






目录
编辑RDD运行过程过上述对RDD概念、依赖关系和Stage划分的介绍,结合之前介绍的Spark运行基本流程,再总结一下RDD在Spark架构中的运行过程:
val:name:List(类型)=List(“ ”,” ”,” ”)
(1)通过SparkSession中的createDataset来创建Dataset
(2)DataFrame通过“as[ElementType]”方法转换得到Dataset
1.介绍spark
导论(基于Hadoop的MapReduce的优缺点)
MapReduce是一个分布式运算程序的编程框架,是用户开发“基于Hadoop的数据分析应用”的核心框架
MapReduce是一种用于处理大规模数据集的编程模型和计算框架。它将数据处理过程分为两个主要阶段:Map阶段和Reduce阶段。在Map阶段,数据被分割为多个小块,并由多个并行运行的Mapper进行处理。在Reduce阶段,Mapper的输出被合并和排序,并由多个并行运行的Reducer进行最终的聚合和计算。MapReduce的优缺点如下:
优点:
可伸缩性:MapReduce可以处理大规模的数据集,通过将数据分割为多个小块并进行并行处理,可以有效地利用集群的计算资源。它可以在需要处理更大数据集时进行水平扩展,而不需要对现有的代码进行修改。
容错性:MapReduce具有高度的容错性。当某个节点发生故障时,作业可以自动重新分配给其他可用的节点进行处理,从而保证作业的完成。
灵活性:MapReduce允许开发人员使用自定义的Mapper和Reducer来处理各种类型的数据和计算任务。它提供了灵活的编程模型,可以根据具体需求进行定制和扩展。
易于使用:MapReduce提供了高级抽象,隐藏了底层的并行和分布式处理细节。开发人员只需要关注数据的转换和计算逻辑,而不需要关心并发和分布式算法的实现细节。
缺点:
适用性有限:MapReduce适用于一些需要进行大规模数据处理和分析的场景,但对于一些需要实时计算和交互式查询的场景,MapReduce的延迟较高,不太适合。
复杂性:尽管MapReduce提供了高级抽象,但对于开发人员来说,编写和调试MapReduce作业仍然是一项复杂的任务。需要熟悉MapReduce的编程模型和框架,并理解分布式计算的概念和原理。
磁盘IO开销:在MapReduce中,数据需要在Map和Reduce阶段之间进行磁盘IO,这可能会导致性能瓶颈。尽管可以通过合理的数据分区和调优来减少磁盘IO的开销,但仍然需要考虑和处理数据移动和复制的开销。
综上所述,MapReduce是一种适用于大规模数据处理的编程模型和计算框架,具有可伸缩性、容错性、灵活性和易用性等优点。然而,它在实时计算和交互式查询等场景下的适用性有限,同时开发和调试MapReduce作业的复杂性也需要考虑
1.1 Spark 为何物
Spark 是当今大数据领域最活跃、最热门、最高效的大数据通用计算平台之一。
Hadoop 之父 Doug Cutting 指出:Use of MapReduce engine for Big Data projects will decline, replaced by Apache Spark (大数据项目的 MapReduce 引擎的使用将下降,由 Apache Spark 取代)。
spark概述
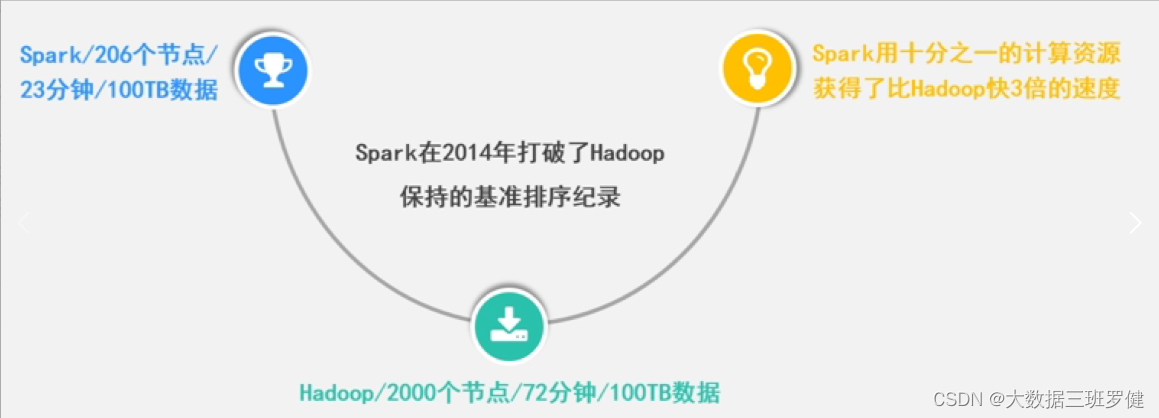
第一阶段:Spark最初由美国加州伯克利大学( UC Berkelcy)的AMP实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序
第二阶段:2013年Spark加入Apache孵化器项日后发展迅猛,如今已成为Apache软件基金会最重要的三大分布式计算系统开源项目之一( Hadoop磁盘MR离线式、Spark基于内存实时数据分析框架、Storm数据流分析框架 )
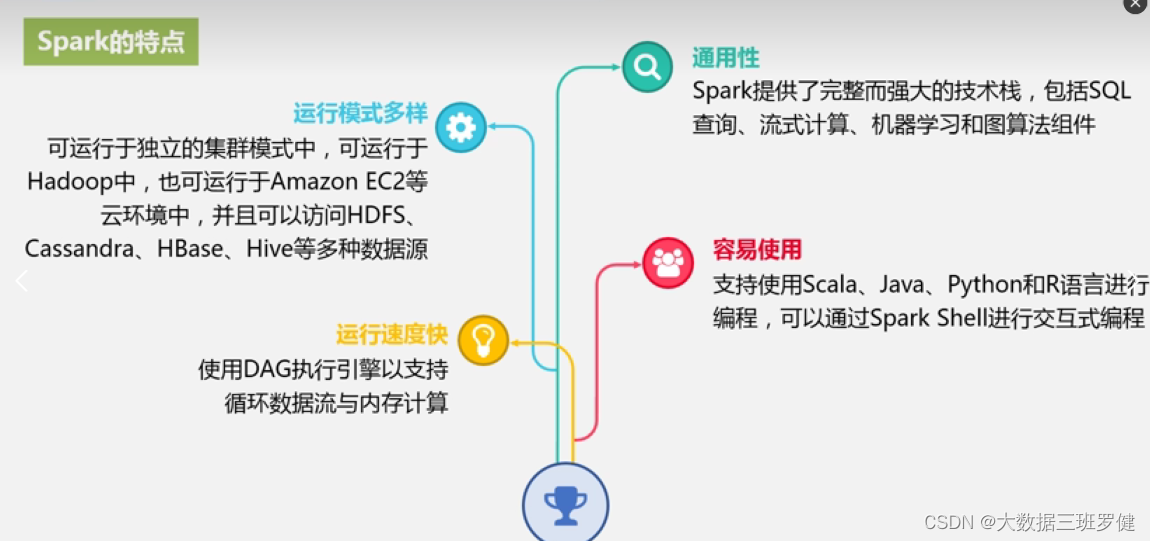
1.2Spark的主要特点

