子报错 2:若报错Diagnostics: Container [pid = 13832, containeriD = container 1632283661222 0002 02 000001] is running beyond virtual memory Limits,就在yarn - site.xml添加属性并重启 Hadoop 集群或 yarn 进程。

解决:yarn-site.xml添加以下属性,然后重启Hadoop集群或者yarn进程
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4.5</value>
</property>
说明见:https://blog.csdn.net/qq_39327985/article/details/86515307
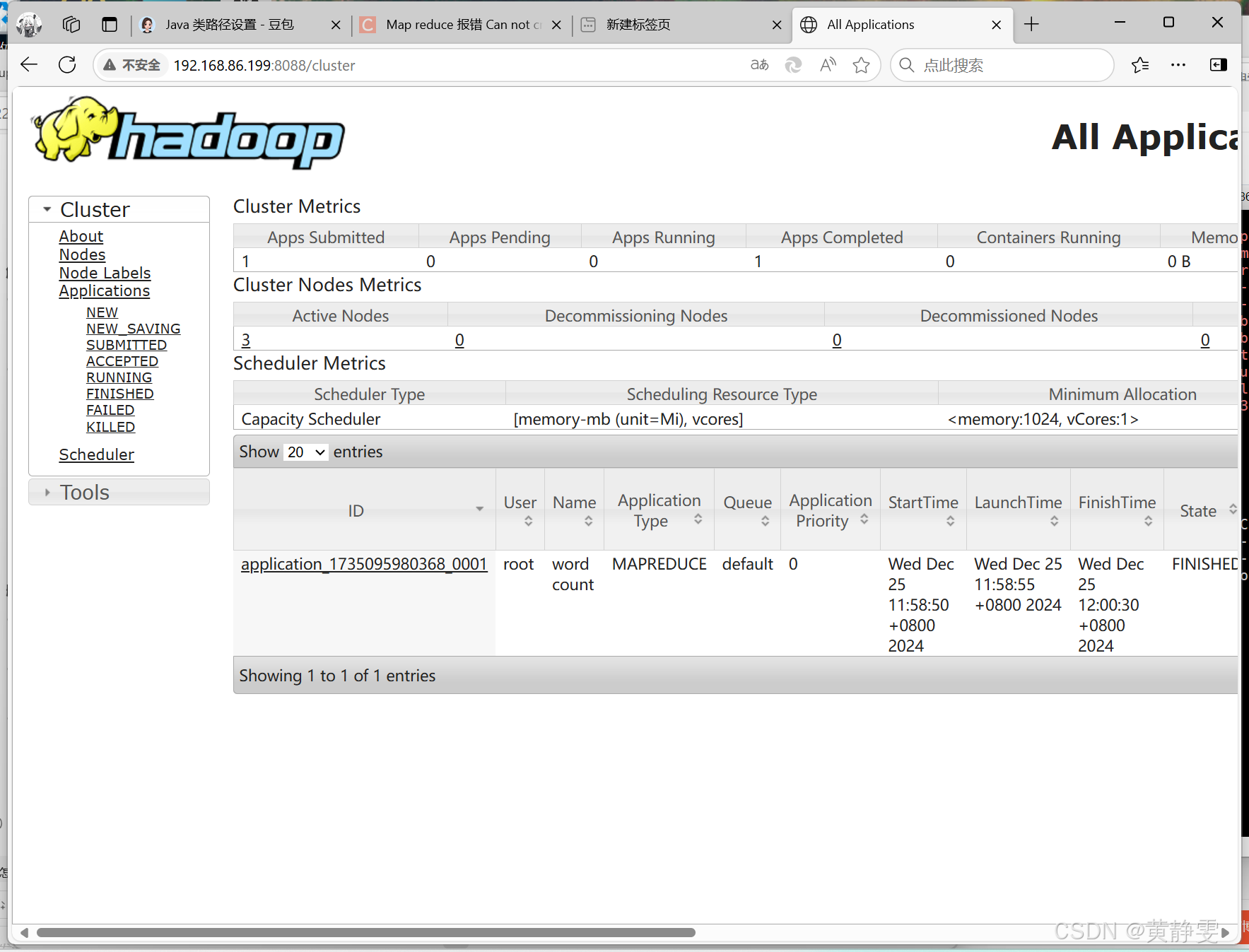
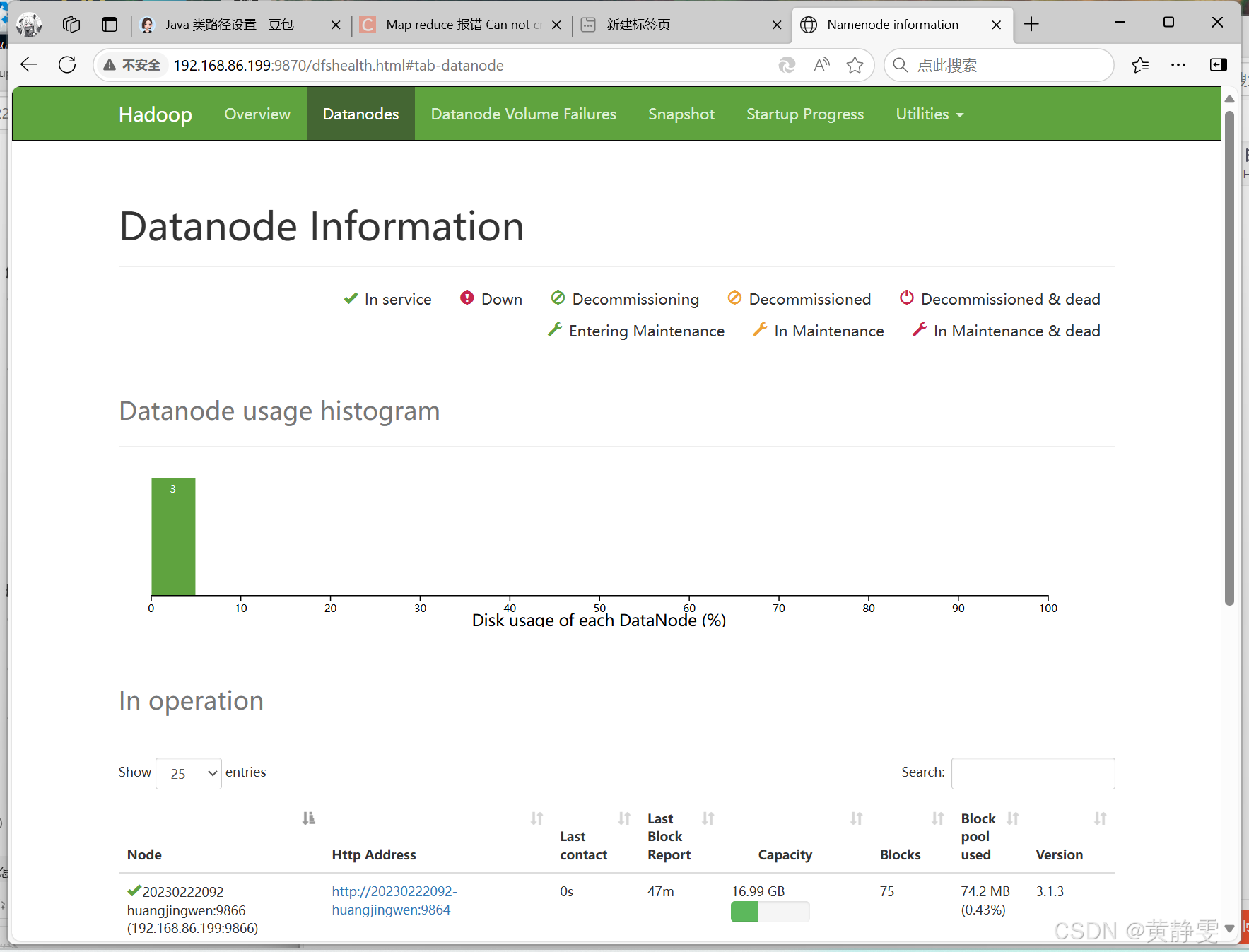
3、查看 HDFS 和 YARN 管理页面
HDFS 的 NameNode 进程 web 端口是 9870,YARN 的 web 端口是 8088,我们可以用浏览器访问这两个管理页面,查看各自提供的信息,比如 HDFS 管理页面可以查看文件系统的状态、节点信息等,YARN 管理页面可以查看任务执行情况、资源分配等。
通过以上步骤,我们详细学习了 Hadoop 伪分布式部署的全过程,包括 SSH 免密登录配置、Hadoop 的安装、配置、启动、验证以及常见问题解决,还了解了如何查看 HDFS 和 YARN 的管理页面。希望大家在实际操作中不断积累经验,更好地掌握 Hadoop 技术,为处理大数据奠定坚实基础。如果在操作过程中有任何疑问,欢迎随时交流。
四、Hadoop 完全分布式安装教程
在大数据处理领域,Hadoop 的完全分布式安装是构建高效数据处理集群的关键一步。本教程将详细介绍 Hadoop 完全分布式安装的全过程,帮助读者掌握这一重要技术。
1、完全分布式安装概述
在生产环境中,Hadoop 通常采用完全分布式安装,即集群部署。Hadoop 具有典型的主从架构,HDFS 的 NameNode 是主节点,DataNode 是从节点;YARN 的 ResourceManager 是主节点,NodeManager 是从节点。在正式部署前,做好规划至关重要,它不仅能指导安装过程,避免失误导致集群启动失败,还方便日后查询进程运行情况。
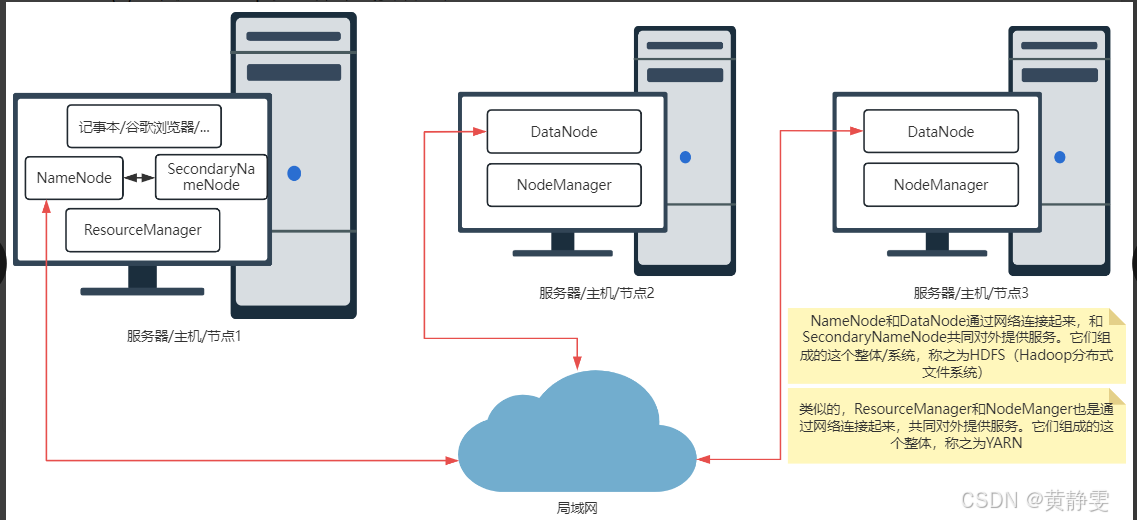
(一)Hadoop 集群规划
以本次部署为例,规划如下(请根据实际虚拟机修改 IP 地址):
| 主机 IP | 主机名(自定义) | HDFS | YARN |
|---|---|---|---|
| 192.168.159.100 | master | NameNode、DataNode | ResourceManager、NodeManager |
| 192.168.159.101 | slave1 | SecondaryNameNode、DataNode | NodeManager |
| 192.168.159.102 | slave2 | DataNode | NodeManager |
2、安装前准备
(一)准备虚拟机
基于之前已安装 Hadoop 伪分布式的虚拟机进行操作。找到其路径,创建三个文件夹(master、slave1、slave2),将原虚拟机文件分别复制到这三个文件夹中。然后用 vmware 打开这三个文件夹下的虚拟机并分别重命名。
找到之前安装hadoop的虚拟机的路径:
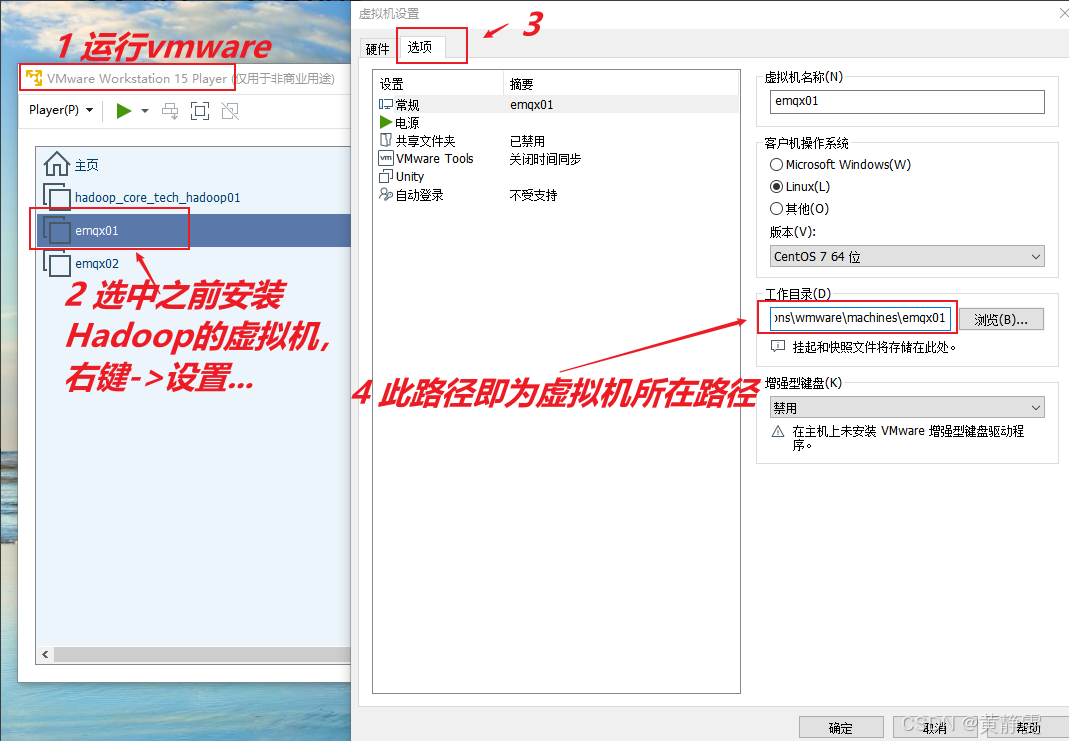
创建三个文件夹,然后复制步骤1中找到的虚拟机文件,并分别粘贴一份到这三个文件夹中:

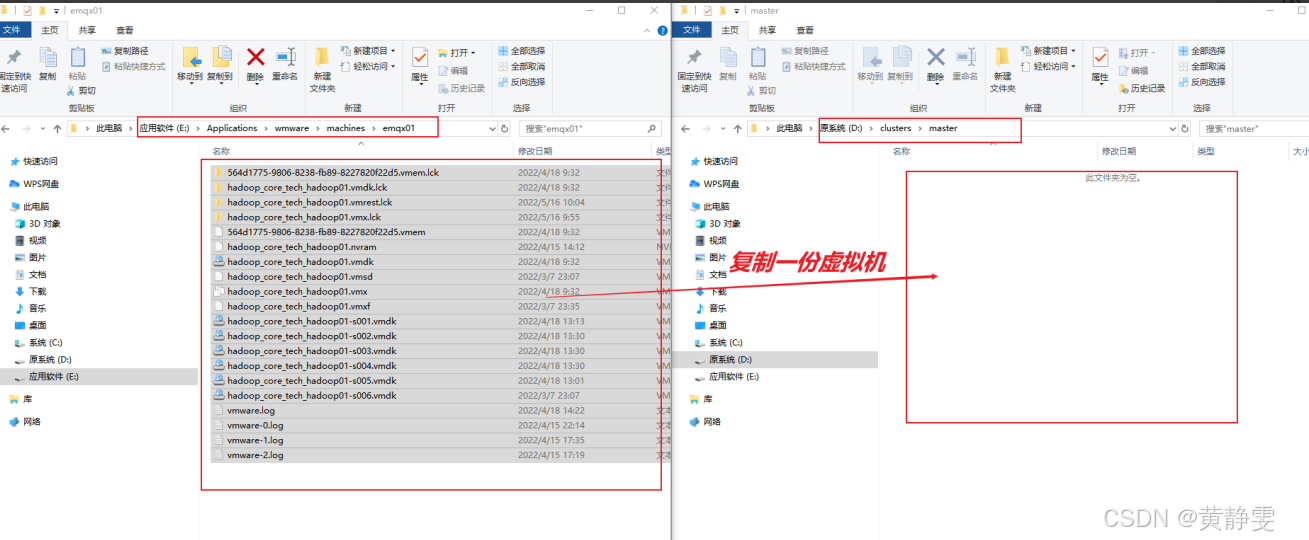
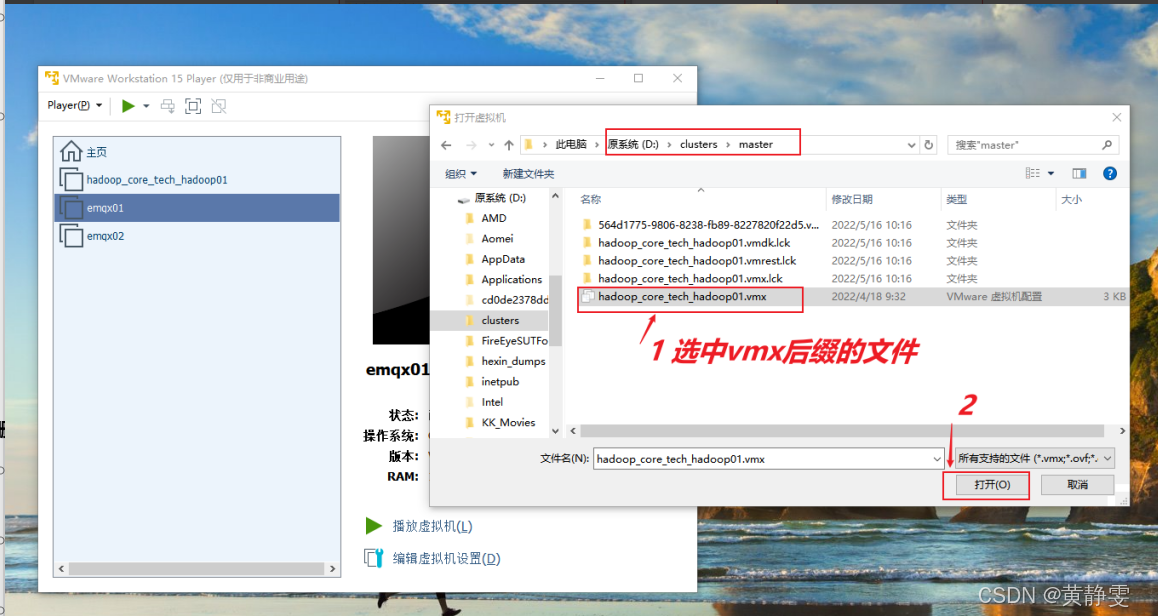
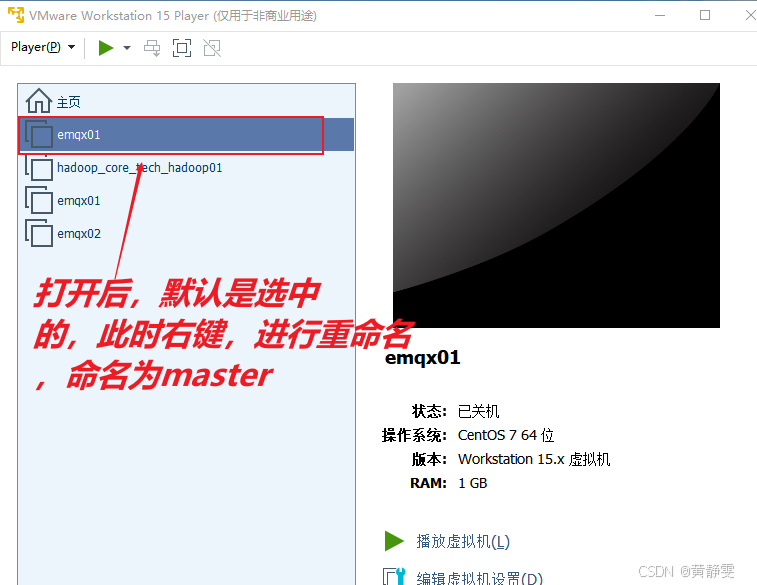
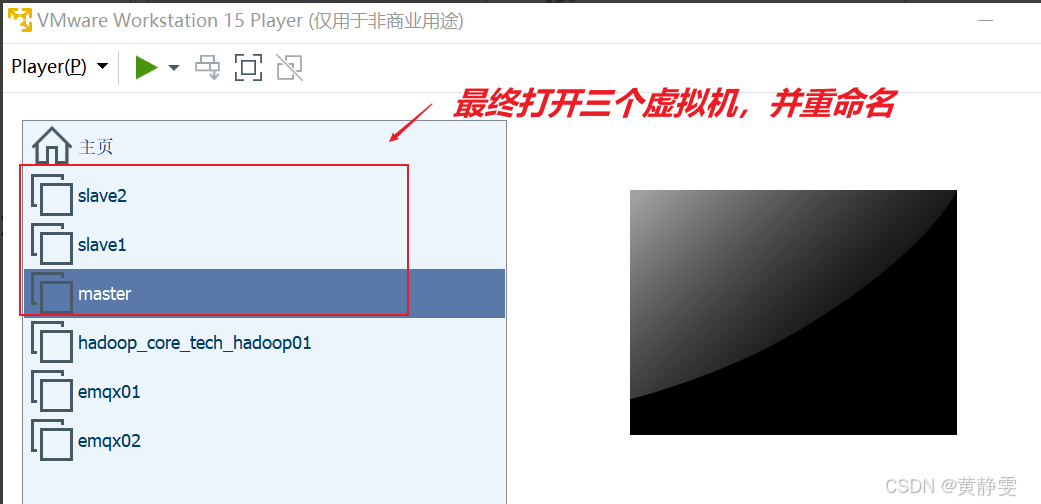
用vmware打开master、slave1、slave2文件夹下的虚拟机,并重命名
以打开master为例。首先Player -> 文件 -> 打开... 弹出一个对话框,然后在对话框中,选中要打开的虚拟机,最后将虚拟机进行重命名。
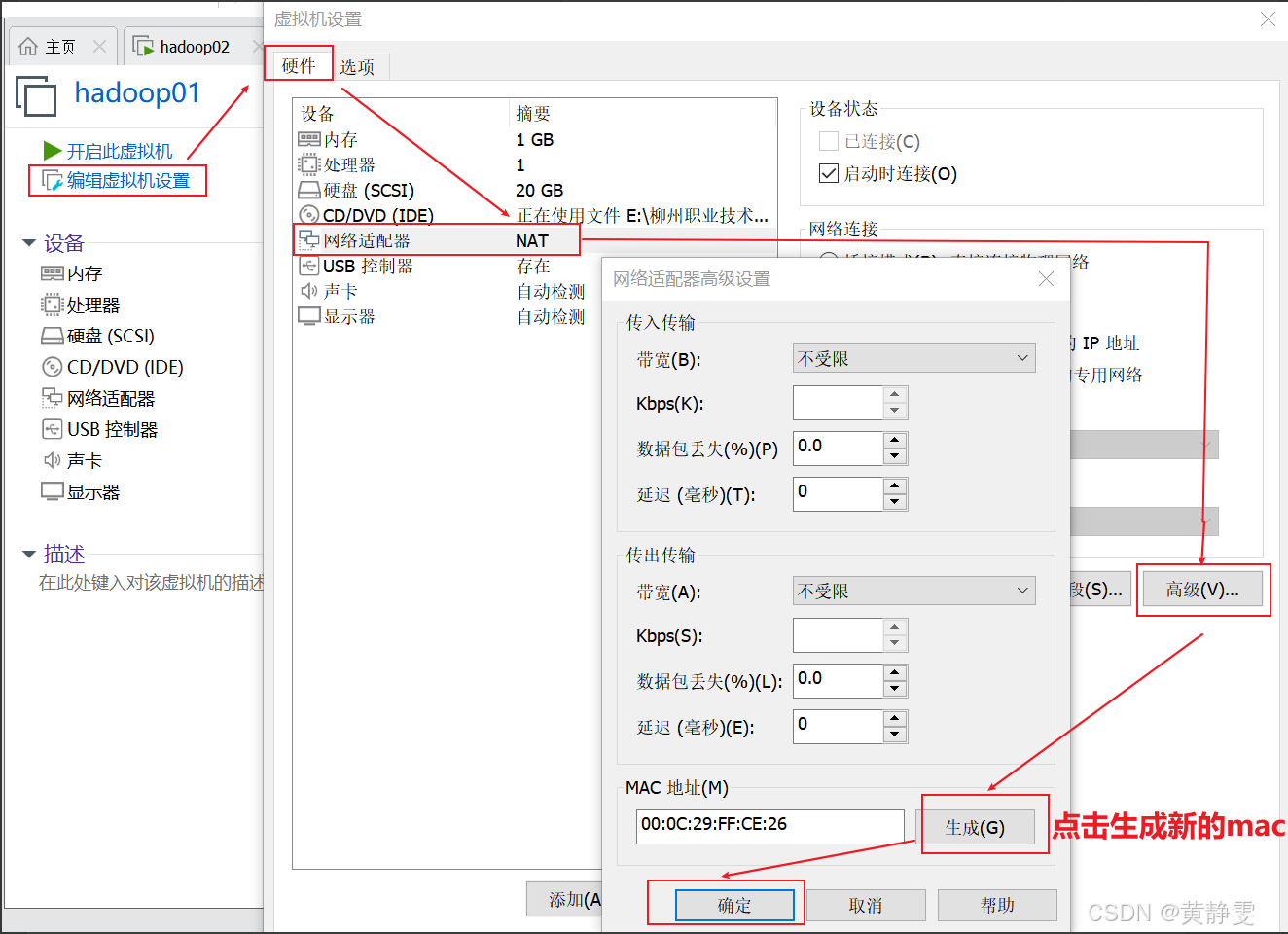