2.介绍scala
Scala简介
Scala是一门现代的多范式编程语言 ,运行于IAVA平台(JVM,JAVA虚拟机)并兼容现有的JAVA程序
Scala的特点
① Scala具备强大的并发性,支持函数式编程,可以更好地支持分布式系统。
② Scala语法简洁,能提供优雅的API。
③ Scala兼容Java,运行速度快,且能融合到Hadoop生态圈中。
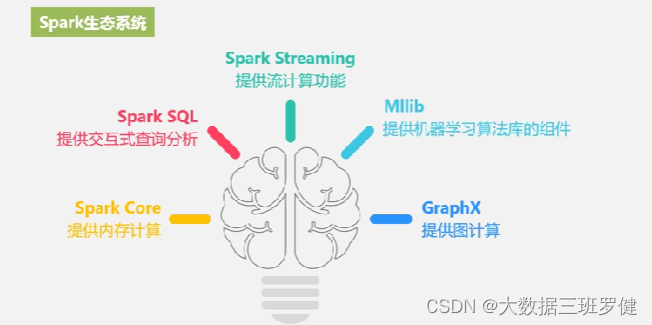
Spark生态系统
在实际应用中,大数据处理主要包括一下3个类型:
① 复杂的批量数据处理:时间跨度通常在数十分钟到数小时之间。
② 基于历史数据的交互式查询:时间跨度通常在数十秒到数分钟之间。
③ 基于实时数据流的数据处理:时间跨度通常在数百毫秒到数秒之间。
当同时存在以上三种场景时,就需要同时部署三种不同的软件