(二)修改 MAC 地址
为避免 MAC 地址冲突导致通信问题,需修改三台虚拟机的 MAC 地址(注意修改前关闭虚拟机)。
(三)修改 IP 和主机名
由于虚拟机是拷贝而来,IP 和主机名相同,需进行修改。以 master 为例,运行虚拟机,打开网卡配置文件,将 IPADDR 修改为规划中的 IP,保存退出后重启网卡,确认能访问外网,再执行hostnamectl set-hostname master命令修改主机名,退出 root 并重新登录即可看到新主机名。slave1 和 slave2 的修改过程类似。
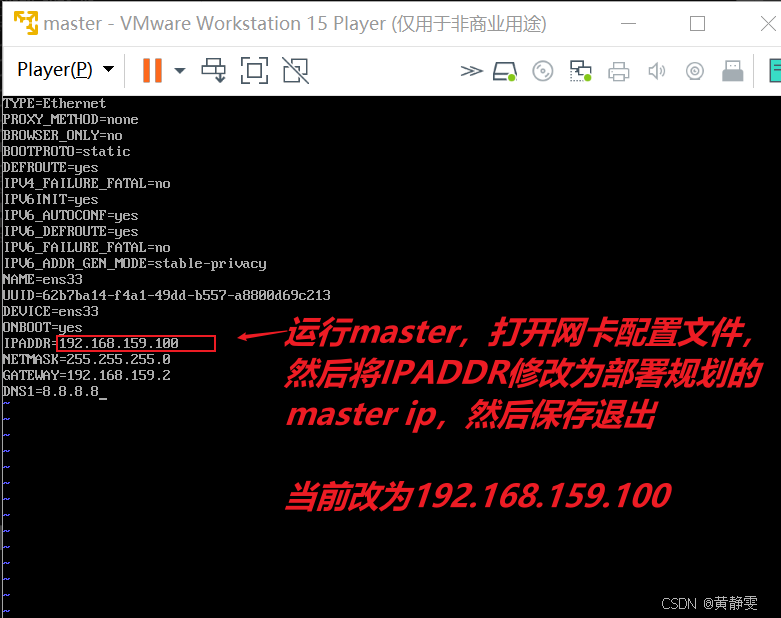
1、ip修改后,重启网卡:systemctl restart network
systemctl restart network
2、ping www.baidu.com确认访问外网没有问题
ping www.baidu.com
3、执ihostnamectlset-hostname master将主机名改为master
4、退出root,再重新登录,命令行提示符着型最新的主机名
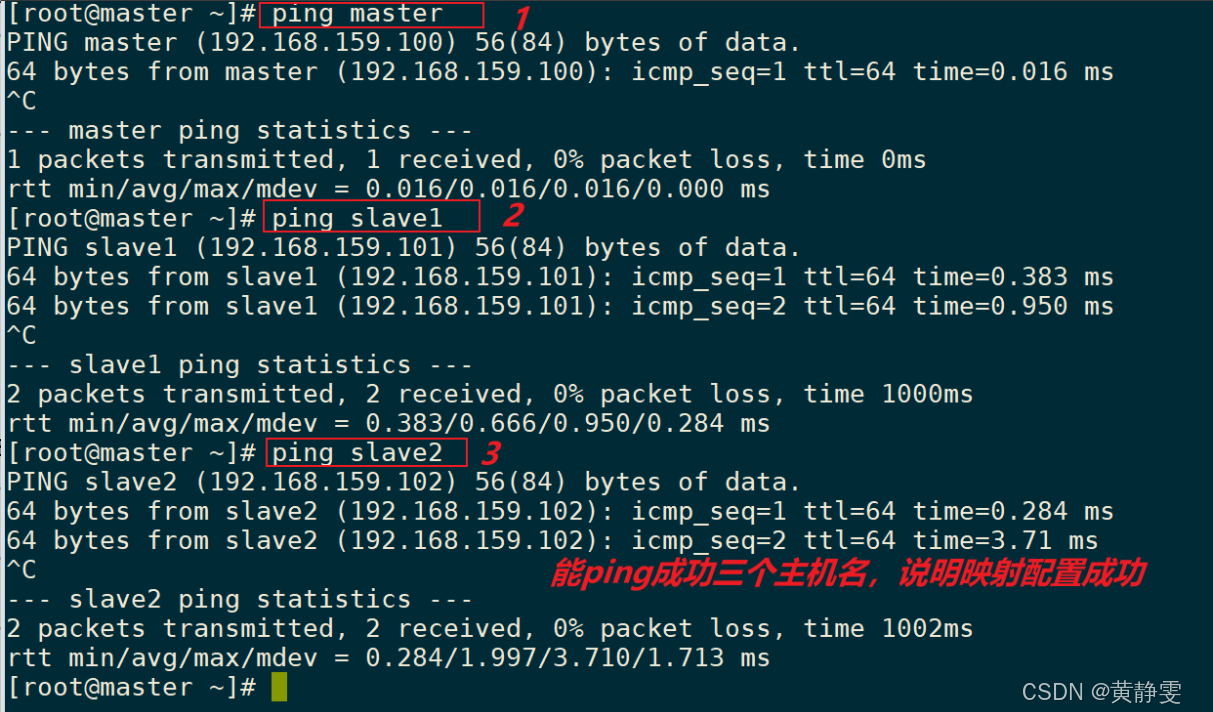
(四)修改主机名和 IP 的映射
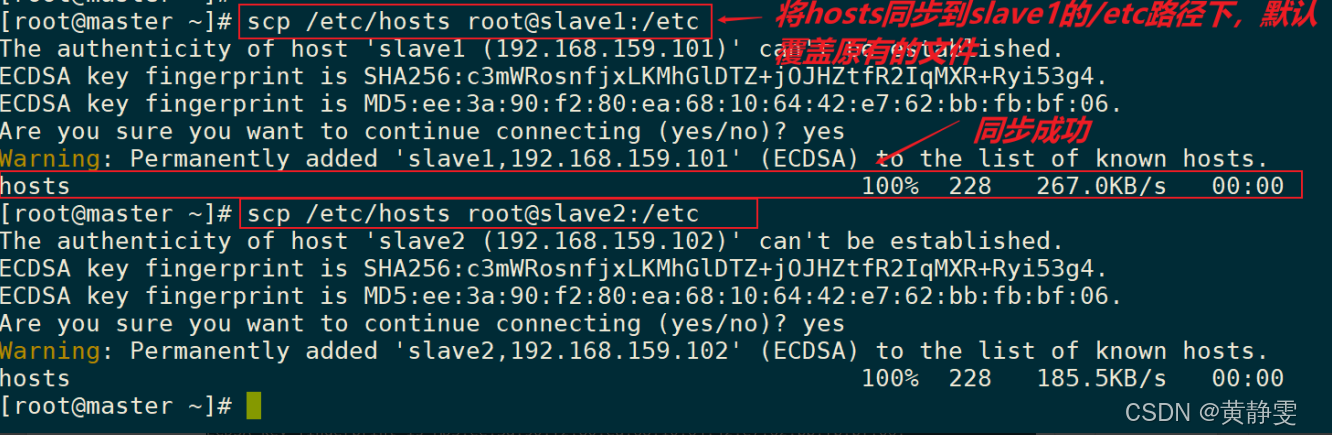
在 master、slave1、slave2 的/etc/hosts文件中新增映射记录,确保三台主机能相互 ping 通。为避免手写错误,可在 master 配置好后,使用scp命令将/etc/hosts文件同步到 slave1 和 slave2。
vi
/etc/hosts

提示:为了避免手写错误,master的hosts映射配置好后,可以通过scp命令,将master修改好的/etc/hosts文件,同步到slave1、slave2主机上。
(五)设置免密登录和关闭防火墙
由于虚拟机是从已设置好的环境复制而来,之前已设置免密登录和关闭防火墙开机自启,故这两步无需重复操作。但需注意,master 可免密登录到 master、slave1、slave2。
(六)删除 Hadoop 伪分布式数据
为保证环境干净,需删除三个节点 HDFS 数据路径(思考:之前配置的 HDFS 数据存放路径在哪?看哪个配置文件可知?用什么命令删除?)。
一、解决思路:
- 查找 HDFS 数据存放路径:
- HDFS 的数据存放路径通常在
hdfs-site.xml配置文件中进行配置。 - 查找
dfs.datanode.data.dir属性,它指定了 DataNode 存储数据块的位置。 - 查找
dfs.namenode.name.dir属性,它指定了 NameNode 存储元数据的位置。
- HDFS 的数据存放路径通常在
- 删除数据路径:
- 对于找到的数据路径,可以使用
rm -rf命令删除,但需要注意的是,这是一个非常危险的操作,因为它会永久性删除数据,因此在操作前请确保你已经备份了重要数据或确定要删除的数据是可删除的。
- 对于找到的数据路径,可以使用
二、具体步骤:
- 查看 HDFS 配置文件:
- 打开
hdfs-site.xml文件,通常位于 Hadoop 的配置目录中,例如/etc/hadoop/hdfs-site.xml或$HADOOP_HOME/etc/hadoop/hdfs-site.xml。 - 查找
dfs.datanode.data.dir和dfs.namenode.name.dir属性,如下是一个hdfs-site.xml的示例:
- 打开
<configuration>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hdfs/name</value>
</property>
</configuration>
- 在上述示例中,DataNode 的数据存储在
/hdfs/data目录,NameNode 的元数据存储在/hdfs/name目录。
- 删除数据路径:
- 对于每个节点,使用
rm -rf命令删除数据目录,但请谨慎操作,因为这是一个不可逆的操作。假设 DataNode 的数据目录是/hdfs/data,NameNode 的元数据目录是/hdfs/name,执行以下命令:
- 对于每个节点,使用
rm -rf /hdfs/data
rm -rf /hdfs/name
- 你需要在每个节点上执行上述命令,因为你提到要删除三个节点的数据路径。
三、注意事项:
- 备份重要数据:
- 在执行删除操作前,请务必备份重要数据,以免数据丢失。
- 可以使用
cp -r命令将数据复制到其他位置,例如:
cp -r /hdfs/data /backup/hdfs_data_backup
cp -r /hdfs/name /backup/hdfs_name_backup
- 确保集群停止:
- 在删除数据之前,确保 Hadoop 集群已完全停止,避免删除过程中数据损坏或其他异常。可以使用以下命令停止集群:
stop-dfs.sh
stop-yarn.sh
四、总结:
- 首先在
hdfs-site.xml配置文件中查找dfs.datanode.data.dir和dfs.namenode.name.dir属性,确定数据存放路径。 - 备份重要数据,使用
cp -r命令将数据复制到其他位置。 - 确保集群已停止,使用
stop-dfs.sh和stop-yarn.sh命令。 - 使用
rm -rf命令删除数据路径,但要谨慎操作,因为这是不可逆的。
通过以上步骤,可以清理 HDFS 数据路径,为保证环境干净提供基础,但请谨慎操作,避免数据丢失。
3、安装过程
(一)修改 master 主机上的 hadoop 配置文件
1.hadoop - env.sh:若之前未添加source /etc/profile,则添加该命令。
2.core - site.xml:设置fs.defaultFS为hdfs://master,hadoop.tmp.dir为/usr/local/hadoop - 3.1.3/data。
core-site.xml配置文件的内容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-3.1.3/data</value>
</property>
</configuration>
3.hdfs - site.xml:设置dfs.replication为3,dfs.secondary.http.address为slave1:50090。
hdfs-site.xml配置文件的内容
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.secondary.http.address</name>
<value>slave1:50090</value>
</property>
</configuration>
4.yarn - site.xml:设置yarn.nodemanager.aux - services为mapreduce_shuffle,yarn.resourcemanager.hostname为master,yarn.nodemanager.vmem - pmem - ratio为4.5。
yarn-site.xml配置文件的内容
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4.5</value>
</property>
</configuration>
5.mapred - site.xml:设置mapreduce.framework.name为yarn,并添加相关环境变量配置。
mapred-site.xml配置文件的内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>
6.workers:填写master、slave1、slave2。
master
slave1
slave2
(二)同步配置文件
将 master 主机上修改好的 hadoop 配置文件同步到 slave1 和 slave2 上。使用scp命令,例如在 master 上执行scp./* slave1:pwd(将当前路径下所有文件同步到 slave1 的当前路径下,需自行完成 slave2 的同步)。

1.scp第一个参数*表示当前路径下的所有文件第二个参数冒号左边表示目标主机,冒号右边表示目标生机的路径。pwd打印出当前路径。
2.整句命令的作用是将当前路径下的所有文件,以root身份同步到slave1的pwd输出的路径下
(三)时间同步
hadoop集群各个节点之间的时间应该一致,也就是master当前时间如果是2022-01-01 01:01:01,那么slave1和slave2上也应该是这个时间。如果各个节点之间时间不一致/不同步,那么集群就会一些错误。
ntp(Network Time Protocol,网络时间协议)是一种跟时间设置相关的协议。客户端-服务端架构。