核心组件:
Spark的应用场景

Spark的运行架构
1.基本概念
在具体讲解Spark运行架构之前,需要先了解以下7个重要的概念。
① RDD:是弹性分布式数据集的英文缩写,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
② DAG:是有向无环图的英文缩写,反映RDD之间的依赖关系。
③ Executor:是运行在工作节点上的一个进程,负责运行任务,并为应用程序存储数据。
④ 应用:用户编写的Spark应用程序。
⑤ 任务:运行在Executor上的工作单元。
⑥ 作业:一个作业包含多个RDD及作用于相应RDD上的各种操作。
⑦ 阶段:是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为“阶段”,或者也被称为“任务集”
2.Spark运行架构

(1)当一个Spark应用被提交时,首先需要为这个应用构建起基本的运行环境,即由任务控制节点创建一个SparkContext,由SparkContext负责和资源管理器的通信以及进行资源的申请、任务的分配和监控等。SparkContext 会向资源管理器注册并申请运行Executor的资源。
(2)资源管理器为Executor分配资源,并启动Executor进程,Executor运行情况将随着“心跳”发送到资源管理器上。
(3)SparkContext 根据 RDD 的依赖关系构建 DAG 图,DAG 图提交给 DAG 调度器进行解析,将DAG图分解成多个“阶段”(每个阶段都是一个任务集),并且计算出各个阶段之间的依赖关系,然后把一个个“任务集”提交给底层的任务调度器进行处理;Executor 向 SparkContext 申请任务,任务调度器将任务分发给 Executor 运行,同时SparkContext将应用程序代码发放给Executor。
(4)任务在Executor上运行,把执行结果反馈给任务调度器,然后反馈给DAG调度器,运行完毕后写入数据并释放所有资源。
Spark运行架构特点:
1.每个application都有自己专属的Executor进程,并且该进程在application运行期间一直驻留,executor进程以多线程的方式运行Task
2.Spark运行过程与资源管理无关,子要能够获取Executor进程并保持通信即可
3.Task采用了数据本地性和推测执行等优化机制,实现“计算向数据靠拢”
核心-RDD
设计背景
1.许多迭代式算法《比如机器学习、图算法等)和交互式数据挖掘工具,共同之处是,不同计算阶段之间会重用中间结果
2.目前的MapReduce框架都是把中间结果写入到磁盘中,带来大量的数据复制、磁盘Io和序列化开销
3.RDD就是为了满足这种需求而出现的,它提供了一个抽象的数据结构
4.我们不必担心底层数据的分布式持性,只需将具体的应用逻辑表达为一系列转换处理
5.不同RDD之间的转换操作形成依赖关系,可以实现管道化,避免中间数据存储
RDD概念
1.一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,不同节点上进行并行计算
2.RDD提供了一种高度受限的共享内存模型,RDD是只读的记录分区集合,不能直接修改,只能通过在转换的过程中改
RDD典型的执行过程如下