ntp.aliyun.com是阿里云一个公网ntp服务器,执行ntpdate ntp.aliyun.com命令,可以从这个ntp服务器拉取时间并更新当前机器的时间。在master、slave1、slave2上分别执行该命令,即可完成时间同步,此时三个节点的时间是一致的。(最好设置定时任务,每隔一段时间同步下时间)
执行ntpdate ntp.aliyun.com命令,在 master、slave1、slave2 上分别执行,确保各节点时间一致(建议设置定时任务定期同步)。
(四)NameNode 格式化
在 master 上执行hdfs namenode-format命令,只需格式化一次,以后启动集群无需再次格式化。
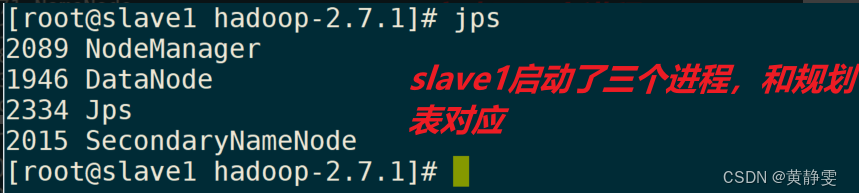
(五)启动 Hadoop 集群
在 master 上执行start-all.sh命令启动集群,然后通过jps命令查看各节点启动的进程是否与规划表对应。


4、安装后验证
查看 HDFS 的 web 管理页面,确认是否有 3 个 DataNode 节点;查看 YARN 的 web 管理页面,确认是否有 3 个 NodeManager。
通过以上步骤,我们完成了 Hadoop 完全分布式安装。在实际操作中,需仔细检查每一步,确保集群正常运行。希望本教程能帮助大家顺利构建 Hadoop 集群,开启大数据处理之旅。如有疑问,欢迎交流。
五、Hadoop 分布式文件系统(HDFS):原理、架构与实践
在大数据时代,如何高效存储和管理海量数据成为了一个关键问题。Hadoop 分布式文件系统(HDFS)应运而生,它为大规模数据存储提供了可靠、高可用的解决方案。本文将详细介绍 HDFS 的本质、架构、核心概念、数据副本恢复流程以及常用命令,帮助读者全面了解和掌握这一强大的分布式文件系统。
(一)HDFS 的本质
HDFS 是 Hadoop 生态系统中的核心组件之一,它的主要功能是存储海量数据。与传统文件系统不同,HDFS 采用分布式架构,能够在多个节点上并行存储和处理数据,从而实现高可靠性和高扩展性。HDFS 以树状目录结构来组织文件,类似于 Linux 文件系统,用户可以方便地对文件进行操作和管理。
(二)HDFS 解决的核心问题
(1)存储海量离线数据
HDFS 能够轻松应对 TB、PB 甚至 ZB 级别的海量数据存储需求。通过将数据分布存储在多个节点上,它可以充分利用集群的存储资源,提供大规模的数据存储能力。
(2)保证数据高可用
数据的高可用性是 HDFS 的重要特性之一。它通过数据副本机制,将每个数据块复制多份存储在不同的节点上。当某个节点出现故障时,系统可以自动从其他副本中恢复数据,确保数据不会丢失,从而保证了数据的高可用性。
(3)支持高并发访问
在大数据应用场景中,常常需要对数据进行高并发访问。HDFS 通过分布式架构和数据块存储方式,能够同时处理多个客户端的请求,提供高效的数据读取和写入性能,满足高并发访问的需求。
(4)不适合大量小文件存储的原因
需要注意的是,HDFS 并不适合存储大量的小文件。这是因为 HDFS 的 NameNode 进程需要在内存中存储文件的元数据,包括文件名、文件数据块信息等。当文件数量过多时,会占用大量的内存资源,导致 NameNode 节点内存耗尽,而实际存储的数据总量可能并不大,无法充分发挥 HDFS 存储海量数据的优势。
(三)、HDFS 的架构
(1)NameNode
NameNode 是 HDFS 的核心节点,它负责管理文件系统的命名空间和元数据。具体来说,NameNode 记录了文件的名称、目录结构、文件与数据块的映射关系以及数据块在 DataNode 上的存储位置等信息。所有对文件系统的操作,如创建文件、删除文件、读取文件等,都需要先与 NameNode 进行交互,获取元数据信息后才能进行实际的数据操作。
(2)SecondaryNameNode
SecondaryNameNode 的主要作用是定期合并 NameNode 的 EditLog 和 FSImage 文件,以防止 EditLog 文件过大导致恢复元数据时性能下降。它并不是 NameNode 的备用节点,而是辅助 NameNode 进行元数据管理的一个重要组件。
(3)DataNode
DataNode 是实际存储数据块的节点,它负责响应客户端的读写请求,将数据块存储在本地磁盘上,并定期向 NameNode 发送心跳信息和数据块报告,以表明自己的存活状态和所存储的数据块情况。一个 HDFS 集群中通常包含多个 DataNode 节点,它们共同构成了数据存储的基础。
(4)HDFS 客户端
HDFS 客户端是用户与 HDFS 系统交互的接口,它提供了一系列的命令和 API,使用户能够方便地对 HDFS 中的文件进行操作,如上传文件、下载文件、创建目录、删除文件等。客户端通过与 NameNode 和 DataNode 进行通信,完成各种文件操作请求。
(四)、HDFS 的基本概念
(1)元数据
元数据是描述数据的数据,在 HDFS 中,除了文件的数据本身外,其他与文件相关的信息都属于元数据。例如,文件的名称、权限、修改时间、数据块大小、数据块与 DataNode 的映射关系等。元数据对于文件系统的正常运行至关重要,它存储在 NameNode 的内存中,以便快速响应客户端的请求。为了保证元数据的可靠性,NameNode 会将所有的操作记录到 EditLog 日志文件中,并定期由 SecondaryNameNode 将 EditLog 合并到 FSImage 文件中。当集群重启时,NameNode 会读取 FSImage 文件来恢复元数据。
(2)数据块
HDFS 在存储文件时,会将文件按照一定的大小进行分割,这些分割后的独立文件单元称为数据块(Block)。在 Hadoop 2 中,默认的数据块大小为 128MB。数据块是 HDFS 存储和管理数据的基本单位,将大文件分割成数据块有以下几个优点:
- 便于数据的分布式存储和处理:数据块可以分布存储在不同的 DataNode 节点上,从而实现数据的并行处理和高可用性。
- 提高数据的可靠性:通过数据副本机制,每个数据块可以在多个节点上保存副本,当某个节点出现故障时,系统可以从其他副本中恢复数据。
- 简化存储管理:以数据块为单位进行管理,比直接管理整个文件更加灵活和高效。
(3)数据副本
为了保证数据的可靠性和高可用性,HDFS 采用了数据副本机制。即对于每个数据块,系统会在不同的 DataNode 节点上存储多个副本(默认副本数为 3)。数据副本的分布策略通常会考虑节点的机架位置等因素,以尽量保证数据的安全性和读取性能。例如,一个数据块的三个副本可能会分别存储在不同的机架上,这样即使某个机架出现故障,系统仍然可以从其他机架上的副本中获取数据。
(五)、数据副本的恢复流程
(1)数据块在 HDFS 中的分布
在正常情况下,数据块会分布存储在多个 DataNode 节点上,形成多个副本。当客户端读取数据时,HDFS 会根据数据块的分布情况,选择距离客户端最近的副本进行读取,以提高读取性能。同时,这种分布方式也保证了在部分节点故障时,数据的可用性。
(2)数据副本的恢复机制
- 节点故障检测:NameNode 会定期接收来自 DataNode 的心跳信息。如果在一段时间内,NameNode 没有收到某个 DataNode 的心跳,则会将该节点标识为死节点。这可能意味着该节点出现了故障,如硬件故障、网络故障等。
- 副本复制:当检测到节点故障后,NameNode 会根据配置的副本数,选择其他健康的 DataNode 节点,从现有副本中复制一份新的副本。这个过程会自动进行,无需人工干预,确保数据副本数量始终满足配置要求,从而保证数据的可靠性。
(六)、HDFS 的常用命令
(1)hdfs dfs -ls <path>
该命令用于显示 HDFS 指定路径下的所有文件和目录信息。命令执行后,会输出文件或目录的权限、所有者、所属组、大小、修改时间和名称等信息。例如:
hdfs dfs -ls /user/hadoop
(2)hdfs dfs -mkdir [-p] <path>
用于在 HDFS 上创建新的目录。如果指定的父目录不存在,加上 “-p” 选项可以自动创建父目录。例如:
hdfs dfs -mkdir /user/hadoop/data
hdfs dfs -mkdir -p /user/hadoop/dir1/dir2
(3)hdfs dfs -put <local src path> <dst path>
将本地文件上传到 HDFS 指定路径。例如:
hdfs dfs -put localfile.txt /user/hadoop/upload
(4)hdfs dfs -get <src path> <local dst>
将 HDFS 上的文件下载到本地文件系统指定路径。例如:
hdfs dfs -get /user/hadoop/file.txt localdir
(5)hdfs dfs -rm [-r] <path>
删除 HDFS 上的文件或目录。使用 “-r” 选项可以递归删除目录及其子目录下的所有文件。例如:
hdfs dfs -rm /user/hadoop/file.txt
hdfs dfs -rm -r /user/hadoop/dir
(6)hdfs dfs -chown [-R] [OWNER][:[GROUP]] PATH...