优点:
惰性调用,管道化,避免同步等待,不需要保存中间结果,每次操变得简单
RDD特性
1.高效的容错性
现有容错机制:数据复制或者记录日志RDD具有天生的容错性:血缘关系,重新计算丢失分区,无需回滚系统,重算过程在不同节点之间并行,只记录粗粒度的操作
2.中间结果持久化到内存,数据在内存中的多个RDD操作直接按进行传递,避免了不必要的读写磁盘开销
3.存放的数据可以是JAVA对象,避免了不必要的对象序列化和反序列化
RDD之间的依赖关系
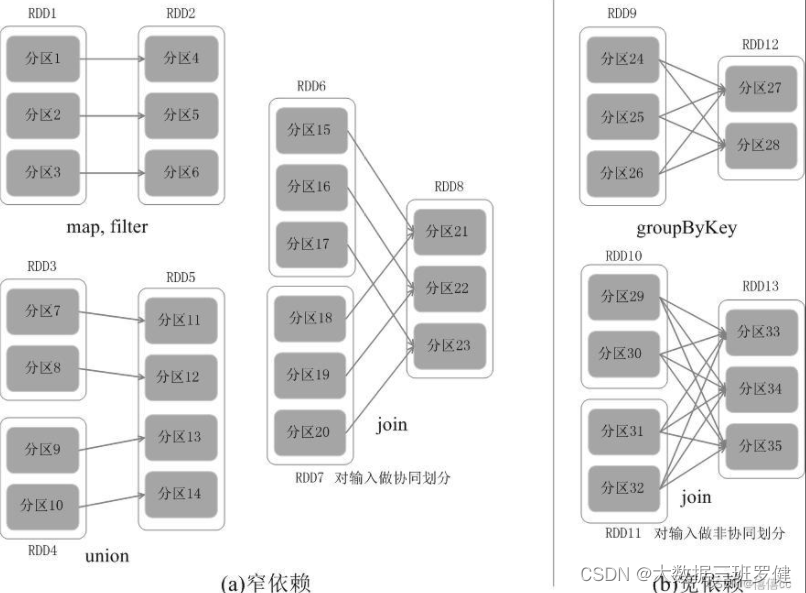
父RDD的一个分区只被一个子RDD的一个分区所使用就是窄依赖,否则就是宽依赖。

阶段的划分

RDD运行过程
过上述对RDD概念、依赖关系和Stage划分的介绍,结合之前介绍的Spark运行基本流程,再总结一下RDD在Spark架构中的运行过程:
(1)创建RDD对象;
(2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
(3)DAGScheduler负责把DAG图分解成多个Stage,每个Stage中包含了多个Task,每个Task会被TaskScheduler分发给各个WorkerNode上的Executor去执行。

3.Scala基础方法
(1)定义使用常量变量
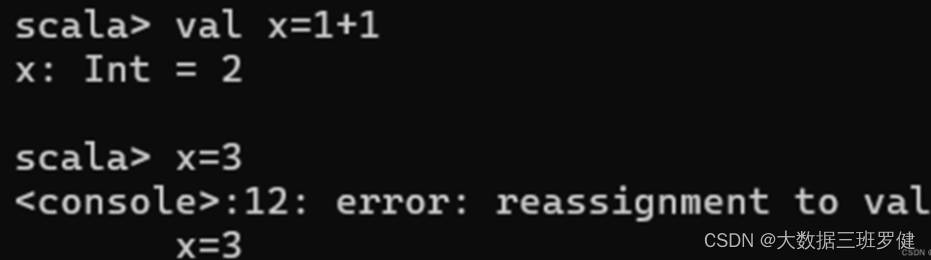
1.val定义常量:
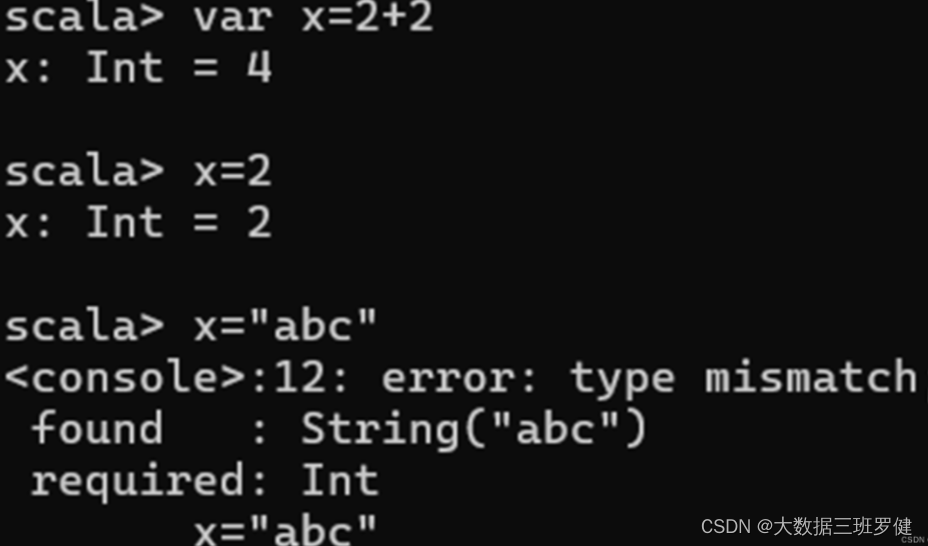
2.var定义变量:
(2)定义使用数组
方法一:

方法二:

(3)操作数组
1.查看数组长度:

2.查看数组z的第一个元素:

3.查看数组z中除了第一个元素外的其他元素:

4.判断数组z是否为空:

5.判断数组z 是否包含元素“a”:

(4)连接数组
1.“++”连接:

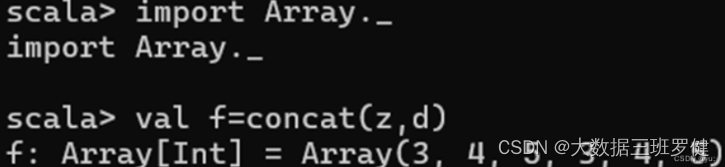
2.concat()l连接:
(5)创建区间函数,生成数组
1.调用函数:

2.Scala占位符:

(6)高阶函数 —函数作为返回值
定义高阶函数计算矩形周长:

(7)函数柯里化
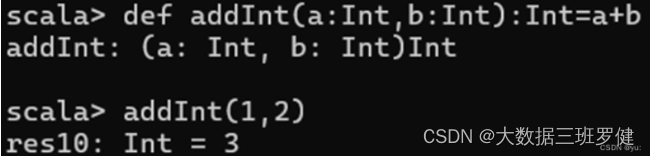
定义两个整数相加函数的写法以及其调用方式:
函数柯里化:

(8)使用for循环
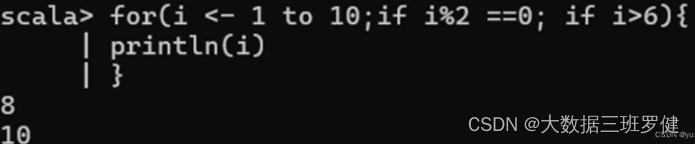
环嵌套if判断
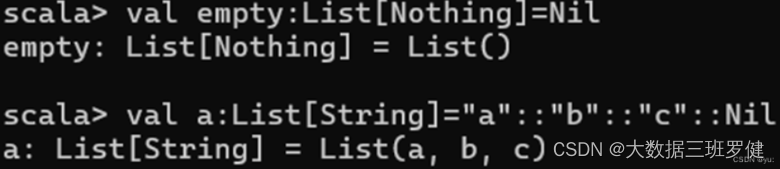
(9)定义不同数据类型的列表
val:name:List(类型)=List(“ ”,” ”,” ”)
使用“Nil”和“::”定义列表:
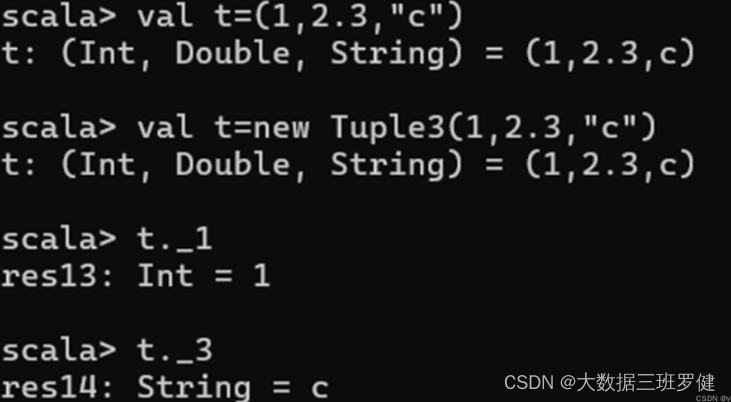
(10)定义和使用元祖
4.Spark编程基础
RDD简介
RDD 是一个容错的、只读的、可进行并行操作的数据结构,是一个分布在集群各个节点中的存放元素的集合。RDD有3种不同的创建方法。第一种是将程序中已存在的 Sea 集合(如集合、列表、数组)转换成RDD,第二种是对已有RDD 进行转换得到新的RDD,这两种方法都是通过内存中已有的数据创建RDD 的。第三种是直接读取外部存储系统的数据创建 RDD
(1).parallelize()
创建RDD及查看分区个数
创建RDD及查看分区个数
package test
import org.apache.spark.{SparkConf, SparkContext}
object d {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("worldcount").setMaster("local")
val sc = new SparkContext(conf)
val data = Array(1, 2, 3, 4, 5)
//val distData = sc.parallelize(data)显示默认分区个数
val distData = sc.parallelize(data, 4)//设置分区为4
print(distData.partitions.size)
}
}(2).makeRDD()
//使用makeRDD()方法创建RDD并查看各分区的值
val seq=Seq((1,seq("iteblogs.com","sparkhost1.com")),
(3,Seq("iteblog.com","sparkhost2.com")),
(2,Seq("iteblog.com","sparkhost3.com")))
//使用makeRDD创建RDD
val iteblog=sc.makeRDD(seq)
//查看RDD的值
iteblog.collect.foreach(print)(3).map()方法转换数据
可以对RDD中的每一个数据元素通过某种函数进行转换并返回新的RDD
//创建RDD
val disData = sc.parallelize(List(1,3,45,3,76))
//map()方法求平均值
val sq_list=disData.map(x => x*x)
println(sq_list)(4).sortBy()方法进行排序
P58 获取上半年实际薪资排名前三的员工信息
//创建RDD
val data = sc.parallelize(List((1,3),(45,3),(7,6)))
//使用sortBy()方法对元祖的第二个值进行降序排序,分区个数设置为1
val sort_data=data.sortBy(x => x._2,false,1)
println(sort_data)(5).filter()方法进行过滤
package test
import org.apache.spark.{SparkConf, SparkContext}
object b {
def main(args: Array[String]): Unit = {
val conf =new SparkConf().setMaster("local").setAppName("PartialFumction")
val sc=new SparkContext(conf)
val rdd1 = sc.parallelize(List(('a',1),('b',2),('c',3)))
rdd1.filter(_._2>1).collect.foreach(println)
rdd1.filter(x => x._2 > 1).collect.foreach(println)
}
}(6).Distinct()方法去重
package test
import org.apache.spark.{SparkConf, SparkContext}
object c {
def main(args: Array[String]): Unit = {
val conf =new SparkConf().setMaster("local").setAppName("PartialFumction")
val sc=new SparkContext(conf)
val rdd3=sc.makeRDD(List(1,100,200,300,100))
rdd3.filter(x => x>99).collect()