改变指定文件或目录的所有者和所属组。“-R” 选项用于递归修改子目录的所有者和所属组。例如:
hdfs dfs -chown user1:group1 /user/hadoop/file.txt
hdfs dfs -chown -R user2:group2 /user/hadoop/dir
(7)hdfs dfs -chmod [-R] <MODE [,MODE]... | OCTALMODE> PATH...
修改指定文件或目录的权限。例如:
hdfs dfs -chmod 755 /user/hadoop/file.txt
hdfs dfs -chmod -R g+w /user/hadoop/dir
(七)、总结
Hadoop 分布式文件系统(HDFS)作为大数据存储的重要解决方案,通过其独特的架构、数据副本机制和丰富的命令集,为海量数据的存储和管理提供了强大的支持。理解 HDFS 的原理和使用方法,对于从事大数据相关工作的人员至关重要。希望本文能够帮助读者更好地掌握 HDFS,为进一步探索大数据领域奠定坚实的基础。
六、深入解析 Hadoop 分布式文件系统(HDFS)的 Java API 应用
一、引言
在大数据处理领域,Hadoop 分布式文件系统(HDFS)扮演着至关重要的角色。它提供了高可靠性、高吞吐量的数据存储服务,能够应对海量数据的存储和处理需求。而通过 Hadoop Java API,开发者可以更加灵活地与 HDFS 进行交互,实现各种复杂的数据操作。本文将详细介绍如何使用 Hadoop Java API 进行 HDFS 文件的读写操作,并结合实际代码示例和操作步骤,帮助读者深入理解和掌握这一技术。
二、Hadoop Java API 概述
Hadoop Java API 是 Hadoop 框架提供的一组编程接口,它允许开发者使用 Java 语言与 Hadoop 生态系统中的各种组件进行交互,包括 HDFS、MapReduce 等。通过这些 API,开发者可以在 Java 程序中实现对 HDFS 文件的创建、读取、写入、删除等操作,以及对文件系统的管理和监控。Hadoop Java API 提供了丰富的类和方法,使得开发者能够方便地操作 HDFS 中的文件和目录,实现高效的数据处理和存储。
三、使用 Hadoop Java API 查看 HDFS 文件列表
(一)创建 Java 项目
- 打开 IDEA,点击 “New Project” 创建一个新的 Java 项目。
- 在创建项目的过程中,关联 JDK(确保 JDK 版本与 Hadoop 兼容)。
- 为项目命名并选择项目路径,点击 “Finish” 完成项目创建。
- 在项目中创建一个包(package),例如 “com.lzzy”。
- 在包下创建一个 Java 类,例如 “HdfsDemo”。
(二)引入 HDFS 相关的 jar 包
- 点击 “Project Structure”,在弹出的对话框中选择 “Libraries”。
- 点击 “+” 号,选择 “From Maven...” 或 “Java”,找到 HDFS 相关的 jar 包并添加到项目中。确保引入的 jar 包版本与 Hadoop 集群版本一致。
(三)编写代码查看文件列表
- 在 “HdfsDemo” 类中,导入必要的类:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
- 在 “main” 方法中,编写以下代码:
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
conf.set("fs.defaultFs", "hdfs://hjw:9000"); // 设置HDFS的地址
FileSystem fs = FileSystem.get(conf);
FileStatus[] fileStatuses = fs.listStatus(new Path("/")); // 获取根目录下的文件列表
for (FileStatus fileStatus : fileStatuses) {
System.out.println(fileStatus.getPath());
}
fs.close();
}
(四)运行程序
- 右键点击 “HdfsDemo” 类,选择 “Run 'HdfsDemo.main ()'” 运行程序。
- 观察控制台输出,查看 HDFS 根目录下的文件列表。
(五)练习与扩展
- 练习:修改程序代码,使其输出 HDFS 的 “/dir1” 下的所有文件名。如果 HDFS 中不存在 “/dir1” 目录,先使用 hdfs 命令创建该目录,并上传一个文件到该目录下。
- 扩展:对代码进行升级改造,使程序在运行时可以接受一个路径参数,输出该路径下的文件列表。这样可以提高程序的灵活性,无需每次修改代码来指定不同的路径。
四、使用 Hadoop Java API 在 HDFS 上写文件
(一)实现思路
- 创建一个 Java 项目,并在项目中创建一个主类(Main Class)。
- 创建一个 “Configuration” 对象,用于配置 HDFS 连接参数,如设置 “fs.defaultFS” 为 HDFS 的地址。
- 通过 “FileSystem.get (...)” 方法获取一个 “FileSystem” 对象,该对象用于与 HDFS 进行交互。
- 使用 “FileSystem” 对象的 “create (...)” 方法创建一个新的文件,并返回一个 “FSDataOutputStream” 对象,用于向文件中写入数据。
- 调用 “FSDataOutputStream” 对象的 “writeUTF (...)” 方法或其他写入方法,将数据写入到 HDFS 文件中。
- 最后关闭 “FSDataOutputStream” 和 “FileSystem” 对象,释放资源。
(二)演示代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class WriteToHdfsDemo {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
conf.set("fs.defaultFs", "hdfs://hjw");
// 准备测试数据
List<String> data = new ArrayList<>();
data.add("hello hdfs\n");
data.add("i love lz\n");
data.add("我来自广西");
FileSystem fs = FileSystem.get(conf);
// 创建一个文件,路径为/dir3/ram-to-dfs.txt,如果/dir3目录不存在,会自动创建
FSDataOutputStream out = fs.create(new Path("/dir3/ram-to-dfs.txt"));
// 将data对象的数据写到hdfs
for (String d : data) {
// d.getBytes(StandardCharsets.UTF_8)的作用是将UTF-8字符串转成字节数组
out.write(d.getBytes(StandardCharsets.UTF_8));
}
out.flush();
out.close();
fs.close();
}
}
(三)练一练
- 多次运行上述代码,观察 HDFS 上 “/dir3/ram-to-dfs.txt” 文件内容的变化情况。
- 如果希望将数据追加到文件末尾,而不是覆盖原有内容,需要将 “fs.create ()” 改为 “fs.append ()”,并相应地调整代码逻辑。
五、使用 Hadoop Java API 读 HDFS 上的文件
(一)实现思路
- 创建 Java 项目并创建主类。
- 配置 “Configuration” 对象,连接 HDFS。
- 获取 “FileSystem” 对象。
- 使用 “FileSystem” 对象的 “open (...)” 方法打开要读取的文件,返回一个 “FSDataInputStream” 对象。
- 创建一个 “BufferedReader” 对象,将 “FSDataInputStream” 作为参数传入,用于缓冲读取文件内容。
- 通过 “BufferedReader” 对象的 “readLine ()” 方法逐行读取文件内容,并打印到控制台。
- 关闭 “BufferedReader” 和 “FileSystem” 对象。
(二)示例代码
import java.io.IOException;
import java.io.BufferedReader;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.conf.Configuration;
import java.io.InputStreamReader;
import org.apache.hadoop.fs.FileSystem;
public class ReadFromHdfsDemo {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
conf.set("fs.defaultFs", "hdfs://hjw");
FileSystem fs = FileSystem.get(conf);
FSDataInputStream in = fs.open(new Path("/dir3/ram-to-dfs.txt"));
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
String line = reader.readLine();
while (null!= line) {
System.out.println(line);
line = reader.readLine();
}
reader.close();
fs.close();
}
}
六、综合:使用 Hadoop Java API 将本地文件上传到 HDFS
(一)实现思路
- 创建 Java 项目和主类。
- 配置 “Configuration” 对象。
- 获取 “FileSystem” 对象。
- 使用 “FileSystem” 对象的 “create (...)” 方法创建一个 HDFS 文件流,用于写入数据。
- 通过 “FileInputStream” 对象从本地文件读取数据。
- 使用 “Hadoop 提供的 IOUtils.copyBytes (...)” 方法将本地文件的数据复制到 HDFS 文件中,实现文件上传。
- 关闭相关对象。
(二)演示代码
import java.io.IOException;
import java.io.FileInputStream;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.conf.Configuration;
public class DiskToDfsDemo {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
conf.set("fs.defaultFs", "hdfs://hjw");
FileSystem fs = FileSystem.get(conf);
// 创建一个文件流,和指定的本地文件(此处演示,该本地文件为当前项目目录下的ip.txt)建立连接
FileInputStream in = new FileInputStream("ip.txt");
FSDataOutputStream out = fs.create(new Path("/dir3/ip.txt"));
// 将本地文件(in对象)的字节数拷贝到HDFS文件(out对象)中
IOUtils.copyBytes(in, out, 1024);
fs.close();
}
}
七、项目打包与部署
(一)打包项目为 jar 包
- 在 IDEA 中,点击 “File -> Project Structure...”,打开项目结构对话框。
- 在 “Artifacts” 选项卡中,点击 “+” 号,选择 “JAR -> From modules with dependencies...”,创建一个可执行的 jar 包。
- 选择主类(Main Class),并配置其他相关参数,如输出目录等。
- 点击 “OK” 保存配置,然后点击 “Build -> Build Artifacts...”,选择要构建的 jar 包并点击 “Build” 进行打包。
(二)部署 jar 包到 Hadoop 集群节点并运行
- 将打包好的 jar 包以及 Hadoop 的相关 jar 包上传到 Hadoop 集群的任一节点。
- 使用 Java 命令运行 jar 包,例如:
java -cp hdfs2.7.2-jars/*:./HdfsDemo2024.jar com.demo.ReadFromHdfsDemo
其中,“-cp” 指定了类路径,包括 Hadoop 的 jar 包和自定义的 jar 包,“com.demo.ReadFromHdfsDemo” 是要运行的主类。
(三)扩展与思考
- 尝试使用 “java -jar xxx.jar” 的方式运行 jar 包,了解其与 “java -cp” 方式的区别和适用场景。
- 思考如何优化程序,使其能够更方便地处理不同路径和不同文件名的文件读写操作,提高程序的通用性和可扩展性。
八、总结
通过本文的介绍,我们详细学习了如何使用 Hadoop Java API 进行 HDFS 文件的读写操作,包括查看文件列表、写文件、读文件以及将本地文件上传到 HDFS。同时,我们还了解了如何创建 Java 项目、引入 HDFS 相关的 jar 包、编写代码实现各种功能,以及如何将项目打包成 jar 包并部署到 Hadoop 集群节点上运行。掌握这些知识和技能,对于深入理解 Hadoop 生态系统和进行大数据处理开发具有重要意义。希望读者能够通过实际操作和练习,熟练掌握 Hadoop Java API 的使用,为解决实际的大数据存储和处理问题奠定坚实的基础。
七、Hadoop 核心技术学习心得
在学习《Hadoop 核心技术》这门课程的过程中,我仿佛置身于一个全新的技术领域,开启了一场充满挑战与惊喜的知识探索之旅。通过理论学习、实践操作以及项目实践,我不仅掌握了 Hadoop 这一强大的大数据处理框架的核心技术,更在思维方式、问题解决能力以及团队协作等方面取得了显著的成长。
一、技术知识的深度掌握
(一)HDFS 分布式文件系统
- 架构理解
深入学习了 HDFS 的架构,包括 NameNode、DataNode 以及 SecondaryNameNode 等关键组件的功能和协作机制。明白了 NameNode 作为文件系统的元数据管理中心,如何维护文件系统的命名空间、目录结构以及文件到数据块的映射关系;而 DataNode 则负责实际存储数据块,并定期向 NameNode 发送心跳和数据块报告,以确保数据的可靠性和可用性。这种分布式架构设计使得 HDFS 能够轻松应对海量数据的存储需求,通过数据块的复制和分布存储在多个节点上,实现了数据的高容错性。 - 操作技能
熟练掌握了 HDFS 的常用命令,如文件和目录的创建(mkdir)、查看(ls)、上传(put)、下载(get)、删除(rm)等操作。这些命令的熟练运用为日常的数据管理工作提供了极大的便利,使我能够高效地在分布式环境中组织和处理数据。同时,通过学习 HDFS 的 Java API,我能够在 Java 程序中实现对 HDFS 的更高级操作,如自定义文件操作逻辑、与其他系统进行集成等,进一步拓展了 HDFS 的应用场景。
(二)MapReduce 编程模型
- 编程思想领悟
MapReduce 编程模型是 Hadoop 的核心计算引擎,其分而治之的思想给我留下了深刻的印象。在 Map 阶段,将大规模数据集分割成多个小块,并行地在不同节点上进行处理,生成键值对形式的中间结果;然后在 Reduce 阶段,将具有相同键的值进行合并和进一步计算,最终得到我们所需的结果。通过编写 WordCount 等经典案例,我逐渐掌握了如何将实际问题抽象为 MapReduce 任务,合理设计 Map 和 Reduce 函数的逻辑,以及如何处理数据倾斜等常见问题。这种编程模型不仅提高了数据处理的效率,还使得程序能够在集群环境中自动并行执行,充分发挥分布式计算的优势。 - 性能优化技巧
在实践中,深入研究了 MapReduce 的性能优化策略。学会了通过调整参数,如 Map 和 Reduce 任务的数量、数据块大小等,来优化任务的执行效率;合理选择分区函数,确保数据在 Reduce 阶段能够均匀分布,避免数据倾斜导致的性能瓶颈;使用 Combiner 函数在 Map 端进行局部聚合,减少数据传输量,提高网络带宽利用率。这些优化技巧的掌握,使我能够编写更加高效、快速的 MapReduce 程序,有效应对大规模数据处理的挑战。
(三)YARN 资源管理框架
- 资源管理原理
YARN 作为 Hadoop 的资源管理框架,将资源管理和任务调度分离,实现了对集群资源的统一管理和分配。了解了 ResourceManager 作为资源管理器,负责整个集群资源的分配和调度;NodeManager 则负责管理单个节点上的资源,并向 ResourceManager 汇报资源使用情况。通过学习 YARN 的工作原理,我明白了如何根据不同应用程序的需求,动态地分配 CPU、内存等资源,提高集群资源的利用率,确保各个任务能够公平、高效地运行。 - 任务调度策略
掌握了 YARN 的多种任务调度策略,如 FIFO(先进先出)、Capacity Scheduler(容量调度器)和 Fair Scheduler(公平调度器)等。不同的调度策略适用于不同的应用场景,能够根据任务的优先级、队列设置等因素,合理地安排任务在集群中的执行顺序。这使得我在实际应用中能够根据业务需求选择合适的调度策略,优化任务执行流程,提高整个集群的运行效率。
(四)Hadoop 生态系统集成
- 组件协同工作
认识到 Hadoop 生态系统不仅仅是 HDFS、MapReduce 和 YARN 的简单组合,还包括了众多其他组件,如 Hive、HBase、Spark 等,它们相互协同工作,共同构建了一个完整的大数据处理平台。学习了 Hive 如何基于 HDFS 存储数据,并提供类似于 SQL 的查询语言,方便数据分析师进行数据仓库和数据分析工作;HBase 则专注于实时读写大规模结构化数据,适用于对数据读写性能要求较高的场景。通过了解这些组件的特点和适用场景,以及它们与 Hadoop 核心组件的集成方式,我能够根据具体业务需求,选择合适的组件组合,构建高效、灵活的大数据解决方案。 - 数据处理流程优化
在实际项目中,学会了如何整合不同组件,优化数据处理流程。例如,利用 Hive 进行数据的 ETL(抽取、转换、加载)操作,将处理后的数据存储在 HBase 中,以供实时查询和分析;或者结合 Spark 的快速计算能力,对 HDFS 中的数据进行复杂的迭代计算和机器学习任务。这种多组件协同工作的方式,充分发挥了各个组件的优势,提高了整个大数据处理系统的性能和功能。