rdd3.distinct().collect().foreach(println)
}
}(7).Intersection方法
package test
import org.apache.spark.{SparkConf, SparkContext}
object e {
def main(args: Array[String]): Unit = {
val conf =new SparkConf().setMaster("local").setAppName("PartialFumction")
val sc=new SparkContext(conf)
val rdd1=sc.parallelize(List(('a',1),('a',1),('b',1),('c',1)))
val rdd2=sc.parallelize(List(('a',1),('b',1),('d',1)))
//用intersection()求两个RDD的共同元素
rdd1.intersection(rdd2).collect.foreach(print)
}
}5.Spark编程进阶
1.在集群环境中运行 Spark
(1)准备集群环境
包括安装 Hadoop、配置 SSH、设置环境变量等。
(2)下载并解压 Spark
从官网下载 Spark 压缩包,解压到指定目录
(3)配置 Spark
修改 Spark 配置文件,主要包括修改 master 和 worker 节点的 IP 地址和端口号、设置内存大小等。
(4)启动 Spark启动
master 节点和 worker 节点,可以通过命令行或者 web 界面进行启动。
如果除了设置运行的脚本名称之外不设置其他参数,那么 Spark 程序默认在本地
运行。
--class:应用程序的入口,指主程序。
--master:指定要连接的集群URL。
-deploy-mode:是否将驱动程序部署在工作节点(cluster)或本地作为外部客户端
(client)。
--conf:设置任意 Spark 配登属性,允许使用"key=value WordCount"的格式设置任意的SparkConf 配置属性。
application-jar:包含应用程序和所有依赖关系的JAR包的路径。
application-arguments:传递给main)方法的参数。
将代码 4-3 所示的程序运行模式更改为打包到集样中运行。程序中无须设置 master 地址、Hadoop 安装包位置。输人、输出路径可通过 spark-submit 指定。
2.spark-submit常用项配置
ndme Name 设置程序名
--jars JARS 添加依赖包
-driver-memory MEM Driver 程序使用的内存大小
-executor-memory MEM Executor使用的内存大小
-total-executor-cores NUM Executor使用的总内核数
--executor-cores NUM 每个Bxecutor使用的内核数
-num-executors NUM 启动的Executor数量
spark.eventLog.dir
保存日志相关信息的路径,可以是“hdfs://” 开头的 HDES 路径,也可以
是“e:// 开头的本地路径,路径均需要提前创建
spark.eventLog.enabled 是否开启日志记录
spark.cores.max
当应用程序运行在 Standalone 集群或粗粒度共享模式 Mesos 集群时,应用
程序向集群(不是每台机器,而是整个集群)请求的最大 CPU内核总数。如果不设置,那么对于 Standalone 集群将使用 spark,deploy. defaultCores 指定的数值,而 Mesos 集群将使用集群中可用的内核
6.Spark SQL——结构化数据文件处理
Spark SQL简介
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象结构叫做DataFrame的数据模型(即带有Schema信息的RDD),Spark SQL作为分布式SQL查询引擎,让用户可以通过SQL、DataFrames API和Datasets API三种方式实现对结构化数据的处理。
Spark SQL主要提供了以下三个功能:
Spark SQL可从各种结构化数据源中读取数据,进行数据分析。
Spark SQL包含行业标准的JDBC和ODBC连接方式,因此它不局限于在Spark程序内使用SQL语句进行查询。
Spark SQL可以无缝地将SQL查询与Spark程序进行结合,它能够将结构化数据作为Spark中的分布式数据集(RDD)进行查询。
Spark SQL架构
Spark SQL架构与Hive架构相比,把底层的MapReduce执行引擎更改为Spark,还修改了Catalyst优化器,Spark SQL快速的计算效率得益于Catalyst优化器。从HiveQL被解析成语法抽象树起,执行计划生成和优化的工作全部交给Spark SQL的Catalyst优化器进行负责和管理。