二、实践能力的全面提升
(一)项目实践经验积累
- 项目需求分析与设计
在课程项目实践中,积极参与项目需求分析和设计阶段。学会了从业务需求出发,梳理数据流程,确定数据存储结构和计算逻辑。例如,在一个电商数据分析项目中,需要分析用户行为数据,以了解用户购买偏好和消费趋势。通过与团队成员共同讨论,确定了使用 Hive 对原始日志数据进行清洗和转换,存储到结构化的数据表中;然后利用 MapReduce 或 Spark 进行数据分析和挖掘,最终生成可视化报表供业务部门决策使用。这个过程锻炼了我的需求理解能力和系统设计能力,使我能够根据实际业务场景,设计出合理、高效的大数据解决方案。 - 集群搭建与配置
亲自搭建 Hadoop 集群是一次宝贵的实践经历。从硬件选型、操作系统安装到 Hadoop 各个组件的部署和配置,每一个环节都需要仔细操作。在这个过程中,遇到了各种网络配置、环境变量设置以及组件兼容性等问题,但通过查阅大量资料、参考官方文档以及向老师和同学请教,最终成功搭建了一个稳定的 Hadoop 集群。这不仅使我熟悉了 Hadoop 集群的搭建流程和细节,还培养了我的问题解决能力和耐心,为后续的项目开发和数据处理工作提供了坚实的基础。 - 数据处理与分析任务实现
在项目中,运用所学的 Hadoop 核心技术,实现了各种数据处理和分析任务。编写了复杂的 MapReduce 程序和 Spark 作业,对海量数据进行清洗、转换、统计分析和挖掘。例如,在处理大规模用户行为数据时,通过 MapReduce 实现了数据去重、用户行为路径分析等功能;利用 Spark 的机器学习库进行用户购买预测和商品推荐。这些实践操作让我对 Hadoop 技术在实际数据处理中的应用有了更深入的理解,提高了我的编程能力和数据处理技巧,能够熟练运用各种算法和工具解决实际问题。
(二)问题解决能力培养
- 调试技巧与错误排查
在编写和运行 Hadoop 程序过程中,不可避免地会遇到各种错误和异常。通过不断地调试和排查问题,我逐渐掌握了一套有效的调试技巧。学会了查看 Hadoop 日志文件,从日志信息中获取关键线索,定位错误发生的位置和原因。例如,当 MapReduce 任务失败时,通过分析任务日志中的错误堆栈信息,能够快速判断是数据格式问题、代码逻辑错误还是资源配置不足等原因导致的。同时,学会了使用调试工具,如在 IDEA 中设置断点、逐步调试代码,以便更深入地理解程序的执行过程,找到并解决问题。 - 性能优化与瓶颈突破
面对大数据处理任务的性能挑战,积极探索性能优化方案。当发现程序运行速度过慢或资源消耗过高时,会从多个方面进行分析和优化。除了前面提到的 MapReduce 和 YARN 的性能优化策略外,还会考虑数据存储格式的选择、算法的改进以及硬件资源的合理分配等因素。例如,在处理大量小文件时,将其合并成大文件存储在 HDFS 中,以减少 NameNode 的内存压力和文件操作开销;对于计算密集型任务,适当增加节点的 CPU 核心数或优化算法实现,提高计算效率。通过不断地尝试和优化,成功突破了多个性能瓶颈,提高了项目的整体运行效率。
(三)团队协作与沟通
- 团队合作模式
在课程项目中,与团队成员密切合作,共同完成各项任务。学会了如何在团队中发挥自己的优势,承担相应的责任。例如,有的成员擅长数据建模和算法设计,负责数据分析部分的工作;有的成员熟悉集群管理和运维,负责 Hadoop 集群的搭建和优化;而我则在数据处理和编程方面发挥自己的专长,负责编写 MapReduce 和 Spark 程序。通过合理分工、协作互补,我们高效地完成了项目任务,同时也培养了团队合作精神和沟通能力。 - 沟通与知识共享
团队成员之间的沟通和知识共享是项目成功的关键。定期组织团队会议,讨论项目进展、遇到的问题以及解决方案。在会议中,积极分享自己的经验和见解,同时也认真倾听其他成员的想法和建议。通过这种方式,不仅解决了许多技术难题,还拓宽了自己的知识面。例如,在学习 Hive 时,团队成员之间分享了各自在使用 Hive 过程中的优化技巧和常见问题解决方法,使大家都能够更好地掌握这一工具。此外,还利用版本控制系统(如 Git)进行代码管理和协作开发,确保团队成员之间的代码同步和协作顺畅。
三、思维方式的深刻转变
(一)分布式思维养成
- 从单机到集群的视角转换
Hadoop 的分布式架构要求我彻底改变传统的单机思维方式,学会从集群的角度思考问题。在处理数据和任务时,不再局限于单个计算机的资源和处理能力,而是考虑如何充分利用集群中多个节点的并行计算能力和存储资源。例如,在设计数据存储结构时,会根据数据的特点和访问模式,合理分布数据块在不同节点上,以提高数据的读写性能;在编写程序时,会充分利用 MapReduce 的分布式计算特性,将任务分解为多个子任务在不同节点上并行执行,从而加速整个计算过程。这种分布式思维的养成,使我能够更好地应对大规模数据处理的挑战,设计出更加高效、可扩展的大数据解决方案。 - 数据分布与负载均衡考虑
在分布式环境中,数据分布和负载均衡是影响系统性能的重要因素。学会了如何合理地分布数据,避免数据倾斜现象的发生,确保各个节点的负载相对均衡。例如,在使用 MapReduce 处理数据时,通过自定义分区函数,根据数据的键值将数据均匀地分配到不同的 Reduce 任务中,避免某个 Reduce 任务处理过多的数据而成为性能瓶颈。同时,在集群资源分配方面,也会根据任务的需求和节点的资源状况,动态地调整资源分配策略,保证集群的整体性能和稳定性。
(二)数据驱动决策意识增强
- 基于数据分析的决策过程
通过学习 Hadoop 核心技术,深刻认识到数据在决策过程中的重要性。在项目实践中,学会了通过对海量数据的收集、清洗、分析和可视化,提取有价值的信息,为决策提供数据支持。例如,在分析电商用户行为数据时,通过对用户购买记录、浏览历史、搜索关键词等数据的深入分析,能够了解用户的购买偏好、消费能力以及兴趣爱好等信息,从而为企业的商品推荐、营销策略制定等决策提供依据。这种基于数据分析的决策过程,使决策更加科学、客观,能够有效提高企业的运营效率和竞争力。 - 数据质量与价值挖掘
意识到数据质量是影响决策准确性的关键因素。在数据处理过程中,注重数据的清洗和预处理工作,确保数据的准确性、完整性和一致性。同时,不断探索如何从海量数据中挖掘出更深层次的价值。除了传统的统计分析方法外,还学习了机器学习、数据挖掘等技术,通过建立模型和算法,发现数据中的隐藏模式和规律,为企业提供更具前瞻性的决策建议。例如,利用聚类分析将用户进行分类,针对不同类型的用户制定个性化的营销策略;通过预测模型对商品销量进行预测,提前做好库存管理和生产计划。
(三)创新思维与技术探索精神激发
- 新技术学习与应用尝试
Hadoop 作为大数据领域的核心技术,不断推动着技术创新和行业变革。在学习过程中,始终保持对新技术的好奇心和学习热情,积极关注 Hadoop 生态系统以及大数据领域的最新发展动态。例如,学习和了解 Spark 作为一种新兴的大数据处理框架,与 Hadoop 相比具有更快的计算速度和更丰富的功能,尝试将 Spark 应用于实际项目中,与 Hadoop 进行集成和对比分析,探索如何在不同场景下选择更合适的技术方案。这种对新技术的学习和应用尝试,不仅拓宽了自己的技术视野,还培养了创新思维和技术探索精神。 - 问题解决中的创新思维运用
在面对项目中的各种问题和挑战时,尝试运用创新思维寻找解决方案。不再局限于传统的解决方法,而是敢于尝试新的思路和技术手段。例如,在处理大规模数据的实时处理需求时,传统的 MapReduce 模型可能无法满足性能要求,通过研究和学习新的流处理技术(如 Flink),探索将其与 Hadoop 生态系统集成的可能性,为解决实时数据处理问题提供了新的方向。这种创新思维的运用,使我在解决问题的过程中不断突破自我,提高了应对复杂技术问题的能力。
四、总结与展望
(一)学习收获总结
通过《Hadoop 核心技术》课程的学习,我在技术知识、实践能力和思维方式等方面都取得了丰硕的收获。掌握了 Hadoop 生态系统的核心组件和技术原理,能够熟练运用 HDFS、MapReduce、YARN 等工具进行大数据处理和分析;通过项目实践,积累了丰富的实际操作经验,提高了问题解决能力、团队协作能力和创新思维能力;同时,养成了分布式思维和数据驱动决策的意识,为今后从事大数据相关工作奠定了坚实的基础。
(二)未来发展展望
大数据技术在当今社会的各个领域都有着广泛的应用和巨大的发展潜力。在未来的学习和工作中,我将继续深入学习和研究大数据技术,不断提升自己的专业水平。计划进一步探索 Hadoop 生态系统的高级特性和应用场景,如实时计算、机器学习、数据安全等领域;关注行业发展趋势,学习和掌握新兴的大数据技术和工具,如 Apache Flink、Apache Beam 等,将其与 Hadoop 进行有机结合,为企业提供更加高效、智能的大数据解决方案。同时,希望能够在大数据领域中不断创新和实践,为推动行业发展贡献自己的一份力量。
总之,《Hadoop 核心技术》课程的学习是我技术成长道路上的重要里程碑,它为我打开了一扇通往大数据世界的大门,让我领略到了分布式计算和大数据处理的魅力。我将以此次学习为契机,不断努力,在大数据领域中砥砺前行,追求更高的技术成就。

















 5388
5388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