Spark要想很好地支持SQL,需要完成解析(Parser)、优化(Optimizer)、执行(Execution)三大过程。

Catalyst优化器在执行计划生成和优化的工作时,离不开内部的五大组件。
SqlParse:完成SQL语法解析功能,目前只提供了一个简单的SQL解析器。
Analyze:主要完成绑定工作,将不同来源的Unresolved LogicalPlan和元数据进行绑定,生成Resolved LogicalPlan。
Optimizer:对Resolved Lo;gicalPlan进行优化,生成OptimizedLogicalPlan。
Planner:将LogicalPlan转换成PhysicalPlan。
CostModel:主要根据过去的性能统计数据,选择最佳的物理执行计划。
Spark SQL工作流程:
下在解析SQL语句之前,会创建SparkSession,涉及到表名、字段名称和字段类型的元数据都将保存在SessionCatalog中;
当调用SparkSession的sql()方法时就会使用SparkSqlParser进行解析SQL语句,解析过程中使用的ANTLR进行词法解析和语法解析;
使用Analyzer分析器绑定逻辑计划,在该阶段,Analyzer会使用Analyzer Rules,并结合SessionCatalog,对未绑定的逻辑计划进行解析,生成已绑定的逻辑计划;
使用Optimizer优化器优化逻辑计划,该优化器同样定义了一套规则(Rules),利用这些规则对逻辑计划和语句进行迭代处理;
使用SparkPlanner对优化后的逻辑计划进行转换,生成可以执行的物理计划SparkPlan;
使用QueryExecution执行物理计划,此时则调用SparkPlan的execute()方法,返回RDDs。
DataFrame简介
Spark SQL使用的数据抽象并非是RDD,而是DataFrame。在Spark 1.3.0版本之前,DataFrame被称为SchemaRDD。DataFrame使Spark具备处理大规模结构化数据的能力。在Spark中,DataFrame是一种以RDD为基础的分布式数据集。DataFrame的结构类似传统数据库的二维表格,可以从很多数据源中创建,如结构化文件、外部数据库、Hive表等数据源。
DataFrame可以看作是分布式的Row对象的集合,在二维表数据集的每一列都带有名称和类型,这就是Schema元信息,这使得Spark框架可获取更多数据结构信息,从而对在DataFrame背后的数据源以及作用于DataFrame之上数据变换进行针对性的优化,最终达到提升计算效率。
DataFrame创建
创建DataFrame的两种基本方式:
已存在的RDD调用toDF()方法转换得到DataFrame。
通过Spark读取数据源直接创建DataFrame。
直接创建DataFarme对象
若使用SparkSession方式创建DataFrame,可以使用spark.read从不同类型的文件中加载数据创建DataFrame。spark.read的具体操作,如下所示。

(1)数据准备
在HDFS文件系统中的/spark目录中有一个person.txt文件,内容如下:
1 zhangsan 20
2 lisi 29
3 wangwu 25
4 zhaoliu 30
5 tianqi 35
6 jerry 40
(2)通过文件直接创建DataFrame
我们通过Spark读取数据源的方式进行创建DataFrame
scala > val personDF = spark.read.text("/spark/person.txt")
personDF: org.apache.spark.sql.DataFrame = [value: String]
scala > personDF.printSchema()
root
|-- value: String (Nullable = true)



(3)RDD直接转换为DataFrame
scala > val lineRDD = sc.textFile("/spark/person.txt").map(_.split(" "))
lineRDD: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[6] at map at <console>:24
scala > case class Person(id:Int,name:String,age:Int) defined class Person
scala > val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt))
personRDD: org.apache.spark.rdd.RDD[Person] = MapPartitionsRDD[7] at map at <console>:27
scala > val personDF = personRDD.toDF()
personDF: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]
DataFrame的常用操作
操作DataFrame的常用方法,具体如下表如示。

filter()/where条件查询
filter()
const people = [
{ name: 'Alice', age: 25 },
{ name: 'Bob', age: 18 },
{ name: 'Charlie', age: 22 }
];
const adults = people.filter(person => person.age > 20);
console.log(adults);where
SELECT * FROM users WHERE age > 20;mgroupBy()对数据进行分组
const data = [
{ key: 'a', value: 1 },
{ key: 'b', value: 2 },
{ key: 'c', value: 3 }
];
const groupedData = Object.keys(data).reduce((acc, key) => {
acc[key] = data[key];
return acc;
}, {});
console.log(groupedData);sort()/orderBy():对特定字段进行排序
desc:降序
SELECT * FROM users ORDER BY age DESC;asc:升序
SELECT * FROM users ORDER BY age ASC;sort()
const users = [
{ name: 'Alice', age: 25 },
{ name: 'Bob', age: 18 },
{ name: 'Charlie', age: 22 }
];
users.sort((a, b) => a.age - b.age);
console.log(users);Dataset对象的创建
(1)通过SparkSession中的createDataset来创建Dataset

(2)DataFrame通过“as[ElementType]”方法转换得到Dataset

RDD转换DataFrame
•Spark官方提供了两种方法实现从RDD转换得到DataFrame。
•第一种方法是利用反射机制来推断包含特定类型对象的Schema,这种方式适用于对已知数据结构的RDD转换
•第二种方法通过编程接口构造一个Schema,并将其应用在已知的RDD数据中。















 995
995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









